Erkenntnisse
- Stellen Sie sicher, dass alle beteiligten Parteien den Unterschied zwischen Hoher Verfügbarkeit (HA) und Disaster Recovery (DR) verstehen: Ein gemeinsamer Fall besteht darin, die beiden Konzepte zu verwechseln und die ihnen zugeordneten Lösungen zu verwechseln.
- Sprechen Sie mit den Projektbeteiligten über ihre Erwartungen hinsichtlich der folgenden Aspekte, um die Zielvorgaben für Recovery Point Objectives (RPOs) und Recovery Time Objectives (RTOs) zu definieren:
- Wie viel Ausfallzeiten sie tolerieren können, beachten Sie, dass in der Regel, je schneller die Erholung, desto höher die Kosten.
- Die Art der Vorfälle, vor denen Schutz benötigt wird, unter Angabe der Wahrscheinlichkeit eines solchen Ereignisses. Beispielsweise ist die Wahrscheinlichkeit, dass ein Server heruntergeht, höher als eine Naturkatastrophe, die sich auf alle Rechenzentren in einer Region auswirkt.
- Welche Auswirkungen hat die Nichtverfügbarkeit des Systems auf ihr Geschäft?
- Der Betriebsaufwand (OPEX) für die Lösung wird in Zukunft umgesetzt.
- Überlegen Sie, welche eingeschränkten Dienstoptionen Ihre Endbenutzer akzeptieren können. Dies kann Folgendes beinhalten:
- Weiterhin Zugriff auf Visualisierungsdashboards, auch ohne die aktuellsten Daten, d. h. wenn die Aufnahmepipelines nicht funktionieren, haben Endbenutzer weiterhin Zugriff auf ihre Daten.
- Lesezugriff, aber kein Schreibzugriff.
- Ihre angestrebten RTO- und RPO-Kennzahlen können definieren, welche Notfallwiederherstellungsstrategie Sie implementieren möchten:
- Aktiv/Aktiv.
- Aktiv/Passiv.
- Active/Redeploy on disaster.
- Berücksichtigen Sie Ihr eigenes Verbundziel (Composite Service Level Objective, SLO), um die tolerierbaren Ausfallzeiten einzustufen.
- Stellen Sie sicher, dass Sie alle Komponenten kennen, die sich auf die Verfügbarkeit Ihrer Systeme auswirken können, darunter beispielweise:
- Identitätsverwaltung.
- Netzwerktopologie.
- Geheime/Schlüsselverwaltung.
- Datenquellen.
- Automatisierungs-/Auftragsplanung.
- Quell-Repository- und Bereitstellungspipelinen (GitHub, Azure DevOps).
- Die frühzeitige Erkennung von Ausfällen ist ebenfalls eine Möglichkeit, die RTO- und RPO-Werte deutlich zu senken. Im Folgenden werden einige Aspekte aufgeführt, die Sie beachten sollten:
- Definieren Sie, was ein Ausfall ist und inwieweit dies der Microsoft-Definition eines Ausfalls entspricht. Sie finden die Microsoft-Definition eines Ausfalls auf der Seite zum Azure-SLA auf Produkt- oder Dienstebene.
- Ein effizientes Überwachungs- und Warnsystem mit verantwortlichen Teams, um diese Metriken und Warnungen zeitnah zu überprüfen, hilft dabei, das Ziel zu erreichen.
- In Bezug auf den Abonnemententwurf kann die zusätzliche Infrastruktur für die Notfallwiederherstellung im ursprünglichen Abonnement enthalten sein. Plattform as a Service (PaaS)-Dienste wie Azure Data Lake Storage Gen2 oder Azure Data Factory verfügen in der Regel über systemeigene Features, mit denen sekundäre Instanzen in anderen Regionen fehlschlagen können, während sie im ursprünglichen Abonnement enthalten bleiben. Einige Kunden sollten in Erwägung ziehen, eine dedizierte Ressourcengruppe für Ressourcen zu verwenden, die nur in DR-Szenarien für Kostenzwecke verwendet werden.
- Es sollte beachtet werden, dass Abonnementlimits eine Einschränkung für diesen Ansatz darstellen können.
- Andere Einschränkungen können die Entwurfskomplexitäts- und Verwaltungssteuerelemente umfassen, um sicherzustellen, dass die DR-Ressourcengruppen nicht für Business-as-usual-Workflows (BAU) verwendet werden.
