Tutorial: Teil 3: Auswerten einer benutzerdefinierte Chatanwendung mit dem Azure KI Foundry SDK
In diesem Tutorial verwenden Sie das Azure KI SDK (und andere Bibliotheken), um die in Teil 2 der Tutorialreihe erstellte Chat-App auszuwerten. In diesem dritten Teil wird Folgendes vermittelt:
- Erstellen eines Bewertungsdatasets
- Auswerten der Chat-App mit Azure KI-Evaluatoren
- Iterieren und Verbessern Ihrer App
Dieses Tutorial ist der dritte Teil eines dreiteiligen Tutorials.
Voraussetzungen
- Schließen Sie Teil 2 der Tutorialreihe ab, um die Chat-App zu erstellen.
- Vergewissern Sie sich, dass Sie die Schritte zum Hinzufügen der Telemetrieprotokollierung aus Teil 2 abgeschlossen haben.
Auswerten der Qualität der Chat-App-Antworten
Da Sie nun wissen, dass Ihre Chat-App gut auf Ihre Abfragen reagiert (auch mit dem Chatverlauf), ist es an der Zeit, ihre Leistung anhand einiger verschiedener Metriken und weiterer Daten zu bewerten.
Sie verwenden einen Evaluator mit einem Auswertungsdataset und der Zielfunktion get_chat_response() und bewerten dann die Auswertungsergebnisse.
Nachdem Sie eine Auswertung ausgeführt haben, können Sie Verbesserungen an der Logik vornehmen und beispielsweise den System-Prompt verbessern und beobachten, wie sich die Antworten der Chat-App ändern und verbessern.
Erstellen des Evaluierungsdatasets
Verwenden Sie das folgende Auswertungsdataset, das Beispielfragen und erwartete Antworten (Wahrheit) enthält.
Erstellen Sie eine Datei namens chat_eval_data.jsonl in Ihrem Ordner Assets.
Fügen Sie dieses Dataset in die Datei ein:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Auswerten mit Azure KI-Evaluators
Definieren Sie nun ein Auswertungsskript, mit dem die folgenden Schritte ausgeführt werden:
- Generieren wir einen Zielfunktionswrappers um unsere Chat-App-Logik.
- Laden des
.jsonl-Beispieldatasets - Ausführen der Auswertung, bei der die Zielfunktion übernommen und das Auswertungsdataset mit den Antworten der Chat-App zusammengeführt wird
- Generieren verschiedener GPT-unterstützter Metriken (Relevanz, Fundiertheit und Kohärenz) zum Auswerten der Qualität der Chat-App-Antworten.
- Lokales Ausgeben der Ergebnisse und Protokollieren der Ergebnisse im Cloudprojekt
Mit dem Skript können Sie die Ergebnisse lokal überprüfen, indem Sie die Ergebnisse in der Befehlszeile und in einer JSON-Datei ausgeben.
Das Skript protokolliert außerdem die Auswertungsergebnisse im Cloudprojekt, sodass Sie die Auswertungsausführungen auf der Benutzeroberfläche vergleichen können.
Erstellen Sie im Hauptordner eine Datei namens evaluate.py.
Fügen Sie folgenden Code hinzu, um die erforderlichen Bibliotheken zu importieren, einen Projektclient zu erstellen und einige Einstellungen zu konfigurieren:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Fügen Sie Code hinzu, um eine Wrapperfunktion zu erstellen, die die Auswertungsschnittstelle für die Abfrage- und Antwortauswertung implementiert:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Fügen Sie zuletzt Code zum Ausführen der Auswertung hinzu, und zeigen Sie die Ergebnisse lokal an. Sie erhalten einen Link zu den Auswertungsergebnissen im Azure KI Foundry-Portal:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Konfigurieren des Auswertungsmodells
Da das Auswertungsskript das Modell mehrmals aufruft, sollten Sie die Anzahl der Token pro Minute für das Auswertungsmodell erhöhen.
In Teil 1 dieser Tutorialreihe haben Sie eine .env-Datei erstellt, die den Namen des Auswertungsmodells angibt: gpt-4o-mini. Versuchen Sie, die Token pro Minute für dieses Modell zu erhöhen, wenn Sie über ein verfügbares Kontingent verfügen. Wenn Sie nicht über genügend Kontingent verfügen, um den Wert zu erhöhen, macht das nichts. Das Skript wurde entwickelt, um Fehler zu begrenzen.
- Wählen Sie in Ihrem Projekt im Azure KI Foundry-Portal Modelle und Endpunkte aus.
- Wählen Sie GPT-4o mini aus.
