Analysieren der Dokument-API-Antwort
In diesem Artikel untersuchen wir die verschiedenen Objekte, die als Teil der AnalyzeDocument-Antwort zurückgegeben werden, und wie Sie die Antwort der Dokumentenanalyse-API in Ihren Anwendungen verwenden können.
Analysieren einer Dokumentanforderung
Mit den Dokument Intelligenz-APIs werden Bilder, PDFs und andere Dokumentdateien analysiert, um verschiedene Inhalts-, Layout-, Stil- und semantische Elemente zu extrahieren und zu erkennen. Der Analyze Vorgang ist eine asynchrone API. Bei der Übermittlung eines Dokuments wird ein Operation-Location-Header zurückgegeben, der die URL zum Durchführen der Abfrage enthält. Wenn eine Analyseanforderung erfolgreich abgeschlossen wurde, enthält die Antwort die unter Extrahieren von Modelldaten beschriebenen Elemente.
Antwortelemente
Inhaltselemente sind die grundlegenden Textelemente, die aus dem Dokument extrahiert werden.
Layoutelemente gruppieren Inhaltselemente in strukturierte Einheiten.
Stilelemente beschreiben die Schriftart und Sprache von Inhaltselementen.
Semantische Elemente weisen den angegebenen Inhaltselementen eine Bedeutung zu.
Alle Inhaltselemente sind nach Seiten gruppiert, angegeben durch die Seitennummer (1-indiziert). Sie werden zudem nach einer Lesereihenfolge sortiert, bei der semantisch zusammenhängende Elemente gemeinsam angeordnet werden, selbst wenn sie Zeilen- oder Spaltengrenzen überschreiten. Wenn die Lesereihenfolge zwischen Absätzen und anderen Layoutelementen nicht eindeutig ist, gibt der Dienst den Inhalt im Allgemeinen von links nach rechts und von oben nach unten aus.
Hinweis
Derzeit unterstützt die Dokument Intelligenz keine seitenübergreifende Lesereihenfolge. Auswahlmarkierungen werden nicht innerhalb der umgebenden Wörter positioniert.
Die Eigenschaft für Inhalte der obersten Ebene enthält eine Verkettung aller Inhaltselemente in Lesereihenfolge. Alle Elemente geben ihre Position in der Lesereihenfolge über Abschnitte innerhalb dieser Inhaltszeichenfolge an. Bei einigen Elementen ist der Inhalt möglicherweise nicht zusammenhängend.
Analysieren der Antwort
Die Analyze Antwort für jede API gibt unterschiedliche Objekte zurück. API-Antworten enthalten ggf. Elemente aus Komponentenmodellen.
| Antwortinhalt | Beschreibung | API |
|---|---|---|
| pages | Wörter, Zeilen und Abschnitte, die von jeder Seite des Eingabedokuments erkannt werden. | Modelle „Lesen“, „Layout“, „Allgemeines Dokument“, vordefinierte und benutzerdefinierte Modelle |
| paragraphs | Inhalt, der als Absatz erkannt wird. | Modelle „Lesen“, „Layout“, „Allgemeines Dokument“, vordefinierte und benutzerdefinierte Modelle |
| styles | Identifizierte Textelementeigenschaften. | Modelle „Lesen“, „Layout“, „Allgemeines Dokument“, vordefinierte und benutzerdefinierte Modelle |
| languages | Identifizierte Sprache, die den einzelnen Abschnitten des extrahierten Textes zugeordnet ist. | Lesen |
| tables | Tabellarische Inhalte, die identifiziert und aus dem Dokument extrahiert wurden. Tabellen beziehen sich auf Tabellen, die durch das vorab trainierte Layoutmodell identifiziert wurden. Als Tabellen gekennzeichnete Inhalte werden als strukturierte Felder in das Dokumentobjekt extrahiert. | Modelle „Layout“, „Allgemeines Dokument“, „Rechnung“ und benutzerdefinierte Modelle |
| Zahlen | Abbildungen (Diagramme, Bilder) identifiziert und aus dem Dokument extrahiert und liefern visuelle Darstellungen, die das Verständnis komplexer Informationen unterstützen. | Das Layoutmodell |
| sections | Hierarchische Dokumentstruktur identifiziert und aus dem Dokument extrahiert. Abschnitt oder Unterabschnitt mit den entsprechenden Elementen (Absatz, Tabelle, Abbildung) angefügt. | Das Layoutmodell |
| keyValuePairs | Schlüssel-Wert-Paare, die von einem vorab trainierten Modell erkannt werden. Der Schlüssel ist ein Textabschnitt aus dem Dokument mit dem zugehörigen Wert. | Modelle „Allgemeines Dokument“ und „Rechnung“ |
| documents | Erkannte Felder werden im fields-Wörterbuch innerhalb der Liste der Dokumente zurückgegeben. |
Vordefinierte und benutzerdefinierte Modelle. |
Weitere Informationen zu den Objekten, die von jeder API zurückgegeben werden, finden Sie unter Extrahieren von Modelldaten.
