Lesemodell für Document Intelligence
Dieser Inhalt gilt für:![]() Version 4.0 (GA) | Vorherige Versionen:
Version 4.0 (GA) | Vorherige Versionen:![]() Version 3.1 (GA)
Version 3.1 (GA)![]() Version 3.0 (GA)
Version 3.0 (GA)
Hinweis
Verwenden Sie zum Extrahieren von Text aus externen Bildern wie Beschriftungen, Straßenschildern und Postern das Lesefeature von Image Azure KI Analysis v4.0, das für allgemeine Bilder (keine Dokumente) optimiert ist und das über eine leistungsstärkere synchrone API verfügt. Diese Funktion vereinfacht das Einbetten von OCR in Szenarien mit Echtzeit-Benutzererlebnissen.
Das Dokument Intelligenz-Lesemodell für die optische Zeichenerkennung (Optical Character Recognition, OCR) wird mit einer höheren Auflösung ausgeführt als bei Azure KI Vision-Lesevorgängen, und es extrahiert gedruckten und handschriftlichen Text aus PDF-Dokumenten und gescannten Bildern. Es unterstützt das Extrahieren von Text aus Microsoft Word-, Excel-, PowerPoint- und HTML-Dokumenten. Es erkennt Absätze, Textzeilen, Wörter, Orte und Sprachen. Das Lesemodell ist die zugrunde liegende OCR-Engine für andere vordefinierten Dokument Intelligenz-Modelle wie Layouts, allgemeine Dokumente, Rechnungen, Belege, Identitätsdokumente (ID), Krankenversicherungskarten und W2-Formulare (zusätzlich zu benutzerdefinierten Modellen).
Was ist optische Zeichenerkennung?
Die optische Zeichenerkennung (Optical Character Recognition, OCR) für Dokumente ist für große, textintensive Dokumente in mehreren Dateiformaten und globalen Sprachen optimiert. Es umfasst Funktionen wie das Scannen von Dokumentbildern mit höherer Auflösung für eine bessere Behandlung von kleinerem und dichtem Text, die Erkennung von Absätzen und die Verwaltung von ausfüllbaren Formularen. OCR-Funktionen umfassen auch erweiterte Szenarien wie Einzelzeichenfelder und die genaue Extraktion von Schlüsselfeldern, die häufig in Rechnungen, Belegen und anderen vordefinierten Szenarien vorkommen.
Entwicklungsoptionen (v4)
Dokument Intelligenz Version 4.0: 2024-11-30 (GA) unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Funktion | Ressourcen | Modell-ID |
|---|---|---|
| Lese-OCR-Modell | • Document Intelligence Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Eingabeanforderungen (v4)
Unterstützte Dateiformate:
| Modell | Abbildung: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lesen Sie | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Allgemeines Dokument | ✔ | ✔ | |
| Vordefiniert | ✔ | ✔ | |
| Benutzerdefinierte Extraktion | ✔ | ✔ | |
| Benutzerdefinierte Klassifizierung | ✔ | ✔ | ✔ |
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-11-30 (GA) beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Erste Schritte mit dem Lesemodell (v4)
Versuchen Sie, Text mithilfe von Dokument Intelligenz Studio aus Formularen und Dokumenten zu extrahieren. Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement (Sie können ein kostenloses Abonnement erstellen).
