Benutzerdefinierte Document Intelligence-Modelle
Dieser Inhalt gilt für: ![]() Version 4.0 (GA) | Vorherige Versionen:
Version 4.0 (GA) | Vorherige Versionen: ![]() Version 3.1 (GA)
Version 3.1 (GA) ![]() Version 3.0 (GA)
Version 3.0 (GA) ![]() Version 2.1 (GA)
Version 2.1 (GA)
::: moniker-end
Dieser Inhalt gilt für: ![]() Version 3.1 (GA) | Aktuelle Version:
Version 3.1 (GA) | Aktuelle Version: ![]() Version 4.0 (GA) | Vorherige Versionen:
Version 4.0 (GA) | Vorherige Versionen: ![]() Version 3.0
Version 3.0 ![]() Version 2.1
Version 2.1
Dieser Inhalt gilt für: ![]() Version 3.0 (GA) | Aktuelle Versionen:
Version 3.0 (GA) | Aktuelle Versionen: ![]() Version 4.0 (GA)
Version 4.0 (GA) ![]() Version 3.1 | Vorherige Version:
Version 3.1 | Vorherige Version: ![]() Version 2.1
Version 2.1
Dieser Inhalt gilt für: ![]() Version 2.1 | Neueste Version:
Version 2.1 | Neueste Version: ![]() Version 4.0 (GA)
Version 4.0 (GA)
Document Intelligence verwendet fortschrittliche Technologien zum maschinellen Lernen, um Dokumente zu identifizieren, Informationen in Formularen und Dokumenten zu erkennen, zu extrahieren und sie in Form einer strukturierten JSON-Ausgabe zurückzugeben. Mit Document Intelligence können Sie Dokumentanalysemodelle verwenden, die bereits erstellt/vortrainiert wurden, oder Ihre trainierten, eigenständigen, benutzerdefinierten Modelle nutzen.
Benutzerdefinierte Modelle enthalten jetzt benutzerdefinierte Klassifizierungsmodelle für Szenarien, in denen Sie den Dokumententyp vor dem Aufruf des Extraktionsmodells identifizieren müssen. Klassifizierungsmodelle sind ab der 2023-07-31 (GA)-API verfügbar. Ein Klassifizierungsmodell kann mit einem benutzerdefinierten Extraktionsmodell gepaart werden, um Felder aus Formularen und Dokumenten zu analysieren und zu extrahieren, die für Ihr Unternehmen spezifisch sind. Eigenständige benutzerdefinierte Extraktionsmodelle können kombiniert werden, um zusammengestellte Modelle zu erstellen.
Benutzerdefinierte Dokumentmodelltypen
Es gibt zwei Arten von benutzerdefinierten Dokumentmodellen: Benutzerdefinierte Vorlagenmodelle (auch benutzerdefinierte Formmodelle genannt) und benutzerdefinierte neuronale Modelle (auch als benutzerdefinierte Dokumentmodelle bekannt). Der Beschriftungs- und Trainingsprozess für beide Modelle ist identisch, aber die Modelle unterscheiden sich wie folgt:
Benutzerdefinierte Extraktionsmodelle
Um ein benutzerdefiniertes Extraktionsmodell zu erstellen, beschriften Sie ein Dataset von Dokumenten mit den Werten, die Sie extrahieren möchten, und trainieren das Modell für das beschriftete Dataset. Zunächst benötigen Sie lediglich fünf Beispiele desselben Formular- oder Dokumenttyps.
Benutzerdefiniertes neuronales Modell
Wichtig
Die Document Intelligence v4.0 2024-11-30 (GA)-API unterstützt benutzerdefinierte überlappende Felder für das neuronale Modell, Signaturerkennung und Konfidenz auf Tabellen-, Zeilen- und Zellebene.
