Visualisieren von Azure Databricks-Metriken mithilfe von Dashboards
Hinweis
In diesem Artikel wird auf eine Open-Source-Bibliothek zurückgegriffen, die auf GitHub unter https://github.com/mspnp/spark-monitoring gehostet wird.
Die ursprüngliche Bibliothek unterstützt Azure Databricks Runtime-Versionen bis Version 10.x (Spark 3.2.x).
Databricks hat eine aktualisierte Version zur Unterstützung von Azure Databricks Runtime-Versionen ab Version 11.0 (Spark 3.3.x) für den Branch l4jv2 unter https://github.com/mspnp/spark-monitoring/tree/l4jv2 bereitgestellt.
Beachten Sie, dass das Release 11.0 aufgrund der unterschiedlichen Protokollierungssysteme, die in Databricks Runtime-Instanzen verwendet werden, nicht abwärtskompatibel ist. Achten Sie darauf, den richtigen Build für Ihre Databricks Runtime-Instanz zu verwenden. Die Bibliothek und das GitHub-Repository befinden sich im Wartungsmodus. Es gibt keine Pläne für weitere Releases, und der Support bei Problemen wird nur bestmöglich bereitgestellt. Wenn Sie weitere Fragen zu der Bibliothek oder zur Roadmap für die Überwachung und Protokollierung Ihrer Azure Databricks-Umgebungen haben, wenden Sie sich an azure-spark-monitoring-help@databricks.com.
In diesem Artikel wird das Einrichten eines Grafana-Dashboards zum Überwachen von Azure Databricks-Aufträgen auf Leistungsprobleme veranschaulicht.
Azure Databricks ist ein schneller, leistungsstarker, für Zusammenarbeit ausgelegter Analysedienst, der auf Apache Spark basiert und eine zügige Entwicklung und Bereitstellung von Analyse- und KI-Lösungen für Big Data ermöglicht. Die Überwachung ist eine wichtige Komponente des Einsatzes von Azure Databricks-Workloads in der Produktion. Der erste Schritt besteht im Sammeln von Metriken in einem Arbeitsbereich für die Analyse. In Azure ist Azure Monitor die beste Lösung zur Verwaltung von Protokolldaten. Azure Databricks unterstützt nicht nativ das Senden von Daten an Azure Monitor, aber eine Bibliothek für diese Funktionalität steht in GitHub zur Verfügung.
Diese Bibliothek aktiviert sowohl die Protokollierung von Azure Databricks-Dienstmetriken als auch die Ereignismetriken für die Strukturiertes-Streaming-Abfrage in Apache Spark. Nachdem Sie diese Bibliothek erfolgreich für einen Azure Databricks-Cluster bereitgestellt haben, können Sie weiter eine Reihe von Grafana-Dashboards bereitstellen, die Sie als Teil Ihrer Produktionsumgebung bereitstellen können.
Voraussetzungen
Konfigurieren Sie Ihren Azure Databricks-Cluster zur Verwendung der Überwachungsbibliothek, wie beschrieben in der GitHub-Infodatei.
Bereitstellen des Azure Log Analytics-Arbeitsbereichs
Gehen Sie zum Bereitstellen des Azure Log Analytics-Arbeitsbereichs folgendermaßen vor:
Navigieren Sie zum Verzeichnis
/perftools/deployment/loganalytics.Stellen Sie die Azure Resource Manager-Vorlage logAnalyticsDeploy.json bereit. Weitere Informationen zur Bereitstellung von Resource Manager-Vorlagen finden Sie unter Bereitstellen von Ressourcen mit Azure Resource Manager-Vorlagen und der Azure CLI. Die Vorlage hat die folgenden Parameter:
- location: Die Region, in der Log Analytics-Arbeitsbereich und Dashboards bereitgestellt werden.
- serviceTier: Der Arbeitsbereichstarif. Hier finden Sie eine Liste gültiger Werte.
