Was ist Container Network Observability?
Container Network Observability ist eine Funktion der Suite Erweiterte Container-Netzwerkdienste. Sie stattet Sie mit Überwachungs- und Diagnosetools der nächsten Generation aus, die Ihnen einen unvergleichlichen Einblick in Ihre containerisierten Workloads geben. Mit diesen Tools können Sie Netzwerkprobleme leicht erkennen und beheben und so die optimale Leistung Ihrer Anwendungen sicherstellen.
Container Network Observability ist mit allen Linux-Workloads kompatibel und lässt sich nahtlos in Hubble integrieren, unabhängig davon, ob die zugrunde liegende Datenebene von Cilium oder einem anderen Hersteller stammt (beide werden unterstützt), wodurch Flexibilität für Ihre Container-Netzwerkanforderungen gewährleistet ist.
Hinweis
Für Cilium-Datenebenenszenarien ist Container Network Observability ab Kubernetes Version 1.29 verfügbar. Container Network Observability wird auf allen Linux-Distributionen einschließlich Azure Linux ab Version 2.0 unterstützt.
Features der Container Network Observability
Container Network Observability bietet die folgenden Funktionen zur Überwachung von netzwerkbezogenen Problemen in Ihrem Cluster:
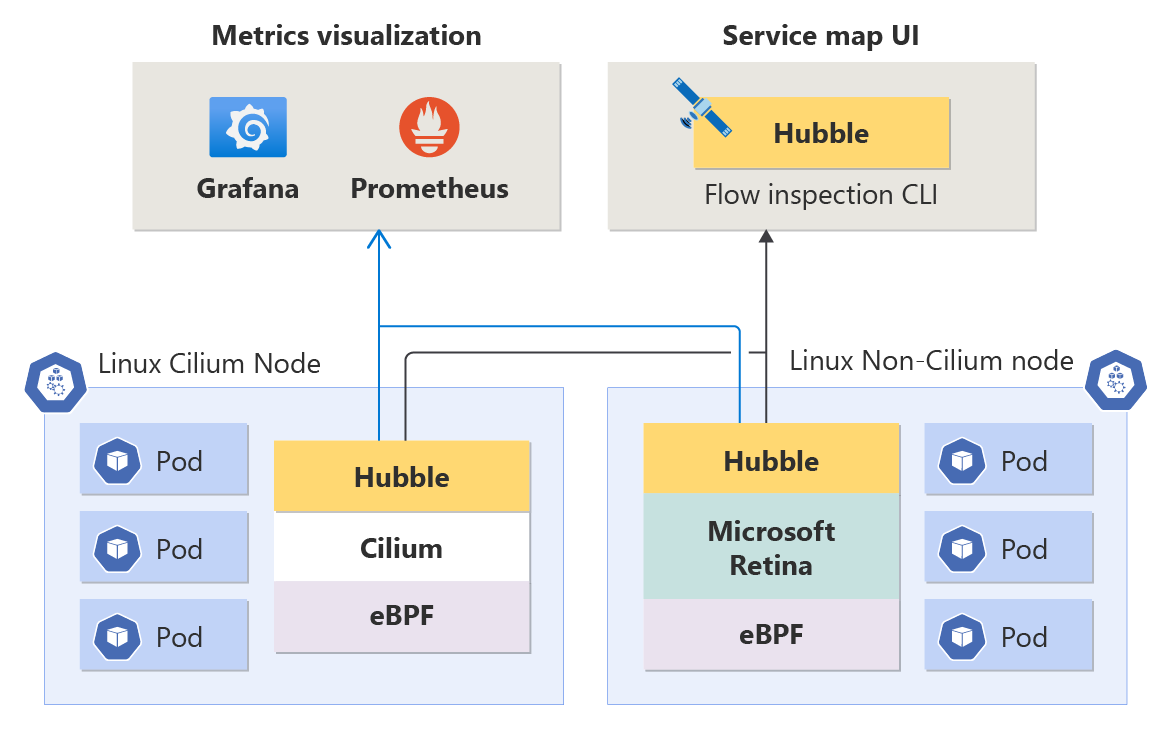
Metriken auf Knotenebene: Das Verständnis des Zustands Ihres Container-Netzwerks auf Knotenebene ist entscheidend für die Aufrechterhaltung einer optimalen Anwendungsleistung. Diese Metriken bieten Einblicke in das Datenverkehrsvolumen, verworfene Pakete, die Anzahl der Verbindungen usw. nach Knoten. Die Metriken werden im Prometheus-Format gespeichert und können daher in Grafana angezeigt werden.
