GPT-4o Echtzeit-API für Sprache und Audio (Vorschau)
Hinweis
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Die Azure OpenAI GPT-4o Echtzeit-API für Sprache und Audio ist Teil der GPT-4o-Modellfamilie, die latenzarme Unterhaltungsinteraktionen mit Sprachein- und ausgabe unterstützt. Die GPT-4o audio-realtime-API wurde entwickelt, um Unterhaltungsinteraktionen latenzarm in Echtzeit zu verarbeiten, wodurch sie sich hervorragend für Anwendungsfälle eignet, die Liveinteraktionen zwischen einem Benutzer und einem Modell umfassen, z. B. Kundendienstmitarbeiter, Sprachassistenten und Echtzeitübersetzer.
Die meisten Benutzer der Echtzeit-API müssen Ton von einem Endbenutzer in Echtzeit bereitstellen und empfangen, einschließlich Anwendungen, die WebRTC oder ein Telefoniesystem verwenden. Die Echtzeit-API ist nicht für die direkte Verbindung mit Endbenutzergeräten konzipiert und basiert auf Clientintegrationen zum Beenden von Endbenutzer-Audiodatenströmen.
Unterstützte Modelle
Die GPT 4o-Echtzeitmodelle sind für globale Bereitstellungen in den Regionen USA, Osten 2 und Schweden, Mitte verfügbar.
gpt-4o-realtime-preview(2024-12-17)gpt-4o-realtime-preview(2024-10-01)
Weitere Informationen finden Sie in der Dokumentation zu Modellen und Versionen.
API-Unterstützung
Die Unterstützung für die Echtzeit-API wurde erstmals in der API-Version 2024-10-01-preview hinzugefügt.
Hinweis
Weitere Informationen zur API und Architektur finden Sie im „Azure OpenAI GPT-4o real-time audio“-Repository auf GitHub.
Bereitstellen eines Modells für Echtzeitaudio
So stellen Sie das gpt-4o-realtime-preview-Modell im Azure KI Foundry-Portal bereit:
- Wechseln Sie zum Azure KI Foundry-Portal, und stellen Sie sicher, dass Sie mit dem Azure-Abonnement angemeldet sind, das Ihre Azure OpenAI Service-Ressource enthält (mit oder ohne Modellimplementierungen).
- Wählen Sie im linken Bereich den Playground Echtzeitaudio unter Playgrounds aus.
- Wählen Sie Neue Bereitstellung erstellen aus, um das Bereitstellungsfenster zu öffnen.
- Suchen Sie nach dem Modell
gpt-4o-realtime-preview, wählen Sie es aus, und wählen Sie dann Bestätigen aus. - Wählen Sie im Bereitstellungs-Assistenten die
2024-12-17-Modellversion aus. - Durchlaufen Sie den Assistenten, um die Bereitstellung des Modells abzuschließen.
Nachdem Sie nun über eine Bereitstellung des Modells gpt-4o-realtime-preview verfügen, können Sie mit ihm im Playground Echtzeit-Audio oder der Echtzeit-API im Azure KI Foundry-Portal in Echtzeit interagieren.
Verwenden von GPT-4o-Echtzeitaudio
Führen Sie die folgenden Schritte aus, um mit Ihrem bereitgestellten gpt-4o-realtime-preview-Modell im Playground Echtzeitaudio in Azure KI Foundry zu chatten:
Wechseln Sie zur Azure OpenAI Service-Seite im Azure KI Foundry-Portal. Stellen Sie sicher, dass Sie mit dem Azure-Abonnement angemeldet sind, das Ihre Azure OpenAI Service-Ressource und das bereitgestellte Modell
gpt-4o-realtime-previewenthält.Wählen Sie im linken Bereich den Playground Echtzeitaudio unter Playgrounds aus.
Wählen Sie ihr bereitgestelltes
gpt-4o-realtime-preview-Modell aus der Dropdownliste Bereitstellung aus.Wählen Sie Mikrofon aktivieren aus, damit der Browser auf Ihr Mikrofon zugreifen kann. Wenn Sie bereits die Berechtigung erteilt haben, können Sie diesen Schritt überspringen.
