Tutorial: Verwenden der Personalisierung in Azure Notebook
Wichtig
Ab dem 20. September 2023 können Sie keine neuen Personalisierungsressourcen mehr erstellen. Der Personalisierungsdienst wird am 1. Oktober 2026 eingestellt.
In diesem Tutorial wird in einer Azure Notebook-Instanz eine Personalisierungsschleife ausgeführt, um den damit verbundenen End-to-End-Lebenszyklus zu veranschaulichen.
In der Schleife wird vorgeschlagen, welche Art von Kaffee ein Kunde bestellen soll. Die Benutzer und ihre Präferenzen werden in einem Benutzerdataset gespeichert. Informationen zum Kaffee werden in einem Kaffeedataset gespeichert.
Benutzer und Kaffee
Das Notebook simuliert die Benutzerinteraktion mit einer Website und wählt aus dem Dataset nach dem Zufallsprinzip einen Benutzer, eine Tageszeit und einen Wettertyp aus. Eine Zusammenfassung der Benutzerinformationen lautet:
| Kunden: Kontextfeatures | Tageszeiten | Wetter |
|---|---|---|
| Alina Bernd Cathrin David |
Morgens Nachmittags Abends |
Sonnig Regnerisch Schnee |
Damit die Personalisierung im Laufe der Zeit lernen kann, sind dem System auch die Details zur Kaffeeauswahl für jede Person bekannt.
| Kaffee: Aktionsfeatures | Temperaturtypen | Ursprungsorte | Röstungsarten | Bio |
|---|---|---|---|---|
| Cappuccino | Heiß | Kenia | Dark | Bio |
| Cold Brew | Kalt | Brasilien | Leicht | Bio |
| Iced Mocha | Kalt | Äthiopien | Leicht | Kein Bio |
| Latte | Heiß | Brasilien | Dark | Kein Bio |
Der Zweck der Personalisierungsschleife besteht darin, so häufig wie möglich die beste Übereinstimmung zwischen den Benutzern und dem Kaffee zu finden.
Der Code für dieses Tutorial steht im GitHub-Repository mit den Personalisierungsbeispielen zur Verfügung.
Funktionsweise der Simulation
Zu Beginn der Systemausführung sind die Vorschläge der Personalisierung nur in 20 bis 30 Prozent der Fälle erfolgreich. Dieser Erfolg wird durch die an die Relevanz-API der Personalisierung gesendete Relevanzbewertung 1 angegeben. Nach einigen Rangfolge- und Relevanzaufrufen verbessert sich das System.
Führen Sie nach der ersten Anforderung eine Offlineauswertung durch. Die Personalisierung kann so die Daten überprüfen und eine bessere Lernrichtlinie vorschlagen. Wenden Sie die neue Lernrichtlinie an, und führen Sie mit dem Notebook erneut 20 Prozent der vorherigen Anforderungsanzahl durch. Die Schleife führt mit der neuen Lernrichtlinie zu einer besseren Leistung.
Einstufen nach Rangfolge und Belohnen von Aufrufen
Für jeden der Tausende von Aufrufen des Personalisierungsdiensts sendet Azure Notebook die Rangfolgenanforderung (Rank) an die REST-API:
- Eindeutige ID für das Rangfolgen-/Anforderungsereignis
- Kontextfeatures: Zufällige Auswahl des Benutzers, des Wetters und der Tageszeit – Simulation eines Benutzers auf einer Website oder einem mobilen Gerät
- Aktionen mit Features: Alle Kaffeedaten, aus denen die Personalisierung einen Vorschlag erstellt
Das System empfängt die Anforderung und vergleicht diese Vorhersage dann mit der bereits bekannten Wahl des Benutzers für die gleiche Tageszeit und das gleiche Wetter. Falls die bekannte Wahl mit der vorhergesagten Auswahl übereinstimmt, wird der Belohnungswert „1“ (Reward) an die Personalisierung gesendet. Andernfalls lautet zurückgesendete Relevanzwert „0“.
