Grundlegende Konzepte
Wann ist Metrics Advisor veraltet?
Ab dem 20. September 2023 können Sie keine neuen Metrics Advisor-Ressourcen mehr erstellen. Der Metrics Advisor-Dienst wird am 1. Oktober 2026 eingestellt.
Was sind mehrdimensionale Zeitreihendaten?
Weitere Informationen finden Sie in der Definition für Multi-dimensional metric (Mehrdimensionale Metrik) im Glossar.
Wie viele Daten sind erforderlich, damit der Metrics Advisor die Anomalieerkennung startet?
Mindestens ein Datenpunkt kann eine Anomalieerkennung auslösen. Dies bringt jedoch nicht die beste Genauigkeit mit sich. Der Dienst geht von einem Fenster vorheriger Datenpunkte aus und verwendet den Wert, den Sie während der Datenfeederstellung als Regel zum Füllen von Lücken angegeben haben.
Es wird empfohlen, dass Sie vor dem Zeitstempel, für den Sie die Ermittlung durchführen möchten, über einige Daten verfügen. Ausgehend von der Granularität der Daten variiert die empfohlene Datenmenge wie unten beschrieben.
| Granularität | Empfohlene Datenmenge für die Erkennung |
|---|---|
| Weniger als 5 Minuten | 4 Tage an Daten |
| 5 Minuten bis 1 Tag | 28 Tage an Daten |
| Mehr als 1 Tag, bis zu 31 Tage | 4 Jahre an Daten |
| Mehr als 31 Tage | 48 Jahre an Daten |
Welche Daten werden von Metrics Advisor verarbeitet, und wie werden die Daten aufbewahrt?
- Metrics Advisor verarbeitet Zeitreihendaten, die aus einer Datenquelle des Kunden gesammelt werden; Verlaufsdaten werden für die Modellauswahl verwendet und bestimmen die erwartete Datengrenze.
- Die Zeitreihendaten und Rückschlussergebnisse des Kunden werden innerhalb des Diensts gespeichert. Metrics Advisor speichert und verarbeitet keine Kundendaten außerhalb der Region, in der der Kunde die Dienstinstanz bereitstellt.
Warum erkennt Metrics Advisor keine Anomalien in Verlaufsdaten?
Metrics Advisor dient zum Erkennen von Livestreamingdaten. Es gibt eine Einschränkung der maximalen Länge der Verlaufsdaten, die der Dienst rückwirkend prüft und für die er eine Anomalieerkennung ausführt. Dies bedeutet, dass nur Datenpunkte nach einem bestimmten frühesten Zeitstempel Anomalieerkennungsergebnisse aufweisen. Der früheste Zeitstempel hängt von der Granularität der Daten ab.
Ausgehend von der Granularität der Daten weisen die Längen der Verlaufsdaten die Anomalieerkennungsergebnisse wie folgt auf.
| Granularität | Maximale Länge der Verlaufsdaten für die Anomalieerkennung |
|---|---|
| Weniger als 5 Minuten | Onboardingzeit – 13 Stunden |
| 5 Minuten bis weniger als 1 Stunde | Onboardingzeit – 4 Tage |
| 1 Stunde bis weniger als 1 Tag | Onboardingzeit – 14 Tage |
| 1 Tag | Onboardingzeit – 28 Tage |
| Mehr als 1 Tag, weniger als 31 Tage | Onboardingzeit – 2 Jahre |
| Mehr als 31 Tage | Onboardingzeit – 24 Jahre |
Welche Art der Datenaufbewahrung und welche Einschränkungen gelten für Metrics Advisor?
- Datenaufbewahrung. Bei Metrics Advisor werden höchstens 10.000 Zeitintervalle (Was ist ein Intervall?) ab dem aktuellen Zeitstempel beibehalten. Dies gilt unabhängig davon, ob Daten verfügbar sind oder nicht. Daten außerhalb dieses Zeitfensters werden gelöscht. Zuordnung der Datenaufbewahrung zur Anzahl von Tagen für unterschiedliche Metrikgranularität.
| Granularität (Min.) | Aufbewahrung (Tage) |
|---|---|
| 1 | 6,94 |
| 5 | 34,72 |
| 15 | 104,1 |
| 60 (=stündlich) | 416,67 |
| 1440 (=täglich) | 10000,00 |
- Beschränkung der maximalen Anzahl von Zeitreihen innerhalb einer Metrik.