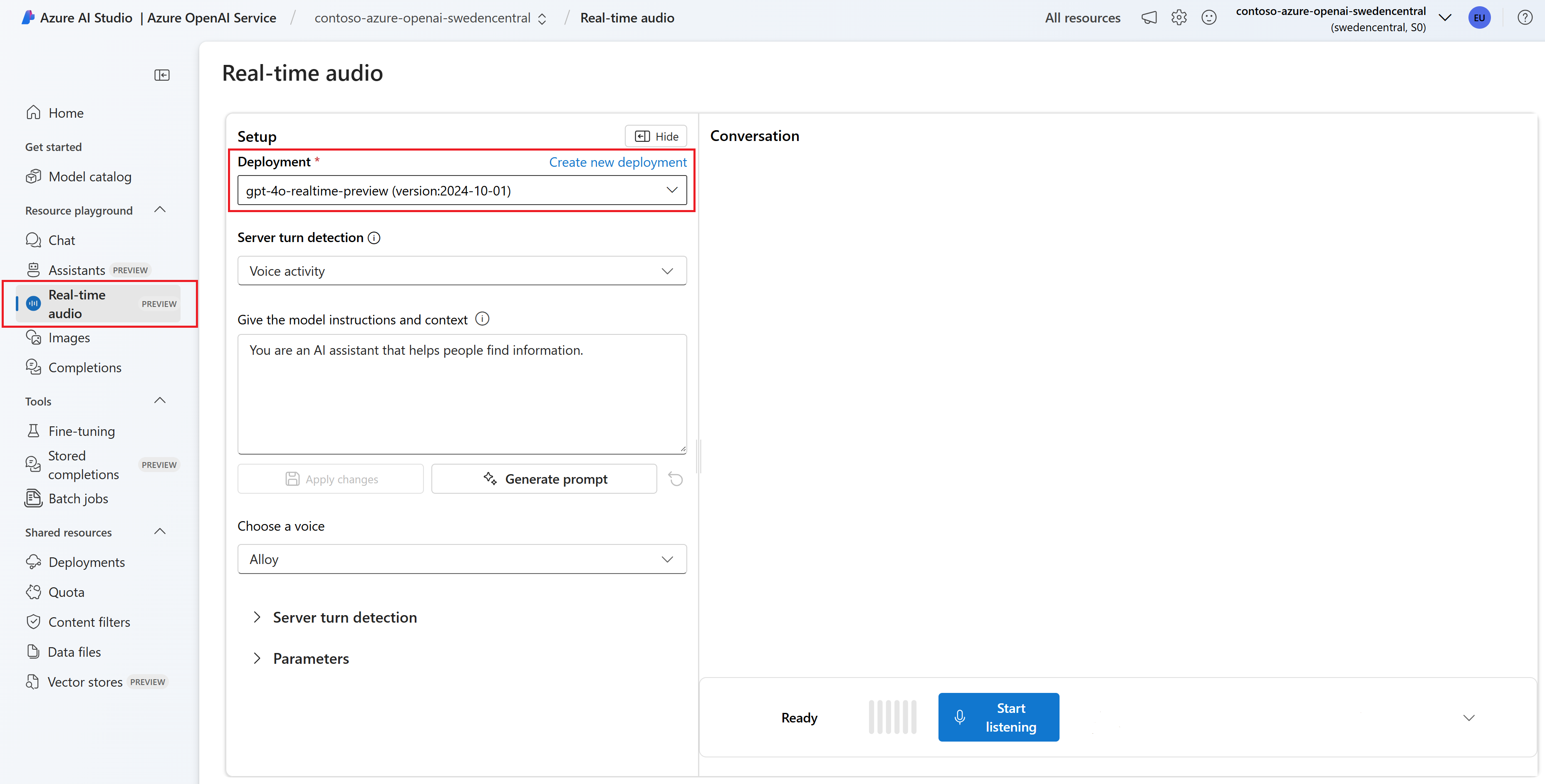
Optional können Sie Inhalte im Textfeld Anweisungen und Kontext für das Modell geben bearbeiten. Gibt dem Modell Anweisungen dazu, wie es sich verhalten soll und auf welchen Kontext es beim Generieren einer Antwort verweisen soll. Sie können die Persönlichkeit des Assistenten beschreiben, ihm sagen, was er beantworten soll und was nicht, und ihm sagen, wie Antworten formatiert werden sollen.