Hinweis
Da es sich hierbei um eine Simulation handelt, ist der Algorithmus für die Belohnung nicht kompliziert. Bei einem echten Szenario sollte für den Algorithmus eine Geschäftslogik verwendet werden, wobei ggf. Gewichtungen für unterschiedliche Aspekte der Erfahrung des Kunden vergeben werden, um das Belohnungsergebnis zu ermitteln.
Voraussetzungen
- Ein Azure Notebook-Konto
- Eine Ressource der Azure KI Personalisierung.
- Wenn Sie die Personalisierungsressource bereits verwendet haben, sollten Sie sicherstellen, dass Sie im Azure-Portal für die Ressource die Daten löschen.
- Laden Sie alle Dateien für dieses Beispiel in ein Azure Notebook-Projekt hoch.
Dateibeschreibungen:
- Personalizer.ipynb ist das Jupyter-Notebook für dieses Tutorial.
- Das Benutzerdataset wird in einem JSON-Objekt gespeichert.
- Das Kaffeedataset wird in einem JSON-Objekt gespeichert.
- Das Beispiel für den JSON-Code einer Anforderung weist das erwartete Format für eine POST-Anforderung an die Rangfolge-API auf.
Konfigurieren der Personalisierungsressource
Konfigurieren Sie im Azure-Portal Ihre Personalisierungsressource so, dass die Häufigkeit der Modellaktualisierung auf 15 Sekunden und die Wartezeit für Belohnung ebenfalls auf 10 Minuten festgelegt ist. Diese Werte finden Sie auf der Seite Konfiguration .
| Einstellung | Wert |
|---|---|
| Häufigkeit der Modellaktualisierung | 15 Sekunden |
| Wartezeit für Belohnung | 10 Minuten |
Diese Werte sind absichtlich niedrig gehalten, um für dieses Tutorial die Änderungen zu verdeutlichen. Sie sollten nicht in einem Produktionsszenario verwendet werden, ohne vorher zu prüfen, ob für Ihre Personalisierungsschleife damit das gewünschte Ziel erreicht wird.
Einrichten der Azure Notebook-Instanz
- Ändern Sie den Kernel in
Python 3.6. - Öffnen Sie die Datei
Personalizer.ipynb.
Ausführen von Notebookzellen
Führen Sie die einzelnen ausführbaren Zellen aus, und warten Sie auf die Rückgabe. Der Vorgang ist abgeschlossen, wenn in den Klammern neben der Zelle anstelle von * eine Zahl angezeigt wird. In den folgenden Abschnitten wird beschrieben, welche programmgesteuerten Vorgänge in den einzelnen Zellen ablaufen und was als Ausgabe zu erwarten ist.
Einfügen der Python-Module
Dient zum Einfügen der erforderlichen Python-Module. Die Zelle hat keine Ausgabe.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Festlegen des Schlüssels und Namens für die Personalisierungsressource
Suchen Sie im Azure-Portal auf der Seite Schnellstart Ihrer Personalisierungsressource nach Ihrem Schlüssel und Endpunkt. Ändern Sie den Wert von <your-resource-name> in den Namen Ihrer Personalisierungsressource. Ändern Sie den Wert von <your-resource-key> in Ihren Personalisierungsschlüssel.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Drucken des aktuellen Datums und der aktuellen Uhrzeit
Verwenden Sie diese Funktion, um sich die Start- und Endzeiten der iterativen Funktion bzw. der Iterationen zu notieren.
Diese Zellen haben keine Ausgabe. Wenn diese Funktion aufgerufen wird, gibt sie das aktuelle Datum und die Uhrzeit aus.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Abrufen des Zeitpunkts der letzten Modellaktualisierung
Wenn die Funktion get_last_updated aufgerufen wird, gibt die Funktion das Datum und die Uhrzeit der letzten Änderung zur Aktualisierung des Modells aus.
Diese Zellen haben keine Ausgabe. Wenn diese Funktion aufgerufen wird, gibt sie das Datum des letzten Modelltrainings aus.
Für die Funktion wird eine GET REST-API zum Abrufen der Modelleigenschaften verwendet.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Abrufen der Richtlinien- und Dienstkonfiguration
Dient zum Überprüfen des Dienststatus mit diesen beiden REST-Aufrufen.
Diese Zellen haben keine Ausgabe. Wenn diese Funktion aufgerufen wird, gibt sie die Dienstwerte aus.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Erstellen von URLs und Lesen von JSON-Datendateien
Mit dieser Zelle wird Folgendes durchgeführt:
- Die in REST-Aufrufen verwendeten URLs werden erstellt.
- Der Sicherheitsheader wird festgelegt, indem der Schlüssel Ihrer Personalisierungsressource verwendet wird.
- Der zufällige Ausgangswert für die Rangfolgeereignis-ID wird festgelegt.
- Die JSON-Datendateien werden eingelesen.
- Die
get_last_updated-Methode wird aufgerufen (Lernrichtlinie wurde in der Beispielausgabe entfernt). - Die
get_service_settings-Methode wird aufgerufen.
Die Zelle enthält die Ausgabe des Aufrufs der Funktionen get_last_updated und get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Stellen Sie sicher, dass die rewardWaitTime der Ausgabe auf 10 Minuten und modelExportFrequency auf 15 Sekunden festgelegt ist.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Problembehandlung für ersten REST-Aufruf
Diese vorherige Zelle ist die erste Zelle, die einen Aufruf der Personalisierung durchführt. Stellen Sie sicher, dass der REST-Statuscode in der Ausgabe <Response [200]> lautet. Wenn Sie einen Fehler erhalten (z. B. 404), obwohl Sie sicher sind, dass Ressourcenschlüssel und -name korrekt sind, sollten Sie das Notebook neu laden.
Stellen Sie sicher, dass für Kaffee und Benutzer jeweils der Wert „4“ angegeben ist. Falls Sie einen Fehler erhalten, sollten Sie überprüfen, ob Sie alle drei JSON-Dateien hochgeladen haben.
Einrichten eines Metrikdiagramms im Azure-Portal
Später in diesem Tutorial können Sie den Langzeitprozess mit 10.000 Anforderungen im Browser in einem Textfeld verfolgen, das aktualisiert wird. Unter Umständen ist dies in einem Diagramm oder als Gesamtsumme einfacher zu sehen, nachdem der Langzeitprozess abgeschlossen ist. Verwenden Sie die Metriken der Ressource, um diese Informationen anzuzeigen. Sie können das Diagramm jetzt erstellen, da Sie eine Anforderung an den Dienst gesendet haben. Aktualisieren Sie das Diagramm dann regelmäßig, während der Langzeitprozess aktiv ist.
Wählen Sie im Azure-Portal Ihre Personalisierungsressource aus.
Wählen Sie in der Ressourcennavigation unter „Überwachung“ die Option Metriken aus.
Wählen Sie im Diagramm die Option Metrik hinzufügen aus.
Der Ressourcen- und Metriknamespace sind bereits festgelegt. Sie müssen die Metrik für erfolgreiche Aufrufe und die Aggregation für die Summe auswählen.
Ändern Sie die Einstellung des Zeitfilters auf die letzten vier Stunden.
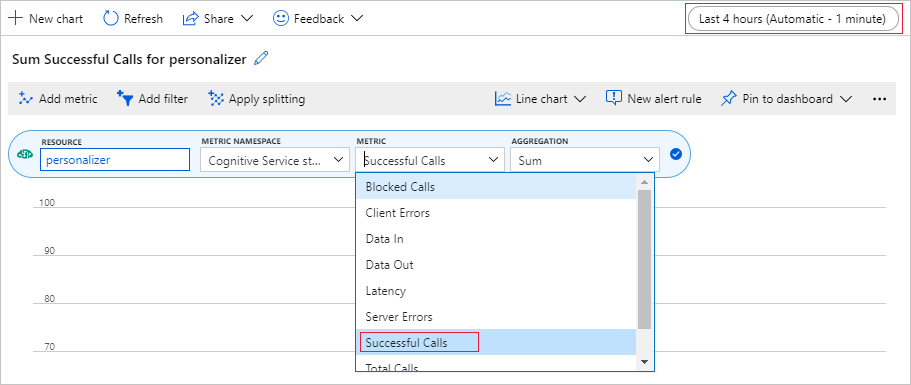
Im Diagramm sollten drei erfolgreiche Aufrufe angezeigt werden.
Generieren einer eindeutigen Ereignis-ID
Diese Funktion generiert eine eindeutige ID für jeden Rangfolgeaufruf. Die ID wird verwendet, um die Informationen zum Rangfolge- und Belohnungsaufruf zu ermitteln. Dieser Wert kann aus einem Geschäftsprozess stammen, z. B. einer Webansicht-ID oder Transaktions-ID.
Die Zelle hat keine Ausgabe. Wenn diese Funktion aufgerufen wird, wird die eindeutige ID ausgegeben.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Abrufen von Benutzer, Wetter und Tageszeit nach dem Zufallsprinzip
Mit dieser Funktion werden ein eindeutiger Benutzer, das Wetter und die Tageszeit ausgewählt, und anschließend werden diese Elemente dem JSON-Objekt hinzugefügt, das an die Rangfolgeanforderung gesendet wird.
Die Zelle hat keine Ausgabe. Wenn die Funktion aufgerufen wird, gibt sie den Benutzernamen, das Wetter und die Tageszeit nach dem Zufallsprinzip zurück.
Liste mit vier Benutzern und ihren Präferenzen (aus Platzgründen sind nur einige Präferenzen aufgeführt):
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Hinzufügen aller Kaffeedaten
Mit dieser Funktion wird die gesamte Kaffeeliste dem JSON-Objekt hinzugefügt, das an die Rangfolgeanforderung gesendet wird.
Die Zelle hat keine Ausgabe. Wenn diese Funktion aufgerufen wird, wird keine Änderung des rankjsonobj-Elements durchgeführt.
Das Beispiel für die Features einer einzelnen Kaffeesorte lautet:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Vergleichen der Vorhersage mit der bekannten Benutzerpräferenz
Diese Funktion wird für jede Iteration nach dem Aufruf der Rangfolge-API aufgerufen.
Mit dieser Funktion wird die Benutzerpräferenz in Bezug auf den Kaffee nach dem Wetter und der Tageszeit mit dem Personalisierungsvorschlag für den Benutzer basierend auf den Filtern verglichen. Wenn sich eine Übereinstimmung mit dem Vorschlag ergibt, wird „1“ als Bewertungspunktzahl zurückgegeben, andernfalls „0“. Die Zelle hat keine Ausgabe. Wenn diese Funktion aufgerufen wird, wird die Bewertungspunktzahl ausgegeben.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Schleife für Rangfolge- und Belohnungsaufrufe
Die nächste Zelle umfasst die Hauptarbeit des Notebooks: Abrufen eines zufälligen Benutzers, Abrufen der Kaffeeliste und Senden beider Angaben an die Rangfolge-API. Die Vorhersage wird mit den bekannten Präferenzen des Benutzers verglichen, und anschließend wird der Belohnungswert zurück an den Personalisierungsdienst gesendet.
Die Schleife wird so häufig ausgeführt, wie dies unter num_requests angegeben ist. Die Personalisierung benötigt einige Tausend Rangfolge- und Belohnungsaufrufe, um ein Modell erstellen zu können.
Unten ist ein Beispiel für den JSON-Code angegeben, der an die Rangfolge-API gesendet wird. Aus Platzgründen ist nicht die gesamte Kaffeeliste angegeben. Den vollständigen JSON-Code für Kaffee finden Sie in coffee.json.
An die Rangfolge-API gesendeter JSON-Code:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
JSON-Codeantwort der Rangfolge-API:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Abschließend wird für jede Schleife eine zufällige Auswahl für Benutzer, Wetter, Tageszeit und ermittelter Belohnungswert angezeigt. Mit dem Belohnungswert „1“ wird angegeben, dass die Personalisierungsressource für den Benutzer, das Wetter und die Tageszeit die richtige Kaffeesorte ausgewählt hat.
1 Alice Rainy Morning Latte 1
In der Funktion wird Folgendes verwendet:
- Rangfolge: POST-REST-API zum Abrufen der Rangfolge.
- Belohnung: POST-REST-API zum Melden der Belohnung.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Ausführen von 10.000 Iterationen
Führen Sie für die Personalisierungsschleife 10.000 Iterationen aus. Dies ist ein zeitintensives Ereignis. Schließen Sie nicht den Browser, in dem das Notebook ausgeführt wird. Aktualisieren Sie das Metrikdiagramm im Azure-Portal in regelmäßigen Abständen, um die Gesamtzahl der Dienstaufrufe anzuzeigen. Wenn ungefähr 20.000 Aufrufe und ein Rangfolge- und Belohnungsaufruf für jede Iteration der Schleife durchgeführt wurden, sind die Iterationen abgeschlossen.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Anzeigen der Ergebnisse in einem Diagramm zur Verdeutlichung der Verbesserung
Erstellen Sie aus count und rewards ein Diagramm.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Ausführen der Diagrammerstellung für 10.000 Rangfolgeanforderungen
Führen Sie die Funktion createChart aus.
createChart(count,rewards)
Lesen des Diagramms
In diesem Diagramm ist der Erfolg des Modells für die aktuelle Standardlernrichtlinie dargestellt.
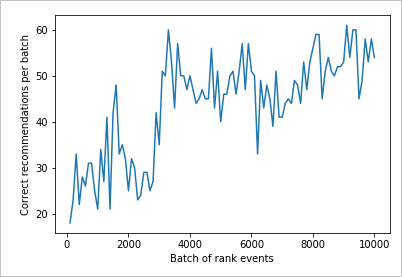
Das ideale Ziel besteht darin, dass sich für die Schleife nach Abschluss des Tests eine Erfolgsrate ergibt, die nahe bei 100 Prozent liegt (abzüglich der Durchsuchung). Der Standardwert für die Durchsuchung beträgt 20 %.
100-20=80
Sie finden diesen Durchsuchungswert im Azure-Portal auf der Seite Konfiguration für die Personalisierungsressource.
Sie können eine bessere Lernrichtlinie ermitteln, indem Sie basierend auf Ihren Daten für die Rangfolge-API im Portal für Ihre Personalisierungsschleife eine Offlinebewertung durchführen.
Durchführen einer Offlinebewertung
Öffnen Sie im Azure-Portal die Seite Bewertungen der Personalisierungsressource.
Wählen Sie die Option Bewertung erstellen aus.
Geben Sie die erforderlichen Daten für den Bewertungsnamen und den Datumsbereich für die Schleifenbewertung ein. Der Datumsbereich sollte nur die Tage enthalten, die für Ihre Bewertung relevant sind.
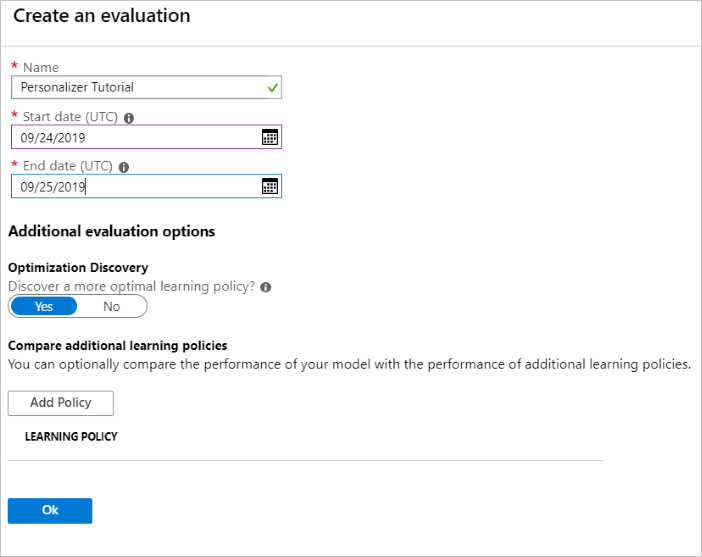
Mit dieser Offlinebewertung soll ermittelt werden, ob für die in dieser Schleife verwendeten Features und Aktionen eine bessere Lernrichtlinie vorhanden ist. Stellen Sie sicher, dass die Ermittlung zur Optimierung aktiviert ist, um diese bessere Lernrichtlinie zu ermitteln.