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.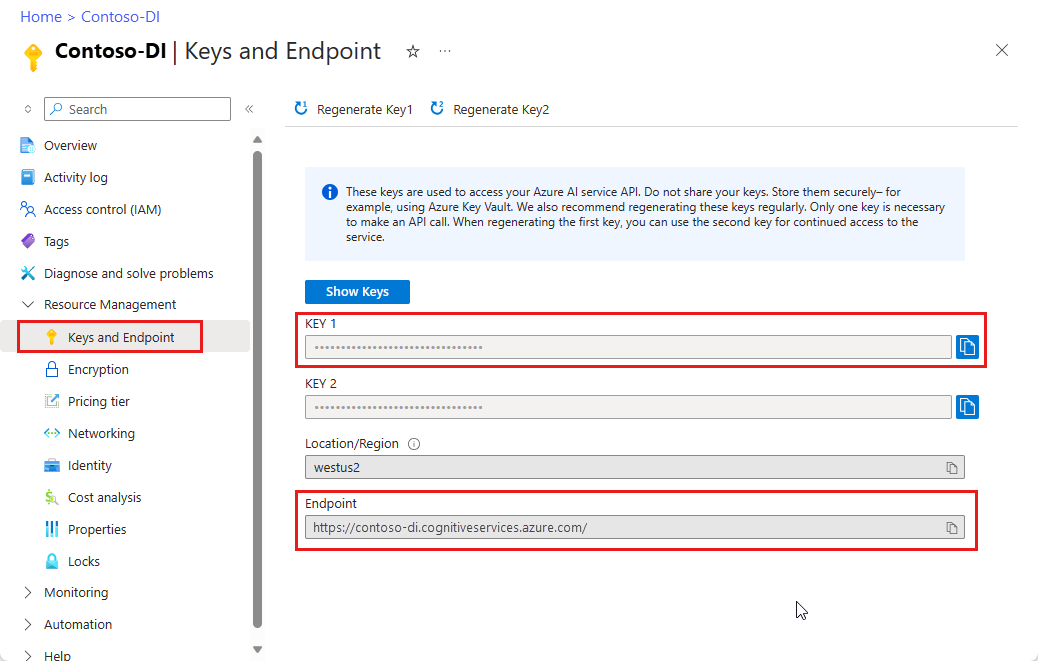
Hinweis
Derzeit bietet Dokument Intelligenz Studio keine Unterstützung für die Microsoft Word-, Excel-, PowerPoint- und HTML-Dateiformate.
Beispieldokument, das mit Dokument Intelligenz Studio verarbeitet wurde
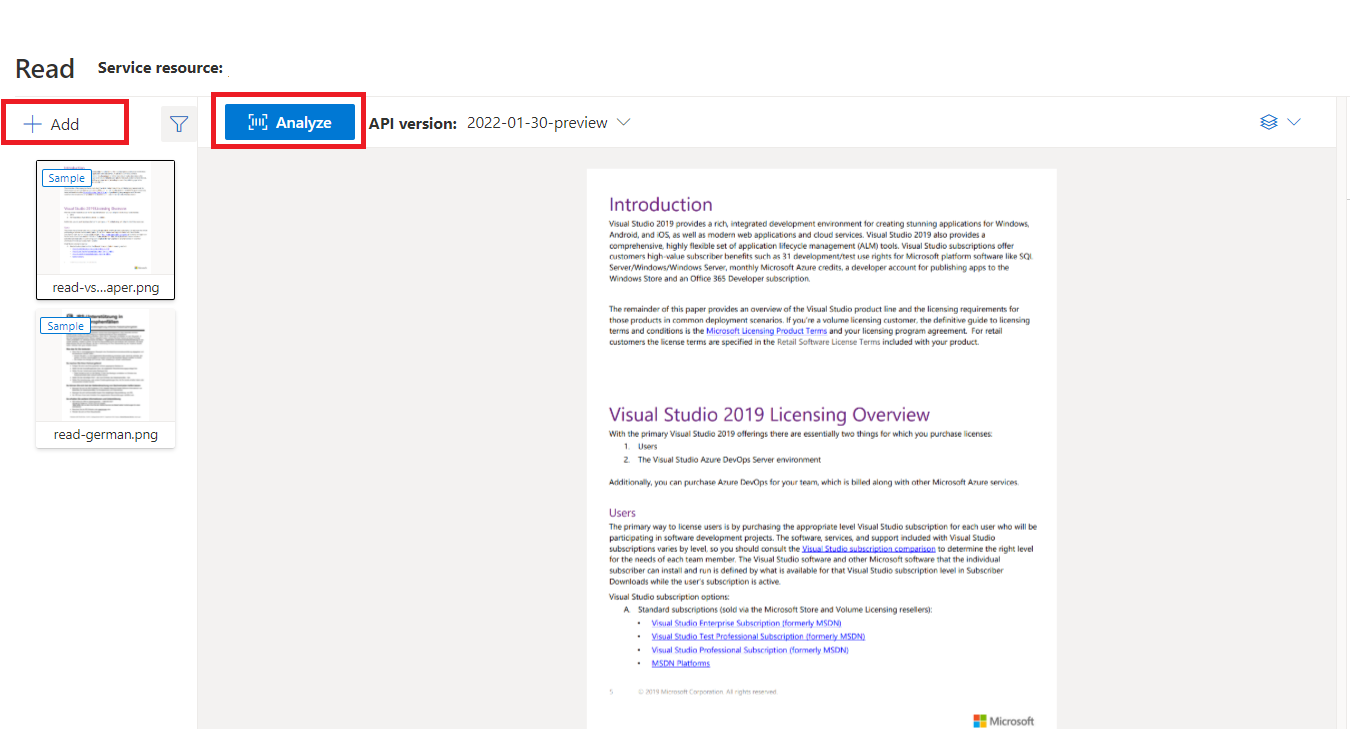
Wählen Sie auf der Startseite von Document Intelligence StudioLesen aus.
