Übersicht über generative KI-Gatewayfunktionen in Azure API Management
GILT FÜR: Alle API Management-Ebenen
In diesem Artikel werden Funktionen in Azure API Management vorgestellt, mit denen Sie generative KI-APIs verwalten können, wie sie z. B. von Azure OpenAI Service bereitgestellt werden. Azure API Management bietet eine Reihe von Richtlinien, Metriken und anderen Features zur Verbesserung der Sicherheit, Leistung und Zuverlässigkeit für die APIs, die Ihren intelligenten Apps zugrunde liegen. Zusammen werden diese Features als GenAI-Gatewayfunktionen für Ihre generativen KI-APIs bezeichnet, wobei „GenAI“ für generative KI steht.
Hinweis
- Dieser Artikel konzentriert sich auf Funktionen zum Verwalten von APIs, die von Azure OpenAI Service verfügbar gemacht werden. Viele der GenAI-Gatewayfunktionen gelten für andere LLM-APIs (Large Language Model), einschließlich derjenigen, die über die Azure KI-Modellrückschluss-API verfügbar sind.
- Generative KI-Gatewayfunktionen sind keine Features eines separaten API-Gateways, sondern Features des vorhandenen API-Gateways von API Management. Weitere Informationen finden Sie in der Übersicht über Azure API Management.
Herausforderungen bei der Verwaltung generativer KI-APIs
Eine der Hauptressourcen, in generativen KI-Diensten sind Token. Azure OpenAI Service weist ein Kontingent für Ihre Modellimplementierungen zu. Dieses wird in Token pro Minute (TPM) ausgedrückt und auf Ihre Modellconsumer aufgeteilt. Dabei kann es sich beispielsweise um verschiedene Anwendungen, Entwicklerteams oder Abteilungen innerhalb des Unternehmens handeln.
Mit Azure lässt sich ganz einfach eine einzelne App mit Azure OpenAI Service verbinden: Sie können eine direkte Verbindung unter Verwendung eines API-Schlüssels mit einem TPM-Grenzwert herstellen, der direkt auf der Modellimplementierungsebene konfiguriert ist. Mit zunehmender Größe Ihres Anwendungsportfolios gibt es jedoch mehrere Apps, die einzelne oder sogar mehrere Azure OpenAI Service-Endpunkte aufrufen, die als Instanzen mit nutzungsbasierter Bezahlung oder als PTU-Instanzen (Provisioned Throughput Units; bereitgestellte Durchsatzeinheiten) bereitgestellt werden. Das bringt gewisse Herausforderungen mit sich:
- Wie wird die Tokenverwendung in mehreren Anwendungen nachverfolgt? Können Verrechnungen für mehrere Anwendungen/Teams berechnet werden, die Azure OpenAI Service-Modelle verwenden?
- Wie können Sie sicherstellen, dass eine einzelne App nicht das gesamte TPM-Kontingent nutzt und andere Apps deshalb keine Azure OpenAI Service-Modelle verwenden können?
- Wie wird der API-Schlüssel sicher auf mehrere Anwendungen verteilt?
- Wie wird die Last auf mehrere Azure OpenAI-Endpunkte verteilt? Können Sie sicherstellen, dass die zugesicherte Kapazität in PTUs aufgebraucht ist, bevor auf Instanzen mit nutzungsbasierter Bezahlung zurückgegriffen wird?
Im Rest dieses Artikels erfahren Sie, wie Azure API Management Ihnen dabei helfen kann, diese Herausforderungen zu bewältigen.
Importieren einer Azure OpenAI Service-Ressource als API
Importieren Sie eine API aus einem Azure OpenAI Service-Endpunkt mit nur einem Klick in Azure API Management. API Management optimiert den Onboardingprozess durch automatisches Importieren des OpenAPI-Schemas für die Azure OpenAI-API und richtet die Authentifizierung für den Azure OpenAI-Endpunkt mittels verwalteter Identität ein, sodass keine manuelle Konfiguration mehr erforderlich ist. Innerhalb der gleichen benutzerfreundlichen Umgebung können Sie Richtlinien für Tokengrenzwerte und für die Ausgabe von Tokenmetriken vorkonfigurieren.

