Anpassen eines Modells mit Feinabstimmung
Mit Azure OpenAI Service können Sie unsere Modelle mit einem Prozess für Ihre persönlichen Datasets anpassen, der als Optimierung bezeichnet wird. Mit diesem Anpassungsschritt können Sie den Dienst besser nutzen, da er Folgendes bieten kann:
- Qualitativ hochwertigere Ergebnisse als die, die Sie nur durch schnelle Datentechnik erhalten können
- Die Möglichkeit, mit mehr Beispielen zu trainieren, als in den maximalen Anfragekontext eines Modells passen.
- Tokeneinsparungen durch kürzere Eingabeaufforderungen
- Anforderungen mit geringerer Latenz, insbesondere bei Verwendung kleinerer Modelle.
Im Gegensatz zum Few-Shot-Lernen verbessert die Feinabstimmung das Modell durch Training mit wesentlich mehr Beispielen, als in eine Eingabeaufforderung passen, sodass Sie bessere Ergebnisse für eine Vielzahl von Aufgaben erzielen können. Da die Feinabstimmung die Gewichtungen des Basismodells anpasst, um die Leistung für den jeweiligen Vorgang zu verbessern, müssen Sie nicht so viele Beispiele oder Anweisungen in die Eingabeaufforderung aufnehmen. Das bedeutet, es werden für jeden API-Aufruf weniger Text gesendet und weniger Token verarbeitet, was möglicherweise Kosten spart und die Latenz von Anforderungen verbessert.
Wir verwenden LoRA (Low Rank Approximation), um Modelle so zu optimieren, dass ihre Komplexität reduziert wird, ohne die Leistung erheblich zu beeinträchtigen. Bei dieser Methode wird die ursprüngliche Matrix mit hohem Rang durch eine Matrix mit niedrigerem Rang approximiert, so dass während der überwachten Trainingsphase nur eine kleinere Teilmenge der wichtigen Parameter optimiert wird, was das Modell handhabbarer und effizienter macht. Für Benutzer wird das Training so schneller und erschwinglicher als mit anderen Techniken.
Das Azure KI Foundry-Portal bietet zwei einzigartige Optimierungsumgebungen:
- Hub-/Projektansicht: unterstützt die Feinabstimmung von Modellen mehrerer Anbieter wie Azure OpenAI, Meta Llama, Microsoft Phi usw.
- Azure OpenAI-zentrische Ansicht: unterstützt nur die Feinabstimmungen von Azure OpenAI-Modellen, bietet jedoch Unterstützung für zusätzliche Features wie die Weights & Biases-Vorschauintegration (W&B).
Wenn Sie nur Azure OpenAI-Modelle optimieren, wird die Azure OpenAI-zentrische Feinabstimmung empfohlen, die Sie durch Navigieren zu https://oai.azure.com erreichen.
Voraussetzungen
- Lesen Sie den Leitfaden Einsatzgebiete für die Optimierung mit Azure OpenAI.
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
- Eine Azure OpenAI-Ressource in einer Region, die die Optimierung des Azure OpenAI-Modells unterstützt. In der Tabelle mit der Modellzusammenfassung und der regionalen Verfügbarkeit finden Sie eine Liste der verfügbaren Modelle nach Region und unterstützten Funktionen. Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
- Für den Zugriff auf die Optimierung ist Mitwirkender für Cognitive Services OpenAI erforderlich.
- Wenn Sie noch keinen Zugriff auf die Kontingentanzeige haben und Modelle im Azure KI Foundry-Portal bereitstellen, benötigen Sie zusätzliche Berechtigungen.
Modelle
Die folgenden Modelle unterstützen die Optimierung:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Die Feinabstimmung für dieses Modell befindet sich derzeit in der öffentlichen Vorschau.
Oder Sie können ein zuvor feinabgestimmtes Modell optimieren, das als „base-model.ft-{jobid}“ formatiert ist.
Schauen Sie sich die Modellseite an, um zu überprüfen, welche Regionen derzeit Optimierung unterstützen.
Überblick über den Workflow für das Azure AI Foundry-Portal
Nehmen Sie sich einen Moment Zeit, um sich den Optimierungsworkflow für die Verwendung des Azure AI Foundry-Portals anzusehen.
- Bereiten Sie Ihre Trainings- und Validierungsdaten vor.
- Verwenden Sie den Assistenten zum Erstellen benutzerdefinierter Modelle im Azure KI Foundry-Portal zum Trainieren Ihres benutzerdefinierten Modells.
- Wählen Sie ein Basismodell aus.
- Wählen Sie die Trainingsdaten aus.
- Wählen Sie optional Ihre Validierungsdaten aus.
- Konfigurieren Sie optional Aufgabenparameter für Ihren Optimierungsauftrag.
- Überprüfen Sie Ihre Auswahl, und trainieren Sie das neue benutzerdefinierte Modell.
- Überprüfen des Status Ihres optimierten Modells.
- Stellen Sie Ihr benutzerdefiniertes Modell für die Verwendung bereit.
- Verwenden Sie Ihr benutzerdefiniertes Modell.
- Optional: Analysieren Sie die Leistung und Eignung Ihres benutzerdefinierten Modells.
Vorbereiten Ihrer Trainings- und Validierungsdaten
Ihre Trainings- und Validierungsdatasets bestehen aus Ein- und Ausgabebeispielen für das gewünschte Verhalten des Modells.
Die Trainings- und Validierungsdaten, die Sie verwenden, müssen als JSON Lines (JSONL)-Dokument formatiert werden. Für gpt-35-turbo (alle Versionen), gpt-4, gpt-4o und gpt-4o-mini muss das Optimierungsdataset im Konversationsformat formatiert sein, das von der Chatvervollständigungs-API verwendet wird.
Wenn Sie eine Schrittanleitung zur Optimierung eines gpt-4o-mini Modells (2024-07-18) wünschen, sehen Sie sich das Azure OpenAI-Optimierungstutorial an.
Beispieldateiformat
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Dateiformat für mehrteiligen Chat in Azure OpenAI
Mehrteilige Unterhaltungen in einer einzigen Zeile Ihrer JSONL-Trainingsdatei werden ebenfalls unterstützt. Um die Feinabstimmung für bestimmte Assistentenmeldungen zu überspringen, fügen Sie das optionale weight-Schlüsselwertpaar hinzu. Derzeit kann weight auf 0 oder 1 festgelegt werden.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvervollständigungen mit Vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Zusätzlich zum JSONL-Format müssen Dateien mit Trainings- und Validierungsdaten in UTF-8 codiert sein und eine Bytereihenfolge-Marke (BOM) enthalten. Die Datei muss kleiner als 512 MB sein.
Erstellen von Trainings- und Validierungsdatasets
Je mehr Trainingsbeispiele Sie haben, desto besser. Für die Feinabstimmung sind mindestens 10 Trainingsbeispiele erforderlich, aber eine so geringe Anzahl reicht nicht aus, um die Reaktionen des Modells merklich zu beeinflussen. Es empfiehlt sich, Hunderte, wenn nicht Tausende von Trainingsbeispielen bereitzustellen, um erfolgreich zu sein.
Im Allgemeinen führt eine Verdoppelung der Datasetgröße zu einer linearen Erhöhung der Modellqualität. Bedenken Sie jedoch, dass Beispiele mit geringer Qualität die Leistung beeinträchtigen können. Wenn Sie das Modell mit vielen internen Daten trainieren, ohne zuvor das Dataset zu bereinigen, sodass es nur noch Beispiele mit höchster Qualität enthält, erhalten Sie möglicherweise ein Modell, das viel schlechter funktioniert als erwartet.
Verwenden des Assistenten zum Erstellen benutzerdefinierter Modelle
Das Azure AI Foundry-Portal bietet den Assistenten zum Erstellen benutzerdefinierter Modelle, damit Sie interaktiv ein optimiertes Modell für Ihre Azure-Ressource erstellen und trainieren können.
Öffnen Sie das Azure AI Foundry-Portal unter https://oai.azure.com/, und melden Sie sich mit Anmeldeinformationen an, die Ihnen Zugriff auf Ihre Azure OpenAI-Ressource gewähren. Wählen Sie während des Anmeldeworkflows das passende Verzeichnis, Azure-Abonnement und die Azure OpenAI-Ressource aus.
Navigieren Sie im Azure KI Foundry-Portal zum Bereich Tools > Optimierung, und wählen Sie Modell optimieren aus.

Der Assistent zum Erstellen benutzerdefinierter Modelle wird geöffnet.
Auswählen des Basismodells
Der erste Schritt beim Erstellen eines benutzerdefinierten Modells besteht in der Auswahl eines Basismodells. Im Bereich Basismodell können Sie ein Basismodell auswählen, das für Ihr benutzerdefiniertes Modell verwendet werden soll. Ihre Auswahl hat sowohl auf die Leistung als auch auf die Kosten Ihres Modells Einfluss.
Wählen Sie das Basismodell in der Dropdownliste Basismodelltyp und dann Weiter aus, um fortzufahren.
- Oder Sie können ein zuvor feinabgestimmtes Modell optimieren, das als „base-model.ft-{jobid}“ formatiert ist.

Weitere Informationen zu unseren verfeinerbaren Basismodellen finden Sie unter Modelle.
Auswahl Ihrer Trainingsdaten
Der nächste Schritt besteht darin, entweder vorhandene vorbereitete Trainingsdaten auszuwählen oder neue vorbereitete Trainingsdaten für die Verwendung beim Anpassen des Modells hochzuladen. Im Bereich Trainingsdaten werden alle vorhandenen, zuvor hochgeladenen Datasets sowie Optionen zum Hochladen neuer Trainingsdaten angezeigt.

Wenn Ihre Trainingsdaten bereits in den Dienst hochgeladen wurden, wählen Sie Dateien aus Azure OpenAI-Verbindung aus.
- Wählen Sie die Datei aus der angezeigten Dropdownliste aus.
Verwenden Sie eine der folgenden Optionen, um neue Trainingsdaten hochzuladen:
Wählen Sie Lokale Datei aus, um Trainingsdaten aus einer lokalen Datei hochzuladen.
Wählen Sie Azure Blob Storage oder andere freigegebene Webspeicherorte aus, um Trainingsdaten aus Azure Blob Storage oder einem anderen freigegebenen Webspeicherort zu importieren.
Für große Datendateien wird der Import aus Azure Blob Storage empfohlen. Große Dateien können instabil werden, wenn sie über mehrteilige Formulare hochgeladen werden, da die Anforderungen atomar sind und nicht erneut ausgeführt oder fortgesetzt werden können. Weitere Informationen zu Azure Blob Storage finden Sie unter Was ist Azure Blob Storage?.
Hinweis
Dateien mit Trainingsdaten müssen als JSONL-Dateien formatiert und in UTF-8 mit BOM (Bytereihenfolge-Marke) codiert groß sein. Die Datei muss kleiner als 512 MB sein.
Hochladen von Trainingsdaten aus einer lokalen Datei
Sie können ein neues Trainingsdataset aus einer lokalen Datei in den Dienst hochladen, indem Sie eine der folgenden Methoden verwenden:
Ziehen Sie die Datei per Drag & Drop in den Clientbereich des Bereichs Trainingsdaten, und wählen Sie anschließend Datei hochladen aus.
Wählen Sie im Clientbereich des Bereichs TrainingsdatenNach einer Datei suchen aus, wählen Sie im Dialogfeld Öffnen die hochzuladende Datei und dann Datei hochladen aus.
Nachdem Sie das Trainingsdataset ausgewählt und hochgeladen haben, wählen Sie Weiter aus, um fortzufahren.

Importieren von Trainingsdaten aus Azure Blob Storage
Sie können ein Trainingsdataset aus Azure Blob Storage oder einem anderen freigegebenen Webspeicherort importieren, indem Sie den Namen und den Speicherort der Datei angeben.
Geben Sie den Dateinamen der Datei ein.
Geben Sie als Dateispeicherort die Azure Blob Storage-URL, die Azure Storage-SAS (Shared Access Signature) oder einen anderen Link zu einem zugänglichen freigegebenen Webspeicherort an.
Wählen Sie Importieren aus, um das Trainingsdataset in den Dienst zu importieren.
Nachdem Sie das Trainingsdataset ausgewählt und hochgeladen haben, wählen Sie Weiter aus, um fortzufahren.

Auswählen Ihrer Validierungsdaten
Der nächste Schritt bietet Optionen zum Konfigurieren des Modells für die Verwendung von Validierungsdaten im Trainingsprozess. Wenn Sie keine Validierungsdaten verwenden möchten, können Sie Weiter auswählen, um erweiterte Optionen für das Modell auszuwählen. Andernfalls können Sie, falls Sie über ein Validierungsdataset verfügen, entweder vorhandene vorbereitete Validierungsdaten oder neue vorbereitete Validierungsdaten für die Verwendung beim Anpassen Ihres Modells auswählen.
Im Bereich Validierungsdaten werden alle vorhandenen, zuvor hochgeladenen Trainings- und Validierungsdatasets und Optionen für das Hochladen neuer Validierungsdaten angezeigt.

Wenn Ihre Validierungsdaten bereits in den Dienst hochgeladen wurden, wählen Sie Dataset auswählen aus.
- Wählen Sie die Datei in der Liste aus, die im Bereich Validierungsdaten angezeigt wird.
Verwenden Sie eine der folgenden Optionen, um neue Validierungsdaten hochzuladen:
Wählen Sie Lokale Datei aus, um Validierungsdaten aus einer lokalen Datei hochzuladen.
Wählen Sie Azure Blob Storage oder andere freigegebene Webspeicherorte aus, um Validierungsdaten aus Azure Blob Storage oder einem anderen freigegebenen Webspeicherort zu importieren.
Für große Datendateien wird der Import aus Azure Blob Storage empfohlen. Große Dateien können instabil werden, wenn sie über mehrteilige Formulare hochgeladen werden, da die Anforderungen atomar sind und nicht erneut ausgeführt oder fortgesetzt werden können.
Hinweis
Wie Trainingsdatendateien müssen auch Dateien mit Validierungsdaten als JSONL-Dateien formatiert und in UTF-8 mit BOM (Bytereihenfolge-Marke) codiert sein. Die Datei muss kleiner als 512 MB sein.
Hochladen von Validierungsdaten aus einer lokalen Datei
Sie können ein neues Validierungsdataset aus einer lokalen Datei in den Dienst hochladen, indem Sie eine der folgenden Methoden verwenden:
Ziehen Sie die Datei per Drag & Drop in den Clientbereich des Bereichs Validierungsdaten, und wählen Sie anschließend Datei hochladen aus.
Wählen Sie im Clientbereich des Bereichs ValidierungsdatenNach einer Datei suchen aus, wählen Sie im Dialogfeld Öffnen die hochzuladende Datei und dann Datei hochladen aus.
Nachdem Sie das Validierungsdataset ausgewählt und hochgeladen haben, wählen Sie Weiter aus, um fortzufahren.

Importieren von Validierungsdaten aus Azure Blob Storage
Sie können ein Validierungsdataset aus Azure Blob Storage oder einem anderen freigegebenen Webspeicherort importieren, indem Sie den Namen und den Speicherort der Datei angeben.
Geben Sie den Dateinamen der Datei ein.
Geben Sie als Dateispeicherort die Azure Blob Storage-URL, die Azure Storage-SAS (Shared Access Signature) oder einen anderen Link zu einem zugänglichen freigegebenen Webspeicherort an.
Wählen Sie Importieren aus, um das Trainingsdataset in den Dienst zu importieren.
Nachdem Sie das Validierungsdataset ausgewählt und hochgeladen haben, wählen Sie Weiter aus, um fortzufahren.