Sie können das Musterdokument analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:

Unterstützte Sprachen und Gebietsschemas (v4)
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Dokumentanalysemodelle.
Datenextraktion (v4)
Hinweis
Microsoft Word- und HTML-Datei werden in Version 4.0 unterstützt. Die folgenden Funktionen werden derzeit nicht unterstützt:
- Für die einzelnen Seitenobjekte werden keine Angaben für Winkel, Breite/Höhe und Einheit zurückgegeben.
- Für die einzelnen Objekte wurden weder Begrenzungspolygon noch Begrenzungsbereich erkannt.
- Es wurde kein Seitenbereich (
pages) als Parameter zurückgegeben. - Es gibt kein
lines-Objekt.
Durchsuchbare PDF
Mit der durchsuchbaren PDF-Funktion können Sie eine analoge PDF-Datei, wie eine gescannte PDF-Datei, in eine PDF-Datei mit eingebettetem Text konvertieren. Der eingebettete Text ermöglicht die Deep-Text-Suche innerhalb des extrahierten PDF-Inhalts, indem die erkannten Textentitäten über die Bilddateien überlagert werden.
Wichtig
- Derzeit unterstützt nur das OCR-Lesemodell
prebuilt-readdie Funktion für durchsuchbare PDF-Dateien. Wenn Sie dieses Feature verwenden, geben Sie diemodelIdalsprebuilt-readan. Andere Modelltypen geben für diese Vorschauversion einen Fehler zurück. - Die Funktion für durchsuchbare PDF-Dateien ist im
prebuilt-read-Modell Version2024-11-30GA ohne zusätzliche Kosten zum Generieren einer durchsuchbaren PDF-Ausgabe enthalten.
Verwenden durchsuchbarer PDFs
Um durchsuchbare PDF-Dateien zu verwenden, stellen Sie eine POST-Anforderung mithilfe des Analyze-Vorgangs, und legen Sie das Ausgabeformat auf pdf fest:
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
Abstimmung für den Abschluss des Analyze-Vorgangs. Sobald der Vorgang abgeschlossen ist, stellen Sie eine GET-Anforderung zum Abrufen des PDF-Formats der Analyze-Vorgangsergebnisse.
Nach erfolgreichem Abschluss kann die PDF abgerufen und als application/pdf heruntergeladen werden. Dieser Vorgang ermöglicht das direkte Herunterladen der eingebetteten Textform der PDF anstelle von Base64-codiertem JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
Pages-Parameter
Die Seitensammlung ist eine Liste von Seiten innerhalb des Dokuments. Jede Seite wird innerhalb des Dokuments sequenziell dargestellt und enthält den Ausrichtungswinkel, der angibt, ob die Seite gedreht wurde, sowie die Breite und Höhe (Abmessungen in Pixel). Die Seiteneinheiten in der Modellausgabe werden wie gezeigt berechnet:
| Dateiformat | Berechnete Seiteneinheit | Seiten gesamt |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Jedes Bild = 1 Seiteneinheit | Gesamtzahl der Bilder |
| Jede Seite in der PDF = 1 Seiteneinheit | Gesamtseitenzahl in der PDF | |
| TIFF | Jedes TIFF-Bild = 1 Seiteneinheit | Gesamtanzahl der Bilder im TIFF-Dokument |
| Word (DOCX) | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
| Excel (XLSX) | Jedes Arbeitsblatt = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Arbeitsblätter insgesamt |
| PowerPoint (PPTX) | Jede Folie = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Folien insgesamt |
| HTML | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Verwenden von „pages“ für die Textextraktion
Verwenden Sie für umfangreiche PDF-Dokumente mit mehreren Seiten den Abfrageparameter pages, um bestimmte Seitenzahlen oder Seitenbereiche für die Textextraktion anzugeben.