Ändern Sie optional Einstellungen wie Schwellenwert, Präfixauffüllung und Stilledauer.
Wählen Sie Zuhören starten aus, um die Sitzung zu starten. Sie können in das Mikrofon sprechen, um einen Chat zu starten.
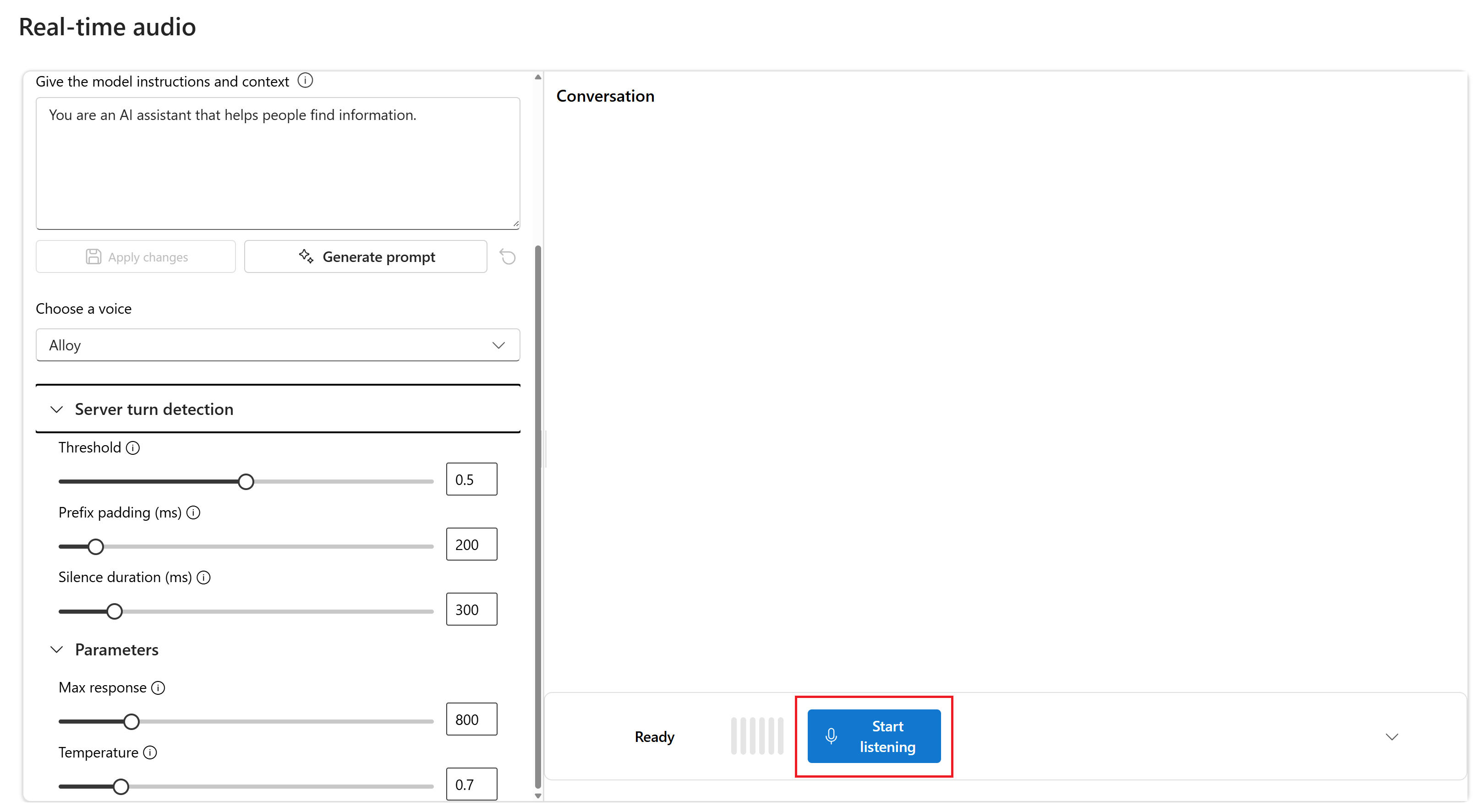
Sie können den Chat jederzeit unterbrechen, indem Sie sprechen. Sie können den Chat beenden, indem Sie die Schaltfläche Zuhören beenden auswählen.