Konfigurieren von Aufgabenparametern
Der Assistent zum Erstellen benutzerdefinierter Modelle zeigt im Bereich Aufgabenparameter Parameter zum Trainieren Ihres optimierten Modells an. Folgende Parameter sind verfügbar:
| Name | Art | Beschreibung |
|---|---|---|
batch_size |
integer | Die für das Training zu verwendende Batchgröße. Die Batchgröße ist die Anzahl der Trainingsbeispiele, die zum Trainieren eines einzelnen Vorwärts- und Rückwärtsdurchlaufs verwendet werden. Im Allgemeinen haben wir festgestellt, dass größere Batchgrößen für größere Datasets besser funktionieren. Der Standardwert sowie der Maximalwert für diese Eigenschaft sind spezifisch für ein Basismodell. Eine größere Batchgröße bedeutet, dass Modellparameter weniger häufig aktualisiert werden, aber mit geringerer Varianz. |
learning_rate_multiplier |
Zahl | Der Lernratenmultiplikator, der für das Training verwendet werden soll. Die Optimierungslernrate ist die ursprüngliche Lernrate, die für das Vorabtraining verwendet wird, mit diesem Wert multipliziert. Größere Lernraten sind tendenziell besser für größere Batchgrößen. Es empfiehlt sich, mit Werten im Bereich 0,02 bis 0,2 zu experimentieren, um zu sehen, was die besten Ergebnisse erzeugt. Eine kleinere Lernrate kann nützlich sein, um Überanpassung zu vermeiden. |
n_epochs |
integer | Die Anzahl der Epochen zum Trainieren des Modells. Eine Epoche bezeichnet einen vollständigen Zyklus über das Trainingsdataset. |
seed |
integer | Der Seed steuert die Reproduzierbarkeit des Auftrags. Die Übergabe der gleichen Seed- und Auftragsparameter sollte zu den gleichen Ergebnissen führen, kann sich aber in seltenen Fällen unterscheiden. Wenn Sie keinen Seed angeben, wird ein Seed für Sie generiert. |
Beta |
integer | Temperaturparameter für den DPO-Verlust, in der Regel im Bereich von 0,1 bis 0,5. Dies steuert, wie viel Aufmerksamkeit wir dem Referenzmodell schenken. Je kleiner der Beta-Wert ist, desto mehr darf das Modell vom Referenzmodell abweichen. Je kleiner Beta wird, desto mehr ignorieren wir das Referenzmodell. |

Wählen Sie entweder Standard aus, um die Standardwerte für den Optimierungsauftrag zu verwenden, oder wählen Sie Benutzerdefiniert aus, um die Hyperparameterwerte anzuzeigen und zu bearbeiten. Wenn Standardwerte ausgewählt sind, bestimmen wir den richtigen Wert algorithmisch basierend auf Ihren Trainingsdaten.
Nachdem Sie die erweiterten Optionen konfiguriert haben, wählen Sie Weiter aus, um Ihre Auswahl zu überprüfen und Ihr optimiertes Modell zu trainieren.
Überprüfen Ihrer Auswahl und Trainieren Ihres Modells
Im Bereich Überprüfen des Assistenten werden Informationen zu Ihren Konfigurationsoptionen angezeigt.

Wenn Sie bereit sind, Ihr Modell zu trainieren, wählen Sie Trainingsauftrag starten, um den Optimierungsauftrag zu starten und zum Fensterbereich Modelle zurückzukehren.
Überprüfen des Status Ihres benutzerdefinierten Modells
Im Bereich Modelle werden Informationen zu Ihrem benutzerdefinierten Modell auf der Registerkarte Benutzerdefinierte Modelle angezeigt. Die Registerkarte enthält Informationen zum Status und zur Auftrags-ID des Optimierungsauftrags für Ihr benutzerdefiniertes Modell. Nach Abschluss des Auftrags wird auf der Registerkarte die Datei-ID der Ergebnisdatei angezeigt. Möglicherweise müssen Sie Aktualisieren auswählen, um einen aktualisierten Status für den Modelltrainingsauftrag anzuzeigen.

Ein Optimierungsauftrag benötigt nach dem Start möglicherweise einige Zeit bis zum Abschluss. Ihr Auftrag befindet sich möglicherweise in der Warteschlange hinter anderen Aufträgen im System. Das Trainieren Ihres Modells kann je nach Größe von Modell und Dataset Minuten oder Stunden dauern.
Im Folgenden finden Sie einige Aufgaben, die Sie im Bereich Modelle ausführen können:
Überprüfen Sie den Status des Optimierungsauftrags für Ihr benutzerdefiniertes Modell in der Spalte Status auf der Registerkarte Benutzerdefinierte Modelle.
Wählen Sie in der Spalte Modellname den Modellnamen aus, um weitere Informationen zum benutzerdefinierten Modell anzuzeigen. Sie können den Status des Optimierungsauftrags, die Trainingsergebnisse, die Trainingsereignisse und die Hyperparameter anzeigen, die für den Auftrag verwendet wurden.
Wählen Sie Trainingsdatei herunterladen aus, um die Trainingsdaten herunterzuladen, die Sie für das Modell verwendet haben.
Wählen Sie Ergebnisse herunterladen aus, um die Ergebnisdatei herunterzuladen, die an den Optimierungsauftrag für Ihr Modell angefügt ist, und eine Analyse Ihres benutzerdefinierten Modells im Hinblick auf seine Trainings- und Validierungsleistung durchführen.
Wählen Sie Aktualisieren aus, um die Informationen auf der Seite zu aktualisieren.
Prüfpunkte
Nach Abschluss jeder Trainingsepoche wird Prüfpunkt generiert. Ein Prüfpunkt ist eine voll funktionsfähige Version eines Modells, das sowohl bereitgestellt als auch als Zielmodell für nachfolgende Feinabstimmungsaufträge genutzt werden kann. Prüfpunkte können besonders nützlich sein, da sie eine Momentaufnahme Ihres Modells bereitstellen können, bevor eine Überanpassung auftritt. Wenn ein Feinabstimmungsauftrag abgeschlossen ist, stehen Ihnen die letzten drei Versionen des Modells zur Bereitstellung zur Verfügung.
Sicherheitsbewertung für GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung: Public Preview
GPT-4, GPT-4o und GPT-4o-mini sind unsere fortschrittlichsten Modelle, die per Optimierung genau auf Ihre Anforderungen zugeschnitten werden können. Wie auch Azure OpenAI-Modelle allgemein bringen die erweiterten Funktionen fein abgestimmter Modelle zusätzliche Herausforderungen im Bereich verantwortungsvolle KI mit sich, die mit schädlichen Inhalten, Manipulation, menschenähnlichem Verhalten, Datenschutzproblemen und anderen Aspekten zusammenhängen. Weitere Informationen zu Risiken, Funktionen und Einschränkungen finden Sie in der Übersicht über verantwortungsvolle KI-Methoden und dem Transparenzhinweis. Um dazu beizutragen, die Risiken zu mindern, die Modelle mit erweiterter Optimierung mit sich bringen, wurden zusätzliche Bewertungsschritte implementiert, die helfen, schädliche Inhalte beim Training und in Ausgaben von optimierten Modellen zu erkennen und zu verhindern. Diese Schritte basieren auf dem Microsoft Responsible AI Standard (Microsoft-Standard für verantwortungsvolle KI) und der Inhaltsfilterung von Azure OpenAI Service.
- Bewertungen werden in dedizierten und kundenspezifischen privaten Arbeitsbereichen durchgeführt.
- Die Bewertungsendpunkte befinden sich am selben geografischen Standort wie die Azure OpenAI-Ressource.
- In Verbindung mit der Durchführung von Bewertungen werden keine Trainingsdaten gespeichert. Nur die finale Modellbewertung (bereitstellbar oder nicht bereitstellbar) wird persistent gespeichert.
Die Bewertungsfilter für Modelle mit GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung sind auf voreingestellte Schwellenwerte festgelegt, die auf Kundenseite nicht geändert werden können. Sie hängen nicht mit benutzerdefinierten Inhaltsfilterkonfigurationen zusammen, die Sie möglicherweise erstellt haben.
Bewertung von Daten
Vor Beginn des Trainings wird eine Bewertung Ihrer Daten hinsichtlich potenziell schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness, Selbstverletzung – siehe Kategoriedefinitionen unter diesem Link) vorgenommen. Wenn schädliche Inhalte mit einem höheren Schweregrad als dem festgelegten erkannt werden, tritt bei Ihrem Trainingsauftrag ein Fehler auf, und es wird eine Benachrichtigung mit den Fehlerkategorien angezeigt.
Beispielbenachrichtigung:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Ihre Trainingsdaten werden automatisch während des Datenimportauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet.
Wenn während des Feinabstimmungsauftrags aufgrund der Erkennung schädlicher Inhalte in Trainingsdaten ein Fehler auftritt, wird Ihnen dieser Auftrag nicht in Rechnung gestellt.
Modellauswertung
Nach Abschluss des Trainings, aber bevor das fein abgestimmte Modell für die Bereitstellung verfügbar ist, wird das resultierende Modell mithilfe der integrierten Risiko- und Sicherheitsmetriken von Azure hinsichtlich potenziell schädlicher Antworten bewertet. Mit dem Testansatz, den wir auch für grundlegende große Sprachmodelle verwenden, simuliert unsere Bewertungsfunktion eine Unterhaltung mit Ihrem fein abgestimmten Modell, um die Wahrscheinlichkeit, dass schädliche Inhalte ausgegeben werden, zu bewerten. Hierbei werden ebenfalls festgelegte Kategorien schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness und Selbstverletzung) verwendet.
Wenn festgestellt wird, dass ein Modell Ausgaben mit Inhalten generiert, die als schädlicher als ein akzeptabler Grad eingestuft werden, werden Sie darüber informiert, dass Ihr Modell nicht für die Bereitstellung verfügbar ist. Diese Benachrichtigung enthält außerdem Informationen zu den konkreten Kategorien schädlicher Inhalte, die erkannt wurden:
Beispielbenachrichtigung:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Wie bei der Datenbewertung wird das Modell automatisch während des Feinabstimmungsauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet. Nur die daraus resultierende Bewertung (bereitstellbar oder nicht bereitstellbar) wird vom Dienst protokolliert. Wenn bei der Bereitstellung des fein abgestimmten Modells aufgrund der Erkennung schädlicher Inhalte in Modellausgaben ein Fehler auftritt, wird Ihnen die Trainingsausführung nicht in Rechnung gestellt.
Bereitstellen eines optimierten Modells
Wenn der Optimierungsauftrag erfolgreich war, können Sie das benutzerdefinierte Modell im Bereich Modelle bereitstellen. Sie müssen Ihr benutzerdefiniertes Modell bereitstellen, um es für die Verwendung in Vervollständigungsaufrufen verfügbar zu machen.
Wichtig
Bleibt die Bereitstellung eines angepassten Modells nach der Bereitstellung länger als fünfzehn (15) Tage inaktiv, wird die Bereitstellung gelöscht. Die Bereitstellung eines angepassten Modells ist inaktiv, wenn das Modell vor mehr als fünfzehn (15) Tagen bereitgestellt wurde und während eines ununterbrochenen Zeitraums von 15 Tagen keine Abschluss- oder Chatabschlussaufrufe an das Modell übermittelt wurden.
Durch das Löschen einer inaktiven Bereitstellung wird das zugrunde liegende angepasste Modell nicht gelöscht oder verändert. Das angepasste Modell kann jederzeit erneut bereitgestellt werden. Wie unter Preise für Azure OpenAI Service beschrieben, fallen für jedes benutzerdefinierte (optimierte) bereitgestellte Modell stündliche Hostingkosten an, unabhängig davon, ob das Modell für Vervollständigungs- oder Chatvervollständigungsaufrufe genutzt wird. Weitere Informationen zum Planen und Verwalten der Kosten mit Azure OpenAI finden Sie im Leitfaden unter Planen und Verwalten der Kosten für Azure OpenAI Service.
Hinweis
Für ein benutzerdefiniertes Modell ist nur eine Bereitstellung zulässig. Wenn Sie ein bereits bereitgestelltes benutzerdefiniertes Modell auswählen, wird eine Fehlermeldung angezeigt.
Um ein benutzerdefiniertes Modell bereitzustellen, wählen Sie das bereitzustellende benutzerdefinierte Modell und dann Modell bereitstellen aus.

Das Dialogfeld Modell bereitstellen wird geöffnet. Geben Sie in diesem Dialogfeld einen Namen in Bereitstellungsname ein, und wählen Sie dann Erstellen aus, um die Bereitstellung Ihres benutzerdefinierten Modells zu starten.

Sie können den Fortschritt Ihrer Bereitstellung im Bereich Bereitstellungen im Azure KI Foundry-Portal überwachen.
Regionsübergreifende Bereitstellung
Die Optimierung unterstützt die Bereitstellung eines optimierten Modells in einer anderen Region als bei der ursprünglichen Optimierung des Modells. Sie können es auch für ein anderes Abonnement/eine andere Region bereitstellen.
Die einzigen Einschränkungen sind, dass die neue Region die Optimierung auch unterstützen muss und bei der abonnementübergreifenden Bereitstellung das Kontos, das das Autorisierungstoken für die Bereitstellung generiert, Zugriff auf die Quell- und Zielabonnements haben muss.
Die Bereitstellung über Abonnements/Regionen hinweg kann über Python oder REST erfolgen.
Verwenden eines bereitgestellten benutzerdefinierten Modells
Nachdem Ihr benutzerdefiniertes Modell bereitgestellt wurde, können Sie es wie jedes andere bereitgestellte Modell verwenden. Sie können Playgrounds im Azure AI Foundry-Portal verwenden, um mit Ihrer neuen Bereitstellung zu experimentieren. Sie können damit fortfahren, die gleichen Parameter mit Ihrem benutzerdefinierten Modell zu verwenden, etwa für temperature und max_tokens, wie das auch mit anderen bereitgestellten Modellen möglich ist.

