Erstellen eines benutzerdefinierten Text-zu-Sprache-Avatars
Die ersten Schritte mit einem benutzerdefinierten Sprachsynthese-Avatar sind ein einfacher Prozess. Alles, was Sie brauchen, sind ein paar Videoclips Ihres Schauspielers. Wenn Sie eine benutzerdefinierte Stimme für denselben Akteur trainieren möchten, können Sie dies separat tun.
Hinweis
Der Zugriff auf den benutzerdefinierten Avatar ist auf der Grundlage von Berechtigungs- und Nutzungskriterien begrenzt. Fordern Sie den Zugriff über das Aufnahmeformular an.
Voraussetzungen
Sie benötigen eine Sprachrekrennungsressource in einer der Regionen, die die Schulung benutzerdefinierter Avatare unterstützen. Der benutzerdefinierte Avatar unterstützt nur standardmäßige (S0) Spracherkennungsressourcen.
Sie benötigen eine Videoaufnahme, in der das Talent eine Einverständniserklärung zur Nutzung seines Bildes und seiner Stimme vorliest. Sie laden dieses Video hoch, wenn Sie den Avatarsprecher einrichten. Weitere Informationen finden Sie unter Avatarsprechereinwilligung hinzufügen.
Sie benötigen Videoaufzeichnungen Ihres Avatarsprechers als Schulungsdaten. Sie laden diese Videos hoch, wenn Sie Schulungsdaten vorbereiten. Weitere Informationen finden Sie unter Hinzufügen von Schulungsdaten.
Schritt 1: Erstellen eines Projekts für einen benutzerdefinierten Avatar
Befolgen Sie diese Schritte, um ein Projekt für einen benutzerdefinierten Avatar zu erstellen:
Melden Sie sich beim Speech Studio an, und wählen Sie Ihre Abonnement- und Spracherkennungsressource aus.
Wählen Sie Benutzerdefinierter Avatar (Vorschau) aus.

Wählen Sie +Projekt erstellen.
Folgen Sie den Anweisungen des Assistenten, um Ihr Projekt zu erstellen.
Tipp
Mischen Sie nicht die Daten für verschiedene Avatare in einem Projekt. Erstellen Sie immer ein neues Projekt für einen neuen Avatar.
Wählen Sie das neue Projekt nach Namen aus. Im linken Bereich werden dann die folgenden Menüelemente angezeigt: Avatar einrichten, Trainingsdaten vorbereiten, Modell trainieren und Modell bereitstellen.


Schritt 2: Hinzufügen der Einwilligung des Avatarsprechers
Ein Avatar-Talent ist ein Einzelner oder Zieldarsteller, dessen Video aufgezeichnet und verwendet wird, um neurale Avatarmodelle zu erstellen. Sie müssen nach allen relevanten Gesetzen und Vorschriften des Avatar-Talents ausreichende Zustimmung einholen, um ihr Video zu verwenden, um den benutzerdefinierten Text für den Sprachavatar zu erstellen.
Sie müssen eine Videodatei mit einer aufgezeichneten Aussage ihres Avatar-Talents bereitstellen und die Verwendung ihres Bilds und ihrer Stimme anerkennen. Microsoft überprüft, ob der Inhalt in der Aufzeichnung mit dem von Microsoft bereitgestellten vordefinierten Skript übereinstimmt. Microsoft vergleicht das Gesicht des Avatar-Talents in der aufgezeichneten Videoanweisungsdatei mit randomisierten Videos aus den Schulungsdatensätzen, um sicherzustellen, dass das Avatar-Talent in Videoaufzeichnungen und das Avatar-Talent in der Videodatei der Anweisung von derselben Person stammen.
Die mündliche Einwilligungserklärung ist in mehreren Sprachen über das GitHub-Repository Azure-Samples/cognitive-services-speech-sdk verfügbar. Die Sprache der verbalen Anweisung muss mit Ihrer Aufzeichnung identisch sein. Siehe auch die Offenlegung für Sprecher.