- Entwerfen Sie den DR-Workflow basierend auf der Wichtigkeit einer Lösung und ihrer Abhängigkeiten. Versuchen Sie beispielsweise nicht, eine Azure Analysis Services-Instanz neu zu erstellen, bevor Ihr Data Warehouse ausgeführt wird, da ein Fehler ausgelöst wird. Verlassen Sie Entwicklungslabore später im Prozess, und stellen Sie zunächst die wichtigsten Unternehmenslösungen wieder her.
- Versuchen Sie, Wiederherstellungsaufgaben zu identifizieren, die über Lösungen hinweg parallelisiert werden können, wodurch die gesamter RTO reduziert wird.
- Wenn Azure Data Factory in einer Lösung verwendet wird, vergessen Sie nicht, die selbstgehosteten IRs in den Geltungsbereich einzuschließen. Azure Site Recovery ist ideal für diese Computer.
- Manuelle Vorgänge sollten so weit wie möglich automatisiert werden, um Bedienungsfehler zu vermeiden, insbesondere dann, wenn der Druck sehr hoch ist. Folgendes wird empfohlen:
- Übernehmen Sie die Ressourcenbereitstellung über Bicep-, ARM-Vorlagen oder PowerShell-Skripts.
- Übernehmen sie die Versionsverwaltung von Quellcode und Ressourcenkonfiguration.
- Verwenden Sie CI/CD-Releasepipelinen anstelle von Klick-Ops.
- Wenn Sie über einen Plan für das Failover verfügen, sollten Sie Prozeduren in Betracht ziehen, um auf die primären Instanzen zurückzugreifen.
- Definieren Sie klare Indikatoren und Metriken, um zu überprüfen, ob das Failover erfolgreich war und Lösungen ausgeführt werden oder dass die Situation wieder normal ist (auch als primär funktionsfähig bezeichnet).
- Entscheiden Sie, ob Ihre Vereinbarungen auf Service-Level-Vereinbarungen (SLAs) nach einem Failover gleich bleiben sollen, oder ob Sie einen herabgestuften Dienst zulassen.
- Diese Entscheidung hängt stark von dem zu unterstützenden Geschäftsprozess ab. Beispielsweise sieht das Failover für ein Raumbuchungssystem viel anders aus als ein Kernbetriebssystem.
- Eine RTO/RPO-Definition sollte auf bestimmten Benutzerszenarien und nicht auf Infrastrukturebene basieren. Auf diese Weise erhalten Sie genauere Granularität darüber, welche Prozesse und Komponenten zuerst wiederhergestellt werden sollen, wenn ein Ausfall oder eine Katastrophe auftritt.
- Stellen Sie sicher, dass Sie Kapazitätsüberprüfungen in die Zielregion einschließen, bevor Sie mit einem Failover fortfahren: Wenn es ein großes Notfall gibt, sollten Sie beachten, dass viele Kunden gleichzeitig versuchen, ein Failover auf dieselbe gekoppelte Region durchzuführen, was zu Verzögerungen oder Konflikte bei der Bereitstellung der Ressourcen führen kann.
- Wenn diese Risiken inakzeptabel sind, sollte entweder eine Aktive/Aktive oder eine passive DR-Strategie berücksichtigt werden.
- Es sollte ein Notfallwiederherstellungsplan erstellt und verwaltet werden, um den Wiederherstellungsvorgang und die Aktionsbesitzer zu dokumentieren. Denken Sie außerdem daran, dass Personen womöglich abwesend sind. Stellen Sie deshalb sicher, dass Sie Zweitkontakte angeben.
- Regelmäßige Notfallwiederherstellungs-Drills sollten durchgeführt werden, um den DR-Planworkflow zu überprüfen, dass er das erforderliche RTO/RPO erfüllt und die verantwortlichen Teams trainiert.
- Daten- und Konfigurationssicherungen sollten ebenfalls regelmäßig getestet werden, um sicherzustellen, dass sie für die Unterstützung von Wiederherstellungsaktivitäten geeignet sind.