Analysieren Ihres benutzerdefinierten Modells
Azure OpenAI fügt eine Ergebnisdatei mit dem Namen results.csv an jeden Optimierungsauftrag an, nachdem dieser abgeschlossen wurde. Sie können die Ergebnisdatei verwenden, um die Trainings- und Validierungsleistung Ihres benutzerdefinierten Modells zu analysieren. Die Datei-ID für die Ergebnisdatei wird für jedes benutzerdefinierte Modell in der Spalte Ergebnisdatei-ID des Bereichs Modelle im Azure AI Foundry-Portal aufgeführt. Sie können die Datei-ID verwenden, um die Ergebnisdatei zu identifizieren und im Bereich Datendateien im Azure AI Foundry-Portal herunterzuladen.
Die Ergebnisdatei ist eine CSV-Datei, die eine Kopfzeile und eine Zeile für jeden Trainingsschritt enthält, der durch den Optimierungsauftrag ausgeführt wurde. Die Ergebnisdatei enthält die folgenden Spalten:
| Spaltenname | BESCHREIBUNG |
|---|---|
step |
Die Anzahl der Trainingsschritte. Ein Trainingsschritt stellt einen einzelnen Durchgang, vorwärts und rückwärts, über einen Batch von Trainingsdaten dar. |
train_loss |
Der Verlust für den Trainingsbatch. |
train_mean_token_accuracy |
Der Prozentsatz der Token im Trainingsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
valid_loss |
Der Verlust für den Validierungsbatch. |
validation_mean_token_accuracy |
Der Prozentsatz der Token im Validierungsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
full_valid_loss |
Der am Ende jeder Epoche berechnete Validierungsverlust. Wenn das Training gut verläuft, sollte der Verlust abnehmen. |
full_valid_mean_token_accuracy |
Die gültige mittlere Tokengenauigkeit, die am Ende jeder Epoche berechnet wird. Wenn das Training gut verläuft, sollte die Tokengenauigkeit größer werden. |
Sie können die Daten in Ihrer results.csv-Datei auch als Plots im Azure KI Foundry-Portal anzeigen. Wählen Sie den Link für Ihr trainiertes Modell aus, und es werden drei Diagramme angezeigt: Verlust, mittlere Tokengenauigkeit und Tokengenauigkeit. Wenn Sie Validierungsdaten bereitgestellt haben, werden beide Datasets auf demselben Plot angezeigt.
Achten Sie darauf, dass Ihr Verlust mit der Zeit abnimmt und Ihre Genauigkeit zunimmt. Wenn eine Divergenz zwischen Ihren Trainings- und Validierungsdaten angezeigt wird, kann dies auf eine Überanpassung hindeuten. Versuchen Sie, mit weniger Epochen oder einem kleineren Multiplikator der Lernrate zu trainieren.
Bereinigen Ihrer Bereitstellungen, benutzerdefinierten Modelle und Trainingsdateien
Wenn Sie mit Ihrem benutzerdefinierten Modell fertig sind, können Sie die Bereitstellung und das Modell löschen. Sie können gegebenenfalls außerdem die Trainings- und Validierungsdateien löschen, die Sie in den Dienst hochgeladen haben.
Löschen Ihrer Modellimplementierung
Wichtig
Bleibt die Bereitstellung eines angepassten Modells nach der Bereitstellung länger als fünfzehn (15) Tage inaktiv, wird die Bereitstellung gelöscht. Die Bereitstellung eines angepassten Modells ist inaktiv, wenn das Modell vor mehr als fünfzehn (15) Tagen bereitgestellt wurde und während eines ununterbrochenen Zeitraums von 15 Tagen keine Abschluss- oder Chatabschlussaufrufe an das Modell übermittelt wurden.
Durch das Löschen einer inaktiven Bereitstellung wird das zugrunde liegende angepasste Modell nicht gelöscht oder verändert. Das angepasste Modell kann jederzeit erneut bereitgestellt werden. Wie unter Preise für Azure OpenAI Service beschrieben, fallen für jedes benutzerdefinierte (optimierte) bereitgestellte Modell stündliche Hostingkosten an, unabhängig davon, ob das Modell für Vervollständigungs- oder Chatvervollständigungsaufrufe genutzt wird. Weitere Informationen zum Planen und Verwalten der Kosten mit Azure OpenAI finden Sie im Leitfaden unter Planen und Verwalten der Kosten für Azure OpenAI Service.
Sie können die Bereitstellung Ihres benutzerdefinierten Modells im Bereich Bereitstellungen im Azure KI Foundry-Portal löschen. Wählen Sie die zu löschende Bereitstellung aus, und wählen Sie dann Löschen aus, um die Bereitstellung zu löschen.
Löschen des benutzerdefinierten Modells
Sie können ein benutzerdefiniertes Modell im Bereich Modelle im Azure KI Foundry-Portal löschen. Wählen Sie auf der Registerkarte Benutzerdefinierte Modelle das zu löschende benutzerdefinierte Modell und dann Löschen aus, um das benutzerdefinierte Modell zu löschen.
Hinweis
Sie können kein benutzerdefiniertes Modell löschen, für das eine Bereitstellung vorhanden ist. Sie müssen zunächst die Modellimplementierung löschen, bevor Sie Ihr benutzerdefiniertes Modell löschen können.
Löschen Ihrer Trainingsdateien
Sie können optional Trainings- und Validierungsdateien, die Sie für das Training hochgeladen haben, und Ergebnisdateien, die während des Trainings generiert wurden, im Bereich Verwaltung>Daten + Indizes im Azure AI Foundry-Portal löschen. Wählen Sie die zu löschende Datei aus, und wählen Sie dann Löschen aus, um die Datei zu löschen.
Kontinuierliche Optimierung
Nachdem Sie ein optimiertes Modell erstellt haben, können Sie das Modell im Laufe der Zeit durch weitere Optimierungen weiter verfeinern. Kontinuierliche Optimierung ist der iterative Prozess, bei dem ein bereits optimiertes Modell als Basismodell ausgewählt und anhand neuer Sätze von Trainingsbeispielen weiter verfeinert wird.
Wenn Sie eine Optimierung für ein Modell durchführen möchten, das Sie bereits optimiert haben, verwenden Sie den gleichen Prozess wie unter Erstellen eines angepassten Modells beschrieben, anstatt jedoch den Namen eines generischen Basismodells anzugeben, geben Sie Ihr bereits abgestimmtes Modell an. Ein benutzerdefiniertes optimiertes Modell würde wie folgt aussehen: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

Außerdem wird empfohlen, den suffix-Parameter einzuschließen, um die Unterscheidung zwischen verschiedenen Iterationen Ihres optimierten Modells zu vereinfachen.
suffix verwendet eine Zeichenfolge und wird so festgelegt, dass das optimierte Modell identifiziert wird. Mit der OpenAI Python-API wird eine Zeichenfolge von bis zu 18 Zeichen unterstützt, die Ihrem optimierten Modellnamen hinzugefügt wird.







