Trainieren eines benutzerdefinierten Sprachmodells
In diesem Artikel erfahren Sie, wie Sie ein benutzerdefiniertes Modell trainieren, um die Erkennungsgenauigkeit gegenüber dem Microsoft-Basismodell zu verbessern. Die Spracherkennungsgenauigkeit und -qualität eines benutzerdefinierten Sprachmodells bleibt auch dann konsistent, wenn ein neues Basismodell veröffentlicht wird.
Hinweis
Sie bezahlen für die Nutzung des benutzerdefinierten Sprachmodells und das Endpunkthosting. Ihnen werden zudem Gebühren für das Training des benutzerdefinierten Sprachmodells in Rechnung gestellt, wenn das Basismodell am 1. Oktober 2023 oder nach diesem Datum erstellt wurde. Wenn das Basismodell vor Oktober 2023 erstellt wurde, fallen keine Kosten für das Training an. Weitere Informationen finden Sie unter Azure KI Speech – Preise und im Abschnitt „Gebühren für die Anpassung“ im Migrationsleitfaden zu Version 3.2 der Spracherkennungs-API.
Das Trainieren eines Modells ist in der Regel ein iterativer Prozess. Sie wählen zunächst ein Basismodell aus, das den Ausgangspunkt für ein neues Modell darstellt. Sie trainieren ein Modell mit Datasets, die Text und Audio enthalten können, und dann testen Sie. Wenn die Erkennungsqualität oder -genauigkeit Ihre Anforderungen nicht erfüllt, können Sie ein neues Modell mit mehr oder geänderten Trainingsdaten erstellen und dann erneut testen.
Sie können ein benutzerdefiniertes Modell nach dem Training für begrenzte Zeit verwenden. Jedoch müssen Sie Ihr benutzerdefiniertes Modell ausgehend vom neuesten Basismodell regelmäßig neu erstellen und anpassen, um die verbesserte Genauigkeit und Qualität zu nutzen. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Wichtig
Wenn Sie ein benutzerdefiniertes Modell mit Audiodaten trainieren, wählen Sie eine KI Services-Ressource für die Speech-Region mit dedizierter Hardware zum Trainieren mit Audiodaten aus. Nachdem ein Modell trainiert wurde, können Sie es nach Bedarf in eine KI Services-Ressource für Speech in einer anderen Region kopieren.
In Regionen mit dedizierter Hardware für das Training benutzerdefinierter Sprache verwendet der Speech-Dienst bis zu 100 Stunden Ihrer Audiotrainingsdaten und kann etwa 10 Stunden Daten pro Tag verarbeiten. Weitere Informationen finden Sie in den Fußnoten der Tabelle Regionen.
Erstellen eines Modells
Nachdem Sie Trainingsdatasets hochgeladen haben, folgen Sie diesen Anweisungen, um mit dem Trainieren Ihres Modells zu beginnen:
Melden Sie sich in Speech Studio an.
Wählen Sie Custom Speech> Ihr Projektname >Benutzerdefinierte Modelle trainieren aus.
Wählen Sie Neues Modell trainieren aus.
Wählen Sie auf der Seite Basismodell auswählen ein Basismodell und dann Weiter aus. Wenn Sie nicht sicher sind, wählen Sie oben in der Liste das neueste Modell aus. Der Name des Basismodells entspricht dem Datum im Format JJJJMMTT, an dem es veröffentlicht wurde. Die Anpassungsfunktionen des Basismodells werden nach dem Modellnamen in Speech Studio in Klammern aufgeführt.
Wichtig
Beachten Sie das Ablaufdatum für die Anpassung. Dies ist das letzte Datum, an dem Sie das Basismodell zum Training verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Wählen Sie auf der Seite Daten auswählen ein oder mehrere Datasets aus, die Sie zum Training verwenden möchten. Wenn keine Datasets verfügbar sind, brechen Sie das Setup ab, und wechseln Sie dann zum Menü Speech-Datasets, um Datasets hochzuladen.
Geben Sie einen Namen und eine Beschreibung für Ihr benutzerdefiniertes Modell ein, und wählen Sie dann Weiter aus.
Aktivieren Sie optional das Kontrollkästchen Test im nächsten Schritt hinzufügen. Wenn Sie diesen Schritt überspringen, können Sie die gleichen Tests später ausführen. Weitere Informationen finden Sie unter Testen der Erkennungsqualität und Quantitatives Testen des Modells.
Wählen Sie Speichern und schließen aus, um den Buildvorgang für Ihr benutzerdefiniertes Modell einzuleiten.