Voraussetzungen
- Azure-Abonnement: Kostenloses Azure-Konto
- Node.js LTS- oder ESM-Unterstützung.
- Eine Azure OpenAI-Ressource, die in der Region „USA, Osten 2“ oder „Schweden, Mitte“ erstellt wurde. Weitere Informationen finden Sie unter Verfügbarkeit der Regionen.
- Anschließend müssen Sie ein
gpt-4o-realtime-preview-Modell mit Ihrer Azure OpenAI-Ressource bereitstellen. Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
Voraussetzungen für Microsoft Entra ID
Für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID müssen Sie:
- Die Azure CLI installieren, die für die schlüssellose Authentifizierung mit Microsoft Entra ID verwendet wird
- Weisen Sie Ihrem Benutzerkonto die
Cognitive Services User-Rolle zu. Sie können Rollen im Azure-Portal unter Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen zuweisen.
Bereitstellen eines Modells für Echtzeitaudio
So stellen Sie das gpt-4o-realtime-preview-Modell im Azure KI Foundry-Portal bereit:
- Wechseln Sie zum Azure KI Foundry-Portal, und stellen Sie sicher, dass Sie mit dem Azure-Abonnement angemeldet sind, das Ihre Azure OpenAI Service-Ressource enthält (mit oder ohne Modellimplementierungen).
- Wählen Sie im linken Bereich den Playground Echtzeitaudio unter Playgrounds aus.
- Wählen Sie Neue Bereitstellung erstellen aus, um das Bereitstellungsfenster zu öffnen.
- Suchen Sie nach dem Modell
gpt-4o-realtime-preview, wählen Sie es aus, und wählen Sie dann Bestätigen aus. - Wählen Sie im Bereitstellungs-Assistenten die
2024-12-17-Modellversion aus. - Durchlaufen Sie den Assistenten, um die Bereitstellung des Modells abzuschließen.
Nachdem Sie nun über eine Bereitstellung des Modells gpt-4o-realtime-preview verfügen, können Sie mit ihm im Playground Echtzeit-Audio oder der Echtzeit-API im Azure KI Foundry-Portal in Echtzeit interagieren.
Einrichten
Erstellen Sie einen neuen Ordner
realtime-audio-quickstartfür die Anwendung, und öffnen Sie Visual Studio Code in diesem Ordner mit dem folgenden Befehl:mkdir realtime-audio-quickstart && code realtime-audio-quickstartErstellen Sie
package.jsonmit dem folgenden Befehl:npm init -yAktualisieren Sie
package.jsonmit dem folgenden Befehl auf ECMAScript:npm pkg set type=moduleInstallieren Sie die Echtzeit-Audioclientbibliothek für JavaScript mit:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzInstallieren Sie für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID das
@azure/identity-Paket mit:npm install @azure/identity
Abrufen von Ressourceninformationen
Sie müssen die folgenden Informationen abrufen, um Ihre Anwendung bei Ihrer Azure OpenAI-Ressource zu authentifizieren:
| Variablenname | Wert |
|---|---|
AZURE_OPENAI_ENDPOINT |
Diesen Wert finden Sie im Abschnitt Schlüssel und Endpunkt, wenn Sie die Ressource über das Azure-Portal untersuchen. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Dieser Wert entspricht dem benutzerdefinierten Namen, den Sie während der Bereitstellung eines Modells für die Bereitstellung ausgewählt haben. Diesen Wert finden Sie unter Ressourcenverwaltung>Modellbereitstellungen im Azure-Portal. |
OPENAI_API_VERSION |
Erfahren Sie mehr über API-Versionen. |
Erfahren Sie mehr über schlüssellose Authentifizierung und das Festlegen von Umgebungsvariablen.