- dataRetention (optional): Die Dauer der Speicherung von Protokolldaten im Log Analytics-Arbeitsbereich in Tagen. Der Standardwert ist 30 Tage. Im Tarif
Freemuss die Datenaufbewahrung sieben Tage betragen. - workspaceName (optional): Ein Name für den Arbeitsbereich. Ohne Angabe generiert die Vorlage einen Namen.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Diese Vorlage erstellt den Arbeitsbereich und auch einen Satz von vordefinierten Abfragen, die vom Dashboard verwendet werden.
Bereitstellen von Grafana auf einem virtuellen Computer
Das Open-Source-Projekt Grafana können Sie bereitstellen, um die in Ihrem Azure Log Analytics-Arbeitsbereich gespeicherten Zeitreihenmetriken mithilfe des Grafana-Plug-Ins für Azure Monitor zu visualisieren. Grafana wird auf einem virtuellen Computer (VM) ausgeführt und erfordert ein Speicherkonto, ein virtuelles Netzwerk und andere Ressourcen. Gehen Sie zum Bereitstellen eines virtuellen Computers mit dem Bitnami-zertifizierten Grafana-Image und dazugehörigen Ressourcen wie folgt vor:
Verwenden Sie die Azure-Befehlszeilenschnittstelle, um die Azure Marketplace-Image-Bedingungen für Grafana zu akzeptieren.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultNavigieren Sie in Ihrer lokalen Kopie des GitHub-Repositorys zum
/spark-monitoring/perftools/deployment/grafana-Verzeichnis.Stellen Sie die Resource Manager-Vorlage grafanaDeploy.json wie folgt bereit:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Sobald die Bereitstellung abgeschlossen ist, wird das Bitnami-Image von Grafana auf dem virtuellen Computer installiert.
Aktualisieren des Grafana-Kennworts
Im Rahmen des Installationsvorgangs gibt das Grafana-Installationsskript ein temporäres Kennwort für den Administrator-Benutzer aus. Sie benötigen dieses temporäre Kennwort für die Anmeldung. Um das temporäre Kennwort zu erhalten, gehen Sie folgendermaßen vor:
- Melden Sie sich beim Azure-Portal an.
- Wählen Sie die Ressourcengruppe aus, in der die Ressourcen bereitgestellt wurden.
- Wählen Sie den virtuellen Computer aus, auf dem Grafana installiert wurde. Wenn Sie den Standardparameternamen in der Bereitstellungsvorlage verwendet haben, wird dem VM-Namen sparkmonitoring-vm-grafana vorangestellt.
- Klicken Sie im Abschnitt Support + Problembehandlung auf Startdiagnose, um die Startdiagnoseseite zu öffnen.
- Klicken Sie auf der Startdiagnoseseite auf Serielles Protokoll.
- Suchen Sie nach folgender Zeichenfolge: „Setting Bitnami application password to“.
- Kopieren Sie das Kennwort an einen sicheren Speicherort.
Ändern Sie als Nächstes mit folgenden Schritten das Grafana-Administratorkennwort:
- Wählen Sie im Azure-Portal den virtuellen Computer aus, und klicken Sie auf Übersicht.
- Kopieren Sie die öffentliche IP-Adresse.
- Öffnen Sie einen Browser, und navigieren Sie zur folgenden URL:
http://<IP address>:3000. - Geben Sie im Grafana-Anmeldebildschirm admin für den Benutzernamen ein, und verwenden Sie das Grafana-Kennwort aus den vorherigen Schritten.
- Wählen Sie nach der Anmeldung Konfiguration aus (das Zahnradsymbol).
- Wählen Sie Serveradministrator aus.
- Wählen Sie auf der Registerkarte Benutzer die admin-Anmeldung aus.
- Aktualisieren Sie das Kennwort.
Erstellen einer Azure Monitor-Datenquelle
Erstellen Sie einen Dienstprinzipal, mit dem Grafana Ihren Zugriff auf den Log Analytics-Arbeitsbereich verwalten kann. Weitere Informationen finden Sie unter Erstellen eines Azure-Dienstprinzipals mit Azure CLI.
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDBeachten Sie die Werte für „appId“, „password“ und „tenant“ in der Ausgabe dieses Befehls:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Melden Sie sich wie weiter oben beschrieben bei Grafana an. Wählen Sie Konfiguration (das Zahnradsymbol) und dann Datenquellen aus.
Klicken Sie auf der Registerkarte Datenquellen auf Datenquelle hinzufügen.
Wählen Sie Azure Monitor als Datenquelle aus.
Geben Sie im Abschnitt Einstellungen im Textfeld Name einen Namen für die Datenquelle ein.
Geben Sie im Abschnitt Azure Monitor-API-Details die folgenden Informationen ein:
- Subscription Id: Die ID Ihres Azure-Abonnements.
- Tenant Id: Die frühere Mandanten-ID.
- Client Id: Der frühere Wert von „appId“.
- Geheimer Clientschlüssel: Der frühere Wert von „password“.
Aktivieren Sie im Abschnitt Azure Protokollanalyse-API-Details das Kontrollkästchen und wählen Sie Dieselben Details wie die Azure Monitor-API aus.
Klicken Sie auf Speichern und testen. Wenn die Log Analytics-Datenquelle ordnungsgemäß konfiguriert ist, wird eine Erfolgsmeldung angezeigt.
Erstellen des Dashboards
Erstellen Sie mit folgenden Schritten die Dashboards in Grafana:
Navigieren Sie in Ihrer lokalen Kopie des GitHub-Repositorys zum
/perftools/dashboards/grafana-Verzeichnis.Führen Sie folgendes Skript aus:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shDie Ausgabe des Skripts ist eine Datei namens SparkMonitoringDash.json.
Kehren Sie zum Grafana-Dashboard zurück, und wählen Sie Erstellen aus (das Plussymbol).
Wählen Sie Importieren aus.
Klicken Sie auf JSON-Datei hochladen.
Wählen Sie die in Schritt 2 erstellte SparkMonitoringDash.json-Datei aus.
Wählen Sie im Abschnitt Optionen unter ALA die zuvor erstellte Azure Monitor-Datenquelle aus.
Klicken Sie auf Importieren.
Visualisierungen in den Dashboards
Sowohl Azure Log Analytics als auch Grafana-Dashboards enthalten eine Reihe von Zeitreihenvisualisierungen. Jedes Diagramm ist ein Zeitreihenplot von Metrikdaten, die sich auf einen Apache Spark-Auftrag, die Phasen des Auftrags und die Aufgaben, aus denen jede Phase besteht, beziehen.
Die Visualisierungen sind:
Auftragslatenz
Diese Visualisierung zeigt die Ausführungslatenz für einen Auftrag an, eine grobe Sicht der Gesamtleistung eines Auftrags. Die Dauer der Auftragsausführung wird vom Anfang bis zum Abschluss angezeigt. Beachten Sie, dass die Startzeit des Auftrags nicht mit der Auftragsübermittlungszeit identisch ist. Die Latenz wird in Quantilen (10%, 30%, 50%, 90%) der Auftragsausführung dargestellt, indiziert durch Cluster-ID und Anwendungs-ID.
Phasenlatenz
Die Visualisierung zeigt die Latenz der einzelnen Phasen pro Cluster, Anwendung und für die einzelne Phase an. Diese Visualisierung ist nützlich zum Identifizieren einer bestimmten Phase, die langsam ausgeführt wird.
Aufgabenlatenz
Diese Visualisierung zeigt die Ausführungslatenz von Aufgaben an. Die Latenz wird als ein Quantil der Taskausführung pro Cluster, Phasenname und Anwendung dargestellt.