Voraussetzungen
- Lesen Sie den Leitfaden Einsatzgebiete für die Optimierung mit Azure OpenAI.
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
- Eine Azure OpenAI-Ressource Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
- Die folgenden Python-Bibliotheken:
os,json,requests,openai. - Die OpenAI Python-Bibliothek sollte mindestens Version 0.28.1 sein.
- Für den Zugriff auf die Optimierung ist Mitwirkender für Cognitive Services OpenAI erforderlich.
- Wenn Sie noch keinen Zugriff auf die Kontingentanzeige haben und Modelle im Azure KI Foundry-Portal bereitstellen, benötigen Sie zusätzliche Berechtigungen.
Modelle
Die folgenden Modelle unterstützen die Optimierung:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Die Feinabstimmung für dieses Modell befindet sich derzeit in der öffentlichen Vorschau.
Sie können auch ein zuvor optimiertes Modell weiter optimieren, das als base-model.ft-{jobid} formatiert ist.
Schauen Sie sich die Modellseite an, um zu überprüfen, welche Regionen derzeit Optimierung unterstützen.
Überprüfen des Workflows für das Python SDK
Nehmen Sie sich einen Moment Zeit, um den Optimierungsworkflow für die Verwendung des Python SDK mit Azure OpenAI zu überprüfen:
- Bereiten Sie Ihre Trainings- und Validierungsdaten vor.
- Wählen Sie ein Basismodell aus.
- Laden Sie Ihre Trainingsdaten hoch.
- Trainieren Sie Ihr neues benutzerdefiniertes Modell.
- Überprüfen Sie den Status Ihres benutzerdefinierten Modells.
- Stellen Sie das benutzerdefinierte Modell für die Verwendung bereit.
- Verwenden Sie Ihr benutzerdefiniertes Modell.
- Optional: Analysieren Sie Ihr benutzerdefiniertes Modell auf Leistung und Eignung.
Vorbereiten Ihrer Trainings- und Validierungsdaten
Ihre Trainings- und Validierungsdatasets bestehen aus Ein- und Ausgabebeispielen für das gewünschte Verhalten des Modells.
Die Trainings- und Validierungsdaten, die Sie verwenden, müssen als JSON Lines (JSONL)-Dokument formatiert werden. Für gpt-35-turbo-0613 muss das Optimierungs-Dataset im Konversationsformat formatiert werden, das von den Chatabschlussen API verwendet wird.
Wenn Sie eine schrittweise Anleitung zur Optimierung eines gpt-35-turbo-0613 wünschen, lesen Sie bitte das Azure OpenAI Optimierungslernprogramm
Beispieldateiformat
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Dateiformat für mehrteiligen Chat
Mehrteilige Unterhaltungen in einer einzigen Zeile Ihrer JSONL-Trainingsdatei werden ebenfalls unterstützt. Um die Feinabstimmung für bestimmte Assistentenmeldungen zu überspringen, fügen Sie das optionale weight-Schlüsselwertpaar hinzu. Derzeit kann weight auf 0 oder 1 festgelegt werden.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvervollständigungen mit Vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Zusätzlich zum JSONL-Format müssen Dateien mit Trainings- und Validierungsdaten in UTF-8 codiert sein und eine Bytereihenfolge-Marke (BOM) enthalten. Die Datei muss kleiner als 512 MB sein.
Erstellen von Trainings- und Validierungsdatasets
Je mehr Trainingsbeispiele Sie haben, desto besser. Für die Feinabstimmung sind mindestens 10 Trainingsbeispiele erforderlich, aber eine so geringe Anzahl reicht nicht aus, um die Reaktionen des Modells merklich zu beeinflussen. Es empfiehlt sich, Hunderte, wenn nicht Tausende von Trainingsbeispielen bereitzustellen, um erfolgreich zu sein.
Im Allgemeinen führt eine Verdoppelung der Datasetgröße zu einer linearen Erhöhung der Modellqualität. Bedenken Sie jedoch, dass Beispiele mit geringer Qualität die Leistung beeinträchtigen können. Wenn Sie das Modell mit vielen internen Daten trainieren, ohne zuvor das Dataset zu bereinigen, sodass es nur noch Beispiele mit höchster Qualität enthält, erhalten Sie möglicherweise ein Modell, das viel schlechter funktioniert als erwartet.
Hochladen Ihrer Trainingsdaten
Der nächste Schritt besteht darin, entweder vorhandene vorbereitete Trainingsdaten auszuwählen oder neue vorbereitete Trainingsdaten für die Verwendung beim Anpassen des Modells hochzuladen. Nachdem Sie Ihre Trainingsdaten vorbereitet haben, können Sie Ihre Dateien in den Dienst hochladen. Es gibt zwei Möglichkeiten zum Hochladen von Trainingsdaten:
Für große Datendateien wird der Import aus Azure Blob Storage empfohlen. Große Dateien können instabil werden, wenn sie über mehrteilige Formulare hochgeladen werden, da die Anforderungen atomar sind und nicht erneut ausgeführt oder fortgesetzt werden können. Weitere Informationen zu Azure Blob Storage finden Sie unter Was ist Azure Blob Storage?
Hinweis
Dateien mit Trainingsdaten müssen als JSONL-Dateien formatiert und in UTF-8 mit BOM (Bytereihenfolge-Marke) codiert groß sein. Die Datei muss kleiner als 512 MB sein.
Das folgende Python-Beispiel lädt mit Hilfe des Python SDK lokale Trainings- und Validierungsdateien hoch und ruft die zurückgegebenen Datei-IDs ab.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Erstellen eines angepassten Modells
Nachdem Sie Ihre Trainings- und Validierungsdateien hochgeladen haben, können Sie mit dem Optimierungsauftrag beginnen.
Der folgende Python-Code zeigt ein Beispiel für das Erstellen eines neuen Optimierungsauftrags mit dem Python SDK:
In diesem Beispiel übergeben wir auch den Seed-Parameter. Der Seed steuert die Reproduzierbarkeit des Auftrags. Die Übergabe der gleichen Seed- und Auftragsparameter sollte zu den gleichen Ergebnissen führen, kann sich aber in seltenen Fällen unterscheiden. Wenn Sie keinen Seed angeben, wird ein Seed für Sie generiert.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Sie können auch zusätzliche optionale Parameter wie Hyperparameter übergeben, um die Kontrolle über den Optimierungsprozess zu behalten. Für das Ersttraining empfehlen wir die Verwendung der automatischen Standardwerte, die vorhanden sind, ohne diese Parameter anzugeben.
Die aktuellen unterstützten Hyperparameter für die Optimierung sind:
| Name | Art | Beschreibung |
|---|---|---|
batch_size |
integer | Die für das Training zu verwendende Batchgröße. Die Batchgröße ist die Anzahl der Trainingsbeispiele, die zum Trainieren eines einzelnen Vorwärts- und Rückwärtsdurchlaufs verwendet werden. Im Allgemeinen haben wir festgestellt, dass größere Batchgrößen für größere Datasets besser funktionieren. Der Standardwert sowie der Maximalwert für diese Eigenschaft sind spezifisch für ein Basismodell. Eine größere Batchgröße bedeutet, dass Modellparameter weniger häufig aktualisiert werden, aber mit geringerer Varianz. |
learning_rate_multiplier |
Zahl | Der Lernratenmultiplikator, der für das Training verwendet werden soll. Die Optimierungslernrate ist die ursprüngliche Lernrate, die für das Vorabtraining verwendet wird, mit diesem Wert multipliziert. Größere Lernraten sind tendenziell besser für größere Batchgrößen. Es empfiehlt sich, mit Werten im Bereich 0,02 bis 0,2 zu experimentieren, um zu sehen, was die besten Ergebnisse erzeugt. Eine kleinere Lernrate kann nützlich sein, um Überanpassung zu vermeiden. |
n_epochs |
integer | Die Anzahl der Epochen zum Trainieren des Modells. Eine Epoche bezeichnet einen vollständigen Zyklus über das Trainingsdataset. |
seed |
integer | Der Seed steuert die Reproduzierbarkeit des Auftrags. Die Übergabe der gleichen Seed- und Auftragsparameter sollte zu den gleichen Ergebnissen führen, kann sich aber in seltenen Fällen unterscheiden. Wenn Sie keinen Seed angeben, wird ein Seed für Sie generiert. |
So legen Sie benutzerdefinierte Hyperparameter mit der 1.x-Version der OpenAI Python-API fest:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Überprüfen des Optimierungsauftragsstatus
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Auflisten von Feinabstimmungsereignissen
So untersuchen Sie die einzelnen Feinabstimmungsereignisse, die während des Trainings generiert wurden:
Möglicherweise müssen Sie für Ihre OpenAI-Clientbibliothek mit pip install openai --upgrade ein Upgrade auf die neueste Version durchführen, um diesen Befehl ausführen zu können.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Prüfpunkte
Nach Abschluss jeder Trainingsepoche wird Prüfpunkt generiert. Ein Prüfpunkt ist eine voll funktionsfähige Version eines Modells, das sowohl bereitgestellt als auch als Zielmodell für nachfolgende Feinabstimmungsaufträge genutzt werden kann. Prüfpunkte können besonders nützlich sein, da sie eine Momentaufnahme Ihres Modells bereitstellen können, bevor eine Überanpassung auftritt. Wenn ein Feinabstimmungsauftrag abgeschlossen ist, stehen Ihnen die letzten drei Versionen des Modells zur Bereitstellung zur Verfügung. Die letzte Epoche wird durch Ihr fein abgestimmtes Modell dargestellt, die beiden vorherigen Epochen sind als Prüfpunkte verfügbar.
Sie können den Befehl zum Auflisten der Prüfpunkte ausführen, um die Liste der Prüfpunkte abzurufen, die einem einzelnen Feinabstimmungsauftrag zugeordnet sind:
Möglicherweise müssen Sie für Ihre OpenAI-Clientbibliothek mit pip install openai --upgrade ein Upgrade auf die neueste Version durchführen, um diesen Befehl ausführen zu können.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Sicherheitsbewertung für GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung: Public Preview
GPT-4, GPT-4o und GPT-4o-mini sind unsere fortschrittlichsten Modelle, die per Optimierung genau auf Ihre Anforderungen zugeschnitten werden können. Wie auch Azure OpenAI-Modelle allgemein bringen die erweiterten Funktionen fein abgestimmter Modelle zusätzliche Herausforderungen im Bereich verantwortungsvolle KI mit sich, die mit schädlichen Inhalten, Manipulation, menschenähnlichem Verhalten, Datenschutzproblemen und anderen Aspekten zusammenhängen. Weitere Informationen zu Risiken, Funktionen und Einschränkungen finden Sie in der Übersicht über verantwortungsvolle KI-Methoden und dem Transparenzhinweis. Um dazu beizutragen, die Risiken zu mindern, die Modelle mit erweiterter Optimierung mit sich bringen, wurden zusätzliche Bewertungsschritte implementiert, die helfen, schädliche Inhalte beim Training und in Ausgaben von optimierten Modellen zu erkennen und zu verhindern. Diese Schritte basieren auf dem Microsoft Responsible AI Standard (Microsoft-Standard für verantwortungsvolle KI) und der Inhaltsfilterung von Azure OpenAI Service.
- Bewertungen werden in dedizierten und kundenspezifischen privaten Arbeitsbereichen durchgeführt.
- Die Bewertungsendpunkte befinden sich am selben geografischen Standort wie die Azure OpenAI-Ressource.
- In Verbindung mit der Durchführung von Bewertungen werden keine Trainingsdaten gespeichert. Nur die finale Modellbewertung (bereitstellbar oder nicht bereitstellbar) wird persistent gespeichert.
Die Bewertungsfilter für Modelle mit GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung sind auf voreingestellte Schwellenwerte festgelegt, die auf Kundenseite nicht geändert werden können. Sie hängen nicht mit benutzerdefinierten Inhaltsfilterkonfigurationen zusammen, die Sie möglicherweise erstellt haben.
Bewertung von Daten
Vor Beginn des Trainings wird eine Bewertung Ihrer Daten hinsichtlich potenziell schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness, Selbstverletzung – siehe Kategoriedefinitionen unter diesem Link) vorgenommen. Wenn schädliche Inhalte mit einem höheren Schweregrad als dem festgelegten erkannt werden, tritt bei Ihrem Trainingsauftrag ein Fehler auf, und es wird eine Benachrichtigung mit den Fehlerkategorien angezeigt.
Beispielbenachrichtigung:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Ihre Trainingsdaten werden automatisch während des Datenimportauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet.
Wenn während des Feinabstimmungsauftrags aufgrund der Erkennung schädlicher Inhalte in Trainingsdaten ein Fehler auftritt, wird Ihnen dieser Auftrag nicht in Rechnung gestellt.
Modellauswertung
Nach Abschluss des Trainings, aber bevor das fein abgestimmte Modell für die Bereitstellung verfügbar ist, wird das resultierende Modell mithilfe der integrierten Risiko- und Sicherheitsmetriken von Azure hinsichtlich potenziell schädlicher Antworten bewertet. Mit dem Testansatz, den wir auch für grundlegende große Sprachmodelle verwenden, simuliert unsere Bewertungsfunktion eine Unterhaltung mit Ihrem fein abgestimmten Modell, um die Wahrscheinlichkeit, dass schädliche Inhalte ausgegeben werden, zu bewerten. Hierbei werden ebenfalls festgelegte Kategorien schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness und Selbstverletzung) verwendet.
Wenn festgestellt wird, dass ein Modell Ausgaben mit Inhalten generiert, die als schädlicher als ein akzeptabler Grad eingestuft werden, werden Sie darüber informiert, dass Ihr Modell nicht für die Bereitstellung verfügbar ist. Diese Benachrichtigung enthält außerdem Informationen zu den konkreten Kategorien schädlicher Inhalte, die erkannt wurden:
Beispielbenachrichtigung:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Wie bei der Datenbewertung wird das Modell automatisch während des Feinabstimmungsauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet. Nur die daraus resultierende Bewertung (bereitstellbar oder nicht bereitstellbar) wird vom Dienst protokolliert. Wenn bei der Bereitstellung des fein abgestimmten Modells aufgrund der Erkennung schädlicher Inhalte in Modellausgaben ein Fehler auftritt, wird Ihnen die Trainingsausführung nicht in Rechnung gestellt.
Bereitstellen eines optimierten Modells
Wenn der Optimierungsauftrag erfolgreich war, wird der Wert der fine_tuned_model-Variable im Antworttext auf den Namen Ihres benutzerdefinierten Modells festgelegt. Ihr Modell ist jetzt auch für die Ermittlung über die API zum Auflisten von Modellen verfügbar. Allerdings können Sie Vervollständigungsaufrufe an Ihr angepasstes Modell erst ausgeben, wenn Ihr angepasstes Modell bereitgestellt wurde. Sie müssen Ihr angepasstes Modell bereitstellen, um es für die Verwendung mit Vervollständigungsaufrufen verfügbar zu machen.
Wichtig
Bleibt die Bereitstellung eines angepassten Modells nach der Bereitstellung länger als fünfzehn (15) Tage inaktiv, wird die Bereitstellung gelöscht. Die Bereitstellung eines angepassten Modells ist inaktiv, wenn das Modell vor mehr als fünfzehn (15) Tagen bereitgestellt wurde und während eines ununterbrochenen Zeitraums von 15 Tagen keine Abschluss- oder Chatabschlussaufrufe an das Modell übermittelt wurden.
Durch das Löschen einer inaktiven Bereitstellung wird das zugrunde liegende angepasste Modell nicht gelöscht oder verändert. Das angepasste Modell kann jederzeit erneut bereitgestellt werden. Wie unter Preise für Azure OpenAI Service beschrieben, fallen für jedes benutzerdefinierte (optimierte) bereitgestellte Modell stündliche Hostingkosten an, unabhängig davon, ob das Modell für Vervollständigungs- oder Chatvervollständigungsaufrufe genutzt wird. Weitere Informationen zum Planen und Verwalten der Kosten mit Azure OpenAI finden Sie im Leitfaden unter Planen und Verwalten der Kosten für Azure OpenAI Service.
Sie können auch Azure KI Foundry oder die Azure CLI verwenden, um Ihr angepasstes Modell bereitzustellen.
Hinweis
Für ein angepasstes Modell ist nur eine Bereitstellung zulässig. Wenn Sie ein bereits bereitgestelltes angepasstes Modell auswählen, tritt ein Fehler auf.
Im Gegensatz zu den vorherigen SDK-Befehlen muss die Bereitstellung über die API der Steuerungsebene erfolgen, die eine separate Autorisierung, einen anderen API-Pfad und eine andere API-Version erfordert.
| -Variable | Definition |
|---|---|
| token | Es gibt mehrere Möglichkeiten, ein Autorisierungstoken zu generieren. Die einfachste Methode für anfängliche Tests besteht darin, Cloud Shell über das Azure-Portal zu starten. Führen Sie dann az account get-access-token aus. Sie können dieses Token als temporäres Autorisierungstoken für API-Tests verwenden. Es wird empfohlen, dies in einer neuen Umgebungsvariable zu speichern. |
| Abonnement | Die Abonnement-ID für die zugeordnete Azure OpenAI-Ressource. |
| resource_group | Der Ressourcengruppenname für Ihre Azure OpenAI-Ressource. |
| resource_name | Den Namen der Azure OpenAI-Ressource. |
| model_deployment_name | Der benutzerdefinierte Name für die Bereitstellung Ihres neuen optimierten Modells. Das ist der Name, auf den in Ihrem Code verwiesen wird, wenn Chatabschlussaufrufe ausgeführt werden. |
| fine_tuned_model | Rufen Sie diesen Wert aus Ihrem Optimierungsauftrag aus dem vorherigen Schritt ab. Er sieht wie folgt aus: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Dieser Wert muss dem JSON-Code „deploy_data“ hinzugefügt werden. Alternativ können Sie auch einen Prüfpunkt bereitstellen, indem Sie die Prüfpunkt-ID übergeben, die im Format ftchkpt-e559c011ecc04fc68eaa339d8227d02d angezeigt wird. |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Regionsübergreifende Bereitstellung
Die Optimierung unterstützt die Bereitstellung eines optimierten Modells in einer anderen Region als bei der ursprünglichen Optimierung des Modells. Sie können es auch für ein anderes Abonnement/eine andere Region bereitstellen.
Die einzigen Einschränkungen sind, dass die neue Region die Optimierung auch unterstützen muss und bei der abonnementübergreifenden Bereitstellung das Kontos, das das Autorisierungstoken für die Bereitstellung generiert, Zugriff auf die Quell- und Zielabonnements haben muss.