Absatzextraktion
Das OCR-Lesemodell in Dokument Intelligenz extrahiert alle identifizierten Textblöcke in der paragraphs-Sammlung als Objekt der obersten Ebene unter analyzeResults. Jeder Eintrag in dieser Auflistung stellt einen Textblock dar und enthält den extrahierten Text als content sowie die Koordinaten des Begrenzungs-polygon. Die span-Informationen zeigen auf das Textfragment innerhalb der content-Eigenschaft der obersten Ebene, die den vollständigen Text aus dem Dokument enthält.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Text, Zeilen- und Wortextraktion
Das OCR-Lesemodell extrahiert gedruckten und handschriftlichen Text als lines und words. Das Modell gibt Koordinaten für das Begrenzungs-polygon und confidence für die extrahierten Wörter aus. Die styles-Auflistung enthält alle handschriftlichen Formatvorlagen für Zeilen (sofern erkannt) sowie die Spannen, die auf den zugeordneten Text zeigen. Dieses Feature gilt für unterstützte handschriftliche Sprachen.
Für Microsoft Word, Excel, PowerPoint und HTML extrahiert das Lesemodell Version 3.1 und später den gesamten eingebetteten Text unverändert. Texte werden als Wörter und Absätze extrahiert. Eingebettete Bilder werden nicht unterstützt.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Extraktion handschriftlicher Stile
Die Antwort umfasst die Klassifizierung, ob es sich bei den einzelnen Textzeilen um einen handschriftlichen Stil handelt, sowie eine Konfidenzbewertung. Weitere Informationen finden Sie unterSprachunterstützung für Handschriften. Das folgende Beispiel zeigt einen beispielhaften JSON-Ausschnitt.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Wenn Sie die Add-On-Funktion für Schriftart/Schriftschnitt aktiviert haben, erhalten Sie als Teil des styles-Objekts auch das Ergebnis für die Schriftart und den Schriftschnitt.
Nächste Schritte v4.0
Schnellstart für Dokument Intelligenz:
Erkunden Sie unsere REST-API:
Weitere Beispiele finden Sie auf GitHub:
Dieser Inhalt gilt für:![]() Version 3.1 (GA) | Aktuelle Version:
Version 3.1 (GA) | Aktuelle Version:![]() Version 4.0 (GA) | Vorherige Versionen:
Version 4.0 (GA) | Vorherige Versionen:![]() Version 3.0
Version 3.0
Dieser Inhalt gilt für:![]() Version 3.0 (GA) | Aktuelle Versionen:
Version 3.0 (GA) | Aktuelle Versionen:![]() Version 4.0 (GA)
Version 4.0 (GA)![]() Version 3.1
Version 3.1
Hinweis
Verwenden Sie zum Extrahieren von Text aus externen Bildern wie Beschriftungen, Straßenschildern und Postern das Lesefeature von Image Azure KI Analysis v4.0, das für allgemeine Bilder (keine Dokumente) optimiert ist und das über eine leistungsstärkere synchrone API verfügt. Diese Funktion vereinfacht das Einbetten von OCR in Szenarien mit Echtzeit-Benutzererlebnissen.
Das Dokument Intelligenz-Lesemodell für die optische Zeichenerkennung (Optical Character Recognition, OCR) wird mit einer höheren Auflösung ausgeführt als bei Azure KI Vision-Lesevorgängen, und es extrahiert gedruckten und handschriftlichen Text aus PDF-Dokumenten und gescannten Bildern. Es unterstützt das Extrahieren von Text aus Microsoft Word-, Excel-, PowerPoint- und HTML-Dokumenten. Es erkennt Absätze, Textzeilen, Wörter, Orte und Sprachen. Das Lesemodell ist die zugrunde liegende OCR-Engine für andere vordefinierten Dokument Intelligenz-Modelle wie Layouts, allgemeine Dokumente, Rechnungen, Belege, Identitätsdokumente (ID), Krankenversicherungskarten und W2-Formulare (zusätzlich zu benutzerdefinierten Modellen).