Elementeigenschaften
Span-Eigenschaften
Abschnitte geben die logische Position der einzelnen Elemente in der Lesereihenfolge insgesamt an, wobei jedes span-Element in der Eigenschaft der Zeichenfolge für den Inhalt auf oberster Ebene einen Zeichenversatz und eine Zeichenlänge angibt. Standardmäßig werden Zeichenversatz und -länge in Form der vom Benutzer wahrgenommenen Zeichen (auch als grapheme clusters oder Textelemente bezeichnet) zurückgegeben. Zur Unterstützung verschiedener Entwicklungsumgebungen, die unterschiedliche Zeicheneinheiten verwenden, kann der Benutzer den Abfrageparameter stringIndexIndex angeben, um Abschnittversatz und -länge auch in Unicode-Codepunkten (Python 3) oder UTF16-Codeeinheiten (Java, JavaScript, .NET) zurückzugeben. Weitere Informationen finden Sie unter Unterstützung für mehrere Sprachen und Emojis.
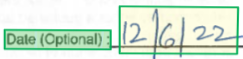
Begrenzungsbereich
Begrenzungsbereiche beschreiben die visuelle Position jedes Elements in der Datei. Wenn Elemente nicht visuell zusammenhängend sind oder sich über mehrere Seiten erstrecken (Tabellen), werden die Positionen der meisten Elemente mithilfe eines Arrays von Begrenzungsbereichen beschrieben. Jeder Bereich gibt die Seitennummer (1-indiziert) und das Begrenzungspolygon an. Das Begrenzungspolygon wird als eine Sequenz aus Punkten beschrieben, die links relativ zur natürlichen Ausrichtung des Elements beginnt und im Uhrzeigersinn fortgesetzt wird. Bei einem Viereck sind die Plotpunkte die Ecken oben links, oben rechts, unten rechts und unten links. Jeder Punkt stellt seine X,Y-Koordinate in der Seiteneinheit dar, die durch die Einheiteneigenschaft festgelegt ist. Im Allgemeinen sind Pixel die Maßeinheit für Bilder und Zentimeter oder Zoll die Einheit für PDFs.
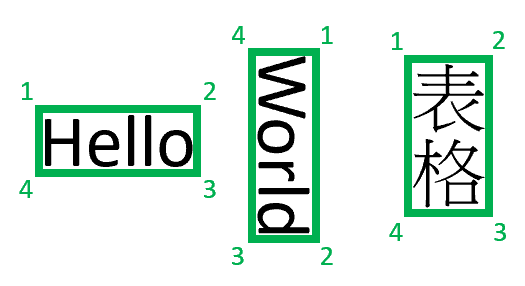
Hinweis
Derzeit gibt Dokument Intelligenz nur Vierecke mit vier Scheitelpunkten als gebundene Polygone zurück. Zukünftige Versionen können möglicherweise eine andere Anzahl von Punkten zurückgeben, um komplexere Formen zu beschreiben, z. B. gekrümmte Linien oder nicht rechtwinklige Bilder. Begrenzungsbereiche werden nur auf gerenderte Dateien angewendet. Wird die Datei nicht gerendert, werden keine Begrenzungsbereiche zurückgegeben. Derzeit werden Dateien im DOCX-/XLSX-/PPTX-/HTML-Format nicht gerendert.