- Eine frühzeitige Zusammenarbeit mit den Teams, die für Netzwerkbetrieb, Identität und Ressourcenbereitstellung zuständig sind, ermöglicht eine Einigung auf die optimale Lösung unter diesen Gesichtspunkten:
- Wie werden Benutzer und Datenverkehr von Ihrem primären an den sekundären Standort weitergeleitet? Konzepte wie DNS-Umleitung oder die Verwendung bestimmter Tools wie Azure Traffic Manager können ausgewertet werden.
- So stellen Sie den Zugriff und die Rechte auf die sekundäre Website zeitnah und sicher bereit.
- Während einer Katastrophe ist eine effektive Kommunikation zwischen den vielen beteiligten Parteien entscheidend für die effiziente und schnelle Ausführung des Plans. Teams können Folgendes umfassen:
- Entscheidungsträger.
- Team zur Reaktion auf Vorfälle.
- Betroffene interne Benutzer und Teams.
- Externe Teams.
- Die Orchestrierung der verschiedenen Ressourcen zur richtigen Zeit stellt die Effizienz bei der Ausführung des Notfallwiederherstellungsplans sicher.
Überlegungen
Antimuster
- Kopieren/Einfügen dieser Artikelreihe Diese Artikelreihe soll Kunden, die nach der nächsten Detailebene für einen Azure-spezifischen DR-Prozess suchen, Anleitungen bieten. Aus diesem Grund basiert das Verfahren auf den allgemeinen Microsoft IP- und Referenzarchitekturen und nicht auf einer einzelnen kundenspezifischen Azure-Implementierung.
Auch wenn die bereitgestellten Details zu einem soliden Grundverständnis beitragen, müssen die Kunden den spezifischen Kontext, ihre eigene Implementierung und die für sie geltenden Anforderungen berücksichtigen, bevor sie eine zweckmäßige DR-Strategie und einen entsprechenden Prozess entwickeln können.
Betrachtung der Notfallwiederherstellung als rein technischer Prozess: Die geschäftlichen Projektbeteiligten spielen eine entscheidende Rolle bei der Definition der Anforderungen für die Notfallwiederherstellung und bei den Schritten zur Geschäftsvalidierung, die zur Bestätigung einer Dienstwiederherstellung erforderlich sind. Durch die Einbeziehung der geschäftlichen Projektbeteiligten in alle Notfallwiederherstellungsaktivitäten erhalten Sie einen geeigneten Notfallwiederherstellungsvorgang, der einen Mehrwert für das Unternehmen darstellt und umsetzbar ist.
DR-Pläne nach dem „Set-and-Forget“-Prinzip: Azure entwickelt sich ständig weiter, ebenso wie die Nutzung der verschiedenen Komponenten und Services durch einzelne Kunden. Ein zielführender DR-Prozess muss sich daher an diese Entwicklung anpassen. Entweder über den Lebenszyklus der Softwareentwicklung (SOFTWARE Development Life Cycle, SDLC) oder regelmäßige Überprüfungen sollten Kunden ihren DR-Plan regelmäßig überarbeiten. Ziel ist es, die Gültigkeit des Dienstwiederherstellungsplans sicherzustellen und alle Abweichungen zwischen Komponenten, Diensten oder Lösungen zu berücksichtigen.
Papierbasierte Einschätzungen: Auch wenn die End-to-End-Simulation eines DR-Ereignisses in einem modernen Datenökosystem schwierig ist, sollten alle Anstrengungen unternommen werden, um einer vollständigen Simulation der betroffenen Komponenten so nahe wie möglich zu kommen. Regelmäßig geplante Notfallübungen sorgen dafür, dass die zuständigen Personen in der Organisation sich den Notfallwiederherstellungsplan einprägen und so im Ernstfall sicher ausführen können.