Summe der Aufgabenausführung pro Host
Diese Visualisierung zeigt die Summe der Aufgabenausführungslatenz pro Host in einem Cluster an. Das Anzeigen der Aufgabenausführungslatenz pro Host identifiziert Hosts mit einer viel höheren gesamten Aufgabenlatenz als andere Hosts. Dies kann bedeuten, dass Aufgaben ineffizient oder ungleichmäßig auf Hosts verteilt wurden.
Aufgabenmetriken
Diese Visualisierung zeigt einen Satz von Ausführungsmetriken für die Ausführung einer bestimmten Aufgabe an. Diese Metriken beinhalten die Größe und Dauer eines Datenshuffles, die Dauer der Serialisierungs- und Deserialisierungsvorgänge und Sonstiges. Wenn Sie die Log Analytics-Abfrage für den Bereich anzeigen, wird der vollständige Satz der Metriken angezeigt. Diese Visualisierung ist nützlich, um die Vorgänge zu verstehen, die eine Aufgabe ausmachen, und den Ressourcenverbrauch der einzelnen Vorgänge zu identifizieren. Spitzen im Diagramm stellen kostspielige Vorgänge dar, die untersucht werden sollten.
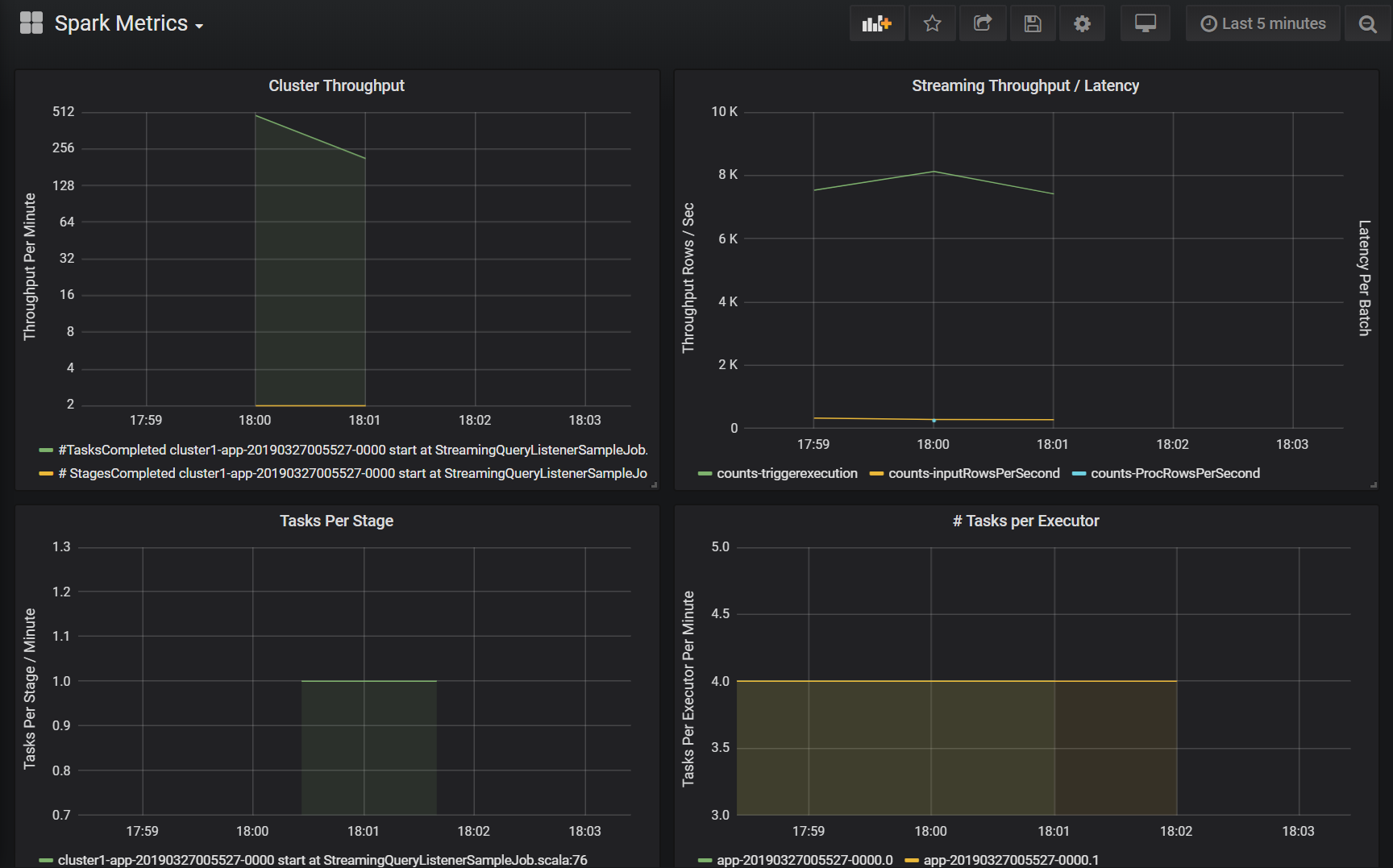
Clusterdurchsatz
Diese Visualisierung ist eine allgemeine Ansicht von nach Cluster und Anwendung indizierten Arbeitselementen zur Darstellung des pro Cluster und Anwendung verrichteten Arbeitspensums. Sie zeigt die Anzahl der pro Cluster, Anwendung und Phase abgeschlossenen Aufträge, Aufgaben und Phasen in Schritten von einer Minute an.
Streamingdurchsatz/Latenz