Hubble-Metriken (Metriken auf DNS- und Pod-Ebene): Diese Prometheus-Metriken enthalten Quell- und Zielpodinformationen, die es Ihnen ermöglichen, netzwerkbezogene Probleme auf granularer Ebene zu identifizieren. Die Metriken decken das Datenverkehrsvolumen, verworfene Pakete, TCP-Zurücksetzungen, L4/L7-Paketflüsse usw. ab. Es gibt auch DNS-Metriken (derzeit nur für Nicht-Cilium-Datenebenen), die DNS-Fehler und fehlende Antworten auf DNS-Anforderungen erfassen.
Hubble-Datenflussprotokolle: Datenflussprotokolle bieten umfassende Einblicke in die Netzwerkaktivität Ihres Clusters. Sämtliche Kommunikation an und von Pods wird protokolliert, sodass Sie Konnektivitätsprobleme im Laufe der Zeit untersuchen können. Datenflussprotokolle helfen bei der Beantwortung von Fragen wie: Hat der Server die Anforderung des Clients erhalten? Was ist die Roundtrip-Wartezeit zwischen der Anforderung des Clients und der Serverantwort?
Hubble CLI: Die Hubble-Befehlszeilenschnittstelle (CLI) kann Datenflussprotokolle für den gesamten Cluster mit anpassbarer Filterung und Formatierung abrufen.
Hubble UI: Hubble UI ist eine benutzerfreundliche browserbasierte Benutzeroberfläche zum Untersuchen von Clusternetzwerkaktivitäten. Sie erstellt ein Dienstverbindungsdiagramm basierend auf Datenflussprotokollen und zeigt Datenflussprotokolle für den ausgewählten Namespace an. Benutzer sind für die Bereitstellung und Verwaltung der Infrastruktur verantwortlich, die zum Ausführen von Hubble UI erforderlich ist.
Hauptvorteile der Container Network Observability
CNI-agnostisch: Unterstützt alle Azure CNI-Varianten einschließlich kubenet.
Cilium und Nicht-Cilium: Bietet eine einheitliche, nahtlose Erfahrung sowohl für Cilium- als auch für Nicht-Cilium-Datenebenen.
eBPF-basierter Netzwerkeinblick: Nutzt eBPF (erweiterter Berkeley Packet Filter) für Leistung und Skalierbarkeit, um potenzielle Engpässe und Überlastungsprobleme zu erkennen, bevor sie die Anwendungsleistung beeinträchtigen. Erhalten Sie Einblicke in wichtige Netzwerkintegritätsindikatoren, einschließlich Datenverkehrsvolumen, verworfene Pakete und Verbindungsinformationen.
Tiefer Einblick in die Netzwerkaktivität: Verstehen Sie anhand detaillierter Netzwerk-Datenflussprotokolle, wie Ihre Anwendungen miteinander kommunizieren.
Vereinfachte Optionen für die Speicherung und Visualisierung von Metriken: Wählen Sie zwischen:
- Azure Managed Prometheus und Grafana: Azure verwaltet die Infrastruktur und die Wartung, sodass sich Benutzer auf die Konfiguration von Metriken und die Visualisierung von Metriken konzentrieren können.