Weitere Informationen zum Aufzeichnen des Einwilligungsvideos finden Sie unter Aufzeichnen von Videobeispielen.
Führen Sie die folgenden Schritte aus, um ein Avatarsprecherprofil hinzuzufügen und ihre Einwilligungserklärung in Ihr Projekt hochzuladen:
Melden Sie sich in Speech Studio an.
Wählen Sie Benutzerdefinierter Avatar> Name Ihres Projekts>Avatarsprecher einrichten>Einwilligungsvideo hochladen.
Folgen Sie auf der Seite Einwilligungsvideo hochladen den Anweisungen, um das Video der Avatarsprechereinwilligung hochzuladen, das Sie zuvor aufgezeichnet haben.
- Wählen Sie die Sprache der mündlichen Einwilligungserklärung aus, die vom Avatarsprecher aufgezeichnet wurde.
- Geben Sie den Avatarsprechernamen und Ihren Firmennamen in derselben Sprache wie die aufgezeichnete Anweisung ein.
- Der Name des Avatarsprechers muss der Name der Person sein, die die Einwilligungserklärung aufgezeichnet hat.
- Der Firmenname muss mit dem Firmennamen übereinstimmen, der in der aufgezeichneten Erklärung gesprochen wurde.
- Sie können Ihre Daten aus lokalen Dateien oder aus einem freigegebenen Speicher mit Azure Blob hochladen.
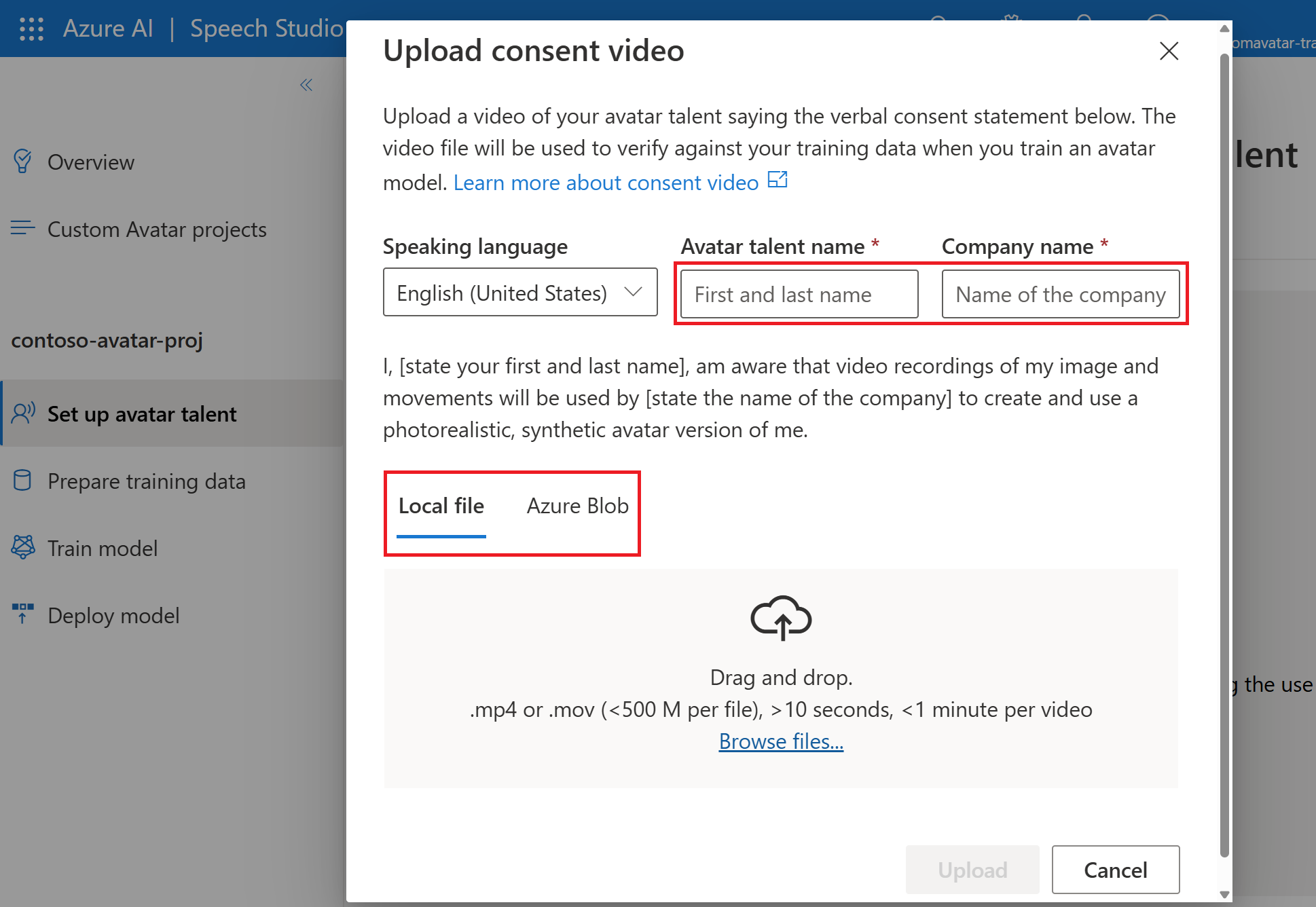
Wählen Sie die Option Hochladen.