Inhaltselemente
Word
Ein Wort ist ein Inhaltselement, das aus einer Folge von Zeichen besteht. In der Dokument Intelligenz wird ein Wort als eine Sequenz nebeneinander angeordneter Zeichen definiert, wobei die Wörter durch Leerzeichen voneinander getrennt sind. Bei Sprachen, die keine Leerzeichen zwischen Wörtern verwenden, wird jedes Zeichen als separates Wort zurückgegeben, auch wenn es keine semantische Worteinheit darstellt.

Auswahlmarkierungen
Eine Auswahlmarkierung ist ein Inhaltselement, das eine visuelle Glyphe repräsentiert, die den Status einer Auswahl anzeigt. Kontrollkästchen sind eine gängige Form der Auswahlmarkierung. Sie werden jedoch auch mithilfe von Optionsfeldern oder Zellen mit Rahmen in einem Formular dargestellt. Eine Auswahlmarkierung kann „ausgewählt“ oder „nicht ausgewählt“ sein, wobei der Status mit unterschiedlichen visuellen Darstellungen angezeigt wird.

Layoutelemente
Linie
Eine Zeile ist eine geordnete Abfolge von aufeinander folgenden Inhaltselementen, die durch einen sichtbaren Leerraum voneinander getrennt sind, oder von Elementen, die bei Sprachen ohne Leerzeichen zwischen Wörtern unmittelbar nebeneinander liegen. Inhaltselemente, die sich in derselben horizontalen Ebene (Zeile) befinden, aber durch mehr als einen sichtbaren Leerraum voneinander getrennt sind, werden meist in mehrere Zeilen aufgeteilt. Auch wenn diese Funktion mitunter semantisch zusammenhängende Inhalte in separate Zeilen aufteilt, ermöglicht sie die Darstellung von Textinhalten, die in mehrere Spalten oder Zellen aufgeteilt sind. Zeilen in vertikaler Schreibrichtung werden in vertikaler Richtung erkannt.

Paragraph
Ein Absatz ist eine geordnete Abfolge von Zeilen, die eine logische Einheit bilden. Üblicherweise weisen die Zeilen die gleiche Ausrichtung und gleiche Abstände zwischen den Zeilen auf. Absätze werden häufig durch Einrückung, einen zusätzlichen Abstand oder Aufzählungszeichen/Nummerierung gekennzeichnet. Inhalte können nur einem einzigen Absatz zugewiesen werden. Einzelne Absätze können darüber hinaus einer funktionalen Rolle im Dokument zugeordnet sein. Zu den derzeit unterstützten Rollen gehören Kopfzeile, Fußzeile, Seitennummer, Titel, Abschnittsüberschrift und Fußnote.

Seite
Eine Seite ist eine Gruppierung von Inhalten, die normalerweise einer Seite eines Blattes Papier entspricht. Eine gerenderte Seite ist durch Breite und Höhe in der angegebenen Einheit gekennzeichnet. Im Allgemeinen sind Pixel die Maßeinheit für Bilder und Zentimeter oder Zoll die Einheit für PDFs. Für Seiten, die gedreht werden können, beschreibt die Winkeleigenschaft den Textwinkel insgesamt in Grad.
Hinweis
Bei Arbeitsblättern (z. B. in Excel) wird jedes Blatt einer Seite zugeordnet. Bei Präsentationen (z. B. in PowerPoint) wird jede Folie einer Seite zugeordnet. Bei Dateiformaten ohne ein natives Seitenkonzept und ohne Rendering – z. B. HTML- oder Word-Dokumente – wird der Hauptinhalt der Datei als eine einzige Seite betrachtet.
Tabelle
Eine Tabelle ordnet Inhalte in einer Gruppe von Zellen in einem Rasterlayout an. Die Zeilen und Spalten können durch Rasterlinien, Farbmarkierungen oder größere Abstände optisch voneinander getrennt werden. Die Position einer Tabellenzelle wird durch ihre Zeilen- und Spaltenindizes angegeben. Eine Zelle kann sich über mehrere Zeilen und Spalten erstrecken.
Je nach Position und Formatierung kann eine Zelle als allgemeiner Inhalt, Zeilenüberschrift, Spaltenüberschrift, Stub-Überschrift oder Beschreibung klassifiziert werden:
Eine Zeilenüberschrift ist üblicherweise die erste Zelle in einer Zeile, die die übrigen Zellen in der Zeile beschreibt.