Nachfolgend finden Sie ein Beispiel für die Bereitstellung eines Modells, das von einem Abonnement/einer Region in ein/e andere/s optimiert wurde.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Um zwischen demselben Abonnement, aber unterschiedliche Regionen bereitzustellen, müssen Abonnement- und Ressourcengruppen für Quell- und Zielvariablen identisch, und nur die Namen der Quell- und Zielressourcen müssen eindeutig sein.
Mandantenübergreifende Bereitstellung
Das Konto, das zum Generieren von Zugriffstoken mit az account get-access-token --tenant verwendet wird, sollte über Berechtigungen für Cognitive Services OpenAI-Mitwirkende für die Quell- und Zielressourcen von Azure OpenAI verfügen. Sie müssen zwei unterschiedliche Token generieren, eines für den Quellmandanten und eines für den Zielmandanten.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Bereitstellen eines Modells mit Azure CLI
Das folgende Beispiel zeigt, wie Sie die Azure-Befehlszeilenschnittstelle verwenden, um Ihr benutzerdefiniertes Modell bereitzustellen. Bei der Azure CLI müssen Sie einen Namen für die Bereitstellung Ihres angepassten Modells angeben. Weitere Informationen zur Verwendung der Azure CLI zum Bereitstellen angepasster Modelle finden Sie unter az cognitiveservices account deployment.
Zum Ausführen dieses Azure CLI-Befehls in einem Konsolenfenster müssen Sie die folgenden <Platzhalter> durch die entsprechenden Werte für Ihr benutzerdefiniertes Modell ersetzen:
| Platzhalter | Wert |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Der Name oder die ID Ihres Azure-Abonnements |
| <YOUR_RESOURCE_GROUP> | Name Ihrer Azure-Ressourcengruppe |
| <YOUR_RESOURCE_NAME> | Der Name Ihrer Azure OpenAI-Ressource. |
| <YOUR_DEPLOYMENT_NAME> | Der Name, den Sie für Ihre Modellimplementierung verwenden möchten. |
| <YOUR_FINE_TUNED_MODEL_ID> | Der Name Ihres angepassten Modells. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Verwenden eines bereitgestellten angepassten Modells
Nachdem Ihr benutzerdefiniertes Modell bereitgestellt wurde, können Sie es wie jedes andere bereitgestellte Modell verwenden. Sie können den Chat-Playground in Azure AI Foundry verwenden, um mit Ihrer neuen Bereitstellung zu experimentieren. Sie können damit fortfahren, die gleichen Parameter mit Ihrem benutzerdefinierten Modell zu verwenden, etwa für temperature und max_tokens, wie das auch mit anderen bereitgestellten Modellen möglich ist.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analysieren Ihres angepassten Modells
Azure OpenAI fügt eine Ergebnisdatei mit dem Namen results.csv an jeden Optimierungsauftrag an, nachdem dieser abgeschlossen wurde. Sie können die Ergebnisdatei verwenden, um die Trainings- und Validierungsleistung Ihres angepassten Modells zu analysieren. Die Datei-ID für die Ergebnisdatei wird für jedes angepasste Modell aufgelistet, und Sie können das Python SDK verwenden, um die Datei-ID abzurufen und die Ergebnisdatei für die Analyse herunterzuladen.
Im folgenden Python-Beispiel wird die Datei-ID der ersten Ergebnisdatei abgerufen, die an den Optimierungsauftrag für Ihr angepasstes Modell angefügt ist, und anschließend wird das Python SDK verwendet, um die Datei zur Analyse in Ihr Arbeitsverzeichnis herunterzuladen.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Die Ergebnisdatei ist eine CSV-Datei, die eine Kopfzeile und eine Zeile für jeden Trainingsschritt enthält, der durch den Optimierungsauftrag ausgeführt wurde. Die Ergebnisdatei enthält die folgenden Spalten:
| Spaltenname | BESCHREIBUNG |
|---|---|
step |
Die Anzahl der Trainingsschritte. Ein Trainingsschritt stellt einen einzelnen Durchgang, vorwärts und rückwärts, über einen Batch von Trainingsdaten dar. |
train_loss |
Der Verlust für den Trainingsbatch. |
train_mean_token_accuracy |
Der Prozentsatz der Token im Trainingsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
valid_loss |
Der Verlust für den Validierungsbatch. |
validation_mean_token_accuracy |
Der Prozentsatz der Token im Validierungsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
full_valid_loss |
Der am Ende jeder Epoche berechnete Validierungsverlust. Wenn das Training gut verläuft, sollte der Verlust abnehmen. |
full_valid_mean_token_accuracy |
Die gültige mittlere Tokengenauigkeit, die am Ende jeder Epoche berechnet wird. Wenn das Training gut verläuft, sollte die Tokengenauigkeit größer werden. |
Sie können die Daten in Ihrer results.csv-Datei auch als Plots im Azure KI Foundry-Portal anzeigen. Wählen Sie den Link für Ihr trainiertes Modell aus, und es werden drei Diagramme angezeigt: Verlust, mittlere Tokengenauigkeit und Tokengenauigkeit. Wenn Sie Validierungsdaten bereitgestellt haben, werden beide Datasets auf demselben Plot angezeigt.
Achten Sie darauf, dass Ihr Verlust mit der Zeit abnimmt und Ihre Genauigkeit zunimmt. Wenn Sie eine Abweichung zwischen Ihren Trainings- und Validierungsdaten feststellen, kann dies auf eine Überanpassung hindeuten. Versuchen Sie, mit weniger Epochen oder einem kleineren Multiplikator der Lernrate zu trainieren.
Bereinigen Ihrer Bereitstellungen, optimierten Modelle und Trainingsdateien
Wenn Sie mit Ihrem angepassten Modell fertig sind, können Sie die Bereitstellung und das Modell löschen. Sie können gegebenenfalls außerdem die Trainings- und Validierungsdateien löschen, die Sie in den Dienst hochgeladen haben.
Löschen Ihrer Modellimplementierung
Wichtig
Bleibt die Bereitstellung eines angepassten Modells nach der Bereitstellung länger als fünfzehn (15) Tage inaktiv, wird die Bereitstellung gelöscht. Die Bereitstellung eines angepassten Modells ist inaktiv, wenn das Modell vor mehr als fünfzehn (15) Tagen bereitgestellt wurde und während eines ununterbrochenen Zeitraums von 15 Tagen keine Abschluss- oder Chatabschlussaufrufe an das Modell übermittelt wurden.
Durch das Löschen einer inaktiven Bereitstellung wird das zugrunde liegende angepasste Modell nicht gelöscht oder verändert. Das angepasste Modell kann jederzeit erneut bereitgestellt werden. Wie unter Preise für Azure OpenAI Service beschrieben, fallen für jedes benutzerdefinierte (optimierte) bereitgestellte Modell stündliche Hostingkosten an, unabhängig davon, ob das Modell für Vervollständigungs- oder Chatvervollständigungsaufrufe genutzt wird. Weitere Informationen zum Planen und Verwalten der Kosten mit Azure OpenAI finden Sie im Leitfaden unter Planen und Verwalten der Kosten für Azure OpenAI Service.
Sie können verschiedene Methoden verwenden, um die Bereitstellung für Ihr angepasstes Modell zu löschen:
Löschen Ihres angepassten Modells
Analog dazu können Sie verschiedene Methoden verwenden, um Ihr angepasstes Modell zu löschen:
Hinweis
Sie können kein benutzerdefiniertes Modell löschen, für das eine Bereitstellung vorhanden ist. Zuerst müssen Sie die Modellimplementierung löschen, bevor Sie Ihr angepasstes Modell löschen können.
Löschen Ihrer Trainingsdateien
Sie können optional Trainings- und Validierungsdateien, die Sie zum Trainieren hochgeladen haben, und Ergebnisdateien, die während des Trainings generiert wurden, aus Ihrem Azure OpenAI-Abonnement löschen. Sie können die folgenden Methoden verwenden, um Ihre Trainings-, Validierungs- und Ergebnisdateien zu löschen:
- Azure KI Foundry
- Die REST-APIs
- Python SDK
Im folgenden Python-Beispiel wird das Python SDK verwendet, um die Trainings-, Validierungs- und Ergebnisdateien für Ihr benutzerdefiniertes Modell zu löschen:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Kontinuierliche Optimierung
Nachdem Sie ein optimiertes Modell erstellt haben, können Sie das Modell im Laufe der Zeit durch weitere Optimierungen verfeinern. Kontinuierliche Optimierung ist der iterative Prozess, bei dem ein bereits optimiertes Modell als Basismodell ausgewählt und anhand neuer Sätze von Trainingsbeispielen weiter verfeinert wird.
Wenn Sie eine Optimierung für ein Modell durchführen möchten, das Sie bereits optimiert haben, verwenden Sie den gleichen Prozess wie unter Erstellen eines angepassten Modells beschrieben, anstatt jedoch den Namen eines generischen Basismodells anzugeben, geben Sie die ID Ihres bereits abgestimmten Modells an. Die ID des optimierten Modells sieht wie folgt aus: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Außerdem wird empfohlen, den suffix-Parameter einzuschließen, um die Unterscheidung zwischen verschiedenen Iterationen Ihres optimierten Modells zu vereinfachen.
suffix verwendet eine Zeichenfolge und wird so festgelegt, dass das optimierte Modell identifiziert wird. Mit der OpenAI Python-API wird eine Zeichenfolge von bis zu 18 Zeichen unterstützt, die Ihrem optimierten Modellnamen hinzugefügt wird.
Wenn Sie sich nicht sicher sind, welche ID Ihr vorhandenes optimiertes Modell hat, finden Sie diese Informationen auf der Seite Modelle von Azure KI Foundry, oder Sie können eine Liste der Modelle für eine bestimmte Azure OpenAI-Ressource mithilfe der REST-API generieren.
Voraussetzungen
- Lesen Sie den Leitfaden Einsatzgebiete für die Optimierung mit Azure OpenAI.
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
- Eine Azure OpenAI-Ressource Weitere Informationen finden Sie unter Erstellen einer Ressource und Bereitstellen eines Modells mit Azure OpenAI.
- Für den Zugriff auf die Optimierung ist Mitwirkender für Cognitive Services OpenAI erforderlich.
- Wenn Sie noch keinen Zugriff auf die Kontingentanzeige haben und Modelle im Azure KI Foundry-Portal bereitstellen, benötigen Sie zusätzliche Berechtigungen.
Modelle
Die folgenden Modelle unterstützen die Optimierung:
-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Die Feinabstimmung für dieses Modell befindet sich derzeit in der öffentlichen Vorschau.
Oder Sie können ein zuvor feinabgestimmtes Modell optimieren, das als „base-model.ft-{jobid}“ formatiert ist.
Schauen Sie sich die Modellseite an, um zu überprüfen, welche Regionen derzeit Optimierung unterstützen.
Überprüfen des Workflows für die REST-API
Nehmen Sie sich einen Moment Zeit, um den Optimierungsworkflow für die Verwendung von REST-APIs und Python mit Azure OpenAI zu überprüfen:
- Bereiten Sie Ihre Trainings- und Validierungsdaten vor.
- Wählen Sie ein Basismodell aus.
- Laden Sie Ihre Trainingsdaten hoch.
- Trainieren Sie Ihr neues benutzerdefiniertes Modell.
- Überprüfen Sie den Status Ihres benutzerdefinierten Modells.
- Stellen Sie das benutzerdefinierte Modell für die Verwendung bereit.
- Verwenden Sie Ihr benutzerdefiniertes Modell.
- Optional: Analysieren Sie Ihr benutzerdefiniertes Modell auf Leistung und Eignung.
Vorbereiten Ihrer Trainings- und Validierungsdaten
Ihre Trainings- und Validierungsdatasets bestehen aus Ein- und Ausgabebeispielen für das gewünschte Verhalten des Modells.
Die Trainings- und Validierungsdaten, die Sie verwenden, müssen als JSON Lines (JSONL)-Dokument formatiert werden. Für gpt-35-turbo-0613 und andere verwandte Modelle muss das Optimierungs-Dataset im Konversationsformat formatiert werden, das von der Chatabschluss-API verwendet wird.
Wenn Sie eine schrittweise Anleitung zur Feinabstimmung eines gpt-35-turbo-0613 wünschen, lesen Sie das Tutorial zur Feinabstimmung von Azure OpenAI
Beispieldateiformat
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Dateiformat für mehrteiligen Chat
Mehrteilige Unterhaltungen in einer einzigen Zeile Ihrer JSONL-Trainingsdatei werden ebenfalls unterstützt. Um die Feinabstimmung für bestimmte Assistentenmeldungen zu überspringen, fügen Sie das optionale weight-Schlüsselwertpaar hinzu. Derzeit kann weight auf 0 oder 1 festgelegt werden.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvervollständigungen mit Vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Zusätzlich zum JSONL-Format müssen Dateien mit Trainings- und Validierungsdaten in UTF-8 codiert sein und eine Bytereihenfolge-Marke (BOM) enthalten. Die Datei muss kleiner als 512 MB sein.
Erstellen von Trainings- und Validierungsdatasets
Je mehr Trainingsbeispiele Sie haben, desto besser. Für die Feinabstimmung sind mindestens 10 Trainingsbeispiele erforderlich, aber eine so geringe Anzahl reicht nicht aus, um die Reaktionen des Modells merklich zu beeinflussen. Es empfiehlt sich, Hunderte, wenn nicht Tausende von Trainingsbeispielen bereitzustellen, um erfolgreich zu sein.
Im Allgemeinen führt eine Verdoppelung der Datasetgröße zu einer linearen Erhöhung der Modellqualität. Bedenken Sie jedoch, dass Beispiele mit geringer Qualität die Leistung beeinträchtigen können. Wenn Sie das Modell mit vielen internen Daten trainieren, ohne zuvor das Dataset zu bereinigen, sodass es nur noch Beispiele mit höchster Qualität enthält, erhalten Sie möglicherweise ein Modell, das viel schlechter funktioniert als erwartet.
Auswählen des Basismodells
Der erste Schritt beim Erstellen eines benutzerdefinierten Modells besteht in der Auswahl eines Basismodells. Im Bereich Basismodell können Sie ein Basismodell auswählen, das für Ihr benutzerdefiniertes Modell verwendet werden soll. Ihre Auswahl hat sowohl auf die Leistung als auch auf die Kosten Ihres Modells Einfluss.
Wählen Sie das Basismodell in der Dropdownliste Basismodelltyp und dann Weiter aus, um fortzufahren.
Oder Sie können ein zuvor feinabgestimmtes Modell optimieren, das als „base-model.ft-{jobid}“ formatiert ist.
Weitere Informationen zu unseren verfeinerbaren Basismodellen finden Sie unter Modelle.
Hochladen Ihrer Trainingsdaten
Der nächste Schritt besteht darin, entweder vorhandene vorbereitete Trainingsdaten auszuwählen oder neue vorbereitete Trainingsdaten für die Verwendung beim Optimieren des Modells hochzuladen. Nachdem Sie Ihre Trainingsdaten vorbereitet haben, können Sie Ihre Dateien in den Dienst hochladen. Es gibt zwei Möglichkeiten zum Hochladen von Trainingsdaten:
Für große Datendateien wird der Import aus Azure Blob Storage empfohlen. Große Dateien können instabil werden, wenn sie über mehrteilige Formulare hochgeladen werden, da die Anforderungen atomar sind und nicht erneut ausgeführt oder fortgesetzt werden können. Weitere Informationen zu Azure Blob Storage finden Sie unter Was ist Azure Blob Storage?
Hinweis
Dateien mit Trainingsdaten müssen als JSONL-Dateien formatiert und in UTF-8 mit BOM (Bytereihenfolge-Marke) codiert groß sein. Die Datei muss kleiner als 512 MB sein.
Hochladen von Trainingsdaten
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Hochladen von Validierungsdaten
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Erstellen eines angepassten Modells
Nachdem Sie Ihre Trainings- und Validierungsdateien hochgeladen haben, können Sie mit dem Optimierungsauftrag beginnen. Der folgende Code zeigt ein Beispiel für das Erstellen eines neuen Feinabstimmungsauftrags mit der REST API.
In diesem Beispiel übergeben wir auch den Seed-Parameter. Der Seed steuert die Reproduzierbarkeit des Auftrags. Die Übergabe der gleichen Seed- und Auftragsparameter sollte zu den gleichen Ergebnissen führen, kann aber in seltenen Fällen abweichen. Wenn Sie keinen Seed angeben, wird einer für Sie generiert.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Sie können auch zusätzliche optionale Parameter wie Hyperparameter übergeben, um die Kontrolle über den Optimierungsprozess zu behalten. Für das Ersttraining empfehlen wir die Verwendung der automatischen Standardwerte, die vorhanden sind, ohne diese Parameter anzugeben.
Die aktuellen unterstützten Hyperparameter für die Optimierung sind:
| Name | Art | Beschreibung |
|---|---|---|
batch_size |
integer | Die für das Training zu verwendende Batchgröße. Die Batchgröße ist die Anzahl der Trainingsbeispiele, die zum Trainieren eines einzelnen Vorwärts- und Rückwärtsdurchlaufs verwendet werden. Im Allgemeinen haben wir festgestellt, dass größere Batchgrößen für größere Datasets besser funktionieren. Der Standardwert sowie der Maximalwert für diese Eigenschaft sind spezifisch für ein Basismodell. Eine größere Batchgröße bedeutet, dass Modellparameter weniger häufig aktualisiert werden, aber mit geringerer Varianz. |
learning_rate_multiplier |
Zahl | Der Lernratenmultiplikator, der für das Training verwendet werden soll. Die Optimierungslernrate ist die ursprüngliche Lernrate, die für das Vorabtraining verwendet wird, mit diesem Wert multipliziert. Größere Lernraten sind tendenziell besser für größere Batchgrößen. Es empfiehlt sich, mit Werten im Bereich 0,02 bis 0,2 zu experimentieren, um zu sehen, was die besten Ergebnisse erzeugt. Eine kleinere Lernrate kann nützlich sein, um Überanpassung zu vermeiden. |
n_epochs |
integer | Die Anzahl der Epochen zum Trainieren des Modells. Eine Epoche bezeichnet einen vollständigen Zyklus über das Trainingsdataset. |
seed |
integer | Der Seed steuert die Reproduzierbarkeit des Auftrags. Die Übergabe der gleichen Seed- und Auftragsparameter sollte zu den gleichen Ergebnissen führen, kann sich aber in seltenen Fällen unterscheiden. Wenn Sie keinen Seed angeben, wird ein Seed für Sie generiert. |
Überprüfen des Status Ihres angepassten Modells