Das benutzerdefinierte neuronale Modell (benutzerdefiniertes Dokumentmodell) verwendet Deep Learning-Modelle sowie ein Basismodell, das mit einer großen Sammlung von Dokumenten trainiert wurde. Dieses Modell wird dann optimiert oder an Ihre Daten angepasst, wenn Sie das Modell mit einem beschrifteten Dataset trainieren. Benutzerdefinierte neuronale Modelle unterstützen die Extraktion von Schlüsseldatenfeldern von strukturierten, halbstrukturierten und unstrukturierten Dokumente. Wenn Sie sich zwischen den beiden Modelltypen entscheiden müssen, sollten Sie sich für ein neuronales Modell entscheiden, um zu bestimmen, ob es Ihren funktionalen Anforderungen entspricht. Weitere Informationen zu benutzerdefinierten Dokumentmodellen finden Sie unter Neuronale Modelle.
Benutzerdefiniertes Vorlagenmodell
Das benutzerdefinierte Vorlagenmodell (auch: das benutzerdefinierte Formularmodell) basiert auf einer konsistenten visuellen Vorlage, mit der die beschrifteten Daten extrahiert werden. Abweichungen in der visuellen Struktur Ihrer Dokumente beeinflussen die Genauigkeit Ihres Modells. Formulare mit fester Struktur (z. B. Fragebögen oder Bewerbungen) sind Beispiele für einheitliche visuelle Vorlagen.
Ihr Trainingssatz besteht aus klar strukturierten Dokumenten, bei denen die Formatierung und das Layout bei jedem einzelnen Dokument gleich sind. Benutzerdefinierte Vorlagenmodelle unterstützen Schlüssel-Wert-Paare, Auswahlmarkierungen, Tabellen, Signaturfelder und Bereiche. Vorlagenmodelle können mit Dokumenten in jeder der unterstützten Sprachen trainiert werden. Weitere Informationen finden Sie unter Benutzerdefinierte Vorlagenmodelle.
Wenn die Sprache Ihrer Dokumente und die Extraktionsszenarien benutzerdefinierte neuronale Modelle unterstützen, sollten Sie benutzerdefinierte neuronale Modelle anstelle von Vorlagenmodellen verwenden, um eine höhere Genauigkeit zu erzielen.
Tipp
Um sicherzustellen, dass Ihre Trainingsdokumente eine konsistente visuelle Vorlage bilden, entfernen Sie alle vom Benutzer eingegebenen Daten aus den einzelnen Formularen in der Gruppe. Wenn das Erscheinungsbild der leeren Formulare identisch ist, stellen sie eine konsistente visuelle Vorlage dar.
Weitere Informationen finden Sie unter Interpretieren und Verbessern von Genauigkeit und Konfidenz in benutzerdefinierten Modellen.
Eingabeanforderungen
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
Unterstützte Dateiformate:
Modell PDF Abbildung: jpeg/jpg,png,bmp,tiff,heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Lesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ ✱ Microsoft Office-Dateien werden derzeit für andere Modelle oder Versionen nicht unterstützt.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für die kostenpflichtige (S0) und 4 MB für die kostenlose (F0) Stufe.
Die Bildgrößen müssen im Bereich zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkt-Text bei 150 Punkten pro Zoll.Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training des benutzerdefinierten Extraktionsmodells beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und 1G-MB für das neuronale Modell.
Für das Training des benutzerdefinierten Klassifizierungsmodells beträgt die Gesamtgröße der Trainingsdaten
1GBmit einem Maximum von 10 000 Seiten.
Optimale Trainingsdaten
Trainingseingabedaten bilden die Grundlage für jedes Machine Learning-Modell. Sie bestimmen die Qualität, Genauigkeit und Leistung des Modells. Daher ist es wichtig, die bestmöglichen Trainingseingabedaten für Ihr Dokument Intelligenz-Projekt zu erstellen. Wenn Sie das benutzerdefinierte Modell von Dokument Intelligenz verwenden, stellen Sie Ihre eigenen Trainingsdaten zur Verfügung. Im Folgenden finden Sie einige Tipps zum effektiven Trainieren Ihrer Modelle:
Verwenden Sie nach Möglichkeit textbasierte anstelle von bildbasierten PDF-Dateien. Eine Möglichkeit, eine bildbasierte PDF-Datei zu identifizieren, besteht darin, bestimmten Text im Dokument auszuwählen. Wenn Sie nur das gesamte Bild des Texts auswählen können, ist das Dokument bildbasiert und nicht textbasiert.