Sie können mehrere Dimensionen innerhalb einer Metrik aufweisen, und jede Dimension kann mehrere Werte aufweisen. Die maximale Kombination aus Dimensionen für eine Metrik darf 100.000 nicht überschreiten.
- Metrics Advisor Ressourcenadministratoren und Datenfeedbesitzer werden benachrichtigt, wenn die Einschränkung von 80% auf der Detailseite des Datenfeeds erreicht wird.
- Wenn die Metrik die Einschränkung überschritten hat, wird der Datenfeed angehalten und darauf gewartet, dass Kunden Folgeaktionen ausführen. Es wird empfohlen, den Datenfeed durch Filtern auf mehrere Datenfeeds aufzuteilen.
- Einschränkung der maximalen Datenpunkte, die in einer Metrics Advisor Instanz gespeichert sind
Metrics Advisor rechnet mit allen Datenpunkten aller Datenfeeds, die ab dem ersten Erfassungszeitstempel in die Instanz integriert wurden. Die maximale Anzahl von Datenpunkten, die in einer Metrics Advisor Instanz gespeichert werden sollen, beträgt 2 Milliarden.
- Metrics Advisor-Ressourcenadministratoren und alle Benutzer werden benachrichtigt, wenn die Einschränkung von 80 % auf der Seite mit der Datenfeedliste und auf der Seite zum Hinzufügen neuer Datenfeeds erreicht wird.
- Wenn die Gesamtanzahl der Datenpunkte die Beschränkung überschritten hat, werden alle Datenfeeds angehalten und das Onboarding neuer Feeds wird ebenfalls blockiert. Es wird empfohlen, nicht verwendete Datenfeeds zu löschen oder eine neue Metrics Advisor Ressource in Ihrem Abonnement zu erstellen.
Warum kann ich mich nicht bei Metrics Advisor anmelden? Die Fehlermeldung besagt: „Die Ressource wird aufgrund von 90 Tagen Inaktivität nicht mehr ausgeführt“
Es gibt zwei Fälle, in denen eine Ressource außer Betrieb genommen wird:
- Eine Metrics Advisor-Ressource wird erstellt, aber innerhalb von 90 Tagen wurde kein Datenfeed integriert. Die Ressource wird nach 90 Tagen aufgrund von Inaktivität außer Betrieb genommen.
- Wenn ein oder mehrere Datenfeeds erstellt wurden, es jedoch keine neuen Daten gibt, die in Metrics Advisor aufgenommen werden, geht der Dienst in den Leerlaufmodus über und es werden keine Daten verarbeitet. Das System versucht weiterhin, Daten regulär aus der Quelle gemäß der Granularität der Metriken zu erfassen. Wenn jedoch weiterhin keine Daten verfügbar sind oder keine einzelne Zeitreihe für einen Zeitraum von 90 aufeinander folgenden Tagen verarbeitet werden soll, wird die Ressource außer Betrieb genommen. Alle historischen Daten, die der Ressource zugeordnet sind, gehen verloren, wenn sie außer Betrieb genommen wird.
Es wird empfohlen, eine neue Ressource zu erstellen und die alte Ressource zu löschen, wenn Sie die Verwendung neu starten möchten.
Wie erkenne ich Spitzen und Einbrüche als Anomalien?
Wenn Sie harte Schwellenwerte vordefiniert haben, können Sie „harter Schwellenwert“ unter Anomalieerkennungskonfiguration manuell festlegen. Wenn keine Schwellenwerte vorhanden sind, können Sie „intelligente Erkennung“ verwenden, die mit KI betrieben wird. Ausführliche Informationen finden Sie unter Optimieren der Erkennungskonfiguration.
Wie erkenne ich eine fehlende Übereinstimmung mit regulären (saisonalen) Mustern als Anomalien?
Die intelligente Erkennung ist in der Lage, das Muster Ihrer Daten einschließlich saisonaler Muster zu lernen. Anschließend werden die Datenpunkte, die den regulären Mustern nicht entsprechen, als Anomalien erkannt. Ausführliche Informationen finden Sie unter Optimieren der Erkennungskonfiguration.