Nachdem der Upload der Avatarsprechereinwilligung erfolgreich war, können Sie ihr benutzerdefiniertes Avatarmodell trainieren.
Schritt 3: Hinzufügen von Schulungsdaten
Der Spracherkennungsdienst verwendet Ihre Schulungsdaten, um einen einzigartigen Avatar zu erstellen, der dem Aussehen der Person in den Aufzeichnungen entspricht. Nachdem Sie das Avatarmodell trainiert haben, können Sie mit der Synthesierung von Avatarvideos beginnen oder sie für Livechats in Ihren Anwendungen verwenden.
Alle Daten, die Sie hochladen, müssen die Anforderungen für den ausgewählten Datentyp erfüllen. Um sicherzustellen, dass der Spracherkennungsdienst Ihre Daten genau verarbeitet, ist es wichtig, Ihre Daten vor dem Upload korrekt zu formatieren. Informationen zum Bestätigen, dass Ihre Daten korrekt formatiert sind, finden Sie unter Datenanforderungen.
Hochladen Ihrer Daten
Wenn Sie bereit sind, Ihre Daten hochzuladen, wechseln Sie zur Registerkarte zum Vorbereiten von Trainingsdaten, um Ihre Daten hochzuladen.
Führen Sie die folgenden Schritte aus, um Trainingsdaten hochzuladen:
Melden Sie sich in Speech Studio an.
Wählen Sie Benutzerdefinierter Avatar> Ihr Projektname >Trainingsdaten vorbereiten>Daten hochladen aus.