Ein Optimierungsauftrag benötigt nach dem Start möglicherweise einige Zeit bis zum Abschluss. Ihr Auftrag befindet sich möglicherweise in der Warteschlange hinter anderen Aufträgen im System. Das Trainieren Ihres Modells kann je nach Größe von Modell und Dataset Minuten oder Stunden dauern. Im folgenden Beispiel wird die REST-API verwendet, um den Status Ihres Optimierungsauftrags zu überprüfen. Im Beispiel werden Informationen zu Ihrem Auftrag mithilfe der Auftrags-ID abgerufen, die im vorherigen Beispiel zurückgegeben wurde:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Auflisten von Feinabstimmungsereignissen
So untersuchen Sie die einzelnen Feinabstimmungsereignisse, die während des Trainings generiert wurden:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Prüfpunkte
Nach Abschluss jeder Trainingsepoche wird Prüfpunkt generiert. Ein Prüfpunkt ist eine voll funktionsfähige Version eines Modells, das sowohl bereitgestellt als auch als Zielmodell für nachfolgende Feinabstimmungsaufträge genutzt werden kann. Prüfpunkte können besonders nützlich sein, da sie eine Momentaufnahme Ihres Modells bereitstellen können, bevor eine Überanpassung auftritt. Wenn ein Feinabstimmungsauftrag abgeschlossen ist, stehen Ihnen die letzten drei Versionen des Modells zur Bereitstellung zur Verfügung. Die letzte Epoche wird durch Ihr fein abgestimmtes Modell dargestellt, die beiden vorherigen Epochen sind als Prüfpunkte verfügbar.
Sie können den Befehl zum Auflisten der Prüfpunkte ausführen, um die Liste der Prüfpunkte abzurufen, die einem einzelnen Feinabstimmungsauftrag zugeordnet sind:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Sicherheitsbewertung für GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung: Public Preview
GPT-4, GPT-4o und GPT-4o-mini sind unsere fortschrittlichsten Modelle, die per Optimierung genau auf Ihre Anforderungen zugeschnitten werden können. Wie auch Azure OpenAI-Modelle allgemein bringen die erweiterten Funktionen fein abgestimmter Modelle zusätzliche Herausforderungen im Bereich verantwortungsvolle KI mit sich, die mit schädlichen Inhalten, Manipulation, menschenähnlichem Verhalten, Datenschutzproblemen und anderen Aspekten zusammenhängen. Weitere Informationen zu Risiken, Funktionen und Einschränkungen finden Sie in der Übersicht über verantwortungsvolle KI-Methoden und dem Transparenzhinweis. Um dazu beizutragen, die Risiken zu mindern, die Modelle mit erweiterter Optimierung mit sich bringen, wurden zusätzliche Bewertungsschritte implementiert, die helfen, schädliche Inhalte beim Training und in Ausgaben von optimierten Modellen zu erkennen und zu verhindern. Diese Schritte basieren auf dem Microsoft Responsible AI Standard (Microsoft-Standard für verantwortungsvolle KI) und der Inhaltsfilterung von Azure OpenAI Service.
- Bewertungen werden in dedizierten und kundenspezifischen privaten Arbeitsbereichen durchgeführt.
- Die Bewertungsendpunkte befinden sich am selben geografischen Standort wie die Azure OpenAI-Ressource.
- In Verbindung mit der Durchführung von Bewertungen werden keine Trainingsdaten gespeichert. Nur die finale Modellbewertung (bereitstellbar oder nicht bereitstellbar) wird persistent gespeichert.
Die Bewertungsfilter für Modelle mit GPT-4-, GPT-4o- und GPT-4o-mini-Optimierung sind auf voreingestellte Schwellenwerte festgelegt, die auf Kundenseite nicht geändert werden können. Sie hängen nicht mit benutzerdefinierten Inhaltsfilterkonfigurationen zusammen, die Sie möglicherweise erstellt haben.
Bewertung von Daten
Vor Beginn des Trainings wird eine Bewertung Ihrer Daten hinsichtlich potenziell schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness, Selbstverletzung – siehe Kategoriedefinitionen unter diesem Link) vorgenommen. Wenn schädliche Inhalte mit einem höheren Schweregrad als dem festgelegten erkannt werden, tritt bei Ihrem Trainingsauftrag ein Fehler auf, und es wird eine Benachrichtigung mit den Fehlerkategorien angezeigt.
Beispielbenachrichtigung:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Ihre Trainingsdaten werden automatisch während des Datenimportauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet.
Wenn während des Feinabstimmungsauftrags aufgrund der Erkennung schädlicher Inhalte in Trainingsdaten ein Fehler auftritt, wird Ihnen dieser Auftrag nicht in Rechnung gestellt.
Modellauswertung
Nach Abschluss des Trainings, aber bevor das fein abgestimmte Modell für die Bereitstellung verfügbar ist, wird das resultierende Modell mithilfe der integrierten Risiko- und Sicherheitsmetriken von Azure hinsichtlich potenziell schädlicher Antworten bewertet. Mit dem Testansatz, den wir auch für grundlegende große Sprachmodelle verwenden, simuliert unsere Bewertungsfunktion eine Unterhaltung mit Ihrem fein abgestimmten Modell, um die Wahrscheinlichkeit, dass schädliche Inhalte ausgegeben werden, zu bewerten. Hierbei werden ebenfalls festgelegte Kategorien schädlicher Inhalte (Gewalt, sexuelle Inhalte, Hass, Fairness und Selbstverletzung) verwendet.
Wenn festgestellt wird, dass ein Modell Ausgaben mit Inhalten generiert, die als schädlicher als ein akzeptabler Grad eingestuft werden, werden Sie darüber informiert, dass Ihr Modell nicht für die Bereitstellung verfügbar ist. Diese Benachrichtigung enthält außerdem Informationen zu den konkreten Kategorien schädlicher Inhalte, die erkannt wurden:
Beispielbenachrichtigung:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Wie bei der Datenbewertung wird das Modell automatisch während des Feinabstimmungsauftrags im Rahmen der Bereitstellung der Feinabstimmungsfunktion bewertet. Nur die daraus resultierende Bewertung (bereitstellbar oder nicht bereitstellbar) wird vom Dienst protokolliert. Wenn bei der Bereitstellung des fein abgestimmten Modells aufgrund der Erkennung schädlicher Inhalte in Modellausgaben ein Fehler auftritt, wird Ihnen die Trainingsausführung nicht in Rechnung gestellt.
Bereitstellen eines optimierten Modells
Wichtig
Bleibt die Bereitstellung eines angepassten Modells nach der Bereitstellung länger als fünfzehn (15) Tage inaktiv, wird die Bereitstellung gelöscht. Die Bereitstellung eines angepassten Modells ist inaktiv, wenn das Modell vor mehr als fünfzehn (15) Tagen bereitgestellt wurde und während eines ununterbrochenen Zeitraums von 15 Tagen keine Abschluss- oder Chatabschlussaufrufe an das Modell übermittelt wurden.
Durch das Löschen einer inaktiven Bereitstellung wird das zugrunde liegende angepasste Modell nicht gelöscht oder verändert. Das angepasste Modell kann jederzeit erneut bereitgestellt werden. Wie unter Preise für Azure OpenAI Service beschrieben, fallen für jedes benutzerdefinierte (optimierte) bereitgestellte Modell stündliche Hostingkosten an, unabhängig davon, ob das Modell für Vervollständigungs- oder Chatvervollständigungsaufrufe genutzt wird. Weitere Informationen zum Planen und Verwalten der Kosten mit Azure OpenAI finden Sie im Leitfaden unter Planen und Verwalten der Kosten für Azure OpenAI Service.
Das folgende Python-Beispiel zeigt, wie Sie die REST-API verwenden, um eine Modellimplementierung für Ihr angepasstes Modell zu erstellen. Die REST-API generiert einen Namen für die Bereitstellung Ihres angepassten Modells.
| -Variable | Definition |
|---|---|
| token | Es gibt mehrere Möglichkeiten, ein Autorisierungstoken zu generieren. Die einfachste Methode für anfängliche Tests besteht darin, Cloud Shell über das Azure-Portal zu starten. Führen Sie dann az account get-access-token aus. Sie können dieses Token als temporäres Autorisierungstoken für API-Tests verwenden. Es wird empfohlen, dies in einer neuen Umgebungsvariable zu speichern. |
| Abonnement | Die Abonnement-ID für die zugeordnete Azure OpenAI-Ressource. |
| resource_group | Der Ressourcengruppenname für Ihre Azure OpenAI-Ressource. |
| resource_name | Den Namen der Azure OpenAI-Ressource. |
| model_deployment_name | Der benutzerdefinierte Name für die Bereitstellung Ihres neuen optimierten Modells. Das ist der Name, auf den in Ihrem Code verwiesen wird, wenn Chatabschlussaufrufe ausgeführt werden. |
| fine_tuned_model | Rufen Sie diesen Wert aus Ihrem Optimierungsauftrag aus dem vorherigen Schritt ab. Er sieht wie folgt aus: gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Dieser Wert muss dem JSON-Code „deploy_data“ hinzugefügt werden. Alternativ können Sie auch einen Prüfpunkt bereitstellen, indem Sie die Prüfpunkt-ID übergeben, die im Format ftchkpt-e559c011ecc04fc68eaa339d8227d02d angezeigt wird. |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Regionsübergreifende Bereitstellung
Die Optimierung unterstützt die Bereitstellung eines optimierten Modells in einer anderen Region als bei der ursprünglichen Optimierung des Modells. Sie können es auch für ein anderes Abonnement/eine andere Region bereitstellen.
Die einzigen Einschränkungen sind, dass die neue Region die Optimierung auch unterstützen muss und bei der abonnementübergreifenden Bereitstellung das Kontos, das das Autorisierungstoken für die Bereitstellung generiert, Zugriff auf die Quell- und Zielabonnements haben muss.
Nachfolgend finden Sie ein Beispiel für die Bereitstellung eines Modells, das von einem Abonnement/einer Region in ein/e andere/s optimiert wurde.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Um zwischen demselben Abonnement, aber unterschiedliche Regionen bereitzustellen, müssen Abonnement- und Ressourcengruppen für Quell- und Zielvariablen identisch, und nur die Namen der Quell- und Zielressourcen müssen eindeutig sein.
Mandantenübergreifende Bereitstellung
Das Konto, das zum Generieren von Zugriffstoken mit az account get-access-token --tenant verwendet wird, sollte über Berechtigungen für Cognitive Services OpenAI-Mitwirkende für die Quell- und Zielressourcen von Azure OpenAI verfügen. Sie müssen zwei unterschiedliche Token generieren, eines für den Quellmandanten und eines für den Zielmandanten.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Bereitstellen eines Modells mit Azure CLI
Das folgende Beispiel zeigt, wie Sie die Azure-Befehlszeilenschnittstelle verwenden, um Ihr benutzerdefiniertes Modell bereitzustellen. Bei der Azure CLI müssen Sie einen Namen für die Bereitstellung Ihres angepassten Modells angeben. Weitere Informationen zur Verwendung der Azure CLI zum Bereitstellen angepasster Modelle finden Sie unter az cognitiveservices account deployment.
Zum Ausführen dieses Azure CLI-Befehls in einem Konsolenfenster müssen Sie die folgenden <Platzhalter> durch die entsprechenden Werte für Ihr benutzerdefiniertes Modell ersetzen:
| Platzhalter | Wert |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Der Name oder die ID Ihres Azure-Abonnements |
| <YOUR_RESOURCE_GROUP> | Name Ihrer Azure-Ressourcengruppe |
| <YOUR_RESOURCE_NAME> | Der Name Ihrer Azure OpenAI-Ressource. |
| <YOUR_DEPLOYMENT_NAME> | Der Name, den Sie für Ihre Modellimplementierung verwenden möchten. |
| <YOUR_FINE_TUNED_MODEL_ID> | Der Name Ihres angepassten Modells. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Verwenden eines bereitgestellten angepassten Modells
Nachdem Ihr benutzerdefiniertes Modell bereitgestellt wurde, können Sie es wie jedes andere bereitgestellte Modell verwenden. Sie können die Chat-Playgrounds in Azure AI Foundry verwenden, um mit Ihrer neuen Bereitstellung zu experimentieren. Sie können damit fortfahren, die gleichen Parameter mit Ihrem benutzerdefinierten Modell zu verwenden, etwa für temperature und max_tokens, wie das auch mit anderen bereitgestellten Modellen möglich ist.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analysieren Ihres angepassten Modells
Azure OpenAI fügt eine Ergebnisdatei mit dem Namen results.csv an jeden Optimierungsauftrag an, nachdem dieser abgeschlossen wurde. Sie können die Ergebnisdatei verwenden, um die Trainings- und Validierungsleistung Ihres angepassten Modells zu analysieren. Die Datei-ID für die Ergebnisdatei wird für jedes angepasste Modell aufgelistet, und Sie können die REST-API verwenden, um die Datei-ID abzurufen und die Ergebnisdatei für die Analyse herunterzuladen.
Im folgenden Python-Beispiel wird die REST-API verwendet, um die Datei-ID der ersten Ergebnisdatei abzurufen, die an den Optimierungsauftrag für Ihr angepasstes Modell angefügt ist, und anschließend wird die Datei zur Analyse in Ihr Arbeitsverzeichnis heruntergeladen.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Die Ergebnisdatei ist eine CSV-Datei, die eine Kopfzeile und eine Zeile für jeden Trainingsschritt enthält, der durch den Optimierungsauftrag ausgeführt wurde. Die Ergebnisdatei enthält die folgenden Spalten:
| Spaltenname | BESCHREIBUNG |
|---|---|
step |
Die Anzahl der Trainingsschritte. Ein Trainingsschritt stellt einen einzelnen Durchgang, vorwärts und rückwärts, über einen Batch von Trainingsdaten dar. |
train_loss |
Der Verlust für den Trainingsbatch. |
train_mean_token_accuracy |
Der Prozentsatz der Token im Trainingsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
valid_loss |
Der Verlust für den Validierungsbatch. |
validation_mean_token_accuracy |
Der Prozentsatz der Token im Validierungsbatch, die vom Modell richtig vorhergesagt wurden Wenn z. B. die Batchgröße auf 3 festgelegt ist und Ihre Daten [[1, 2], [0, 5], [4, 2]] Vervollständigungen enthalten, wird dieser Wert auf 0,83 (5 von 6) festgelegt, wenn das Modell [[1, 1], [0, 5], [4, 2]] vorhergesagt hat. |
full_valid_loss |
Der am Ende jeder Epoche berechnete Validierungsverlust. Wenn das Training gut verläuft, sollte der Verlust abnehmen. |
full_valid_mean_token_accuracy |
Die gültige mittlere Tokengenauigkeit, die am Ende jeder Epoche berechnet wird. Wenn das Training gut verläuft, sollte die Tokengenauigkeit größer werden. |
Sie können die Daten in Ihrer results.csv-Datei auch als Plots im Azure KI Foundry-Portal anzeigen. Wählen Sie den Link für Ihr trainiertes Modell aus, und es werden drei Diagramme angezeigt: Verlust, mittlere Tokengenauigkeit und Tokengenauigkeit. Wenn Sie Validierungsdaten bereitgestellt haben, werden beide Datasets auf demselben Plot angezeigt.
Achten Sie darauf, dass Ihr Verlust mit der Zeit abnimmt und Ihre Genauigkeit zunimmt. Wenn eine Divergenz zwischen Ihren Trainings- und Validierungsdaten angezeigt wird, kann dies auf eine Überanpassung hindeuten. Versuchen Sie, mit weniger Epochen oder einem kleineren Multiplikator der Lernrate zu trainieren.
Bereinigen Ihrer Bereitstellungen, optimierten Modelle und Trainingsdateien
Wenn Sie mit Ihrem angepassten Modell fertig sind, können Sie die Bereitstellung und das Modell löschen. Sie können gegebenenfalls außerdem die Trainings- und Validierungsdateien löschen, die Sie in den Dienst hochgeladen haben.
Löschen Ihrer Modellimplementierung
Sie können verschiedene Methoden verwenden, um die Bereitstellung für Ihr angepasstes Modell zu löschen:
Löschen Ihres angepassten Modells
Analog dazu können Sie verschiedene Methoden verwenden, um Ihr angepasstes Modell zu löschen:
Hinweis
Sie können kein benutzerdefiniertes Modell löschen, für das eine Bereitstellung vorhanden ist. Zuerst müssen Sie die Modellimplementierung löschen, bevor Sie Ihr angepasstes Modell löschen können.
Löschen Ihrer Trainingsdateien
Sie können optional Trainings- und Validierungsdateien, die Sie zum Trainieren hochgeladen haben, und Ergebnisdateien, die während des Trainings generiert wurden, aus Ihrem Azure OpenAI-Abonnement löschen. Sie können die folgenden Methoden verwenden, um Ihre Trainings-, Validierungs- und Ergebnisdateien zu löschen:
Kontinuierliche Optimierung
Nachdem Sie ein optimiertes Modell erstellt haben, können Sie das Modell im Laufe der Zeit durch weitere Optimierungen weiter verfeinern. Kontinuierliche Optimierung ist der iterative Prozess, bei dem ein bereits optimiertes Modell als Basismodell ausgewählt und anhand neuer Sätze von Trainingsbeispielen weiter verfeinert wird.
Wenn Sie eine Optimierung für ein Modell durchführen möchten, das Sie bereits optimiert haben, verwenden Sie den gleichen Prozess wie unter Erstellen eines angepassten Modells beschrieben, anstatt jedoch den Namen eines generischen Basismodells anzugeben, geben Sie die ID Ihres bereits abgestimmten Modells an. Die ID des optimierten Modells sieht wie folgt aus: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Außerdem wird empfohlen, den suffix-Parameter einzuschließen, um die Unterscheidung zwischen verschiedenen Iterationen Ihres optimierten Modells zu vereinfachen.
suffix verwendet eine Zeichenfolge und wird so festgelegt, dass das optimierte Modell identifiziert wird. Das Suffix kann bis zu 40 Zeichen (a-z, A-Z, 0-9, - und _) enthalten, die ihrem fein abgestimmten Modellnamen hinzugefügt werden.
Wenn Sie sich nicht sicher sind, welche ID Ihr optimiertes Modell hat, finden Sie diese Informationen auf der Seite Modelle von Azure KI Foundry, oder Sie können eine Liste der Modelle für eine bestimmte Azure OpenAI-Ressource mithilfe der REST-API generieren.
Andere Bereitstellungstypen
Die Feinabstimmung von Azure OpenAI unterstützt globale Standardeinsätze in USA, Osten2, USA, Norden-Mitte und Schweden, Mitte für:
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06
Und unterstützt regionale verwaltet-bereitgestellte Bereitstellungen in USA, Norden-Mitte und Schweiz, Westen für:
gpt-4o-mini-2024-07-18gpt-4o-2024-08-06
Globaler Standard (Vorschau)
Globale, optimierte Standardimplementierungen bieten Kosteneinsparungen, aber benutzerdefinierte Modellgewichte können vorübergehend außerhalb der Geographie Ihrer Azure OpenAI-Ressource gespeichert werden.