Achtung
Um die empfohlene schlüssellose Authentifizierung mit dem SDK zu verwenden, stellen Sie sicher, dass die Umgebungsvariable AZURE_OPENAI_API_KEY nicht festgelegt ist.
Texteingabe, Audioausgabe
Erstellen Sie die Datei
text-in-audio-out.jsmit dem folgenden Code:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient(new URL(endpoint), new DefaultAzureCredential(), { deployment: deployment }); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Melden Sie sich mithilfe des folgenden Befehls bei Azure an:
az loginFühren Sie die JavaScript-Datei aus.
node text-in-audio-out.js
Die Ausgabe der Ergebnisse dauert einen Moment.
Output
Das Skript ruft eine Antwort vom Modell ab und gibt die empfangenen Transkript- und Audiodaten aus.
Die Ausgabe ist mit folgender Zeichenfolge vergleichbar:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Beispiel für Webanwendungen
Das JavaScript-Webbeispiel auf GitHub veranschaulicht die Verwendung der GPT-4o Realtime-API für Interaktionen mit dem Modell in Echtzeit. Der Beispielcode enthält eine einfache Weboberfläche, die Audiodaten aus dem Mikrofon des Benutzers erfasst und zur Verarbeitung an das Modell sendet. Das Modell antwortet mit Text und Audio, der vom Beispielcode in der Weboberfläche gerendert wird.
Sie können den Beispielcode lokal auf Ihrem Computer ausführen, indem Sie die folgenden Schritte ausführen. Die aktuellsten Anweisungen finden Sie im Repository auf GitHub.
Wenn Sie Node.js noch nicht installiert haben, laden Sie die neueste LTS-Version von Node.js herunter, und installieren Sie sie.
Klonen Sie das Repository auf Ihren lokalen Computer:
git clone https://github.com/Azure-Samples/aoai-realtime-audio-sdk.gitÖffnen Sie den Ordner
javascript/samples/webin Ihrem bevorzugten Code-Editor.cd ./javascript/samplesFühren Sie
download-pkg.ps1oderdownload-pkg.shaus, um die erforderlichen Pakete herunterzuladen.Wechseln Sie zum Ordner
webaus dem Ordner./javascript/samples.cd ./webFühren Sie
npm installaus, um alle Paketabhängigkeiten zu installieren.Führen Sie
npm run devaus, um den Webserver zu starten. Navigieren Sie bei Bedarf zu allen Firewallberechtigungsaufforderungen.Wechseln Sie in einem Browser zu einer der bereitgestellten URIs aus der Konsolenausgabe (z. B.
http://localhost:5173/).Geben Sie in der Weboberfläche die folgenden Informationen ein:
- Endpoint: Der Ressourcenendpunkt einer Azure OpenAI-Ressource. Sie müssen den
/realtime-Pfad nicht anfügen. Eine Beispielstruktur kannhttps://my-azure-openai-resource-from-portal.openai.azure.comsein. - API-Schlüssel: Ein entsprechender API-Schlüssel für die Azure OpenAI-Ressource.
- Bereitstellung: Der Name des
gpt-4o-realtime-preview-Modells, das Sie im vorherigen Abschnitt bereitgestellt haben. - Systemnachricht: Optional können Sie eine Systemnachricht wie „Sie sprechen immer wie ein freundlicher Pirat“ bereitstellen.
- Temperatur: Wenn Sie möchten, können Sie eine benutzerdefinierte Temperatur bereitstellen.
- Stimme: Wenn Sie möchten, können Sie eine Stimme auswählen.
- Endpoint: Der Ressourcenendpunkt einer Azure OpenAI-Ressource. Sie müssen den
Wählen Sie die Schaltfläche Aufzeichnen aus, um die Sitzung zu starten. Akzeptieren Sie die Berechtigungen zum Verwenden Ihres Mikrofons, wenn Sie dazu aufgefordert werden.