Tokengrenzwertrichtlinie
Konfigurieren Sie die Azure OpenAI-Tokengrenzwertrichtlinie, um Grenzwerte pro API-Consumer basierend auf der Verwendung von Azure OpenAI Service-Token zu verwalten und zu erzwingen. Mit dieser Richtlinie können Sie in Token pro Minute (TPM) ausgedrückte Grenzwerte festlegen.
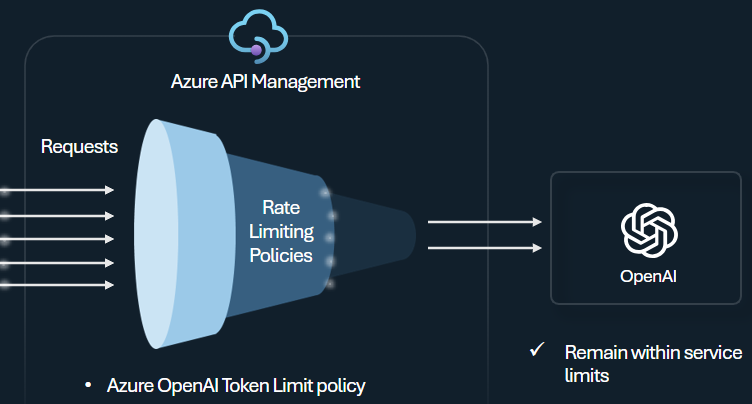
Mit dieser Richtlinie können tokenbasierte Grenzwerte flexibel für einen beliebigen Zählerschlüssel zugewiesen werden. Hierzu zählen z. B. Abonnementschlüssel, Ursprungs-IP-Adresse oder ein beliebiger Schlüssel, der über einen Richtlinienausdruck definiert ist. Die Richtlinie ermöglicht auch die Vorausberechnung von Prompttoken aufseiten von API Management, wodurch unnötige Anforderungen an das Azure OpenAI Service-Back-End minimiert werden, wenn der Prompt den Grenzwert bereits überschreitet.
Das folgende einfache Beispiel veranschaulicht, wie ein TPM-Grenzwert von 500 pro Abonnementschlüssel festgelegt wird:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Tipp
Für die Verwaltung und Erzwingung von Tokengrenzwerten für LLM-APIs, die über die Azure KI-Modellrückschluss-API verfügbar sind, stellt API Management die entsprechende Richtlinie llm-token-limit bereit.
Richtlinie zum Ausgeben von Tokenmetriken
Die Azure OpenAI-Richtlinie zum Ausgeben von Tokenmetriken sendet Metriken zum Verbrauch von LLM-Token über Azure OpenAI Service-APIs an Application Insights. Die Richtlinie hilft Ihnen dabei, sich einen Überblick über die Nutzung von Azure OpenAI Service-Modellen durch mehrere Anwendungen oder API-Consumer zu verschaffen. Diese Richtlinie kann für Szenarien mit verbrauchsbasierter Kostenzuteilung sowie für die Überwachung und Kapazitätsplanung nützlich sein.
