Was ist die Unterhaltungstranskription mit Mehrkanal-Diarisierung? (Vorschauversion)
Hinweis
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschau wird ohne Vereinbarung zum Servicelevel bereitgestellt und nicht für Produktionsworkloads empfohlen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Die Unterhaltungstranskription mit Mehrkanal-Diarisierung (Sprecherunterscheidung) ist eine Spracherkennungslösung, die eine Echtzeit- oder asynchrone Transkription einer beliebigen Besprechung ermöglicht. Dieses Feature kombiniert Spracherkennung, Sprecheridentifikation und Satzzuordnung, um zu bestimmen, wer was und wann in einer Besprechung gesagt hat.
Wichtig
Die Unterhaltungstranskription mit Mehrkanal-Diarisierung (Vorschau) wird am 28. März 2025 eingestellt. Weitere Informationen zum Migrieren zu anderen Spracherkennungsfeatures finden Sie unter Migrieren von Unterhaltungstranskription mit Mehrkanal-Diarisierung.
Migrieren von der Unterhaltungstranskription mit Mehrkanal-Diarisierung
Die Unterhaltungstranskription mit Mehrkanal-Diarisierung (Vorschau) wird am 28. März 2025 eingestellt.
Verwenden Sie stattdessen die folgenden Features, um die Spracherkennung weiterhin mit Diarisierung (Sprecherunterscheidung) zu verwenden:
- Spracherkennung in Echtzeit mit Diarisierung
- Schnelle Transkription mit Diarisierung
- Batchtranskription mit Diarisierung
Diese Spracherkennungsfeatures unterstützen nur die Diarisierung für Audiodaten mit nur einem Kanal. Mehrkanalaudio, das bei der Unterhaltungstranskription mit Mehrkanal-Diarisierung verwendet wurde, wird nicht unterstützt.
Schlüsselfunktionen
Die folgenden Features der Unterhaltungstranskription könnten Sie nützlich finden:
- Zeitstempel: Jede Äußerung eines Sprechers weist einen Zeitstempel auf, sodass Sie leicht erkennen können, wann ein Ausdruck geäußert wurde.
- Lesbare Transkriptionen: Transkripte werden automatisch mit Formatierung und Interpunktion versehen, um sicherzustellen, dass der Text genau dem entspricht, was gesagt wurde.
- Benutzerprofile: Benutzerprofile werden generiert, indem Sprachbeispiele von Benutzern erfasst und an die Signaturgenerierung gesendet werden.
- Sprecheridentifikation: Sprecher werden über Benutzerprofile identifiziert und jedem Sprecher ist ein Sprecherbezeichner zugeordnet.
- Diarisierung mehrerer Sprecher: Ermittlung, wer was gesagt hat, durch Synthetisieren des Audiostreams mit den einzelnen Sprecherbezeichnern.
- Echtzeittranskription: Bereitstellung von Live-Transkripten darüber, wer was und wann sagt, während die Besprechung stattfindet.
- Asynchrone Transkription: Bereitstellung von Transkripten mit höherer Genauigkeit durch Verwendung eines Mehrkanalaudiostreams.
Hinweis
Obwohl die Unterhaltungstranskription die Anzahl der Sprecher im Raum nicht begrenzt, ist sie für 2 bis 10 Sprecher pro Sitzung optimiert.
Anwendungsfälle
Um Besprechungen für alle Beteiligten, z. B. gehörlose und schwerhörige Teilnehmer, zu ermöglichen, ist es wichtig, dass die Transkription in Echtzeit erfolgt. Die Unterhaltungstranskription im Echtzeitmodus nimmt den Audiostream von Besprechungen auf und bestimmt, wer was sagt, sodass alle Besprechungsteilnehmer der Transkription folgen und ohne Verzögerung an der Besprechung teilnehmen können.
Die Besprechungsteilnehmer können sich auf die Besprechung konzentrieren und das Aufzeichnen der Notizen der Unterhaltungstranskription überlassen. Die Teilnehmer können sich aktiv an der Besprechung beteiligen und schnell die nächsten Schritte verfolgen, indem sie das Transkript verwenden, anstatt Notizen zu machen und möglicherweise etwas während der Besprechung zu verpassen.
Funktionsweise
Das folgende Diagramm enthält eine allgemeine Übersicht über die Funktionsweise des Features.
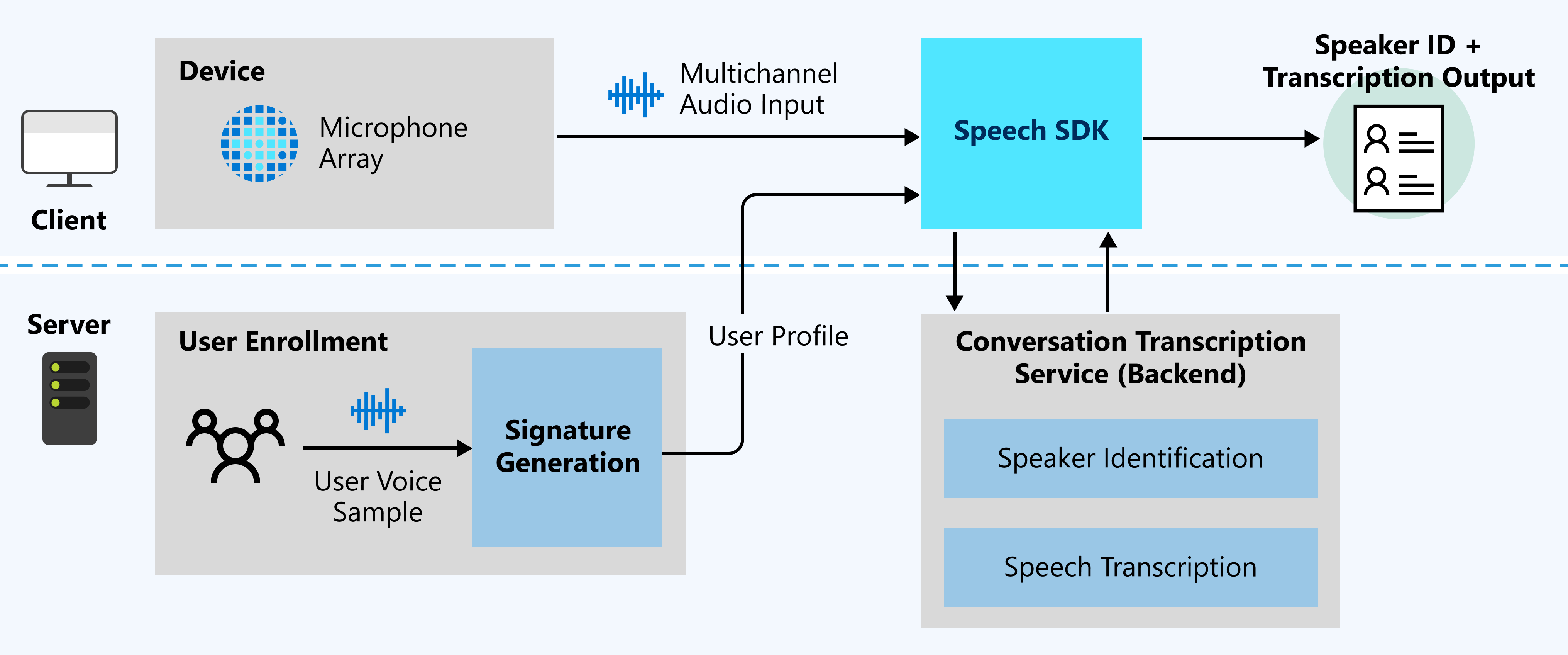
Erwartete Eingaben
Die Unterhaltungstranskription verwendet zwei Eingabetypen:
- Audiostream mit mehreren Kanälen: Spezifikations- und Entwurfsdetails finden Sie unter Empfehlungen zu Mikrofonarrays.
- Benutzerstimmproben: Für die Unterhaltungstranskription sind vor der Unterhaltung Benutzerprofile zur Sprecheridentifikation erforderlich. Sammeln Sie Audioaufzeichnungen von jedem Benutzer, und senden Sie die Aufzeichnungen dann an den Dienst für die Signaturgenerierung, um die Audioaufnahmen zu überprüfen und Benutzerprofile zu generieren.
Benutzerstimmproben für Stimmsignaturen sind für die Sprecheridentifikation erforderlich. Sprecher ohne Stimmproben werden als Nicht identifiziert erkannt. Nicht identifizierte Sprecher können dennoch unterschieden werden, wenn die Eigenschaft DifferentiateGuestSpeakers aktiviert ist (siehe folgendes Beispiel). Die Transkriptionsausgabe zeigt dann die Sprecher z. B. als Gast_0 und Gast_1 an, anstatt sie als zuvor registrierte spezifische Sprechernamen zu erkennen.
config.SetProperty("DifferentiateGuestSpeakers", "true");
Echtzeitmodus im Vergleich zum asynchronen Modus
Die folgenden Abschnitte enthalten weitere Details zu den Transkriptionsmodi, die Sie auswählen können.
Echtzeit
Die Audiodaten werden live verarbeitet, um den Sprecherbezeichner und das Transkript zurückzugeben. Wählen Sie diesen Modus, wenn Ihre Transkriptionslösung den Teilnehmern der Besprechung eine Live-Transkriptansicht ihrer laufenden Besprechung bieten soll. Die Erstellung einer Anwendung, die Besprechungen für gehörlose und schwerhörige Teilnehmer einfacher zugänglich macht, ist z. B. ein idealer Anwendungsfall für die Echtzeittranskription.
Asynchron
Die Audiodaten werden als Batch verarbeitet, um den Sprecherbezeichner und das Transkript zurückzugeben. Wählen Sie diesen Modus aus, wenn Ihre Transkriptionslösung eine höhere Genauigkeit ohne Live-Transkriptansicht bieten soll. Wenn Sie z. B. eine Anwendung erstellen möchten, mit der die Besprechungsteilnehmer verpasste Besprechungen leicht nachvollziehen können, verwenden Sie den asynchronen Transkriptionsmodus, um Transkriptionsergebnisse mit hoher Genauigkeit zu erhalten.
Echtzeit- und asynchroner Modus
Audiodaten werden live verarbeitet, um den Sprecherbezeichner und das Transkript zurückzugeben, und fordern zusätzlich ein Transkript mit hoher Genauigkeit durch asynchrone Verarbeitung an. Wählen Sie diesen Modus aus, wenn Ihre Anwendung eine Echtzeittranskription benötigt sowie eine Transkription mit höherer Genauigkeit für die Verwendung nach der Besprechung erfordert.
Sprach- und Regionsunterstützung
Aktuell unterstützt die Unterhaltungstranskription alle Sprachen der Spracherkennung in den folgenden Regionen: centralus, eastasia, eastus und westeurope.