In der Hauptausgabe sollte eine
<< Session Started >>-Nachricht angezeigt werden. Dann können Sie in das Mikrofon sprechen, um einen Chat zu starten.Sie können den Chat jederzeit unterbrechen, indem Sie sprechen. Sie können den Chat beenden, indem Sie die Schaltfläche Beenden auswählen.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
- Python 3.8 oder eine höhere Version Es wird empfohlen, Python 3.10 oder höher zu verwenden, aber mindestens Python 3.8 ist erforderlich. Wenn Sie keine geeignete Version von Python installiert haben, können Sie die Anweisungen im VS Code-Tutorial für Python befolgen, um Python auf Ihrem Betriebssystem zu installieren.
- Eine Azure OpenAI-Ressource, die in der Region „USA, Osten 2“ oder „Schweden, Mitte“ erstellt wurde. Weitere Informationen finden Sie unter Verfügbarkeit der Regionen.
- Anschließend müssen Sie ein
gpt-4o-realtime-preview-Modell mit Ihrer Azure OpenAI-Ressource bereitstellen. Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
Voraussetzungen für Microsoft Entra ID
Für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID müssen Sie:
- Die Azure CLI installieren, die für die schlüssellose Authentifizierung mit Microsoft Entra ID verwendet wird
- Weisen Sie Ihrem Benutzerkonto die
Cognitive Services User-Rolle zu. Sie können Rollen im Azure-Portal unter Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen zuweisen.
Bereitstellen eines Modells für Echtzeitaudio
So stellen Sie das gpt-4o-realtime-preview-Modell im Azure KI Foundry-Portal bereit:
- Wechseln Sie zum Azure KI Foundry-Portal, und stellen Sie sicher, dass Sie mit dem Azure-Abonnement angemeldet sind, das Ihre Azure OpenAI Service-Ressource enthält (mit oder ohne Modellimplementierungen).
- Wählen Sie im linken Bereich den Playground Echtzeitaudio unter Playgrounds aus.
- Wählen Sie Neue Bereitstellung erstellen aus, um das Bereitstellungsfenster zu öffnen.
- Suchen Sie nach dem Modell
gpt-4o-realtime-preview, wählen Sie es aus, und wählen Sie dann Bestätigen aus. - Wählen Sie im Bereitstellungs-Assistenten die
2024-12-17-Modellversion aus. - Durchlaufen Sie den Assistenten, um die Bereitstellung des Modells abzuschließen.
Nachdem Sie nun über eine Bereitstellung des Modells gpt-4o-realtime-preview verfügen, können Sie mit ihm im Playground Echtzeit-Audio oder der Echtzeit-API im Azure KI Foundry-Portal in Echtzeit interagieren.
Einrichten
Erstellen Sie einen neuen Ordner
realtime-audio-quickstartfür die Anwendung, und öffnen Sie Visual Studio Code in diesem Ordner mit dem folgenden Befehl:mkdir realtime-audio-quickstart && code realtime-audio-quickstartErstellen einer virtuellen Umgebung Wenn Sie Python 3.10 oder höher bereits installiert haben, können Sie mit den folgenden Befehlen eine virtuelle Umgebung erstellen:
Wenn Sie die Python-Umgebung aktivieren, verwenden Sie beim Ausführen von
pythonoderpipüber die Befehlszeile den Python-Interpreter, der im Ordner.venvIhrer Anwendung enthalten ist. Sie können den Befehldeactivateverwenden, um die virtuelle Python-Umgebung zu beenden, und sie später bei Bedarf reaktivieren.Tipp
Es wird empfohlen, eine neue Python-Umgebung zu erstellen und zu aktivieren, um die Pakete zu installieren, die Sie für dieses Tutorial benötigen. Installieren Sie keine Pakete in Ihrer globalen Python-Installation. Sie sollten beim Installieren von Python-Paketen immer eine virtuelle oder Conda-Umgebung verwenden, andernfalls können Sie die globale Python-Installation beschädigen.