Eine Spaltenüberschrift ist üblicherweise die erste Zelle in einer Spalte, die die übrigen Zellen in der Zeile beschreibt.
Eine Zeile oder Spalte kann mehrere Kopfzeilenzellen zur Beschreibung hierarchischer Inhalte enthalten.
Eine Stub-Überschriftenzelle ist üblicherweise die Zelle in der ersten Zeile und der ersten Spalte. Sie kann leer sein oder die Werte in den Kopfzeilenzellen in derselben Zeile/Spalte beschreiben.
Eine Zelle mit einer Beschreibung befindet sich üblicherweise ganz oben oder ganz unten in einer Tabelle und beschreibt den gesamten Tabelleninhalt. Gelegentlich kann sie jedoch in der Mitte einer Tabelle angezeigt werden, um die Tabelle in Abschnitte zu unterteilen. Normalerweise erstrecken sich die Beschreibungszellen über mehrere Zellen in einer einzigen Zeile.
Eine Tabellenlegende enthält Informationen zur Erläuterung der Tabelle. Eine Tabelle kann zudem eine Beschriftung und eine Reihe von Fußnoten aufweisen. Anders als eine Beschreibungszelle liegt eine Legende üblicherweise außerhalb des Rasterlayouts. Eine Tabellennote kommentiert Den Inhalt der Tabelle, häufig mit einem Fußnotensymbol gekennzeichnet, das häufig unter dem Tabellenraster zu finden ist.
Layouttabellen unterscheiden sich von Dokumentfeldern, die aus tabellarischen Daten extrahiert werden. Layouttabellen werden aus tabellarischen visuellen Inhalten des Dokuments extrahiert, ohne die Semantik des Inhalts zu berücksichtigen. Tatsächlich dienen einige Layouttabellen ausschließlich zur optischen Gestaltung und enthalten möglicherweise nicht immer strukturierte Daten. Die Methode zum Extrahieren strukturierter Daten aus Dokumenten mit unterschiedlichen visuellen Layouts, wie z. B. die einzelnen Positionen eines Belegs, erfordert in der Regel eine erhebliche Nachbearbeitung. Es ist wichtig, die Zeilen- oder Spaltenüberschriften strukturierten Feldern mit normalisierten Feldnamen zuzuordnen. Verwenden Sie abhängig vom Dokumenttyp vordefinierte Modelle, oder trainieren Sie ein benutzerdefiniertes Modell, um solche strukturierten Inhalte zu extrahieren. Die resultierenden Informationen werden als Dokumentfelder verfügbar gemacht. Diese trainierten Modelle können auch tabellarische Daten ohne Überschriften und strukturierte Daten in nicht tabellarischer Form verarbeiten, z. B. den Abschnitt zur beruflichen Erfahrung in einem Lebenslauf.
Hinweis
Ab 2024-07-31-preview decken die Begrenzungsbereiche für Abbildungen und Tabellen nur den Kerninhalt ab und schließen zugehörige Beschriftungen und Fußnoten aus.

Zahlen
Abbildungen (Diagramme, Bilder) in Dokumenten spielen eine entscheidende Rolle bei der Ergänzung und Verbesserung des Textinhalts, wobei visuelle Darstellungen bereitgestellt werden, die das Verständnis komplexer Informationen unterstützen. Das vom Layoutmodell erkannte Abbildungsobjekt weist wichtige Eigenschaften auf boundingRegions (die räumlichen Positionen der Abbildung auf den Dokumentseiten, einschließlich der Seitenzahl und der Polygonkoordinaten, die die Begrenzung der Abbildung umrissen), spans (detailiert den Text, der sich auf die Abbildung bezieht, und gibt ihre Offsets und Längen im Text des Dokuments an. Diese Verbindung hilft beim Zuordnen der Abbildung zu ihrem relevanten Textkontext, elements (den Bezeichnern für Textelemente oder Absätze im Dokument, die sich auf die Abbildung beziehen oder beschreiben) und caption falls vorhanden.
Wenn während des ersten Analyze-Vorgangs output=figures angegeben wird, generiert der Dienst zugeschnittene Bilder für alle erkannten Figuren, auf die über /analyeResults/{resultId}/figures/{figureId} zugegriffen werden kann.
FigureId wird in jedes Abbildungsobjekt aufgenommen und folgt einer undokumentierten Konvention von {pageNumber}.{figureIndex}, wobei figureIndex auf eine Instanz pro Seite zurücksetzt.
{
"figures": [
{
"id": "{figureId}",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Abschnitte
Die hierarchische Dokumentstrukturanalyse ist entscheidend bei der Organisation, Verständnis und Verarbeitung umfangreicher Dokumente. Dieser Ansatz ist entscheidend für die semantische Segmentierung langer Dokumente, um das Verständnis zu steigern, die Navigation zu erleichtern und den Abruf von Informationen zu verbessern. Die Einführung von Retrieval Augmented Generation (RAG) in dokumentgeneriver KI unterstreicht die Bedeutung der hierarchischen Dokumentstrukturanalyse. Das Layoutmodell unterstützt Abschnitte und Unterabschnitte in der Ausgabe, die die Beziehung von Abschnitten und Objekten innerhalb der einzelnen Abschnitte identifiziert. Die hierarchische Struktur wird in elements von jedem Abschnitt beibehalten.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Formularfeld (Schlüssel-Wert-Paar)
Ein Formularfeld besteht aus einer Feldbeschriftung (Schlüssel) und einem Wert. Die Feldbeschriftung ist in der Regel eine beschreibende Textzeichenfolge, mit der die Bedeutung des Felds angegeben wird. Sie wird meistens links vom Wert angezeigt, kann aber auch über oder unter dem Wert stehen. Der Feldwert enthält den Inhaltswert einer bestimmten Feldinstanz. Der Wert kann aus Wörtern, Auswahlmarkierungen und anderen Inhaltselementen bestehen. Bei nicht ausgefüllten Formularfeldern kann er auch leer sein. Ein spezieller Formularfeldtyp umfasst einen Wert für die Auswahlmarkierung mit einer Feldbeschriftung rechts daneben. Ein Dokumentfeld ist ein ähnliches Konzept, das sich jedoch von den allgemeinen Formularfeldern unterscheidet. Die Feldbeschriftung (Schlüssel) in einem allgemeinen Formularfeld muss im Dokument angezeigt werden. Daher kann sie im Allgemeinen keine Informationen wie den Namen des Händlers auf einem Beleg erfassen. Dokumentfelder sind beschriftet und extrahieren keinen Schlüssel. Dokumentfelder ordnen nur einen extrahierten Wert einem beschrifteten Schlüssel zu. Weitere Informationen finden Sie unter Dokumentfelder.

Stilelemente
Stil
Ein Stilelement beschreibt den Schriftstil, der auf Textinhalte angewendet werden soll. Der Inhalt wird mithilfe von Abschnitten in der globalen Inhaltseigenschaft angegeben. Derzeit wird nur erkannt, ob es sich um einen handgeschriebenen Text handelt. Wenn weitere Stile hinzugefügt werden, kann der Text durch mehrere nicht miteinander in Konflikt stehende Stilobjekte beschrieben werden. Zur Vereinfachung werden alle Texte, die denselben Schriftstil verwenden (mit der gleichen Konfidenz), über ein einziges Stilobjekt beschrieben.
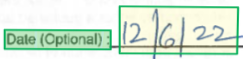
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Sprache
Ein Sprachelement beschreibt die erkannte Sprache für Inhalte, die mithilfe von Abschnitten in der globalen Inhaltseigenschaft angegeben werden. Die erkannte Sprache wird über ein BCP-47-Sprachtag angegeben, das die primäre Sprache und optionale Skript- und Regionsinformationen definiert. Beispielsweise werden Englisch und traditionelles Chinesisch jeweils als "en" bzw. zh-Hant erkannt. Regionale Unterschiede bezüglich der Schreibweise im britischen Englisch können dazu führen, dass der Text als en-GB erkannt wird. Text ohne dominante Sprache (z. B. Zahlen) gilt nicht als Sprachelement.
Semantikelemente
Hinweis
Die hier erläuterten semantischen Elemente gelten für vordefinierte Document Intelligence-Modelle. Ihre benutzerdefinierten Modelle geben möglicherweise unterschiedliche Datendarstellungen zurück. Beispielsweise können Datum und Uhrzeit, die von einem benutzerdefinierten Modell zurückgegeben werden, in einem Muster dargestellt werden, das sich von der ISO 8601-Standardformatierung unterscheidet.