Was ist OCR für Dokumente?
Die optische Zeichenerkennung (Optical Character Recognition, OCR) für Dokumente ist für große, textintensive Dokumente in mehreren Dateiformaten und globalen Sprachen optimiert. Es umfasst Funktionen wie das Scannen von Dokumentbildern mit höherer Auflösung für eine bessere Behandlung von kleinerem und dichtem Text, die Erkennung von Absätzen und die Verwaltung von ausfüllbaren Formularen. OCR-Funktionen umfassen auch erweiterte Szenarien wie Einzelzeichenfelder und die genaue Extraktion von Schlüsselfeldern, die häufig in Rechnungen, Belegen und anderen vordefinierten Szenarien vorkommen.
Entwicklungsoptionen
Document Intelligence v3.1 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Lese-OCR-Modell | • Document Intelligence Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Document Intelligence v3.0 unterstützt die folgenden Tools, Anwendungen und Bibliotheken:
| Feature | Ressourcen | Modell-ID |
|---|---|---|
| Lese-OCR-Modell | • Document Intelligence Studio • REST-API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Eingabeanforderungen
Unterstützte Dateiformate:
| Modell | Abbildung: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lesen Sie | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Allgemeines Dokument | ✔ | ✔ | |
| Vordefiniert | ✔ | ✔ | |
| Benutzerdefinierte Extraktion | ✔ | ✔ | |
| Benutzerdefinierte Klassifizierung | ✔ | ✔ | ✔ |
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-11-30 (GA) beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Erste Schritte mit dem Lesemodell
Versuchen Sie, Text mithilfe von Dokument Intelligenz Studio aus Formularen und Dokumenten zu extrahieren. Sie benötigen die folgenden Ressourcen:
Ein Azure-Abonnement (Sie können ein kostenloses Abonnement erstellen).
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.
Hinweis
Derzeit bietet Dokument Intelligenz Studio keine Unterstützung für die Microsoft Word-, Excel-, PowerPoint- und HTML-Dateiformate.
Beispieldokument, das mit Dokument Intelligenz Studio verarbeitet wurde
Wählen Sie auf der Startseite von Document Intelligence StudioLesen aus.
Sie können das Musterdokument analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:
Unterstützte Sprachen und Gebietsschemas
Eine vollständige Liste der unterstützten Sprachen finden Sie unter Sprachunterstützung – Dokumentanalysemodelle.
Extrahieren von Daten
Hinweis
Microsoft Word- und HTML-Datei werden in Version 4.0 unterstützt. Die folgenden Funktionen werden derzeit nicht unterstützt:
- Für die einzelnen Seitenobjekte werden keine Angaben für Winkel, Breite/Höhe und Einheit zurückgegeben.
- Für die einzelnen Objekte wurden weder Begrenzungspolygon noch Begrenzungsbereich erkannt.
- Es wurde kein Seitenbereich (
pages) als Parameter zurückgegeben. - Es gibt kein
lines-Objekt.
Durchsuchbare PDF
Mit der durchsuchbaren PDF-Funktion können Sie eine analoge PDF-Datei, wie eine gescannte PDF-Datei, in eine PDF-Datei mit eingebettetem Text konvertieren. Der eingebettete Text ermöglicht die Deep-Text-Suche innerhalb des extrahierten PDF-Inhalts, indem die erkannten Textentitäten über die Bilddateien überlagert werden.
Wichtig
- Derzeit unterstützt nur das OCR-Lesemodell
prebuilt-readdie Funktion für durchsuchbare PDF-Dateien. Wenn Sie dieses Feature verwenden, geben Sie diemodelIdalsprebuilt-readan. Andere Modelltypen geben einen Fehler zurück. - Die Funktion für durchsuchbare PDF-Dateien ist im
prebuilt-read-Modell Version2024-11-30ohne zusätzliche Kosten zum Generieren einer durchsuchbaren PDF-Ausgabe enthalten.- Die durchsuchbare PDF unterstützt derzeit nur PDF-Dateien als Eingabe.