Installieren Sie die Echtzeit-Audioclientbibliothek für Python mit:
pip install "https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/py%2Fv0.5.3/rtclient-0.5.3.tar.gz"Installieren Sie für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID das
azure-identity-Paket mit:pip install azure-identity
Abrufen von Ressourceninformationen
Sie müssen die folgenden Informationen abrufen, um Ihre Anwendung bei Ihrer Azure OpenAI-Ressource zu authentifizieren:
| Variablenname | Wert |
|---|---|
AZURE_OPENAI_ENDPOINT |
Diesen Wert finden Sie im Abschnitt Schlüssel und Endpunkt, wenn Sie die Ressource über das Azure-Portal untersuchen. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Dieser Wert entspricht dem benutzerdefinierten Namen, den Sie während der Bereitstellung eines Modells für die Bereitstellung ausgewählt haben. Diesen Wert finden Sie unter Ressourcenverwaltung>Modellbereitstellungen im Azure-Portal. |
OPENAI_API_VERSION |
Erfahren Sie mehr über API-Versionen. |
Erfahren Sie mehr über schlüssellose Authentifizierung und das Festlegen von Umgebungsvariablen.
Texteingabe, Audioausgabe
Erstellen Sie die Datei
text-in-audio-out.pymit dem folgenden Code:import base64 import asyncio from azure.identity.aio import DefaultAzureCredential from rtclient import ( ResponseCreateMessage, RTLowLevelClient, ResponseCreateParams ) # Set environment variables or edit the corresponding values here. endpoint = os.environ["AZURE_OPENAI_ENDPOINT"] deployment = "gpt-4o-realtime-preview" async def text_in_audio_out(): async with RTLowLevelClient( url=endpoint, azure_deployment=deployment, token_credential=DefaultAzureCredential(), ) as client: await client.send( ResponseCreateMessage( response=ResponseCreateParams( modalities={"audio", "text"}, instructions="Please assist the user." ) ) ) done = False while not done: message = await client.recv() match message.type: case "response.done": done = True case "error": done = True print(message.error) case "response.audio_transcript.delta": print(f"Received text delta: {message.delta}") case "response.audio.delta": buffer = base64.b64decode(message.delta) print(f"Received {len(buffer)} bytes of audio data.") case _: pass async def main(): await text_in_audio_out() asyncio.run(main())Führen Sie die Python-Datei aus.
python text-in-audio-out.py
Die Ausgabe der Ergebnisse dauert einen Moment.
Output
Das Skript ruft eine Antwort vom Modell ab und gibt die empfangenen Transkript- und Audiodaten aus.
Die Ausgabe ist mit folgender Zeichenfolge vergleichbar:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: can
Received 12000 bytes of audio data.
Received text delta: I
Received text delta: assist
Received text delta: you
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 28800 bytes of audio data.
Voraussetzungen
- Azure-Abonnement: Kostenloses Azure-Konto
- Node.js LTS- oder ESM-Unterstützung.
- Globale Installation von TypeScript
- Eine Azure OpenAI-Ressource, die in der Region „USA, Osten 2“ oder „Schweden, Mitte“ erstellt wurde. Weitere Informationen finden Sie unter Verfügbarkeit der Regionen.
- Anschließend müssen Sie ein
gpt-4o-realtime-preview-Modell mit Ihrer Azure OpenAI-Ressource bereitstellen. Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
Voraussetzungen für Microsoft Entra ID
Für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID müssen Sie:
- Die Azure CLI installieren, die für die schlüssellose Authentifizierung mit Microsoft Entra ID verwendet wird
- Weisen Sie Ihrem Benutzerkonto die
Cognitive Services User-Rolle zu. Sie können Rollen im Azure-Portal unter Zugriffssteuerung (IAM)>Rollenzuweisung hinzufügen zuweisen.