Globale Standard-Optimierungsbereitstellungen unterstützen derzeit keine Visionen und strukturierten Ausgaben.
Bereitgestellt-verwaltet (Vorschau)
Bereitgestellt-verwaltete und optimierte Bereitstellungen bieten eine vorhersehbare Leistung für optimierte Bereitstellungen. Im Rahmen der öffentlichen Vorschauversion können bereitgestellt-verwaltete Bereitstellungen regional über die Datenebene der REST-API ab der Version 2024-10-01 erstellt werden. Weiter unten finden Sie Beispiele dafür.
Bereitgestellt-verwaltete und optimierte Bereitstellungen unterstützen derzeit keine Visionen und strukturierten Ausgaben.
Erstellen einer bereitgestellt-verwalteten Bereitstellung
Um eine neue Bereitstellung zu erstellen, erstellen Sie einen HTTP PUT-Aufruf über die REST-API zum Erstellen oder Aktualisieren von Bereitstellungen. Der Ansatz ähnelt einer regionsübergreifenden Bereitstellung mit den folgenden Ausnahmen:
- Sie müssen einen SKU-Namen für
ProvisionedStandardangeben. - Die Kapazität muss in PTUs angegeben werden.
- Die
api-versionmuss2024-10-01oder neuer sein. - Die HTTP-Methode sollte auf
PUTfestgelegt sein.
So stellen Sie beispielsweise ein gpt-4o-mini-Modell bereit:
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "ProvisionedStandard", "capacity": 25},
"properties": {
"model": {
"format": "OpenAI",
"name": "gpt-4omini-ft-model-name",
"version": "1",
"source": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{SourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{SourceAOAIAccountName}"
}
}
}'
Skalieren eines optimierten Modells auf „Bereitgestellt-verwaltet“
Zum Skalieren einer optimierten verwalteten Bereitstellung und um die PTU-Kapazität zu erhöhen oder zu verringern, führen Sie den gleichen PUT REST-API-Aufruf wie beim Erstellen der Bereitstellung aus und geben Sie einen aktualisierten capacity Wert für die sku an. Beachten Sie, dass bereitgestellte Bereitstellungen in kleinen Schritten abskaliert werden müssen.
Um beispielsweise das im vorherigen Abschnitt bereitgestellte Modell von 25 auf 40 PTU zu skalieren, führen Sie einen weiteren PUT-Aufruf durch und erhöhen Sie die Kapazität:
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "ProvisionedStandard", "capacity": 40},
"properties": {
"model": {
"format": "OpenAI",
"name": "gpt-4omini-ft-model-name",
"version": "1",
"source": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{SourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{SourceAOAIAccountName}"
}
}
}'
Löschen einer bereitgestellt-verwalteten Bereitstellung
Verwenden Sie zum Löschen einer Bereitstellung die REST-API zum Löschen von Bereitstellungen (/rest/api/aiservices/accountmanagement/deployments/delete?view=rest-aiservices-accountmanagement-2024-10-01&tabs=HTTP&preserve-view=true) und senden Sie HTTP DELETE an die Bereitstellungsressource. Wie beim Erstellen von Bereitstellungen müssen Sie die folgenden Parameter einschließen:
- Azure-Abonnement-ID
- Azure-Ressourcengruppenname
- Name der Azure OpenAI-Ressource
- Name der zu löschenden PTU-Bereitstellung
So löschen Sie beispielsweise das in den vorherigen Abschnitten erstellte und geänderte Modell:
curl -X DELETE "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-01" \
-H "Authorization: Bearer <TOKEN>"
Optimierung in Vision
Die Optimierung ist auch bei Bildern in Ihren JSONL-Dateien möglich. Genauso wie Sie ein oder mehrere Bilder an Chatvervollständigungen senden können, können Sie dieselben Nachrichtentypen in Ihre Trainingsdaten aufnehmen. Bilder können entweder als öffentlich zugängliche URLs oder Daten-URIs bereitgestellt werden, die Base64-codierte Bilder enthalten.
Anforderungen für Bilddatasets
- Ihre Trainingsdatei darf maximal 50.000 Beispiele enthalten, die Bilder beinhalten (ohne Textbeispiele).
- Jedes Beispiel kann höchstens 64 Bilder enthalten.
- Jedes Bild darf höchstens 10 MB groß sein.
Format
Bilder müssen in den folgenden Formaten vorliegen:
- JPEG
- PNG
- WEBP
Bilder müssen sich im RGB- oder RGBA-Bildmodus befinden.
Sie können Bilder nicht als Ausgabe aus Nachrichten mit der Rolle „Assistent“ aufnehmen.
Richtlinie für die Inhaltsmoderation
Wir scannen Ihre Bilder vor dem Training, um sicherzustellen, dass sie dem Transparenzhinweis unserer Nutzungsrichtlinie entsprechen. Dies führt u. U. zu Wartezeit bei der Dateiüberprüfung, bevor die Optimierung beginnt.
Bilder, die Folgendes enthalten, werden aus Ihrem Dataset ausgeschlossen und nicht für Trainings verwendet:
- Personen
- Gesichtserkennung
- CAPTCHAs
Wichtig
Für die Optimierung der Gesichtsüberprüfung in Vision: Wir überprüfen auf Gesichter/Personen, um diese Bilder beim Trainieren des Modells zu überspringen. Die Überprüfungsfunktion nutzt Gesichtserkennung OHNE Gesichtsidentifikation. Das bedeutet, dass wir keine Vorlage für Gesichter erstellen oder bestimmte Gesichtsgeometrie messen, und die für die Gesichtsüberprüfung verwendete Technologie kann Einzelpersonen nicht eindeutig identifizieren. Weitere Informationen zu Daten und Datenschutz bei der Gesichtserkennung finden Sie unter Daten und Datenschutz bei der Gesichtserkennung – Azure KI Services | Microsoft Learn.
Promptzwischenspeicherung
Die Azure OpenAI-Optimierung unterstützt Prompt-Caching bei ausgewählten Modellen. Mit der Promptzwischenspeicherung können Sie die gesamte Anforderungslatenz und die Kosten für längere Prompts reduzieren, die identischen Inhalt am Anfang des Prompts aufweisen. Weitere Informationen zum Prompt-Caching finden Sie unter Erste Schritte mit Prompt-Caching.
Direkte Präferenzoptimierung (DPO) (Vorschau)
Die direkte Präferenzoptimierung (DPO) ist eine Ausrichtungsmethode für große Sprachmodelle, die zur Anpassung der Modellgewichte auf der Grundlage menschlicher Präferenzen verwendet wird. Es unterscheidet sich vom vertiefenden Lernen aus menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF) dadurch, dass es keine Anpassung eines Belohnungsmodells erfordert und einfachere binäre Datenpräferenzen für das Training verwendet. Es ist rechnerisch leichter und schneller als RLHF, während es bei der Ausrichtung genauso effektiv ist.
Warum ist DPO nützlich?
DPO ist besonders nützlich in Szenarien, in denen es keine eindeutige richtige Antwort gibt und subjektive Elemente wie Tonfall, Stil oder bestimmte inhaltliche Vorlieben wichtig sind. Dieser Ansatz ermöglicht es dem Modell auch, sowohl von positiven Beispielen (was als richtig oder ideal angesehen wird) als auch von negativen Beispielen (was weniger erwünscht oder falsch ist) zu lernen.
Man geht davon aus, dass DPO eine Technik ist, die es den Kunden erleichtern wird, qualitativ hochwertige Trainingsdatensätze zu erzeugen. Während viele Kunden Schwierigkeiten haben, ausreichend große Datensätze für die überwachte Feinabstimmung zu generieren, verfügen sie oft bereits über Präferenzdaten, die auf der Grundlage von Benutzerprotokollen, A/B-Tests oder kleineren manuellen Annotationen gesammelt wurden.
Dataset-Format für die direkte Präferenzoptimierung
Dateien für die direkte Präferenzoptimierung haben ein anderes Format als Daten für die überwachte Feinabstimmung. Kunden geben eine „Unterhaltung“ ein, die die Systemnachricht und die anfängliche Benutzernachricht enthält, und dann „Vervollständigungen“ mit gepaarten Präferenzdaten. Benutzer können nur zwei Vervollständigungen angeben.
Die Felder der obersten Ebene sind: input, preferred_output, und non_preferred_output
- Jedes Element im Ordner preferred_output/non_preferred_output muss mindestens eine Assistentenmeldung enthalten
- Jedes Element im Ordner preferred_output/non_preferred_output kann nur Rollen in (assistant, tool) haben.
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Training-Datasets müssen im Format jsonl vorliegen.
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Modellunterstützung für die direkte Präferenzoptimierung
-
gpt-4o-2024-08-06unterstützt die direkte Präferenzoptimierung in den jeweiligen Feinabstimmungsregionen. Die neueste Verfügbarkeit der Region wird auf der Seite „Modelle“ aktualisiert.
Benutzer können die Feinabstimmung der Präferenzen sowohl mit Basismodellen als auch mit Modellen verwenden, die bereits mit der überwachten Feinabstimmung optimiert wurden, solange es sich um ein unterstütztes Modell/eine unterstützte Version handelt.
Wie verwendet man die Feinabstimmung der direkten Präferenzoptimierung?
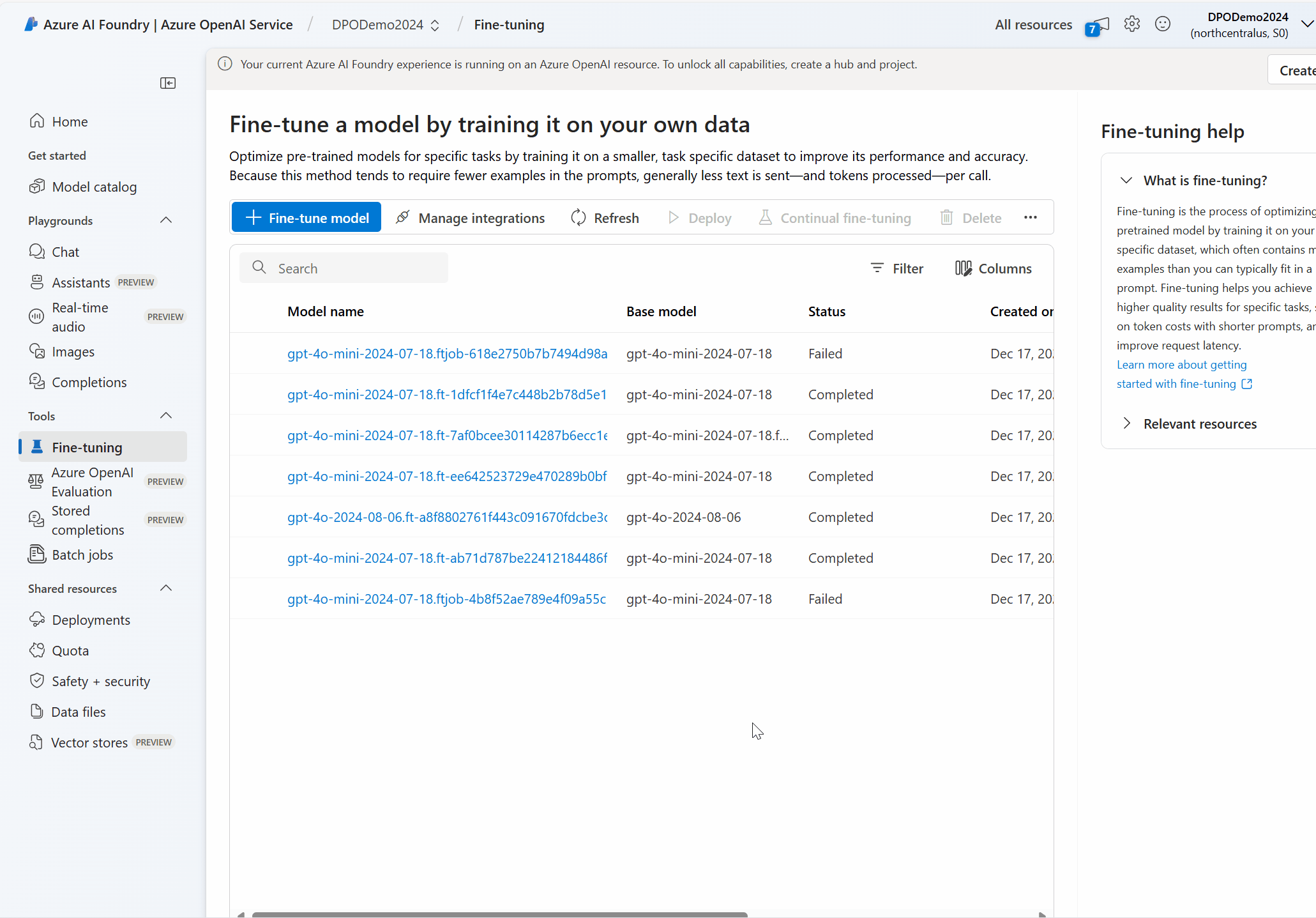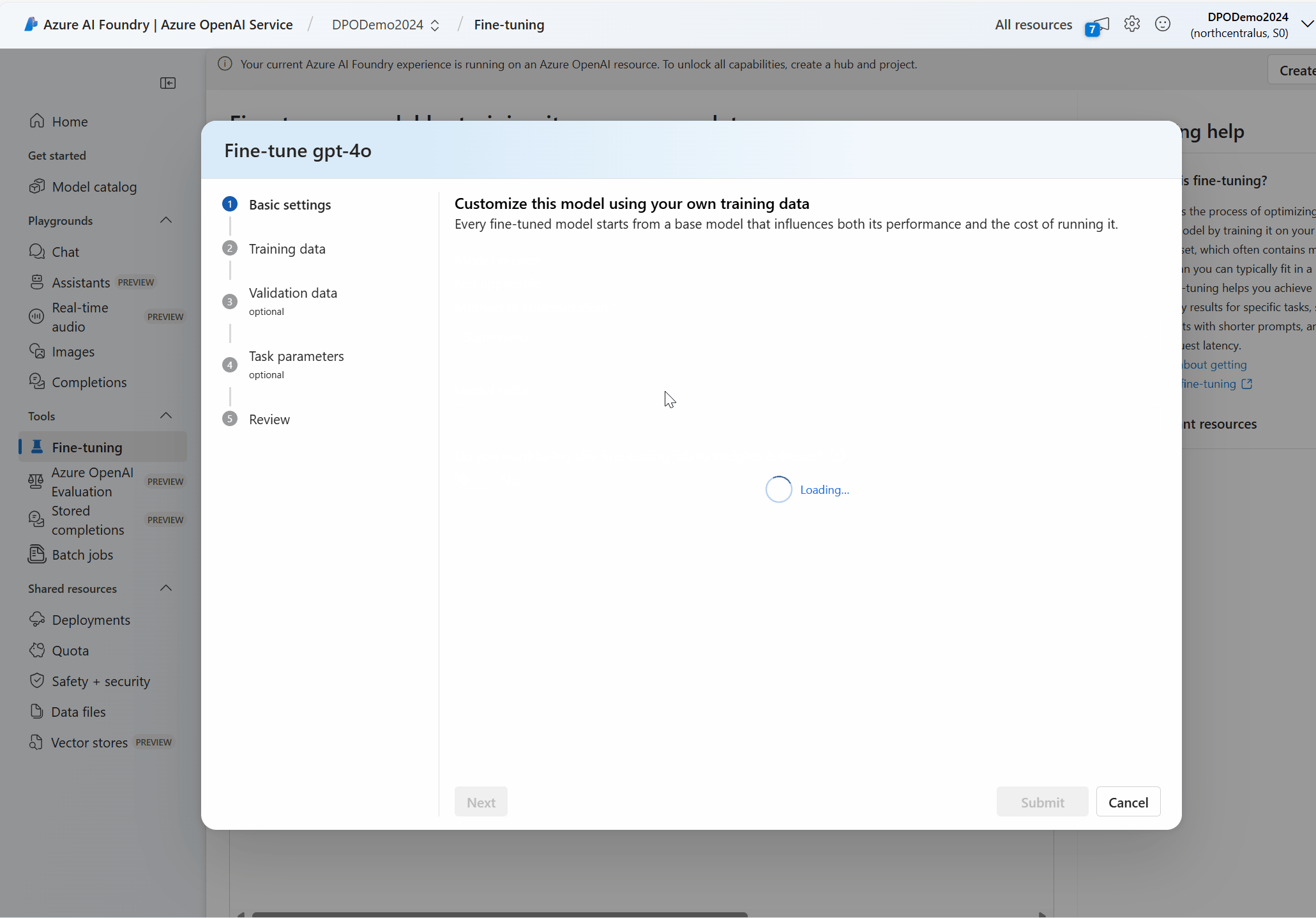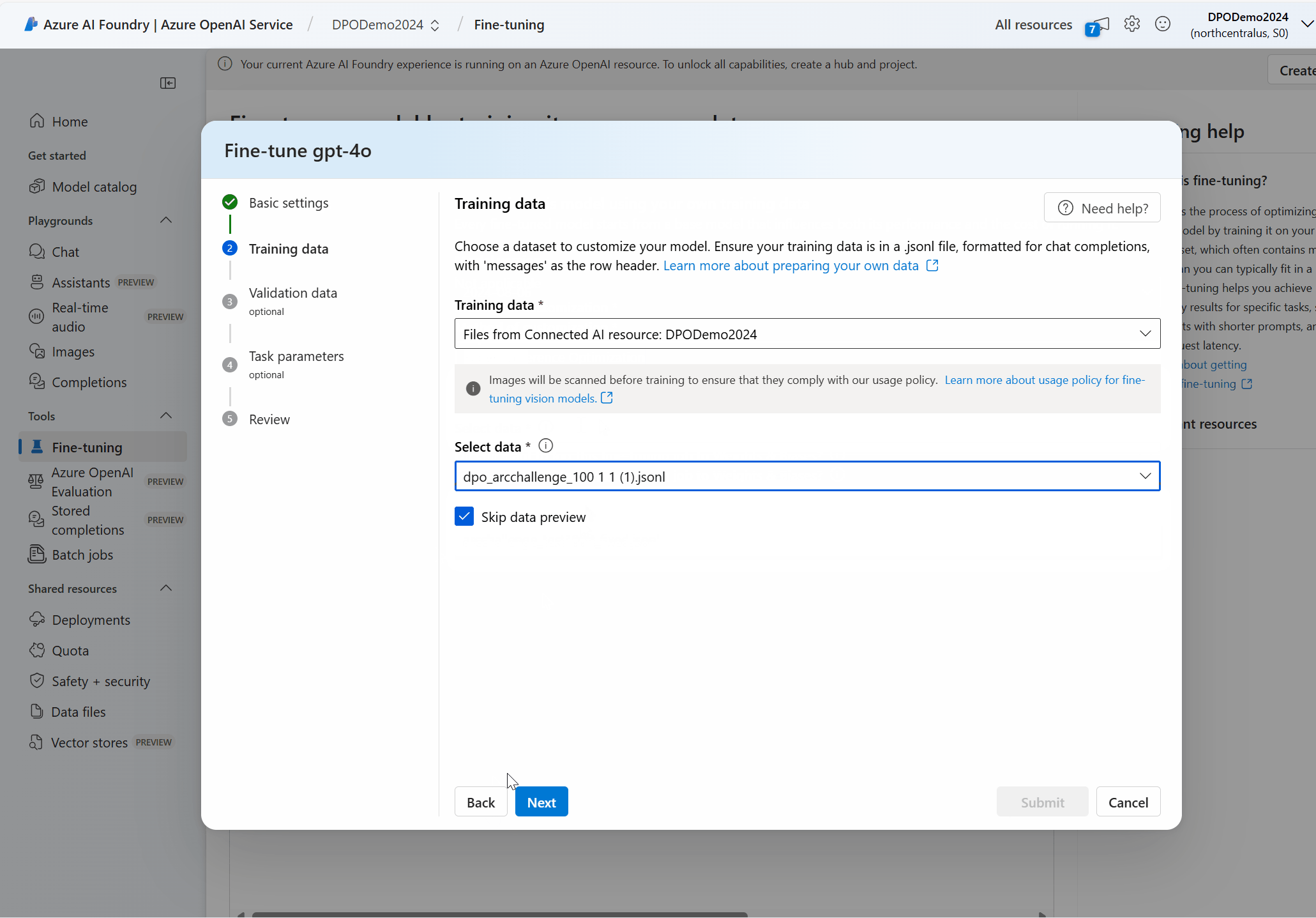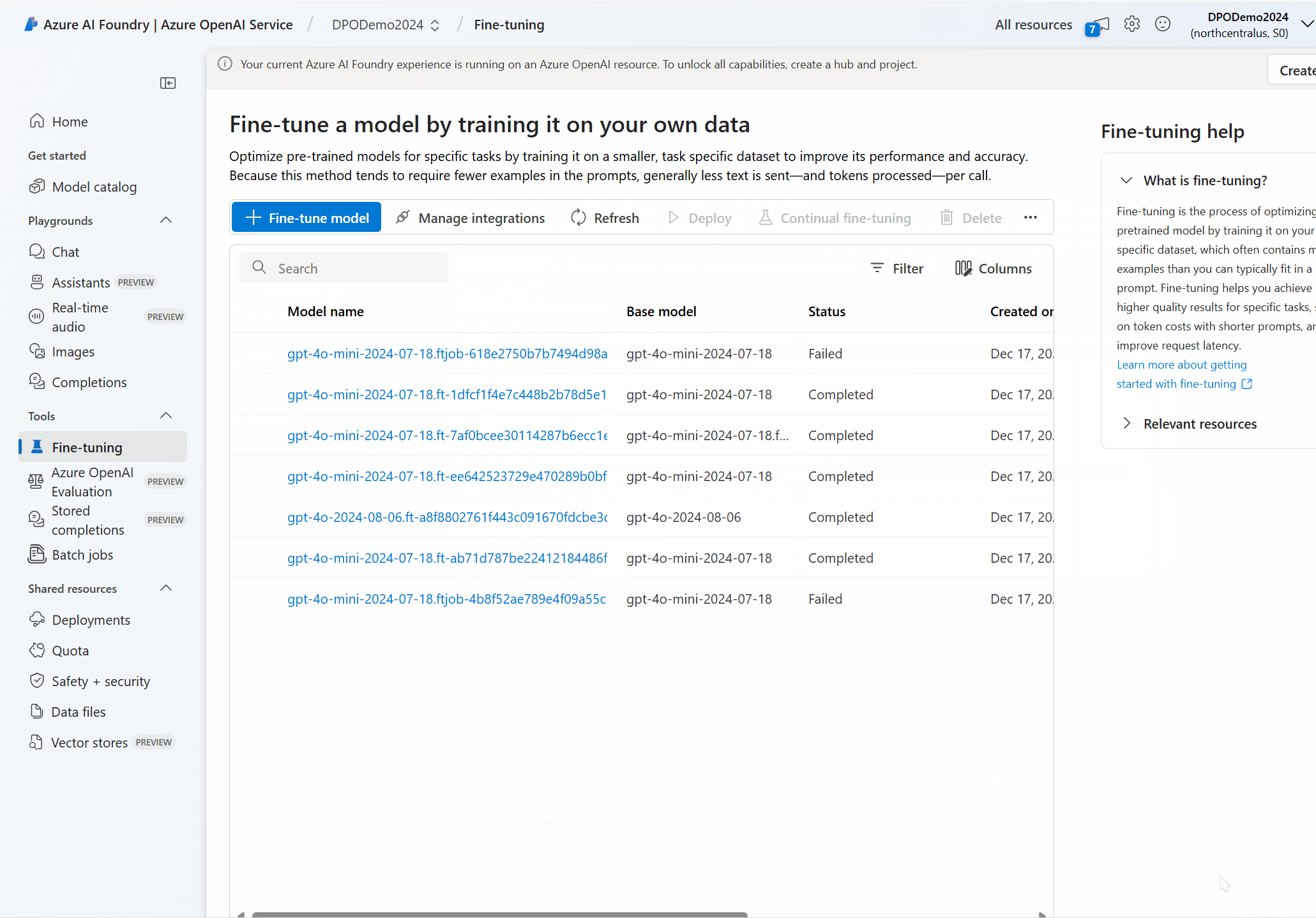
- Bereiten Sie
jsonlDatasets im Präferenz-Format vor. - Wählen Sie das Modell und dann die Methode der Anpassung Direkte Präferenzoptimierung.
- Datasets hochladen – Training und Validierung Zeigen Sie bei Bedarf eine Vorschau an.
- Wählen Sie die Hyperparameter aus. Für erste Experimente werden die Standardwerte empfohlen.
- Überprüfen Sie die Auswahl und erstellen Sie einen Optimierungsauftrag.
Problembehandlung
Wie aktiviere ich die Optimierung?
Um erfolgreich auf die Optimierung zuzugreifen, muss Ihnen die Rolle Mitwirkender für Cognitive Services OpenAI zugewiesen sein. Selbst für Personen mit den hohen Berechtigungen der Rolle „Dienstadministrator“ muss dieses Konto explizit festgelegt werden, um auf die Optimierung zugreifen zu können. Weitere Informationen finden Sie im Leitfaden zur rollenbasierten Zugriffssteuerung.
Warum ist mein Upload fehlgeschlagen?
Wenn der Dateiupload im Azure AI Foundry-Portal fehlschlägt, können Sie die Fehlermeldung unter Datendateien im Azure AI Foundry-Portal anzeigen. Zeigen Sie mit dem Mauszeiger auf „Fehler“ (unter der Statusspalte), und eine Erläuterung des Fehlers wird angezeigt.