Kehren Sie zur Seite Benutzerdefinierte Modelle trainieren zurück.
Wichtig
Notieren Sie sich das Ablaufdatum. Dies ist das letzte Datum, an dem Sie Ihr benutzerdefiniertes Modell für die Spracherkennung verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Erstellen Sie mit dem spx csr model create-Befehl ein Modell mit Datasets für das Training. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie den
project-Parameter auf die ID eines vorhandenen Projekts fest. Dieser Parameter wird empfohlen, um das Modell auch in Speech Studio anzeigen und verwalten zu können. Sie können mit demspx csr project list-Befehl verfügbare Projekte abrufen. - Legen Sie den erforderlichen
dataset-Parameter auf die ID eines Datasets fest, das Sie für das Training verwenden möchten. Um mehrere Datasets anzugeben, legen Sie dendatasets-Parameter (Plural) fest, und trennen Sie die IDs mit einem Semikolon. - Legen Sie den erforderlichen
language-Parameter fest. Das Gebietsschema des Datasets muss mit dem Gebietsschema des Projekts übereinstimmen. Das Gebietsschema können Sie später nicht mehr ändern. Der Parameterlanguageder Speech-Befehlszeilenschnittstelle entspricht derlocale-Eigenschaft in der JSON-Anforderung und -Antwort. - Legen Sie den erforderlichen
name-Parameter fest. Dieser Parameter ist der Name, der im Speech Studio angezeigt wird. Der Parameternameder Speech-Befehlszeilenschnittstelle entspricht derdisplayName-Eigenschaft in der JSON-Anforderung und -Antwort. - Optional können Sie die
base-Eigenschaft festlegen. Beispiel:--base 5988d691-0893-472c-851e-8e36a0fe7aafWenn Sie dasbasenicht angeben, wird das Standardbasismodell für das Gebietsschema verwendet. Der Parameterbaseder Speech-Befehlszeilenschnittstelle entspricht derbaseModel-Eigenschaft in der JSON-Anforderung und -Antwort.
Hier sehen Sie einen Beispielbefehl für die Speech-Befehlszeilenschnittstelle, der ein Modell mit Datasets für das Training erstellt:
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Hinweis
In diesem Beispiel ist das base nicht festgelegt, sodass das Standardbasismodell für das Gebietsschema verwendet wird. Der Basismodell-URI wird in der Antwort zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Wichtig
Notieren Sie sich das Datum in der adaptationDateTime-Eigenschaft. Dies ist das letzte Datum, an dem Sie das Basismodell zum Training verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Notieren Sie sich das Datum in der transcriptionDateTime-Eigenschaft. Dies ist das letzte Datum, an dem Sie Ihr benutzerdefiniertes Modell für die Spracherkennung verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Die oberste self-Eigenschaft im Antworttext ist der URI des Modells. Rufen Sie mit diesem URI Details zu Projekt-, Manifest- und Veraltungsdatumsangaben des Modells ab. Sie verwenden diesen URI auch, um ein Modell zu aktualisieren oder zu löschen.
Führen Sie für die Speech-Befehlszeilenschnittstelle mit Modellen den folgenden Befehl aus:
spx help csr model
Verwenden Sie zum Erstellen eines Modells mit Datasets für das Training den Models_Create-Vorgang der Spracherkennungs-REST-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die
project-Eigenschaft auf den URI eines vorhandenen Projekts fest. Diese Eigenschaft wird empfohlen, um das Modell auch in Speech Studio anzeigen und verwalten zu können. Sie können eine Projects_List-Anforderung zum Abrufen verfügbarer Projekte ausführen. - Legen Sie die erforderliche
datasets-Eigenschaft auf den URI der Datasets fest, die Sie für das Training verwenden möchten. - Legen Sie die erforderliche
locale-Eigenschaft fest. Das Modellgebietsschema muss mit dem Gebietsschema des Projekts und des Basismodells übereinstimmen. Das Gebietsschema können Sie später nicht mehr ändern. - Legen Sie die erforderliche
displayName-Eigenschaft fest. Diese Eigenschaft ist der Name, der in Speech Studio angezeigt wird. - Optional können Sie die
baseModel-Eigenschaft festlegen. Beispiel:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}Wenn Sie dasbaseModelnicht angeben, wird das Standardbasismodell für das Gebietsschema verwendet.