Bereitstellen eines Modells für Echtzeitaudio
So stellen Sie das gpt-4o-realtime-preview-Modell im Azure KI Foundry-Portal bereit:
- Wechseln Sie zum Azure KI Foundry-Portal, und stellen Sie sicher, dass Sie mit dem Azure-Abonnement angemeldet sind, das Ihre Azure OpenAI Service-Ressource enthält (mit oder ohne Modellimplementierungen).
- Wählen Sie im linken Bereich den Playground Echtzeitaudio unter Playgrounds aus.
- Wählen Sie Neue Bereitstellung erstellen aus, um das Bereitstellungsfenster zu öffnen.
- Suchen Sie nach dem Modell
gpt-4o-realtime-preview, wählen Sie es aus, und wählen Sie dann Bestätigen aus. - Wählen Sie im Bereitstellungs-Assistenten die
2024-12-17-Modellversion aus. - Durchlaufen Sie den Assistenten, um die Bereitstellung des Modells abzuschließen.
Nachdem Sie nun über eine Bereitstellung des Modells gpt-4o-realtime-preview verfügen, können Sie mit ihm im Playground Echtzeit-Audio oder der Echtzeit-API im Azure KI Foundry-Portal in Echtzeit interagieren.
Einrichten
Erstellen Sie einen neuen Ordner
realtime-audio-quickstartfür die Anwendung, und öffnen Sie Visual Studio Code in diesem Ordner mit dem folgenden Befehl:mkdir realtime-audio-quickstart && code realtime-audio-quickstartErstellen Sie
package.jsonmit dem folgenden Befehl:npm init -yAktualisieren Sie
package.jsonmit dem folgenden Befehl auf ECMAScript:npm pkg set type=moduleInstallieren Sie die Echtzeit-Audioclientbibliothek für JavaScript mit:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzInstallieren Sie für die empfohlene schlüssellose Authentifizierung mit Microsoft Entra ID das
@azure/identity-Paket mit:npm install @azure/identity
Abrufen von Ressourceninformationen
Sie müssen die folgenden Informationen abrufen, um Ihre Anwendung bei Ihrer Azure OpenAI-Ressource zu authentifizieren:
| Variablenname | Wert |
|---|---|
AZURE_OPENAI_ENDPOINT |
Diesen Wert finden Sie im Abschnitt Schlüssel und Endpunkt, wenn Sie die Ressource über das Azure-Portal untersuchen. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Dieser Wert entspricht dem benutzerdefinierten Namen, den Sie während der Bereitstellung eines Modells für die Bereitstellung ausgewählt haben. Diesen Wert finden Sie unter Ressourcenverwaltung>Modellbereitstellungen im Azure-Portal. |
OPENAI_API_VERSION |
Erfahren Sie mehr über API-Versionen. |
Erfahren Sie mehr über schlüssellose Authentifizierung und das Festlegen von Umgebungsvariablen.
Achtung
Um die empfohlene schlüssellose Authentifizierung mit dem SDK zu verwenden, stellen Sie sicher, dass die Umgebungsvariable AZURE_OPENAI_API_KEY nicht festgelegt ist.
Texteingabe, Audioausgabe
Erstellen Sie die Datei
text-in-audio-out.tsmit dem folgenden Code:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient( new URL(endpoint), new DefaultAzureCredential(), {deployment: deployment} ); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Erstellen Sie die Datei
tsconfig.json, um den TypeScript-Code zu transpilieren, und kopieren Sie den folgenden Code für ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpilieren Sie von TypeScript in JavaScript:
tscMelden Sie sich mithilfe des folgenden Befehls bei Azure an:
az loginFühren Sie den Code mithilfe des folgenden Befehls aus:
node text-in-audio-out.js
Die Ausgabe der Ergebnisse dauert einen Moment.
Output
Das Skript ruft eine Antwort vom Modell ab und gibt die empfangenen Transkript- und Audiodaten aus.
Die Ausgabe ist mit folgender Zeichenfolge vergleichbar:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Zugehöriger Inhalt
- Weitere Informationen finden Sie unter Verwenden der Echtzeit-API.
- Siehe Realtime-API-Referenz
- Erfahren Sie mehr über Kontingente und Grenzwerte in Azure OpenAI