Sich darauf verlassen, dass Microsoft alles übernimmt Bei den Microsoft Azure-Services gibt es eine klare Teilung der Verantwortung, je nach der verwendeten Clouddienstebene:
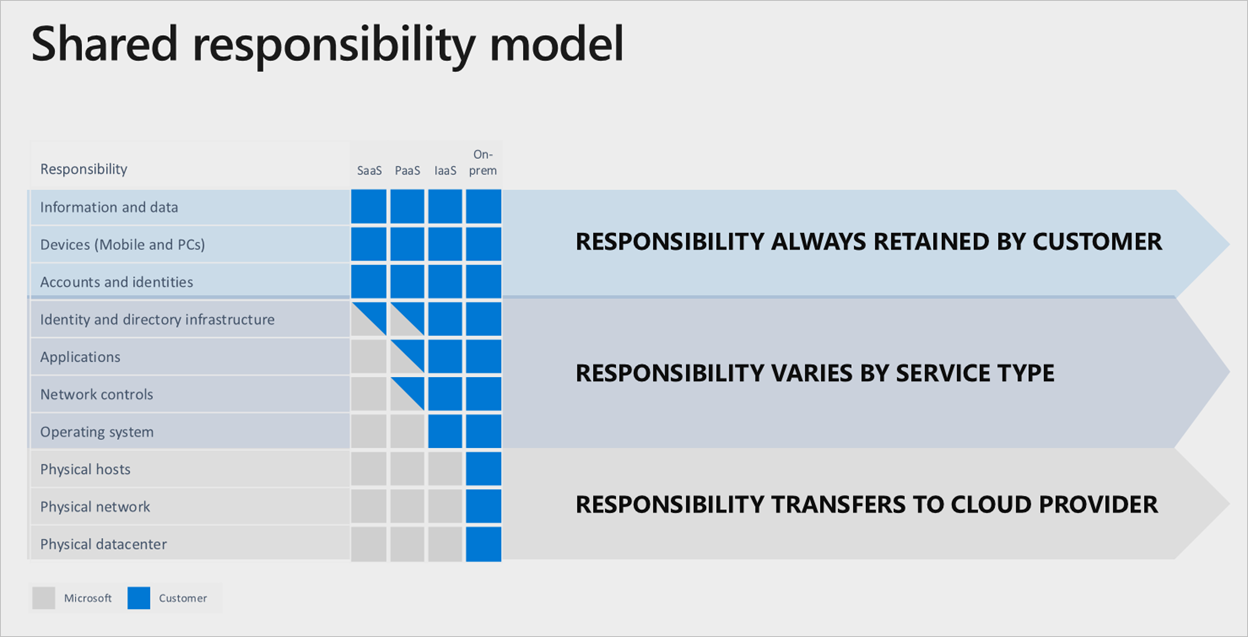 Selbst wenn ein vollständiger Software-as-a-Service (SaaS)-Stack verwendet wird, hat der Kunde weiterhin die Verantwortung dafür, sicherzustellen, dass die Konten, Identitäten und Daten korrekt und aktuell sind, ähnlich wie die Geräte, die für die Interaktion mit den Azure-Services verwendet werden.
Selbst wenn ein vollständiger Software-as-a-Service (SaaS)-Stack verwendet wird, hat der Kunde weiterhin die Verantwortung dafür, sicherzustellen, dass die Konten, Identitäten und Daten korrekt und aktuell sind, ähnlich wie die Geräte, die für die Interaktion mit den Azure-Services verwendet werden.
Ereignisumfang und Strategie
Umfang des Notfallereignisses
Je nach Ereignis sind die Auswirkungen unterschiedlich groß, deshalb müssen Sie auch unterschiedlich reagieren. Die folgende Abbildung veranschaulicht dies für ein Notfallereignis: 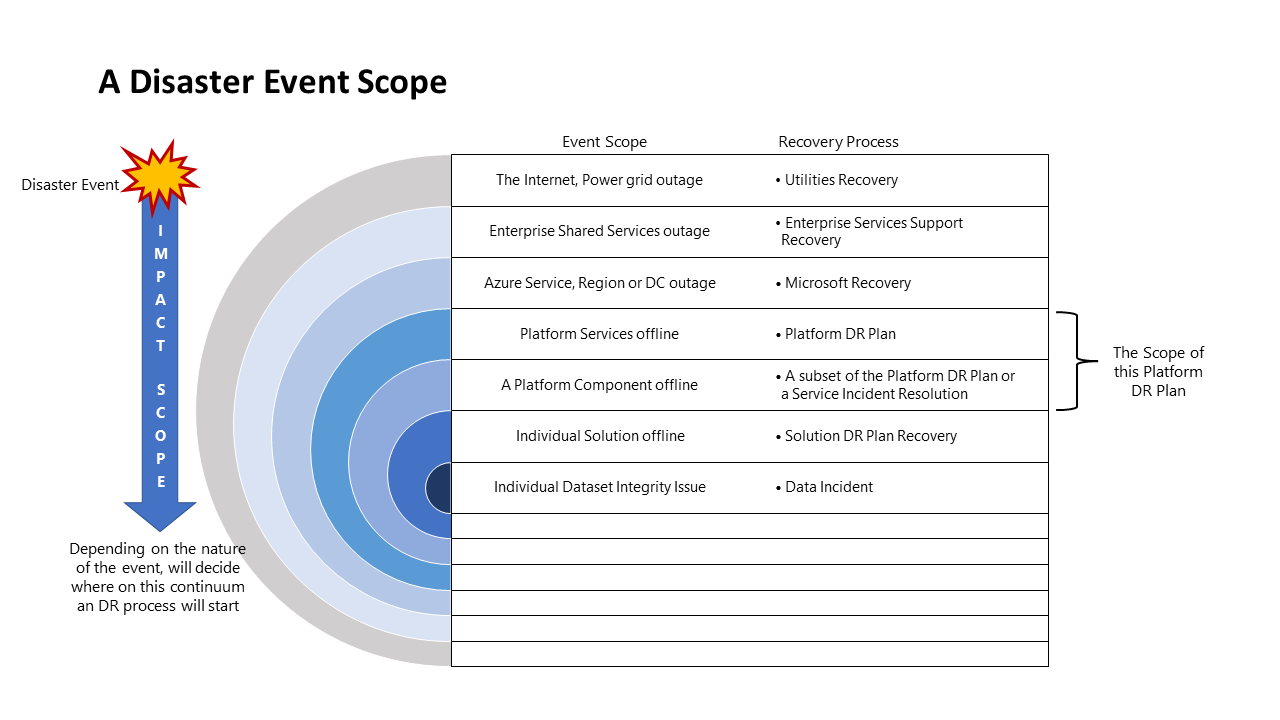
Optionen für eine Notfallstrategie
Es gibt vier allgemeine Optionen für eine Notfallwiederherstellungsstrategie:
- Warten auf Microsoft: Wie der Name schon sagt, bleibt die Lösung offline, bis Microsoft die Services in der betroffenen Region wiederhergestellt hat. Nach der Wiederherstellung wird die Lösung vom Kunden überprüft und dann für die Dienstwiederherstellung auf dem neuesten Stand gebracht.