Mein feinabgestimmtes Modell scheint sich nicht verbessert zu haben
Fehlende Systemmeldung: Sie müssen beim Optimieren eine Systemnachricht bereitstellen. Sie sollten dieselbe Systemmeldung bereitstellen, wenn Sie das feinabgestimmte Modell verwenden. Wenn Sie eine andere Systemmeldung angeben, werden möglicherweise unterschiedliche Ergebnisse angezeigt als die, für die die Feinabstimmung durchgeführt wurde.
Nicht genügend Daten: Während 10 das Mindestmaß für die Ausführung der Pipeline ist, benötigen Sie Hunderte bis Tausende von Datenpunkten, um dem Modell eine neue Fähigkeit anzutrainieren. Bei zu wenigen Datenpunkten besteht die Gefahr der Überanpassung und schlechten Verallgemeinerung. Ihr fein abgestimmtes Modell kann bei den Trainingsdaten gut abschneiden, aber bei anderen Daten schlecht, weil es sich die Trainingsbeispiele gemerkt hat, anstatt Muster zu lernen. Um optimale Ergebnisse zu erzielen, sollten Sie einen Datensatz mit Hunderten oder Tausenden von Datenpunkten vorbereiten.
Schlechte Daten: Ein schlecht kuratiertes oder nicht repräsentatives Dataset erzeugt ein Modell mit niedriger Qualität. Ihr Modell kann ungenaue oder voreingenommene Muster aus Ihrem Dataset lernen. Wenn Sie z. B. einen Chatbot für den Kundendienst trainieren, aber nur Trainingsdaten für ein Szenario (z. B. Artikelrückgabe) bereitstellen, weiß er nicht, wie er auf andere Szenarien reagieren soll. Oder wenn Ihre Trainingsdaten schlecht sind (falsche Antworten enthalten), lernt Ihr Modell, falsche Ergebnisse zu liefern.
Optimierung mit Vision
Vorgehensweise, wenn Bilder übersprungen werden
Ihre Bilder können aus den folgenden Gründen übersprungen werden:
- Sie enthalten CAPTCHAs.
- Sie enthalten Personen.
- Sie enthalten Gesichter.
Entfernen Sie das Bild. Derzeit können Modelle mit Bildern, die diese Elemente enthalten, nicht optimiert werden.
Allgemeine Probleme
| Problem | Ursache/Lösung |
|---|---|
| Übersprungene Bilder | Bilder können aus den folgenden Gründen übersprungen werden: Sie enthalten CAPTCHAs, Personen oder Gesichter. Entfernen Sie das Bild. Derzeit können Modelle mit Bildern, die diese Elemente enthalten, nicht optimiert werden. |
| Nicht zugängliche URL | Vergewissern Sie sich, dass die Bild-URL öffentlich zugänglich ist. |
| Bild zu groß | Vergewissern Sie sich, dass Ihre Bilder innerhalb der Größenbeschränkungen für Datasets liegen. |
| Ungültiges Bildformat | Vergewissern Sie sich, dass Ihre Bilder das erforderliche Datasetformat aufweisen. |
Hochladen großer Dateien
Ihre Trainingsdateien können ziemlich groß werden. Sie können Dateien mit bis zu 8 GB in mehreren Teilen hochladen, indem Sie die Upload-API und nicht die Datei-API verwenden, die nur Dateiuploads von bis zu 512 MB zulässt.
Senken der Trainingskosten
Wenn Sie den Detailparameter für ein Bild auf „niedrig“ festlegen, wird die Größe des Bilds in 512 × 512 Pixel geändert, und das Bild wird unabhängig von seiner Größe nur durch 85 Token dargestellt. Dadurch werden die Kosten für Trainings gesenkt.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Weitere Überlegungen zur Optimierung in Vision
Um die Wiedergabetreue des Bildverständnisses zu steuern, legen Sie den Detailparameter von image_url auf low, high oder auto für jedes Bild fest. Dies wirkt sich auch auf die Anzahl der Token pro Bild, die das Modell während der Trainingszeit sieht, sowie auf die Kosten des Trainings aus.
Nächste Schritte
- Erkunden Sie die Optimierungsfunktionen im Azure OpenAI-Optimierungstutorial.
- Überprüfen der Optimierung des regionalen Verfügbarkeitsmodells
- Weitere Informationen zu Azure OpenAI Kontingenten