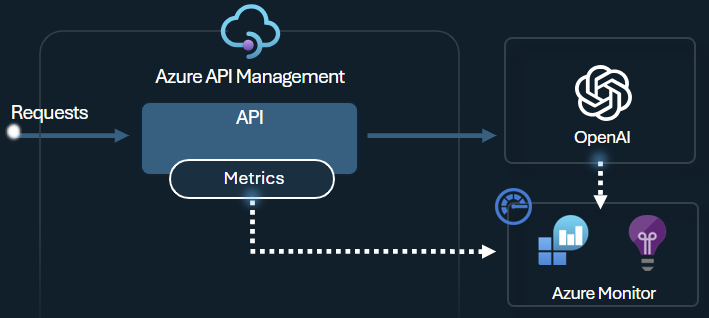
Diese Richtlinie erfasst Metriken zu Prompts und Vervollständigungen sowie zur Gesamttokennutzung und sendet sie an einen Application Insights-Namespace Ihrer Wahl. Darüber hinaus können Sie Dimensionen konfigurieren oder aus vordefinierten Dimensionen auswählen, um Tokennutzungsmetriken aufzuteilen, sodass Sie Metriken nach Abonnement-ID, IP-Adresse oder einer benutzerdefinierten Dimension Ihrer Wahl analysieren können.
Die folgende Richtlinie sendet beispielsweise Metriken an Application Insights, die nach Client-IP-Adresse, API und Benutzer aufgeteilt sind:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Tipp
Um Metriken für LLM-APIs zu senden, die über die Azure KI-Modellrückschluss-API verfügbar sind, stellt API Management die entsprechende Richtlinie llm-emit-token-metric bereit.
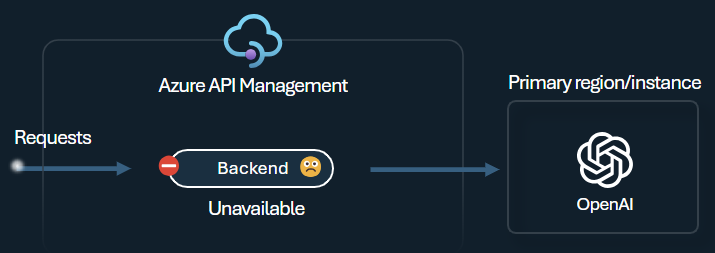
Back-End-Lastenausgleich und Trennschalter
Eine der Herausforderungen beim Erstellen intelligenter Anwendungen besteht darin, dafür zu sorgen, dass die Anwendungen gegenüber Back-End-Fehlern resilient sind und mit hoher Last zurechtkommen. Sie können die Last auf Back-Ends verteilen, indem Sie Ihre Azure OpenAI Service-Endpunkte mit Back-Ends in Azure API Management konfigurieren. Außerdem können Sie Trennschalterregeln definieren, damit keine Anforderungen mehr an die Azure OpenAI Service-Back-Ends weitergeleitet werden, wenn diese nicht reagieren.
Der Lastenausgleich des Back-Ends unterstützt Roundrobin-basierten, gewichteten und prioritätsbasierten Lastenausgleich, sodass Sie flexibel eine Lastenverteilungsstrategie definieren können, die Ihren spezifischen Anforderungen gerecht wird. Definieren Sie beispielsweise Prioritäten innerhalb der Lastenausgleichskonfiguration, um eine optimale Nutzung bestimmter Azure OpenAI-Endpunkte zu gewährleisten – insbesondere derjenigen, die als PTUs erworben wurden.
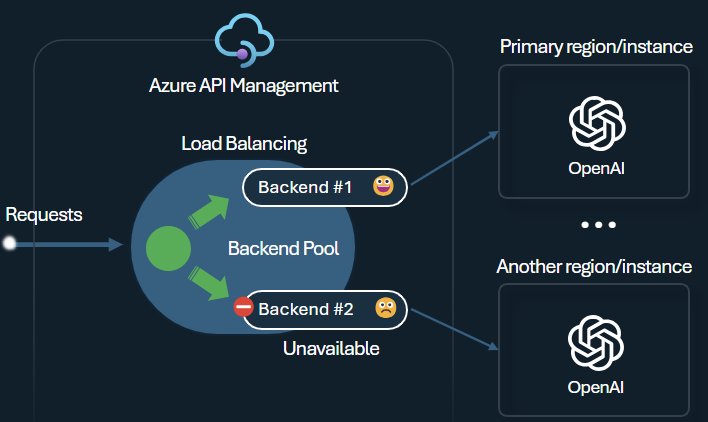
Der Trennschalter des Back-Ends bietet eine dynamische Tripdauer. Dabei werden Werte aus dem vom Back-End bereitgestellten Retry-After-Header angewendet. Dadurch wird eine präzise und zeitnahe Wiederherstellung der Back-Ends sichergestellt und die Nutzung Ihrer priorisierten Back-Ends maximiert.