- Wählen Sie Bearbeiten aus.
- Wenn Sie ein Kontingent haben, um das Ratenlimit für Token pro Minute zu erhöhen, versuchen Sie, es auf 30 zu erhöhen.
- Wählen Sie Speichern und schließen aus.
Ausführen des Auswertungsskripts
Melden Sie sich in der Konsole mit der Azure CLI bei Ihrem Azure-Konto an:
az loginInstallieren Sie das erforderliche Paket:
pip install azure-ai-evaluation[remote]Führen Sie nun das Auswertungsskript aus:
python evaluate.py
Interpretieren der Auswertungsausgabe
In der Konsolenausgabe wird für jede Frage eine Antwort angezeigt, gefolgt von einer Tabelle mit zusammengefassten Metriken. (Möglicherweise werden in Ihrer Ausgabe andere Spalten angezeigt.)
Wenn Sie die Token pro Minute für Ihr Modell nicht erhöhen konnten, werden möglicherweise einige Timeoutfehler angezeigt. Dies ist ein zu erwartendes Verhalten. Das Auswertungsskript wurde entwickelt, um diese Fehler zu behandeln und die Ausführung fortzusetzen.
Hinweis
Möglicherweise werden auch viele WARNING:opentelemetry.attributes: angezeigt: Diese können ignoriert werden und wirken sich nicht auf die Auswertungsergebnisse aus.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Anzeigen von Auswertungsergebnissen im Azure KI Foundry-Portal
Folgen Sie nach dem Abschluss der Auswertung dem Link, um die Auswertungsergebnisse auf der Seite Auswertung im Azure KI Foundry-Portal anzuzeigen.
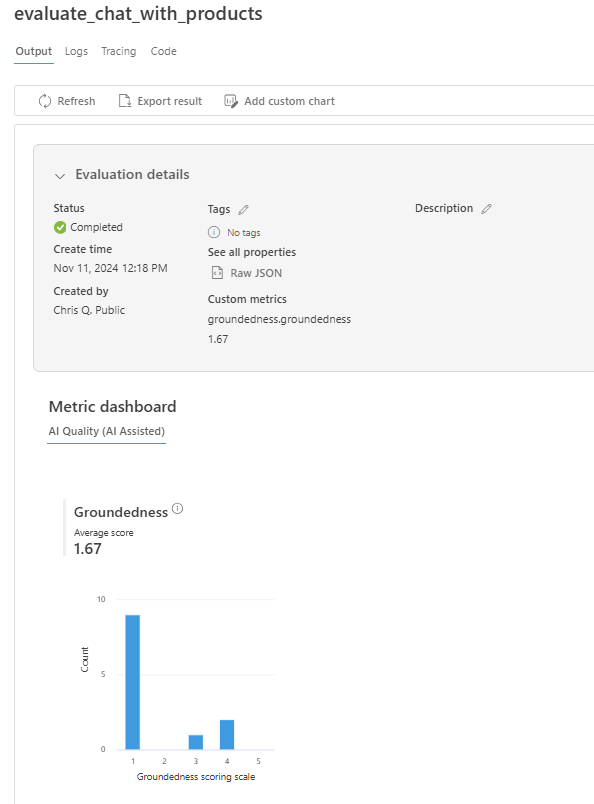
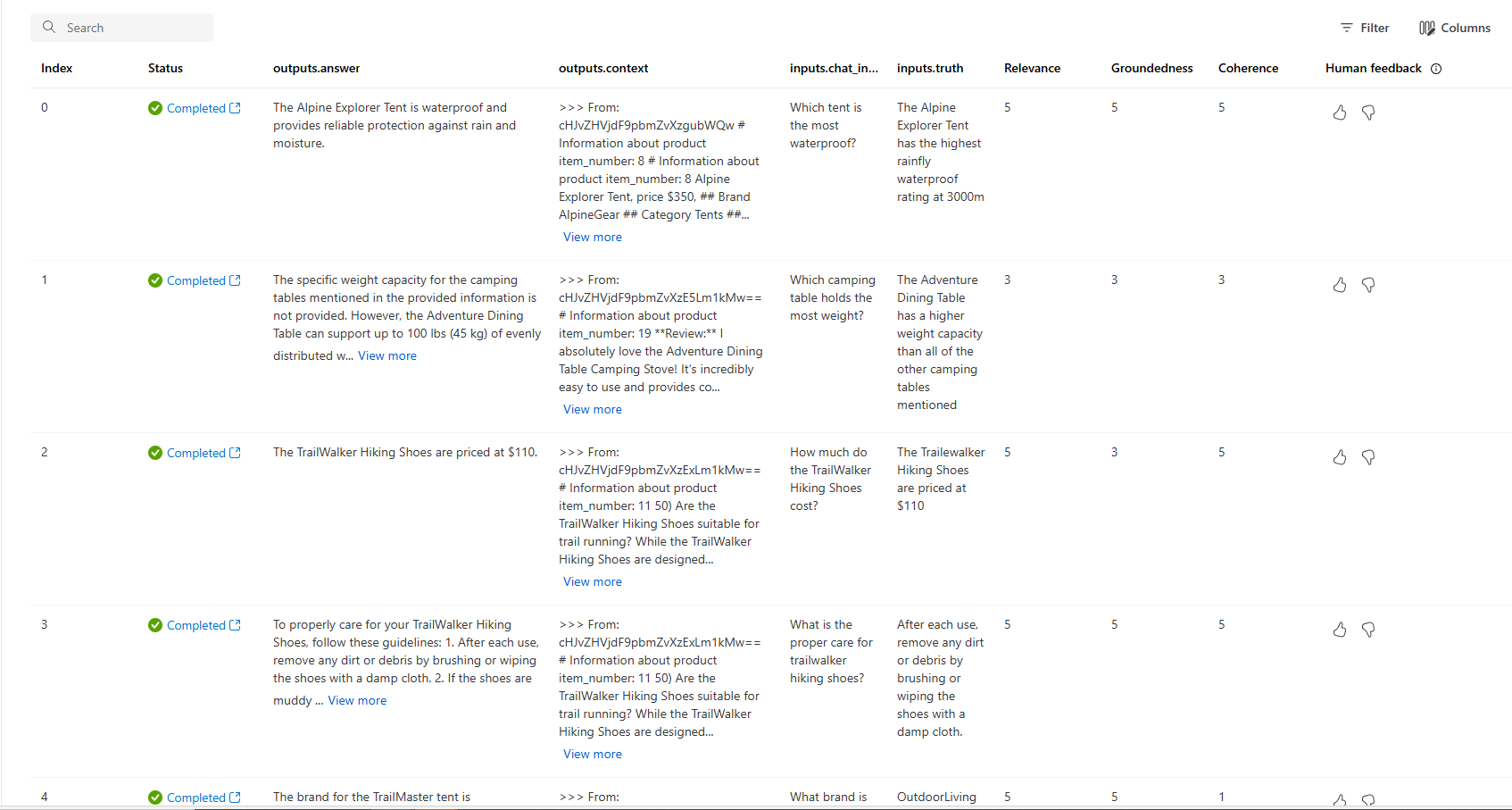
Sie können sich auch die einzelnen Zeilen ansehen und Metrikergebnisse pro Zeile sowie den vollständigen Kontext/die Dokumente anzeigen, die abgerufen wurden. Diese Metriken können beim Interpretieren und Debuggen von Auswertungsergebnissen hilfreich sein.
Weitere Informationen zu Auswertungsergebnissen im Azure KI Foundry-Portal finden Sie unter Anzeigen von Auswertungsergebnissen im Azure KI Foundry-Portal.
Iterieren und Verbessern
Beachten Sie, dass die Antworten nicht gut fundiert sind. In vielen Fällen antwortet das Modell nicht mit einer Antwort, sondern mit einer Frage. Dies ist ein Ergebnis der Anweisungen der Promptvorlage.
- Suchen Sie in Ihrer Datei assets/grounded_chat.prompty den Satz „Wenn die Frage im Zusammenhang mit Outdoor-/Campingausrüstung und Kleidung steht, aber vage ist, stellen Sie klärende Fragen, anstatt auf Dokumente zu verweisen.“
- Ändern Sie den Satz in „Wenn die Frage im Zusammenhang mit Outdoor-/Campingausrüstung und Kleidung steht, aber vage ist, versuchen Sie, basierend auf den Referenzdokumenten zu antworten, und stellen Sie dann klärende Fragen."
- Speichern Sie die Datei, und führen Sie das Bewertungsskript erneut aus.
Testen Sie andere Änderungen an der Promptvorlage, oder testen Sie andere Modelle, um zu sehen, wie sich die Änderungen auf die Bewertungsergebnisse auswirken.
Bereinigen von Ressourcen
Um unnötige Azure-Kosten zu vermeiden, sollten Sie die in diesem Tutorial erstellten Ressourcen löschen, wenn sie nicht mehr benötigt werden. Zum Verwalten von Ressourcen können Sie das Azure-Portal verwenden.