payStub-Modell von Document Intelligence
Das payStub-Modell von Document Intelligence kombiniert leistungsstarke OCR-Funktionen (Optical Character Recognition, optische Zeichenerkennung) mit Deep Learning-Modellen, um Vergütungs- und Gehaltsdaten aus Lohnabrechnungen zu analysieren und zu extrahieren. Die API analysiert Dokumente und Dateien mit Informationen zu Lohnbuchhaltungen; extrahiert wichtige Informationen und gibt eine strukturierte JSON-Datendarstellung zurück.
| Funktion | version | Modell-ID |
|---|---|---|
| payStub-Modell | Version 4.0: 2024-11-30 (GA) | prebuilt-payStub.us |
Testen der payStub-Datenextraktion
Lohnabrechnungen sind wesentliche Dokumente, die von Arbeitgebern an Arbeitnehmer ausgegeben werden, die Einnahmen, Abzüge und Nettolohninformationen für einen bestimmten Zahlungszeitraum bereitstellen. Erfahren Sie, wie Daten mithilfe des prebuilt-payStub.us-Modells extrahiert werden. Sie benötigen die folgenden Ressourcen:
Azure-Abonnement – Sie können ein kostenloses Abonnement erstellen
Eine Dokument Intelligenz-Instanz im Azure-Portal. Sie können den kostenlosen Tarif (
F0) verwenden, um den Dienst auszuprobieren. Wählen Sie nach der Bereitstellung Ihrer Ressource Zu Ressource wechseln aus, um Ihren Schlüssel und Endpunkt abzurufen.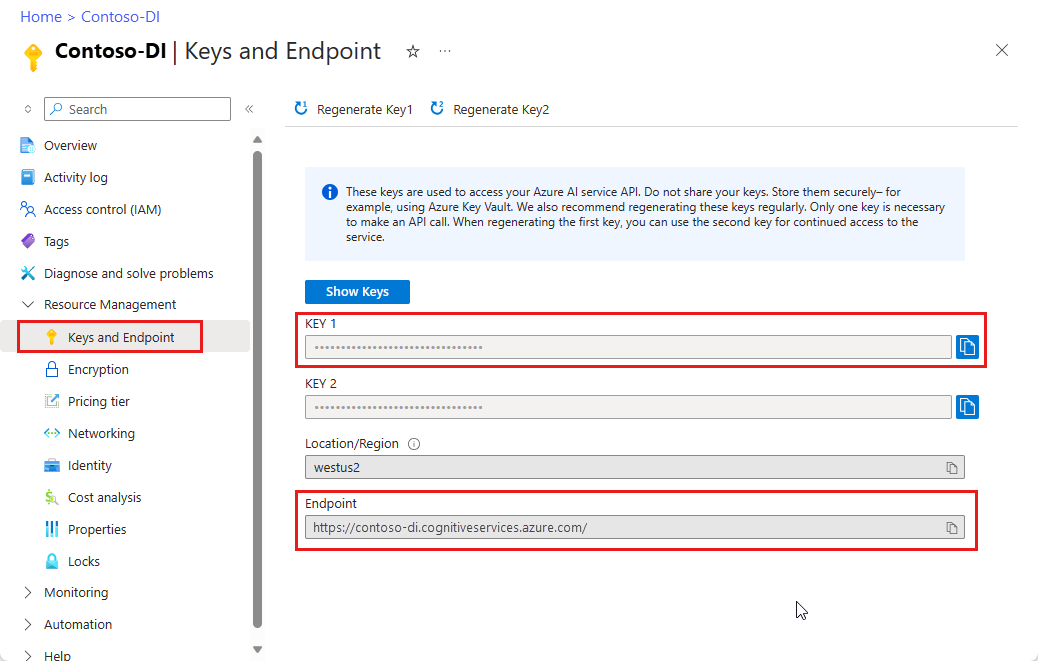
Dokument Intelligenz Studio
Wählen Sie auf der Startseite Document Intelligence Studio Lohnabrechnung aus.
Sie können die Musterlohnabrechnung analysieren oder Ihre eigenen Dateien hochladen.
Wählen Sie die Schaltfläche Analyse ausführen aus, und konfigurieren Sie bei Bedarf die Analyseoptionen:
Eingabeanforderungen
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-11-30 (GA) beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Unterstützte Sprachen und Regionen
Eine vollständige Liste der unterstützten Sprachen finden Sie auf der Seite Sprachunterstützung: vorgefertigte Modelle.
Feldextraktionen
Weitere Informationen zu unterstützten Feldern für die Dokumentextraktion finden Sie in unserem GitHub-Beispielrepository auf der Seite payStub-Modellschema.
Unterstützte Gebietsschemas
Die prebuilt-payStub.us-Version unterstützt das Gebietsschema en-us.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.