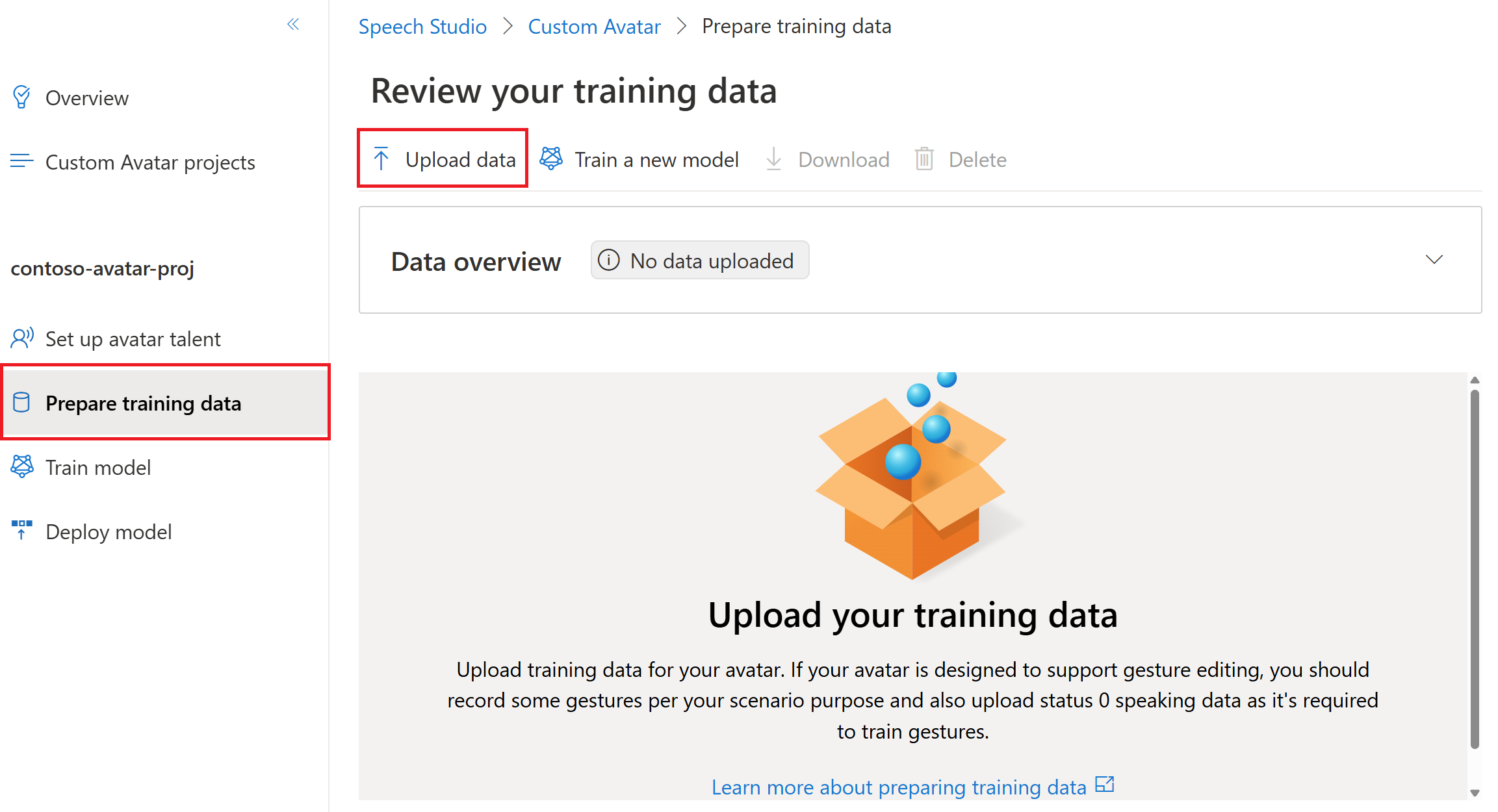
Wählen Sie im Assistenten zum Hochladen von Daten einen Datentyp aus, und wählen Sie dann Weiter aus. Weitere Informationen zu den Datentypen (einschließlich Natürliches Sprechen, Stumm, Gesten und Status 0 Sprechen), finden Sie unter Aufzeichnende Videoclips.
Wählen Sie lokale Dateien von Ihrem Computer aus, oder geben Sie die Azure Blob Storage-URL ein, wo Ihre Daten gespeichert werden.
Wählen Sie Weiter aus.
Überprüfen Sie die Details zum Upload, und wählen Sie Übermitteln aus.

Durch Klicken auf Senden werden die Dateien automatisch überprüft. Bei der Datenüberprüfung werden Format, Größe und Gesamtvolumen der Videodateien geprüft. Beheben Sie ggf. auftretende Fehler, und klicken Sie erneut auf „Senden“.
Nachdem Sie die Daten hochgeladen haben, können Sie die Datenübersicht überprüfen, die anzeigt, ob Sie genügend Daten für den Beginn des Trainings bereitgestellt haben. In diesem Screenshot werden als Beispiel ausreichend Daten für das Training eines Avatars ohne weitere Gesten angezeigt.

Schritt 4: Trainieren Ihres Avatarmodells
Wichtig
Alle Schulungsdaten im Projekt sind in der Schulung enthalten. Die Modellqualität hängt stark von den von Ihnen bereitgestellten Daten ab, und Sie sind für die Videoqualität verantwortlich. Stellen Sie sicher, dass Sie die Schulungsvideos entsprechend dem Leitfaden zum Aufzeichnen von Videobeispielen aufzeichnen.
Führen Sie zum Erstellen eines benutzerdefinierten Avatars in Speech Studio diese Schritte für eine der folgenden Methoden aus:
Melden Sie sich in Speech Studio an.
Wählen Sie Benutzerdefinierter Avatar> Ihr Projektname >Modell trainieren>Modell trainieren.
Geben Sie einen Namen ein, um das Modell zu identifizieren. Wählen Sie den Namen sorgfältig aus. Der Modellname wird als Name des Avatars für Ihre Syntheseanforderung in der SDK- und SSML-Eingabe verwendet. Es sind nur Buchstaben, Ziffern, Bindestriche und Unterstriche zulässig. Verwenden Sie für jedes Modell einen eindeutigen Namen.
Wichtig
Der Name des Avatarmodells muss innerhalb derselben Spracherkennungs- oder KI-Services-Ressource eindeutig sein.
Wählen Sie Trainieren aus, um mit dem Training des Modells zu beginnen.
Die Trainingsdauer hängt von der Menge der verwendeten Daten ab. Das Trainieren eines benutzerdefinierten Avatars dauert normalerweise 20–40 Computestunden. Überprüfen Sie die Preishinweise zur Berechnung von Schulungen.
Kopieren des benutzerdefinierten Avatarmodells in ein anderes Projekt (optional)
Das Training eines benutzerdefinierten Avatars ist aktuell nur in einigen Regionen verfügbar. Nachdem Ihr Avatarmodell in einer unterstützten Region trainiert wurde, können Sie es nach Bedarf in eine Speech-Ressource in einer anderen Region kopieren. Weitere Informationen finden Sie in den Fußnoten der Tabelle Regionen.
So kopieren Sie Ihr benutzerdefiniertes Avatarmodell in ein anderes Projekt:
- Wählen Sie auf der Registerkarte Modell trainieren ein Avatarmodell aus, das Sie kopieren möchten, und klicken Sie dann auf In Projekt kopieren.
- Wählen Sie das Abonnement, die Region, die Spracherkennungsressource und das Projekt aus, in das Sie das Modell kopieren möchten. Sie benötigen eine Sprachressource und ein Projekt in der Zielregion. Gegebenenfalls müssen Sie diese Elemente zunächst erstellen.
- Wählen Sie Übermitteln aus, um das Modell zu kopieren.
Nachdem das Modell kopiert wurde, wird eine Benachrichtigung im Speech Studio angezeigt.
Navigieren Sie zu dem Projekt, in das Sie das Modell kopiert haben, um die Modellkopie bereitzustellen.
Schritt 5: Bereitstellen und Verwenden Ihres Avatarmodells
Nachdem Sie Ihr Avatarmodell erfolgreich erstellt und trainiert haben, stellen Sie es auf Ihrem Endpunkt bereit.
So stellen Sie Ihren Avatar bereit:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Benutzerdefinierter Avatar> Projektname >Modelle bereitstellen aus.
- Wählen Sie Modell bereitstellen und dann ein Modell aus, das Sie bereitstellen möchten.