Diese Visualisierung bezieht sich auf die Metriken in Zusammenhang mit einer Strukturiertes-Streaming-Abfrage. Das Diagramm zeigt die Anzahl der Eingabezeilen pro Sekunde und die Anzahl der pro Sekunde verarbeiteten Zeilen. Die Streamingmetriken werden auch pro Anwendung dargestellt. Diese Metriken werden gesendet, wenn das OnQueryProgress-Ereignis bei der Verarbeitung der Strukturiertes-Streaming-Abfrage generiert wird, und die Visualisierung stellt die Streaminglatenz als Zeitspanne in Millisekunden dar, die die Ausführung eines Abfragebatches benötigt.
Ressourcenverbrauch pro Executor
Als Nächstes wird in einer Reihe von Visualisierungen für das Dashboard der bestimmte Ressourcentyp und seine Nutzung pro Executor auf den einzelnen Clustern angezeigt. Diese Visualisierungen erleichtern das Identifizieren von Ausreißern im Ressourcenverbrauch pro Executor. Wenn z.B. die Zuordnung der Arbeit für einen bestimmten Executor verzerrt ist, wird der Ressourcenverbrauch im Verhältnis zu anderen im Cluster ausgeführten Executorn erhöht. Dies kann anhand der Spitzen im Ressourcenverbrauch für einen Executor identifiziert werden.
Executor-Computezeitmetriken
Als Nächstes wird in einer Reihe von Visualisierungen für das Dashboard das Verhältnis von Executorserialisierungszeit, Deserialisierungszeit, CPU-Zeit und Java-VM-Zeit zur allgemeinen Executorcomputezeit angezeigt. Dies veranschaulicht visuell, wie viel jede dieser vier Metriken zur allgemeinen Executorverarbeitung beiträgt.
Shufflemetriken
Der letzte Satz von Visualisierungen zeigt die Datenshufflemetriken in Verbindung mit einer alle Executor übergreifenden Strukturiertes-Streaming-Abfrage an. Dazu gehören gelesene Shufflebytes, geschriebene Shufflebytes, Shufflearbeitsspeicher und Datenträgernutzung in Abfragen, in denen das Dateisystem verwendet wird.