- Erneute Bereitstellung im Notfall – Die Lösung wird manuell in einer verfügbaren Region von Grund auf neu bereitgestellt, nach dem Notfallereignis.
- Warm-Spare-Strategie (Aktiv/Passiv): In einer alternativen Region wird eine sekundäre gehostete Lösung erstellt, und durch die Bereitstellung der Komponenten wird eine Mindestkapazität gewährleistet. Die Komponenten empfangen jedoch keinen Produktionsdatenverkehr. Die sekundären Dienste in der alternativen Region können "deaktiviert" oder auf einer niedrigeren Leistungsstufe ausgeführt werden, bis z. B. ein DR-Ereignis auftritt.
- Hot-Spare-Strategie (Aktiv/Aktiv): Die Lösung wird regionsübergreifend in einer Aktiv/Aktiv-Konfiguration gehostet. Die sekundäre gehostete Lösung empfängt, verarbeitet und dient Daten als Teil des größeren Systems.
Auswirkungen der DR-Strategie
Während die Betriebskosten oftmals dem höheren Servicelevel geschuldet sind, werden die wichtigsten Entwurfsentscheidungen für eine DR-Strategie häufig von der Ausfallsicherheit bestimmt. Darüber müssen weitere wichtige Aspekte berücksichtigt werden.
Hinweis
Die Kostenoptimierung ist eine der fünf Säulen für eine erstklassige Architektur im Well-Architected Framework von Azure. Ziel ist es, unnötige Ausgaben zu reduzieren und die betriebliche Effizienz zu verbessern.
Das DR-Szenario für dieses Praxisbeispiel ist ein vollständiger regionaler Azure-Ausfall, der sich direkt auf die primäre Region auswirkt, in der die Datenplattform von Contoso gehostet wird.