Verwenden der durchsuchbaren PDF
Um durchsuchbare PDF-Dateien zu verwenden, stellen Sie eine POST-Anforderung mithilfe des Analyze-Vorgangs, und legen Sie das Ausgabeformat auf pdf fest:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Abstimmung für den Abschluss des Analyze-Vorgangs. Sobald der Vorgang abgeschlossen ist, stellen Sie eine GET-Anforderung zum Abrufen des PDF-Formats der Analyze-Vorgangsergebnisse.
Nach erfolgreichem Abschluss kann die PDF abgerufen und als application/pdf heruntergeladen werden. Dieser Vorgang ermöglicht das direkte Herunterladen der eingebetteten Textform der PDF anstelle von Base64-codiertem JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Seiten
Die Seitensammlung ist eine Liste von Seiten innerhalb des Dokuments. Jede Seite wird innerhalb des Dokuments sequenziell dargestellt und enthält den Ausrichtungswinkel, der angibt, ob die Seite gedreht wurde, sowie die Breite und Höhe (Abmessungen in Pixel). Die Seiteneinheiten in der Modellausgabe werden wie gezeigt berechnet:
| Dateiformat | Berechnete Seiteneinheit | Seiten gesamt |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Jedes Bild = 1 Seiteneinheit | Gesamtzahl der Bilder |
| Jede Seite in der PDF = 1 Seiteneinheit | Gesamtseitenzahl in der PDF | |
| TIFF | Jedes TIFF-Bild = 1 Seiteneinheit | Gesamtanzahl der Bilder im TIFF-Dokument |
| Word (DOCX) | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
| Excel (XLSX) | Jedes Arbeitsblatt = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Arbeitsblätter insgesamt |
| PowerPoint (PPTX) | Jede Folie = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder nicht unterstützt | Folien insgesamt |
| HTML | Bis zu 3.000 Zeichen = 1 Seiteneinheit, eingebettete oder verknüpfte Bilder werden nicht unterstützt | Gesamtzahl der Seiten von bis zu 3.000 Zeichen jeweils |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Auswählen der Seiten für die Textextraktion
Verwenden Sie für umfangreiche PDF-Dokumente mit mehreren Seiten den Abfrageparameter pages, um bestimmte Seitenzahlen oder Seitenbereiche für die Textextraktion anzugeben.
Absätze
Das OCR-Lesemodell in Dokument Intelligenz extrahiert alle identifizierten Textblöcke in der paragraphs-Sammlung als Objekt der obersten Ebene unter analyzeResults. Jeder Eintrag in dieser Auflistung stellt einen Textblock dar und enthält den extrahierten Text als content sowie die Koordinaten des Begrenzungs-polygon. Die span-Informationen zeigen auf das Textfragment innerhalb der content-Eigenschaft der obersten Ebene, die den vollständigen Text aus dem Dokument enthält.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Text, Zeilen und Wörter
Das OCR-Lesemodell extrahiert gedruckten und handschriftlichen Text als lines und words. Das Modell gibt Koordinaten für das Begrenzungs-polygon und confidence für die extrahierten Wörter aus. Die styles-Auflistung enthält alle handschriftlichen Formatvorlagen für Zeilen (sofern erkannt) sowie die Spannen, die auf den zugeordneten Text zeigen. Dieses Feature gilt für unterstützte handschriftliche Sprachen.
Für Microsoft Word, Excel, PowerPoint und HTML extrahiert das Lesemodell Version 3.1 und später den gesamten eingebetteten Text unverändert. Texte werden als Wörter und Absätze extrahiert. Eingebettete Bilder werden nicht unterstützt.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Handschriftlicher Text für Textzeilen
Die Antwort umfasst die Klassifizierung, ob es sich bei den einzelnen Textzeilen um einen handschriftlichen Stil handelt, sowie eine Konfidenzbewertung. Weitere Informationen finden Sie unterSprachunterstützung für Handschriften. Das folgende Beispiel zeigt einen beispielhaften JSON-Ausschnitt.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Wenn Sie die Add-On-Funktion für Schriftart/Schriftschnitt aktiviert haben, erhalten Sie als Teil des styles-Objekts auch das Ergebnis für die Schriftart und den Schriftschnitt.
Nächste Schritte
Schnellstart für Dokument Intelligenz:
Erkunden Sie unsere REST-API:
Weitere Beispiele finden Sie auf GitHub: