Azure OpenAI: gespeicherte Fertigstellungen und Destillation (Vorschau)
Mit gespeicherten Fertigstellungen können Sie den Unterhaltungsverlauf aus Chatabschlusssitzungen erfassen, die als Datasets für Auswertungen und Feinabstimmungen verwendet werden.
Support für gespeicherte Fertigstellungen
API-Unterstützung
2024-10-01-preview
Modellunterstützung
gpt-4o-2024-08-06
Regionale Verfügbarkeit
- Schweden, Mitte
- USA Nord Mitte
- USA (Ost 2)
Konfiguration von gespeicherten Fertigstellungen
Um gespeicherte Fertigstellungen für Ihre Azure OpenAI-Bereitstellung zu aktivieren, legen Sie die Einstellung store auf True fest. Verwenden Sie die Einstellungmetadata, um das gespeicherte Fertigstellungs-Dataset mit zusätzlichen Informationen zu erweitern.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
Sobald gespeicherte Fertigstellungen für eine Azure OpenAI-Bereitstellung aktiviert sind, werden sie im Azure AI Foundry-Portal im Bereich gespeicherte Fertigstellungen angezeigt.

Destillation
Mit der Destillation können Sie Ihre gespeicherten Fertigstellungen in ein fein abgestimmtes Dataset umwandeln. Ein gängiger Anwendungsfall ist die Verwendung gespeicherter Fertigstellungen mit einem größeren, leistungsfähigeren Modell für eine bestimmte Aufgabe und die anschließende Verwendung der gespeicherten Fertigstellungen zum Trainieren eines kleineren Modells anhand hochwertiger Beispiele für Modellinteraktionen.
Für die Destillation sind mindestens 10 gespeicherte Fertigstellungen erforderlich. Es wird jedoch empfohlen, Hunderte bis Tausende von gespeicherten Fertigstellungen bereitzustellen, um die besten Ergebnisse zu erzielen.
Verwenden Sie im Bereich gespeicherte Fertigstellungen im Azure AI Foundry-Portal die Optionen Filter, um die Fertigstellungen auszuwählen, mit denen Sie Ihr Modell trainieren möchten.
Um mit der Destillation zu beginnen, wählen Sie Destillieren aus
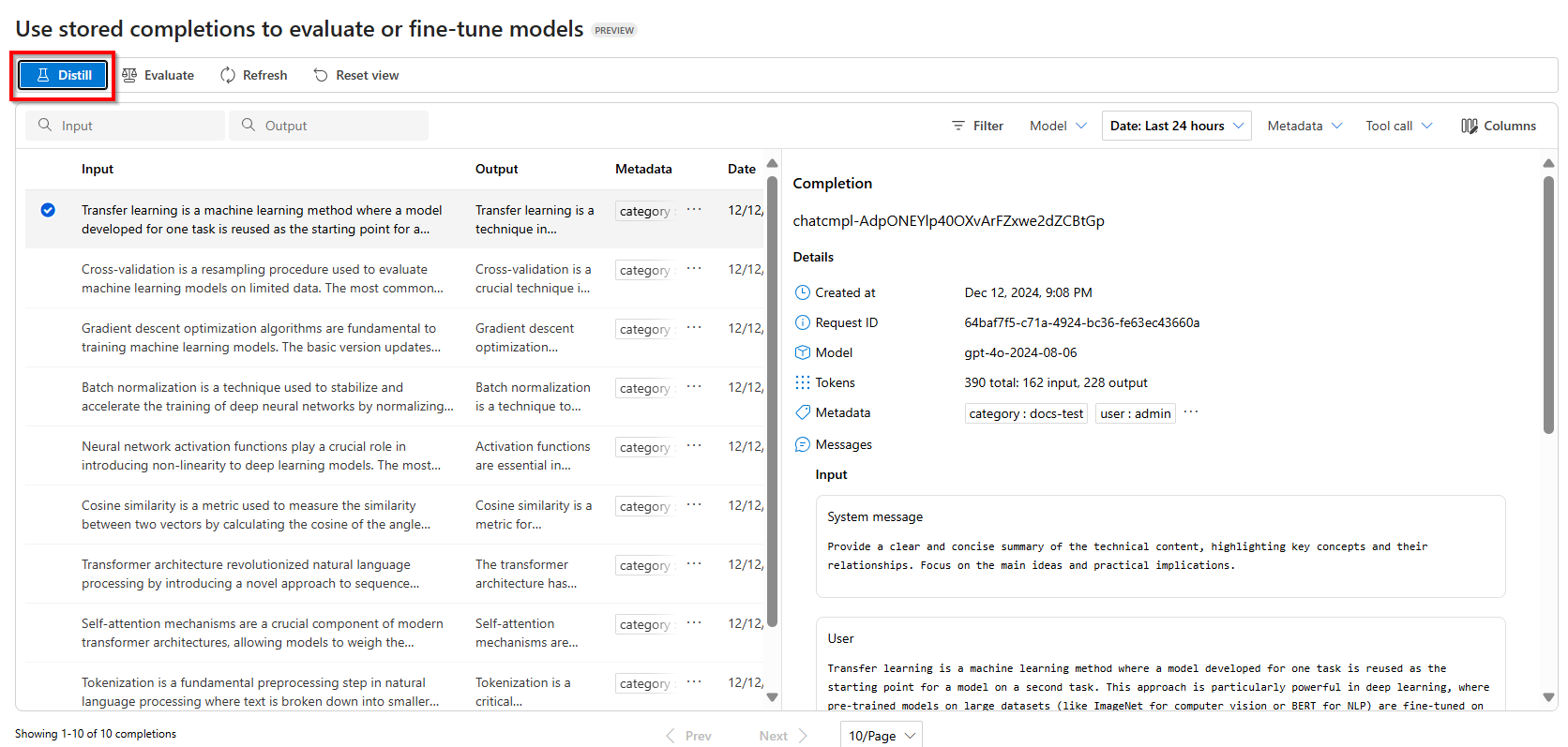
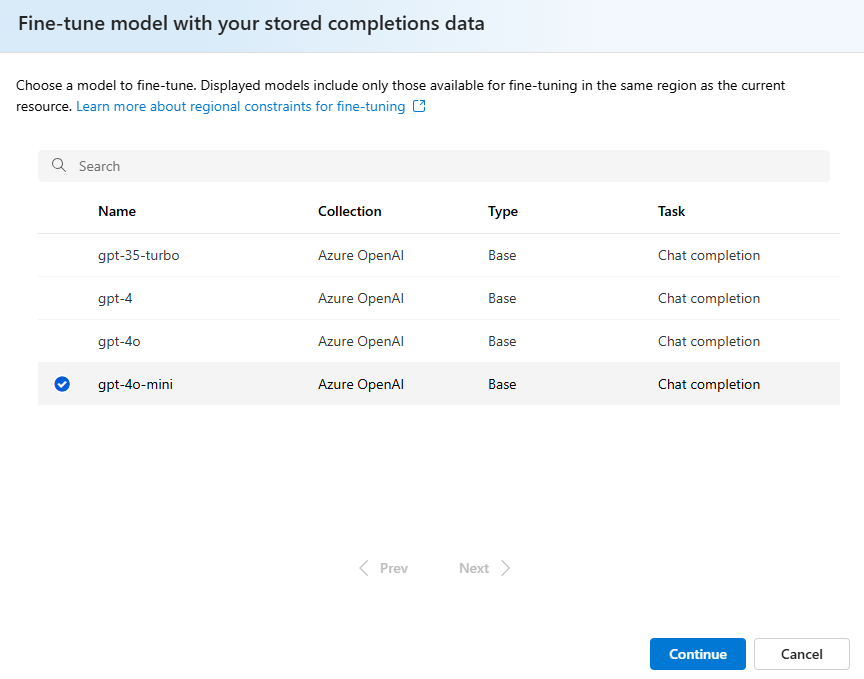
Wählen Sie das Modell aus, das Sie mit Ihrem gespeicherten Fertigstellungs-Dataset optimieren möchten.
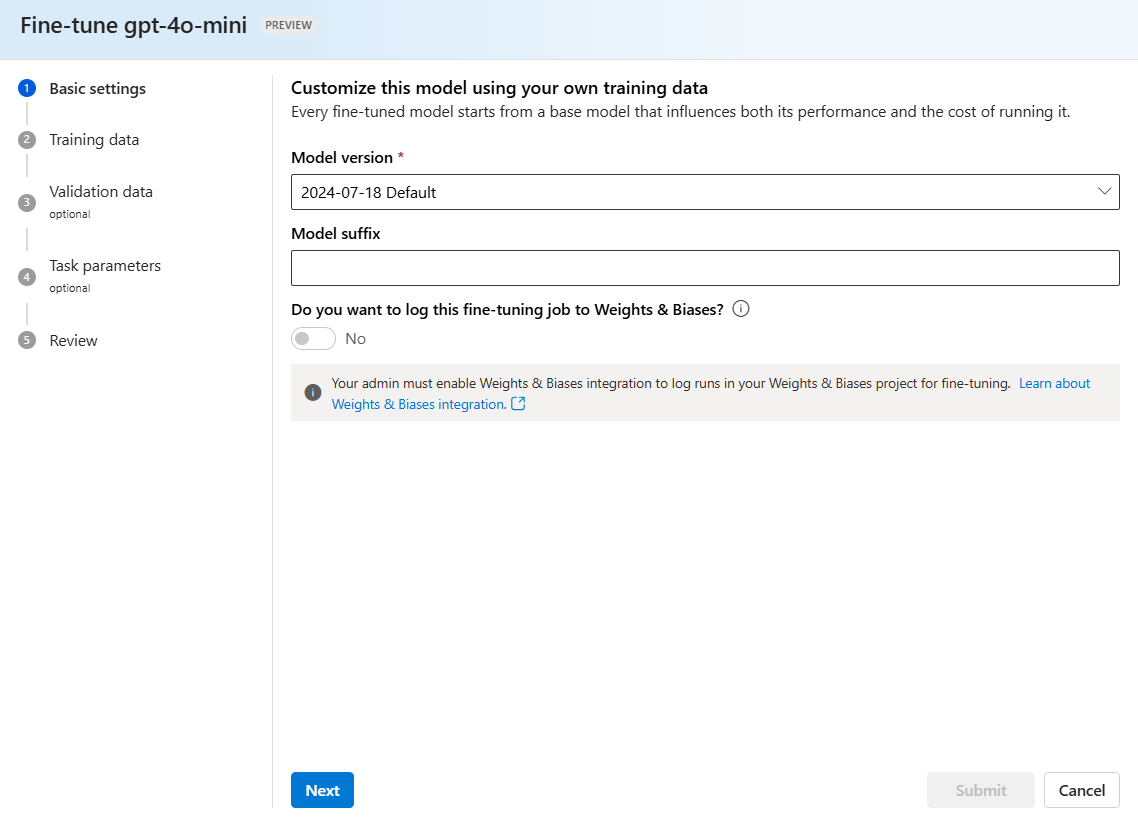
Bestätigen Sie, welche Version des Modells Sie optimieren möchten:
Eine
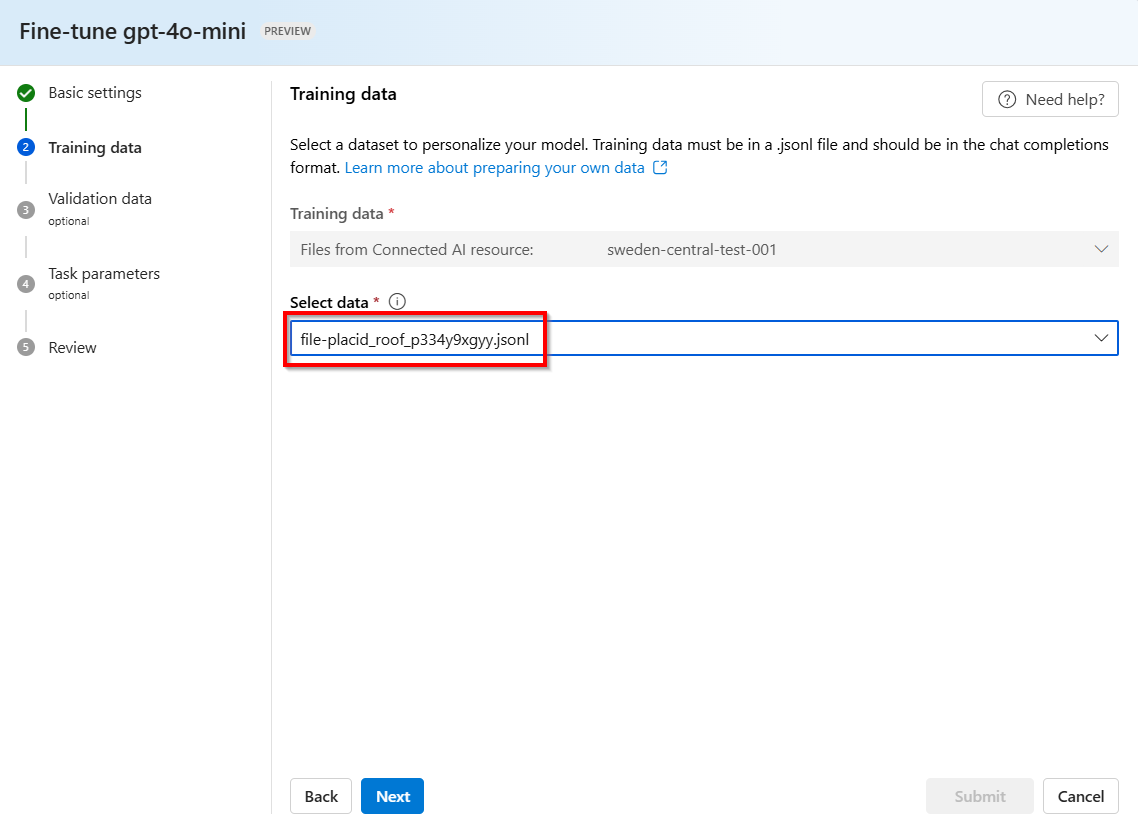
.jsonl-Datei mit einem zufällig generierten Namen wird als Schulungs-Dataset aus Ihren gespeicherten Fertigstellungen erstellt. Wählen Sie die Datei >Weiter aus.Hinweis
Auf gespeicherte Fertigstellungs-destillationsschulungsdateien kann nicht direkt zugegriffen werden und sie können nicht extern exportiert bzw. heruntergeladen werden.




Die restlichen Schritte entsprechen den typischen Azure OpenAI-Optimierungsschritten. Weitere Informationen finden Sie im Leitfaden: Erste Schritte zur Optimierung.
Auswertung
Die Auswertung großer Sprachmodelle ist ein wichtiger Schritt bei der Messung ihrer Leistung über verschiedene Aufgaben und Dimensionen hinweg. Dies ist besonders wichtig für fein abgestimmte Modelle, bei denen die Beurteilung der Leistungsgewinne (oder Verluste) aus dem Training von entscheidender Bedeutung ist. Gründliche Auswertungen können Ihnen dabei helfen, zu verstehen, wie sich verschiedene Versionen des Modells auf Ihre Anwendung oder Ihr Szenario auswirken können.
Gespeicherte Fertigstellungen können als Dataset für laufende Auswertungen verwendet werden.
Verwenden Sie im Bereich gespeicherte Fertigstellungen im Azure AI Foundry-Portal die Optionen Filter, um die Fertigstellungen auszuwählen, die Teil Ihres Auswertungs-Dataset sein sollen.