Erstellen Sie eine HTTP POST-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Ersetzen Sie YourSubscriptionKey durch Ihren Speech-Ressource-Schlüssel, ersetzen Sie YourServiceRegion durch die Speech-Ressource-Region, und legen Sie die Anforderungstexteigenschaften wie zuvor beschrieben fest.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Hinweis
In diesem Beispiel ist das baseModel nicht festgelegt, sodass das Standardbasismodell für das Gebietsschema verwendet wird. Der Basismodell-URI wird in der Antwort zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Wichtig
Notieren Sie sich das Datum in der adaptationDateTime-Eigenschaft. Dies ist das letzte Datum, an dem Sie das Basismodell zum Training verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Notieren Sie sich das Datum in der transcriptionDateTime-Eigenschaft. Dies ist das letzte Datum, an dem Sie Ihr benutzerdefiniertes Modell für die Spracherkennung verwenden können. Weitere Informationen finden Sie unter Modell- und Endpunktlebenszyklus.
Die oberste self-Eigenschaft im Antworttext ist der URI des Modells. Verwenden Sie diesen URI, um Details zu Projekt-, Manifest- und Veraltungsdatumsangaben des Modells abzurufen. Sie verwenden diesen URI auch, um ein Modell zu aktualisieren oder zu löschen.
Kopieren eines Modells
Sie können ein Modell in ein anderes Projekt kopieren, das dasselbe Gebietsschema verwendet. Wenn ein Modell beispielsweise mit Audiodaten in einer Region mit dedizierter Hardware für das Training trainiert wurde, können Sie es nach Bedarf in eine KI Services-Ressource für Speech in einer anderen Region kopieren.
Befolgen Sie die folgenden Anweisungen, um ein Modell in ein Projekt in einer anderen Region zu kopieren:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Speech> Ihr Projektname >Benutzerdefinierte Modelle trainieren aus.
- Wählen Sie Kopieren in aus.
- Wählen Sie auf der Seite Speech-Modell kopieren eine Zielregion aus, in die Sie das Modell kopieren möchten.

- Wählen Sie eine KI Services-Ressource für Speech in der Zielregion aus, oder erstellen Sie eine neue Speech-Ressource.
- Wählen Sie ein Projekt aus, wohin Sie das Modell kopieren möchten, oder erstellen Sie ein neues Projekt.
- Wählen Sie Kopieren aus.

Nachdem das Modell erfolgreich kopiert wurde, werden Sie benachrichtigt und können es im Zielprojekt anzeigen.
Das direkte Kopieren eines Modells in ein Projekt in einer anderen Region wird mit der Speech-Befehlszeilenschnittstelle nicht unterstützt. Sie können mit Speech Studio oder der Spracherkennungs-REST-API ein Modell in ein Projekt in einer anderen Region kopieren.
Um ein Modell in eine andere Sprachressource zu kopieren, verwenden Sie den Models_Copy-Vorgang der Spracherkennungs-REST-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
targetSubscriptionKey-Eigenschaft auf den Schlüssel der Ziel-Speech-Ressource fest.
Erstellen Sie eine HTTP POST-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Verwenden Sie die Region und den URI des Modells, woher Sie kopieren möchten. Ersetzen Sie YourModelId durch die Modell-ID, YourSubscriptionKey durch Ihren Speech-Ressource-Schlüssel, YourServiceRegion durch die Speech-Ressource-Region, und legen Sie die Anforderungstexteigenschaften wie zuvor beschrieben fest.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Hinweis
Nur die targetSubscriptionKey-Eigenschaft im Anforderungstext enthält Informationen zur Ziel-Speech-Ressource.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Verbinden eines Modells
Modelle wurden möglicherweise mithilfe der Speech-Befehlszeilenschnittstelle oder REST-API aus einem Projekt kopiert, ohne mit einem anderen Projekt verbunden zu sein. Das Verbinden eines Modells ist eine Frage der Aktualisierung des Modells mit einem Verweis auf das Projekt.
Wenn Sie in Speech Studio aufgefordert werden, können Sie sie verbinden, indem Sie die Schaltfläche Verbinden auswählen.