Strukturieren Sie Ihre Trainingsdokumente mithilfe eines Unterordners für jedes Format (JPEG/JPG, PNG, BMP, PDF oder TIFF).
Verwenden Sie Formulare, in denen alle verfügbaren Felder ausgefüllt sind.
Verwenden Sie Formulare mit verschiedenen Werten in allen Feldern.
Wenn Ihre Bilder eine niedrige Qualität aufweisen, verwenden Sie ein größeres Dataset (mehr als fünf Trainingsdokumente).
Bestimmen Sie, ob Sie ein einzelnes Modell oder mehrere Modelle verwenden müssen, die aus einem einzelnen Modell bestehen.
Ziehen Sie die Segmentierung Ihres Datasets in Ordner in Erwägung, wobei jeder Ordner eine eindeutige Vorlage ist. Trainieren Sie ein Modell pro Ordner, und stellen Sie die resultierenden Modelle zu einem einzelnen Endpunkt zusammen. Die Modellgenauigkeit kann abnehmen, wenn Sie verschiedene Formate mit einem einzelnen Modell analysieren.
Wenn Ihr Formular Variationen mit Formaten und Seitenumbrüchen aufweist, sollten Sie das Dataset segmentieren, um mehrere Modelle zu trainieren. Benutzerdefinierte Formulare basieren auf einer konsistenten visuellen Vorlage.
Stellen Sie sicher, dass Sie über ein ausgewogenes Dataset verfügen, indem Sie Formate, Dokumenttypen und Struktur berücksichtigen.
Buildmodus
Der build custom model-Vorgang unterstützt nun die benutzerdefinierten Vorlagenmodelle und die benutzerdefinierten neuronalen Modelle. Frühere Versionen der REST-API und der SDKs unterstützten nur einen einzigen Buildmodus, der nun als Vorlagenmodus bezeichnet wird.
Vorlagenmodelle funktionieren nur mit Dokumenten, deren Seiten dieselbe Grundstruktur aufweisen (ein einheitliches Erscheinungsbild) oder die gleiche relative Positionierung von Elementen innerhalb des Dokuments haben.
Neuronale Modelle unterstützen Dokumente, die dieselben Informationen, aber unterschiedliche Seitenstrukturen enthalten. Zu diesen Dokumenten gehören beispielsweise die in den Vereinigten Staaten verwendeten W2-Steuerformulare. Sie enthalten die gleichen Informationen, können aber je nach Unternehmen unterschiedlich aussehen.
In dieser Tabelle finden Sie Links zu den SDK-Referenzen und Codebeispielen für die Buildmodus-Programmiersprache auf GitHub:
| Programmiersprache | SDK-Referenz | Codebeispiel |
|---|---|---|
| C#/.NET | DocumentBuildMode-Struktur | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode-Klasse | BuildModel.java |
| JavaScript | DocumentBuildMode-Typ | buildModel.js |
| Python | DocumentBuildMode-Enumeration | sample_build_model.py |
Vergleichen von Modellfunktionen
In der folgenden Tabelle werden die benutzerdefinierte Vorlage und die benutzerdefinierten neuronalen Features verglichen:
| Funktion | Benutzerdefinierte Vorlage (Formular) | Benutzerdefiniert neuronal (Dokument) |
|---|---|---|
| Dokumentstruktur | Vorlage, Formular und strukturiert | Strukturiert, halbstrukturiert und unstrukturiert |
| Trainingsdauer | 1 bis 5 Minuten | 20 Minuten bis 1 Stunde |
| Extrahieren von Daten | Schlüssel-Wert-Paare, Tabellen, Auswahlmarkierungen, Koordinaten und Signaturen | Schlüssel-Wert-Paare, Auswahlmarkierungen und Tabellen |
| Überlappende Felder | Nicht unterstützt | Unterstützt |
| Dokumentvarianten | Erfordert ein Modell pro Variante | Verwendet ein einzelnes Modell für alle Varianten |
| Sprachunterstützung | Benutzerdefinierte Vorlage für die Sprachunterstützung | Sprachunterstützung: benutzerdefiniert neuronal |
Benutzerdefiniertes Klassifizierungsmodell
Die Klassifizierung von Dokumenten ist ein neues Szenario, das von Document Intelligence über die 2023-07-31-API (v3.1 GA) unterstützt wird. Die Dokumentenklassifizierer-API unterstützt Klassifizierungs- und Aufteilungsszenarien. Trainieren Sie ein Klassifizierungsmodell, um die verschiedenen Arten von Dokumenten zu identifizieren, die Ihre Anwendung unterstützt. Die Eingabedatei für das Klassifizierungsmodell kann mehrere Dokumente enthalten und klassifiziert jedes Dokument innerhalb eines zugeordneten Seitenbereichs. Weitere Informationen finden Sie unter Benutzerdefinierte Klassifizierungsmodelle.
Hinweis
Das v4.0 2024-11-30 (GA)-Dokumentklassifizierungsmodell unterstützt Office-Dokumenttypen für die Klassifizierung. Diese API-Version führt auch eine inkrementelle Schulung für das Klassifizierungsmodell ein.
Tools für benutzerdefinierte Modelle
Document Intelligence v3.1 und höher unterstützen die folgenden Tools, Anwendungen und Bibliotheken, Programme und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Benutzerdefiniertes Modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
Lebenszyklus des benutzerdefinierten Modells
Der Lebenszyklus eines benutzerdefinierten Modells hängt von der API-Version ab, die zum Trainieren verwendet wird. Falls die API-Version eine allgemein verfügbare (GA) Version ist, hat das benutzerdefinierte Modell den gleichen Lebenszyklus wie diese Version. Wenn die API-Version veraltet ist, steht das benutzerdefinierte Modell nicht mehr für Rückschlüsse zur Verfügung. Falls die API-Version eine Vorschauversion ist, hat das benutzerdefinierte Modell den gleichen Lebenszyklus wie die Vorschauversion der API.
Document Intelligence v2.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
Hinweis
Die benutzerdefinierten Modelltypen Benutzerdefiniert neuronal und Benutzerdefinierte Vorlage sind mit den Document Intelligence-APIs Version 3.1 und 3.0 verfügbar.
| Feature | Ressourcen |
|---|---|
| Benutzerdefiniertes Modell | • Document Intelligence-Bezeichnungstool • REST-API • Clientbibliothek SDK • Document Intelligence-Docker-Container |
Erstellen eines benutzerdefinierten Modells
Extrahieren Sie Daten aus Ihren spezifischen oder individuellen Dokumenten mithilfe benutzerdefinierter Modelle. Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.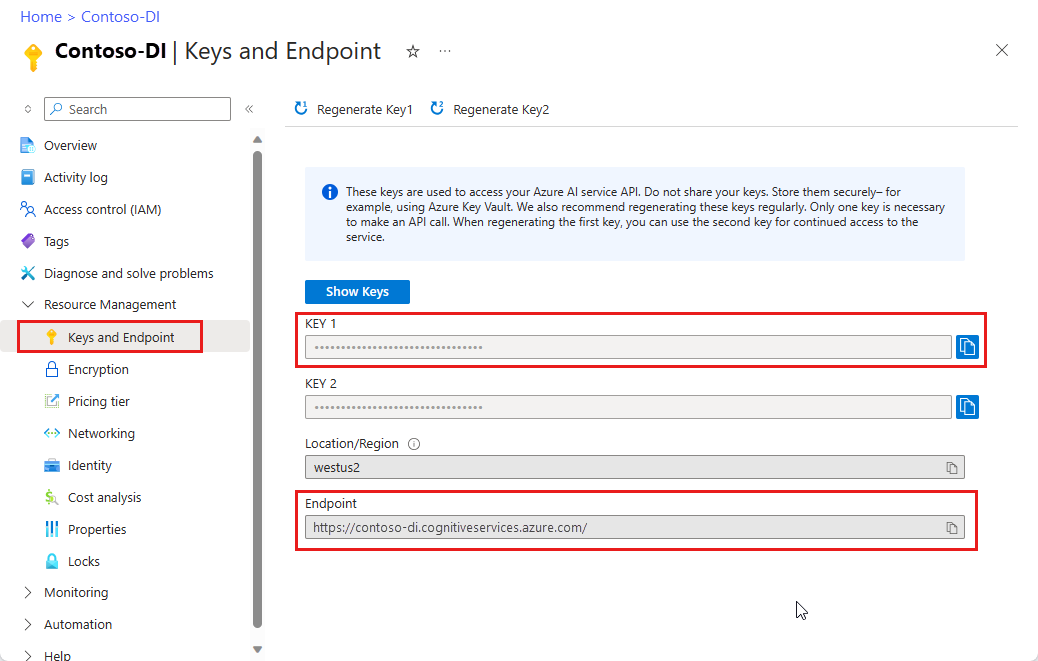
Tool für die Beschriftung von Beispielen
Tipp
- Testen Sie das Dokument Intelligenz v3.0-Studio, um eine verbesserte Erfahrung und eine höhere Modellqualität zu erhalten.
- v3.0 Studio unterstützt jedes Modell, das mit in v2.1 gekennzeichneten Daten trainiert wurde.
- Ausführliche Informationen zum Migrieren von v2.1 zu v3.0 finden Sie im API-Migrationshandbuch.
- Sehen Sie sich unsere SDK-Schnellstarts zur REST-API oder zu C#, Java, JavaScript oder Python an, um mit der Version v3.0 zu beginnen.
Das Stichprobenbeschriftungstool von Document Intelligence ist ein Open-Source-Tool, mit dem Sie die neuesten Features von Document Intelligence und OCR (optische Zeichenerkennung) testen können.
Probieren Sie den Schnellstart zum Beispielbezeichnungstool aus, um mit der Erstellung und Verwendung eines benutzerdefinierten Modells zu beginnen.
Dokument Intelligenz Studio
Hinweis
Document Intelligence Studio ist mit den APIs der Version 3.1 und 3.0 verfügbar.
Wählen Sie auf der Startseite von Document Intelligence Studio die Option Benutzerdefinierte Extraktionsmodelle aus.
Wählen Sie unter Meine Projekte die Option + Projekt erstellen aus.
Füllen Sie die Felder mit den Projektdetails aus.
Fügen Sie Speicherkonto und Blobcontainer hinzu, um eine Verbindung mit Ihrer Trainingsdatenquelle herzustellen.
Überprüfen und erstellen Sie Ihr Projekt.
Fügen Sie Ihre Beispieldokumente hinzu, um Ihr benutzerdefiniertes Modell zu beschriften, zu erstellen und zu testen.
Eine ausführliche Anleitung zum Erstellen Ihres ersten benutzerdefinierten Extraktionsmodells finden Sie unter Erstellen eines benutzerdefinierten Extraktionsmodells.
Zusammenfassung der benutzerdefinierten Modellextraktion
In dieser Tabelle werden die unterstützten Datenextraktionsbereiche verglichen:
| Modell | Formularfelder | Auswahlmarkierungen | Strukturierte Felder (Tabellen) | Signatur | Beschriften von Bereichen | Überlappende Felder |
|---|---|---|---|---|---|---|
| Benutzerdefiniertes Vorlagenmodell | ✔ | ✔ | ✔ | ✔ | ✔ | Nicht zutreffend |
| Benutzerdefiniertes neuronales Modell | ✔ | ✔ | ✔ | ✔ | * | ✔ |
Tabellensymbole:
✔ = unterstützt
**n/a—Derzeit nicht verfügbar;
*-Verhält sich je nach Modell unterschiedlich. Bei Vorlagenmodellen werden zum Zeitpunkt des Trainings synthetische Daten generiert. Bei neuronalen Modellen wird der in der Region erkannte Text ausgewählt.
Tipp
Wenn Sie zwischen den beiden Modelltypen wählen, beginnen Sie mit einem benutzerdefinierten neuronalen Modell, wenn es Ihre funktionalen Anforderungen erfüllt. Weitere Informationen zu benutzerdefinierten neuronalen Modellen finden Sie unter Benutzerdefinierte neuronale Modelle.
Entwicklungsoptionen für benutzerdefinierte Modelle
In der folgenden Tabelle werden die Funktionen beschrieben, die mit den zugehörigen Tools und Client-Bibliotheken verfügbar sind. Stellen Sie als bewährte Methode sicher, dass Sie die hier aufgeführten kompatiblen Tools verwenden.
| Dokumenttyp | REST-API | SDK | Beschriften und Testen von Modellen |
|---|---|---|---|
| Benutzerdefinierte Vorlage v 4.0 v3.1 v3.0 | Dokument Intelligenz 3.1 | Document Intelligence SDK | Dokument Intelligenz Studio |
| Benutzerdefiniertes neuronales Modell v4.0 v3.1 v3.0 | Dokument Intelligenz 3.1 | Document Intelligence SDK | Dokument Intelligenz Studio |
| Benutzerdefiniertes Formular 2.1 | Document Intelligence-API 2.1 GA | Dokument Intelligenz-SDK | Tool für die Beschriftung von Beispielen |
Hinweis
Benutzerdefinierte Vorlagenmodelle, die mit der 3.0-API trainiert wurden, bieten einige Verbesserungen gegenüber der 2.1-API aufgrund von Verbesserungen an der OCR-Engine. Datasets, die zum Trainieren eines benutzerdefinierten Vorlagenmodells mithilfe der 2.1-API verwendet werden, können weiterhin verwendet werden, um ein neues Modell mithilfe der 3.0-API zu trainieren.
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
Unterstützte Dateiformate: JPEG/JPG, PNG, BMP, TIFF und PDF (in Text eingebettet oder gescannt). In Text eingebettete PDF-Dateien sind am besten geeignet, um die Möglichkeit von Fehlern beim Extrahieren und Auffinden von Zeichen auszuschließen.
Für PDF- und TIFF-Dateien können bis zu 2.000 Seiten verarbeitet werden. Bei Abonnements im Free-Tarif werden nur die ersten beiden Seiten verarbeitet.
Die Datei muss im kostenpflichtigen Tarif (S0) kleiner als 500 MB und im kostenlosen Tarif (F0) kleiner als 4 MB sein.
Bei Bildern müssen die Abmessungen zwischen 50 × 50 Pixel und 10,000 × 10,000 Pixel liegen.
Die PDF-Abmessungen sind bis zu 17 × 17 Zoll, sodass die Papierformate Legal oder A3 hineinpassen, oder kleiner.
Der Gesamtumfang der Trainingsdaten beträgt 500 Seiten oder weniger.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Tipp
Trainingsdaten:
- Verwenden Sie nach Möglichkeit textbasierte PDF-Dokumente anstelle von bildbasierten Dokumenten. Gescannte PDF-Dateien werden als Bilder behandelt.
- Geben Sie nur eine einzelne Instanz des Formulars pro Dokument an.
- Für ausgefüllte Formulare sollten Sie Beispiele verwenden, bei denen alle Felder ausgefüllt sind.
- Verwenden Sie Formulare mit verschiedenen Werten in jedem Feld.
- Wenn Ihre Formularbilder von niedrigerer Qualität sind, verwenden Sie ein größeres Dataset. Verwenden Sie beispielsweise 10 bis 15 Bilder.
Unterstützte Sprachen und Regionen
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Benutzerdefinierte Modelle.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe des Dokument Intelligenz-Stichproben-Bezeichnungstools zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.