Um die Auswertung zu konfigurieren, wählen Sie Auswerten aus
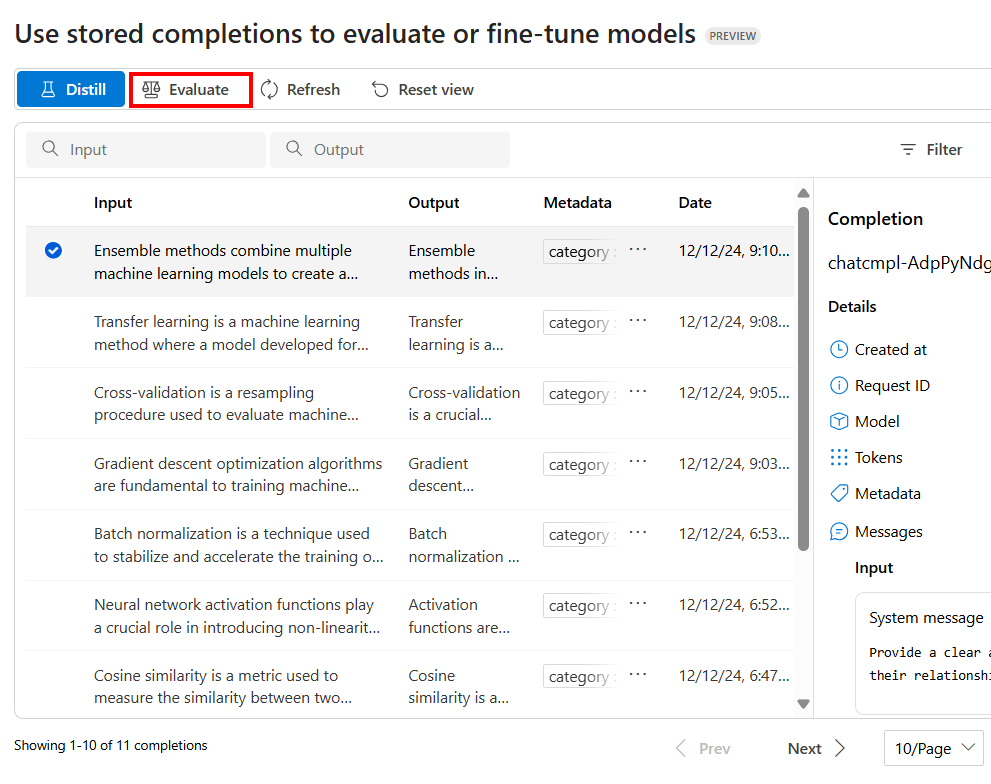
Dadurch wird der Bereich Auswertungen mit einer vorausgefüllten
.jsonl-Datei mit einem zufällig generierten Namen gestartet, die als Auswertungs-Dataset aus Ihren gespeicherten Fertigstellungen erstellt wird.Hinweis
Auf gespeicherte Fertigstellungs-Bewertungsdatendateien kann nicht direkt zugegriffen und sie können nicht extern exportiert bzw. heruntergeladen werden.


Weitere Informationen zur Auswertung finden Sie unter Erste Schritte mit Auswertungen
Problembehandlung
Benötige ich spezielle Berechtigungen, um gespeicherte Fertigstellungen zu verwenden?
Der Zugriff auf gespeicherte Fertigstellungen wird über zwei DataActions gesteuert:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
Standardmäßig hat Cognitive Services OpenAI Contributor Zugriff auf beide Berechtigungen:

Wie lösche ich gespeicherte Daten?
Daten können gelöscht werden, indem die zugeordnete Azure OpenAI-Ressource gelöscht wird. Wenn Sie nur gespeicherte Fertigstellungsdaten löschen möchten, müssen Sie einen Fall beim Kundensupport öffnen.
Wie viel gespeicherte Fertigstellungsdaten kann ich speichern?
Sie können maximal 10 GB Daten speichern.
Kann ich verhindern, dass gespeicherte Fertigstellungen in einem Abonnement aktiviert werden?
Sie müssen einen Fall beim Kundensupport öffnen, um gespeicherte Fertigstellungen auf Abonnementebene zu deaktivieren.
TypeError: Completions.create() got an unexpected argument 'store'
Dieser Fehler tritt auf, wenn Sie eine ältere Version der OpenAI-Clientbibliothek verwenden, die vor der Veröffentlichung der Funktion für gespeicherte Vervollständigungen veröffentlicht wurde. Führen Sie pip install openai --upgrade aus.