Unterstützt Metrics Advisor Datenquellen, die sich hinter einem VNET befinden?
Nein, Metrics Advisor unterstützt derzeit keine Datenquellen, die sich hinter einem VNET befinden.
Wie erkenne ich fehlende Schwankungen als Anomalien?
Wenn Ihre Daten normalerweise recht instabil sind und stark schwanken und Sie benachrichtigt werden möchten, wenn die Daten zu stabil sind oder sogar überhaupt keine Schwankungen mehr aufweisen, kann „Change Threshold“ (Änderungsschwellenwert) so konfiguriert werden, dass solche Datenpunkte erkannt werden, wenn die Änderung zu gering ist. Ausführliche Informationen finden Sie unter Anomalieerkennungskonfiguration.
Wie richte ich E-Mail-Einstellungen ein und aktiviere Warnungen per E-Mail?
Ein Benutzer mit den Berechtigungen „Abonnementadministrator“ oder „Ressourcengruppenadministrator“ muss zu der Metrics Advisor-Ressource navigieren, die im Azure-Portal erstellt wurde, und die Registerkarte Zugriffssteuerung (IAM) auswählen.
Wählen Sie Rollenzuweisung hinzufügen aus.
Wählen Sie die Rolle Cognitive Services Metrics Advisor-Administrator und dann Ihr Konto aus, wie in der Abbildung unten dargestellt.
Wählen Sie die Schaltfläche Speichern aus, und Sie werden als Administrator der Metrik-Advisor-Ressource hinzugefügt. Alle vorgenannten Aktionen müssen von einem Abonnementadministrator oder einem Ressourcengruppenadministrator ausgeführt werden.
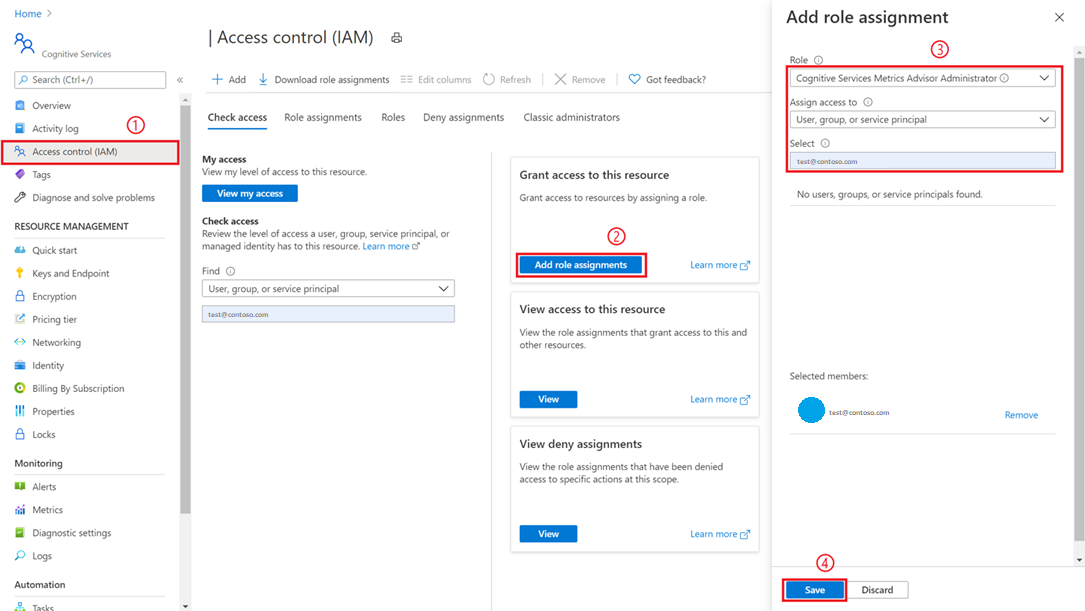
Es kann bis zu einer Minute dauern, bis die Berechtigungen weitergegeben werden. Wählen Sie dann Ihren Metrics Advisor-Arbeitsbereich und anschließend die Option E-Mail-Einstellung im linken Navigationsbereich aus. Füllen Sie die erforderlichen Felder aus, insbesondere die SMTP-bezogenen Informationen.
Wählen Sie Speichern aus, dann sind Sie mit der E-Mail-Konfiguration fertig. Sie können neue Hooks erstellen und metrische Anomalien abonnieren, um Warnungen in Quasi-Echtzeit zu erhalten.

Erweiterte Konzepte
Wie erstellt Metrics Advisor eine Diagnosestruktur für mehrdimensionale Metriken?
Eine Metrik kann in mehrere Zeitreihen nach Dimensionen aufgeteilt werden. Beispielsweise wird die Metrik Response latency für alle Dienste überwacht, die im Besitz des Teams sind. Die Service-Kategorie könnte als Dimension verwendet werden, um die Metrik zu erweitern, sodass Response latency durch Service1, Service2 usw. aufgeteilt wird. Jeder Dienst kann auf verschiedenen Computern in mehreren Rechenzentren bereitgestellt werden, damit die Metrik weiter durch Machine und Data center aufgeteilt werden kann.
| Dienst | Rechenzentrum | Machine |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
Ausgehend von der Gesamtsumme Response latency können wir Detailinformationen der Metrik nach Service, Data center und Machine anzeigen. Möglicherweise ist es jedoch sinnvoller, dass die Dienstbesitzer den Pfad Service ->Data center ->Machine oder Infrastrukturtechniker den Pfad Data Center ->Machine ->Service benutzen. Dies hängt alles von den individuellen Geschäftsanforderungen des Benutzers ab.
Im Metric Advisor können Benutzer jeden Pfad angeben, für den sie von einem Knoten der hierarchischen Topologie aus einen Drilldown oder ein Rollup ausführen möchten. Genauer gesagt handelt es sich bei der hierarchischen Topologie um ein gerichtetes azyklisches Diagramm und nicht um eine Baumstruktur. Es gibt eine vollständige hierarchische Topologie, die aus allen möglichen Dimensionskombinationen besteht, wie im folgenden Beispiel:

Wenn die Dimension Service theoretisch Ls verschiedene Werte, die Dimension Data centerLdc verschiedene Werte und die Dimension MachineLm verschiedene Werte aufweist, dann könnte es in der hierarchischen Topologie (Ls + 1) * (Ldc + 1) * (Lm + 1) Dimensionskombinationen geben.
In der Regel sind jedoch nicht alle Dimensionskombinationen gültig, was die Komplexität erheblich reduzieren kann. Wenn Benutzer die Metrik selbst aggregieren, wird die Anzahl der Dimensionen derzeit nicht beschränkt. Wenn Sie die von Metrics Advisor bereitgestellte Rollup-Funktion verwenden müssen, sollten nicht mehr als sechs Dimensionen vorhanden sein. Allerdings wird die Anzahl der von Dimensionen für eine Metrik erweiterten Zeitreihen auf weniger als 10.000 beschränkt.
Das Tool Diagnosestruktur auf der Diagnoseseite zeigt nur Knoten an, bei denen eine Anomalie erkannt wurde, und nicht die gesamte Topologie. Dies soll Ihnen helfen, das Augenmerk auf das aktuelle Problem zu richten. Außerdem werden möglicherweise nicht alle Anomalien innerhalb der Metrik angezeigt. Stattdessen werden die obersten Anomalien auf der Grundlage des Beitrags angezeigt. So lassen sich die Auswirkungen, der Umfang und der Verbreitungsweg der anormalen Daten schnell herausfinden. Dadurch wird die Anzahl der zu untersuchenden Anomalien erheblich verringert und Benutzern geholfen, ihre zentralen Probleme zu erkennen und zu finden.
Wenn beispielsweise eine Anomalie bei Service = S2 | Data Center = DC2 | Machine = M5 auftritt, wirkt sich die Abweichung der Anomalie auf den übergeordneten Knoten Service= S2 aus, der die Anomalie ebenfalls erkannt hat. Die Anomalie wirkt sich jedoch nicht auf das gesamte Rechenzentrum bei DC2 und alle Dienste bei M5 aus. Die Incidentstruktur wäre wie im unteren Screenshot aufgebaut, die oberste Anomalie ist bei Service = S2 erfasst, und die Ursache könnte über zwei Pfade analysiert werden, die beide zu Service = S2 | Data Center = DC2 | Machine = M5 führen.