Dokument
Ein Dokument ist eine semantisch vollständige Einheit. Eine Datei kann mehrere Dokumente enthalten, z. B. mehrere Steuerformulare innerhalb einer PDF-Datei oder mehrere Belege auf einer einzigen Seite. Die Reihenfolge der Dokumente innerhalb der Datei hat jedoch keinen grundlegenden Einfluss auf die darin vermittelten Informationen.
Hinweis
Die aktuelle Dokument Intelligenz bietet keine Unterstützung für mehrere Dokumente auf einer einzigen Seite.
Der Dokumenttyp beschreibt Dokumente mit einem gemeinsamen Satz semantischer Felder, die durch ein strukturiertes Schema abgebildet werden, unabhängig von der zugehörigen visuellen Vorlage oder dem Layout. Beispielsweise können alle Dokumente vom Typ „Beleg“ den Namen des Händlers, das Transaktionsdatum und die Gesamtsumme der Transaktion enthalten, auch wenn sich Restaurant- und Hotelbelege oft im Aussehen unterscheiden.
Ein Dokumentelement enthält die Liste der erkannten Felder aus den Feldern, die im semantischen Schema des erkannten Dokumenttyps angegeben sind:
Ein Dokumentfeld kann extrahiert oder abgeleitet werden. Extrahierte Felder werden durch den extrahierten Inhalt und optional durch den normalisierten Wert dargestellt, sofern interpretierbar.
Ein abgeleitetes Feld besitzt keine Inhaltseigenschaft und wird nur durch seinen Wert dargestellt.
Ein Arrayfeld enthält keine Inhaltseigenschaft. Der Inhalt kann aus dem Inhalt der Array-Elemente verkettet werden.
Ein Objektfeld enthält eine Inhaltseigenschaft, die den vollständigen Inhalt des Objekts angibt, wobei es sich um eine Obermenge der extrahierten untergeordneten Felder handeln kann.
Das semantische Schema eines Dokumenttyps wird durch die Felder beschrieben, die er enthalten kann. Jedes Feldschema wird durch seinen kanonischen Namen und Werttyp angegeben. Feldwerttypen umfassen grundlegende Typen (z. B. Zeichenfolge), zusammengesetzte Typen (z. B. Adresse) und strukturierte Typen (z. B. Array, Objekt). Der Feldwerttyp gibt außerdem die semantische Normalisierung an, die durchgeführt wird, um erkannte Inhalte in eine normalisierte Darstellung zu konvertieren. Die Normalisierung kann vom Gebietsschema abhängig sein.
Standardtypen
| Feldwerttyp | BESCHREIBUNG | Normalisierte Darstellung | Beispiel (Feldinhalt -> Wert) |
|---|---|---|---|
| Zeichenfolge | Nur-Text | Identisch mit Inhalt | MerchantName: "Contoso" → "Contoso" |
| Datum | Datum | ISO 8601 – JJJJ-MM-TT | InvoiceDate: "5/7/2022" → "2022-05-07" |
| time | Time | ISO 8601 – hh:mm:ss | TransactionTime: "9:45 PM" → "21:45:00" |
| phoneNumber | Telefonnummer | E.164 – +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | Land/Region | ISO 3166-1 alpha-3 | CountryRegion: "United States" → "USA" |
| selectionMark | Is selected | "selected" oder "not selected" | AcceptEula: ☑ → "selected" |
| signature | Unterschrieben | Identisch mit Inhalt | LendeeSignature: {signature} → "signed" |
| number | Gleitkommazahl | Gleitkommazahl | Quantity: "1.20" → 1.2 |
| integer | Ganze Zahl | 64-Bit-Ganzzahl mit Vorzeichen | Count: "123" → 123 |
| boolean | Boolescher Wert | TRUE/FALSE | IsStatutoryEmployee: ☑ → true |
Zusammengesetzte Typen
Währung: Betrag mit optionaler Währungseinheit. Ein Wert, z. B.:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Adresse: Analysierte Adresse. Beispiel:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Strukturierte Typen
Array: Liste mit Feldern desselben Typs
"Items": { "type": "array", "valueArray": [ ] }Objekt: Benannte Liste untergeordneter Felder mit potenziell unterschiedlichen Typen
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.