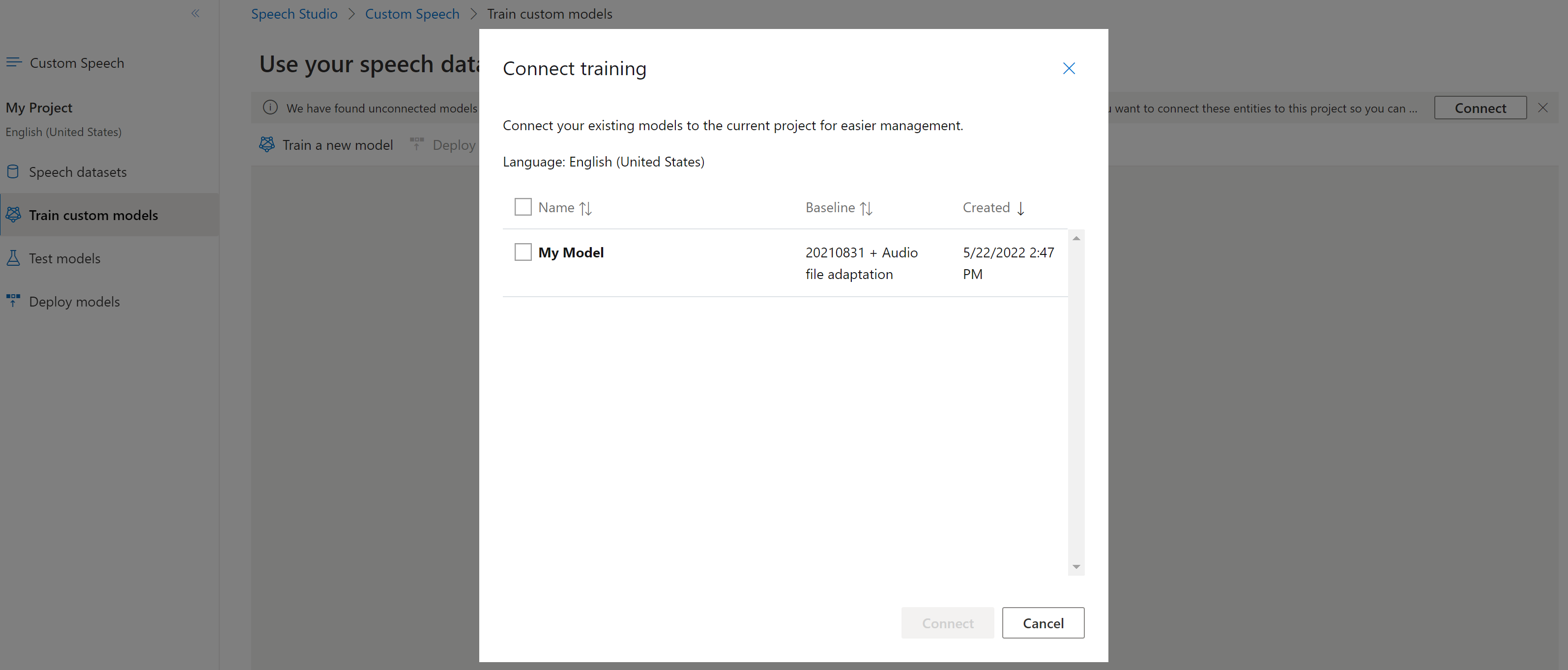
Verwenden Sie den spx csr model update-Befehl, um die Verbindung eines Modells mit einem Projekt herzustellen. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie den
project-Parameter auf den URI eines vorhandenen Projekts fest. Dieser Parameter wird empfohlen, um das Modell auch in Speech Studio anzeigen und verwalten zu können. Sie können mit demspx csr project list-Befehl verfügbare Projekte abrufen. - Legen Sie den erforderlichen
modelId-Parameter auf die ID des Modells fest, das Sie mit dem Projekt verbinden möchten.
Hier sehen Sie einen Beispielbefehl für die Speech-Befehlszeilenschnittstelle, der ein Modell mit einem Projekt verbindet:
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
Führen Sie für die Speech-Befehlszeilenschnittstelle mit Modellen den folgenden Befehl aus:
spx help csr model
Um die Verbindung eines neuen Modells mit einem Projekt der Speech-Ressource herzustellen, in die das Modell kopiert wurde, verwenden Sie den Models_Update-Vorgang der Spracherkennungs-REST-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
project-Eigenschaft auf den URI eines vorhandenen Projekts fest. Diese Eigenschaft wird empfohlen, um das Modell auch in Speech Studio anzeigen und verwalten zu können. Sie können eine Projects_List-Anforderung zum Abrufen verfügbarer Projekte ausführen.
Erstellen Sie eine HTTP PATCH-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Verwenden Sie den URI des neuen Modells. Sie können die neue Modell-ID aus der self-Eigenschaft des Models_Copy-Antworttexts abrufen. Ersetzen Sie YourSubscriptionKey durch Ihren Speech-Ressourcenschlüssel, ersetzen Sie YourServiceRegion durch die Region der Speech-Ressource, und legen Sie die Anforderungstexteigenschaften wie zuvor beschrieben fest.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}