- Verwendung eigener Prometheus- und Grafana-Instanzen: Benutzer stellen ihre eigenen Instanzen bereit, konfigurieren sie und verwalten die zugrunde liegende Infrastruktur.
Metriken
Metriken auf Knotenebene
Die folgenden Metriken werden pro Knoten aggregiert. Alle Metriken enthalten Bezeichnungen:
clusterinstance(Knotenname)
Für Cilium-Datenebenenszenarien bietet Container Network Observability Metriken nur für Linux, Windows wird derzeit nicht unterstützt. Cilium stellt mehrere Metriken zur Verfügung, darunter die folgenden, die von Container Network Observability verwendet werden.
| Metrikname | Beschreibung | Zusätzliche Bezeichnungen | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Gesamtzahl der weitergeleiteten Pakete | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Gesamtanzahl weitergeleiteter Byte | direction |
✅ | ❌ |
| cilium_drop_count_total | Gesamtzahl der gelöschten Pakete | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Gesamtanzahl der gelöschten Byte | direction, reason |
✅ | ❌ |
Metriken auf Podebene (Hubble-Metriken)
Die folgenden Metriken werden pro Pod aggregiert (Knoteninformationen bleiben erhalten). Alle Metriken enthalten Bezeichnungen:
clusterinstance(Knotenname)sourceoderdestination
Für ausgehenden Datenverkehr gibt es eine source-Bezeichnung mit dem Namespace/Namen des Quellpods.
Für eingehenden Datenverkehr gibt es eine destination-Bezeichnung mit dem Namespace/Namen des Zielpods.
| Metrikname | Beschreibung | Zusätzliche Bezeichnungen | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Gesamtanzahl der DNS-Anforderungen nach Abfrage | source oder destination, query, qtypes (Abfragetyp) |
✅ | ❌ |
| hubble_dns_responses_total | Gesamtanzahl der DNS-Antworten nach Abfrage/Antwort | source oder destination, query, qtypes (Abfragetyp), rcode (Rückgabecode), ips_returned (Anzahl der IPs) |
✅ | ❌ |
| hubble_drop_total | Gesamtzahl der gelöschten Pakete | source oder destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Gesamtzahl der TCP-Pakete nach Flag. | source oder destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Verarbeitete Netzwerkdatenflüsse insgesamt (L4/L7-Datenverkehr) | source oder destination, protocol, verdict, type, subtype |
✅ | ❌ |
Begrenzungen
- Metriken auf Podebene sind nur unter Linux verfügbar.
- Die Cilium-Datenebene wird ab Kubernetes Version 1.29 unterstützt.
- Metrikbezeichnungen können subtile Unterschiede zwischen Cilium- und Nicht-Cilium-Clustern aufweisen.
- Für Cilium-basierte Cluster sind DNS-Metriken nur für Pods verfügbar, die Cilium-Netzwerkrichtlinien (Cilium Network Policy, CNP) auf ihren Clustern konfiguriert haben.
- Ablaufprotokolle sind derzeit in der Cloud mit Air Gap nicht verfügbar.
- Hubble-Relay kann abstürzen, wenn einer der Hubble-Knoten-Agents abstürzt, und es kann zu Unterbrechungen bei der Hubble-CLI führen.
Skalieren
Für von Azure verwaltete Prometheus- und Grafana-Instanzen gelten dienstspezifische Skalierungseinschränkungen. Weitere Informationen finden Sie unter Scrape Prometheus-Metriken im großen Stil in Azure Monitor.
Preise
Wichtig
Die erweiterten Container-Netzwerkdienste werden in Zukunft ein kostenpflichtiges Angebot sein. Weitere Informationen zu den Preisen finden Sie unter Erweiterte Container-Netzwerkdienste – Preise.
Nächste Schritte
- Informationen zum Erstellen eines AKS-Clusters mit Container Network Observability finden Sie unter Einrichten der Container Network Observability für Azure Kubernetes Service (AKS).

Azure Kubernetes Service