Richtlinie für die semantische Zwischenspeicherung
Konfigurieren Sie Azure OpenAI-Richtlinien für die semantische Zwischenspeicherung, um die Tokennutzung durch Speicherung von Vervollständigungen für ähnliche Prompts zu optimieren.
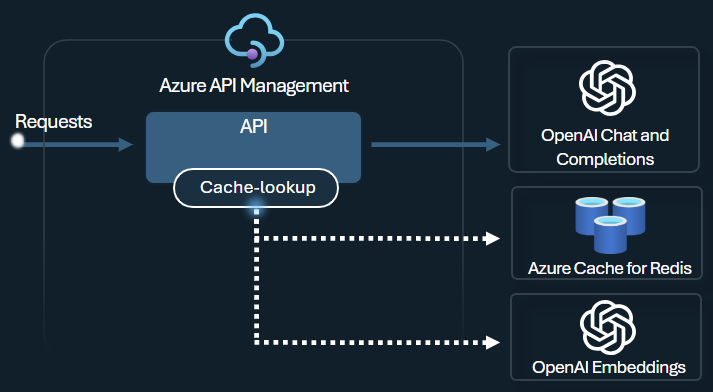
Aktivieren Sie in API Management die semantische Zwischenspeicherung unter Verwendung von Azure Redis Enterprise oder unter Verwendung eines anderen externen Cache, der mit RediSearch kompatibel und in Azure API Management integriert ist. Durch Verwendung der Einbettungs-API von Azure OpenAI Service werden semantisch ähnliche Promptvervollständigungen durch die Richtlinien azure-openai-semantic-cache-store und azure-openai-semantic-cache-lookup gespeichert und aus dem Cache abgerufen. Dieser Ansatz gewährleistet die Wiederverwendung von Vervollständigungen, was die Tokennutzung reduziert und die Reaktionsleistung verbessert.
Tipp
Für die Aktivierung der semantischen Zwischenspeicherung für LLM-APIs, die über die Azure KI-Modellrückschluss-API verfügbar sind, stellt API Management die entsprechenden Richtlinien llm-semantic-cache-store-policy und llm-semantic-cache-lookup-policy bereit.
Labs und Beispiele
- Labs für die GenAI-Gatewayfunktionen von Azure API Management
- Azure API Management (APIM): Azure OpenAI-Beispiel (Node.js)
- Python-Beispielcode für die Verwendung von Azure OpenAI mit API Management
Architektur- und Entwurfsaspekte
- GenAI-Gatewayreferenzarchitektur mit Verwendung von API Management
- Beschleuniger für KI-Hub-Gatewayzielzone
- Entwerfen und Implementieren einer Gatewaylösung mit Azure OpenAI-Ressourcen
- Verwenden eines vor mehreren Azure OpenAI-Bereitstellungen oder -Instanzen hinzugefügten Gateways
Zugehöriger Inhalt
- Blog: Einführung von GenAI-Gatewayfunktionen in Azure API Management
- Blog: Integrieren von Azure-Inhaltssicherheit in API Management für Azure OpenAI-Endpunkte
- Training: Verwalten Ihrer generativen KI-APIs mit Azure API Management
- intelligenter Lastenausgleich für OpenAI-Endpunkte und Azure API Management
- Authentifizieren und Autorisieren des Zugriffs auf Azure OpenAI-APIs mithilfe von Azure API Management