Dieses Ausfallszenario hat die folgenden relativen Auswirkungen auf die vier allgemeinen DR-Strategien: 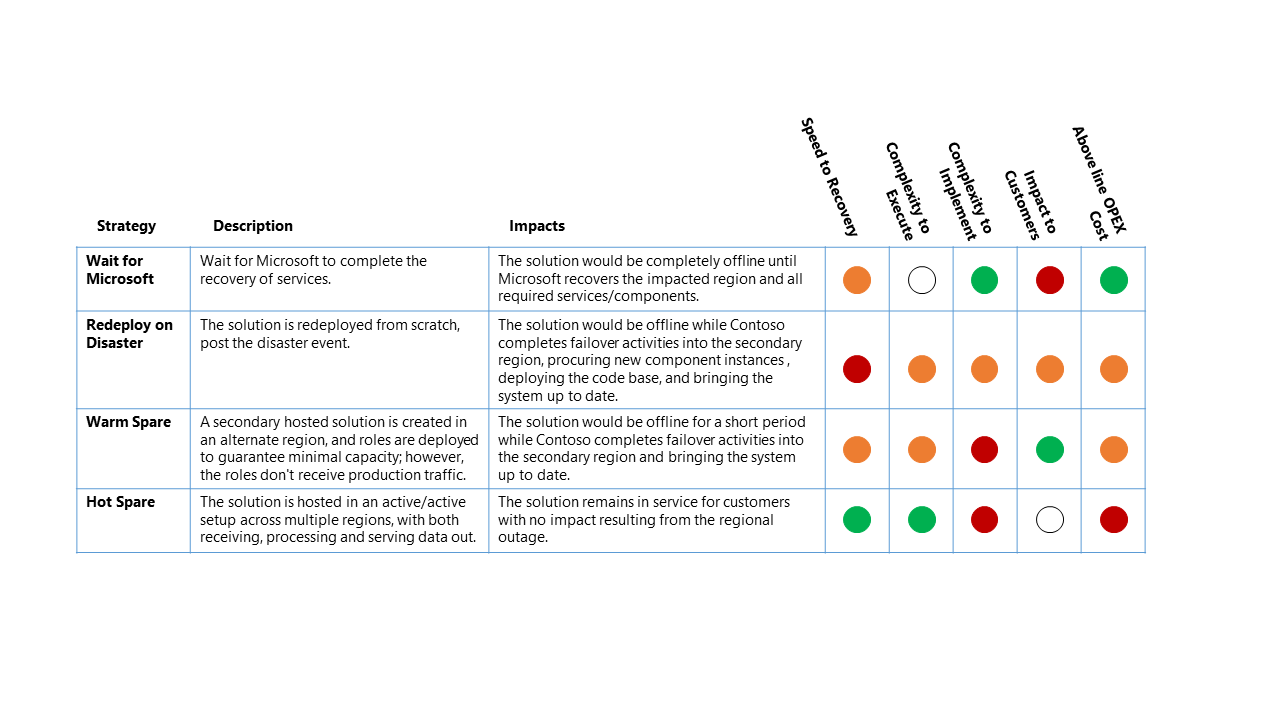
Klassifizierungsschlüssel
- Wiederherstellungszeitziel (RTO): Die erwartete verstrichene Zeit vom Notfallereignis bis zur Plattformdienstwiederherstellung.
- Komplexität der Ausführung: Die Komplexität für die Organisation zum Ausführen der Wiederherstellungsaktivitäten.
- Komplexität zu implementieren: Die Komplexität für die Organisation zur Implementierung der DR-Strategie.
- Auswirkungen auf Kunden: Die direkten Auswirkungen auf Kunden des Datenplattformdiensts aus der DR-Strategie.
- Über den OPEX-Kosten: Die zusätzlichen Kosten, die von der Implementierung dieser Strategie erwartet werden, z. B. erhöhte monatliche Abrechnung für Azure für zusätzliche Komponenten und zusätzliche Ressourcen, die zur Unterstützung erforderlich sind.
Hinweis
Die obige Tabelle sollte als Vergleich zwischen den Optionen gelesen werden - eine Strategie mit einem grünen Indikator ist für diese Klassifizierung besser als eine andere Strategie mit einem gelben oder roten Indikator.
Nächste Schritte
Nachdem Sie jetzt die Empfehlungen für das Szenario kennen, können Sie sich darüber informieren, wie Sie dieses Szenario bereitstellen.