- Wählen Sie Bereitstellen aus, um die Bereitstellung zu starten.
Wichtig
Wenn ein Modell bereitgestellt wird, zahlen Sie für die kontinuierliche Betriebszeit des Endpunkts, unabhängig von Ihrer Interaktion mit diesem Endpunkt. Überprüfen Sie die Preishinweise, wie die Modellimplementierung belastet wird. Sie können eine Bereitstellung löschen, wenn das Modell nicht verwendet wird, um Kosten zu senken und Ressourcen zu sparen.
Nachdem Sie Ihren benutzerdefinierten Avatar bereitgestellt haben, ist er für die Verwendung in Speech Studio oder über die API verfügbar:
- Der Avatar wird in der Avatarliste des Text-zu-Sprache-Avatars auf Speech Studio angezeigt.
- Der Avatar wird in der Avatarliste des Livechatavatars auf Speech Studio angezeigt.
- Sie können den Avatar aus der SDK- und SSML-Eingabe aufrufen, indem Sie den Namen des Avatarmodells angeben. Weitere Informationen finden Sie in den Avatareigenschaften.
Entfernen einer Bereitstellung
Führen Sie die folgenden Schritte aus, um Ihre Bereitstellung zu entfernen:
- Melden Sie sich in Speech Studio an.
- Navigieren Sie zu Benutzerdefinierter Avatar> Ihr Projektname >Modell bereitstellen.
- Wählen Sie die Bereitstellung auf der Seite Modell bereitstellen aus. Das Modell wird aktiv gehostet, wenn der Status „Erfolgreich“ ist.
- Sie können die Schaltfläche Bereitstellung löschen auswählen und den Löschvorgang bestätigen, um das Hosting zu entfernen.
Tipp
Nachdem eine Bereitstellung entfernt wurde, bezahlen Sie nicht mehr für das Hosting. Das Löschen einer Bereitstellung führt nicht zum Löschen Ihres Modells. Wenn Sie das Modell erneut verwenden möchten, erstellen Sie eine neue Bereitstellung.
Verwenden einer benutzerdefinierten Stimme (optional)
Wenn Sie auch eine benutzerdefinierte neurale Stimme (CNV) für den Akteur erstellen, kann der Avatar sehr realistisch sein. Weitere Informationen finden Sie unter Was ist ein benutzerdefinierter Text-zu-Sprache-Avatar?.
Benutzerdefinierte Stimme und benutzerdefinierter Sprachsyntheseavatar sind separate Features. Sie können Sie gemeinsam oder unabhängig voneinander verwenden.
Wenn Sie eine benutzerdefinierte Stimme erstellt haben und sie zusammen mit dem benutzerdefinierten Avatar verwenden möchten, achten Sie auf die folgenden Punkte:
- Stellen Sie sicher, dass der Custom Voice-Endpunkt in derselben Sprachressource wie der benutzerdefinierte Avatarendpunkt erstellt wird. Lesen Sie bei Bedarf den Abschnitt Trainieren ihres professionellen Sprachmodells, um das Custom Voice-Modell in dieselbe Sprachressource wie den benutzerdefinierten Avatarendpunkt zu kopieren.
- Sie können die Custom Voice-Option in der Stimmenliste der Seite Avatarinhaltsgenerierung und Einstellungen für Livechat-Spracheinstellungen sehen.
- Wenn Sie die Batchsynthese für die Avatar-API verwenden, fügen Sie die Eigenschaft
"customVoices"hinzu, um die Bereitstellungs-ID des Custom Voice-Modells dem Sprachnamen in der Anforderung zuzuordnen. Weitere Informationen finden Sie unter Sprachsyntheseeigenschaften. - Wenn Sie die Echtzeitsynthese für die Avatar-API verwenden, lesen Sie unseren Beispielcode auf GitHub, um die benutzerdefinierte Stimme festzulegen.