Wählen Sie OK aus, um die Bewertung zu starten.
Auf der Seite Bewertungen werden die neue Bewertung und der aktuelle Status angezeigt. Die Dauer dieser Bewertung hängt davon ab, wie viele Daten Sie nutzen. Nach einigen Minuten können Sie zu dieser Seite zurückkehren, um die Ergebnisse zu prüfen.
Wählen Sie nach Abschluss der Bewertung die Option Vergleich verschiedener Lernrichtlinien aus. Es werden die verfügbaren Lernrichtlinien und das jeweilige Verhalten für die Daten angezeigt.
Wählen Sie in der Tabelle die oberste Lernrichtlinie und dann die Option Anwenden aus. Die beste Lernrichtlinie wird auf Ihr Modell angewendet, und es wird ein neuer Trainingslauf durchgeführt.
Ändern der Häufigkeit der Modellaktualisierung in „5 Minuten“
- Wählen Sie im Azure-Portal für die Personalisierungsressource die Seite Konfiguration aus.
- Ändern Sie die Häufigkeit der Modellaktualisierung und die Wartezeit für Belohnung jeweils in „5 Minuten“, und wählen Sie anschließend Speichern aus.
Informieren Sie sich weiter über die Wartezeit für Belohnung und die Häufigkeit der Modellaktualisierung.
#Verify new learning policy and times
get_service_settings()
Überprüfen Sie, ob in der Ausgabe für rewardWaitTime und modelExportFrequency jeweils „5 Minuten“ als Wert angegeben ist.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Überprüfen der neuen Lernrichtlinie
Wechseln Sie zur Azure Notebooks-Datei zurück, und führen Sie die gleiche Schleife aus, aber nur für 2.000 Iterationen. Aktualisieren Sie das Metrikdiagramm im Azure-Portal in regelmäßigen Abständen, um die Gesamtzahl der Dienstaufrufe anzuzeigen. Wenn ungefähr 4.000 Aufrufe und ein Rangfolge- und Belohnungsaufruf für jede Iteration der Schleife durchgeführt wurden, sind die Iterationen abgeschlossen.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
Ausführen der Diagrammerstellung für 2.000 Rangfolgeanforderungen
Führen Sie die Funktion createChart aus.
createChart(count2,rewards2)
Überprüfen des zweiten Diagramms
Im zweiten Diagramm sollte ein merklicher Anstieg bei den Rangfolgevorhersagen, für die sich Übereinstimmungen mit den Benutzerpräferenzen ergeben, zu beobachten sein.
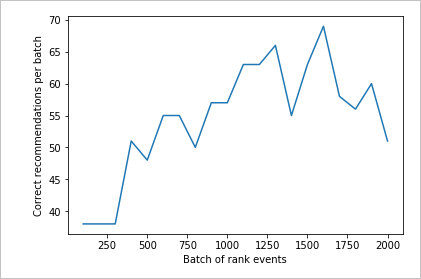
Bereinigen von Ressourcen
Falls Sie die Tutorialreihe nicht weiter durcharbeiten möchten, sollten Sie die folgenden Ressourcen bereinigen:
- Löschen Sie Ihr Azure Notebook-Projekt.
- Löschen Sie Ihre Personalisierungsressource.
Nächste Schritte
Sie finden die in diesem Beispiel verwendeten Jupyter-Notebook- und Datendateien im GitHub-Repository für die Personalisierung.