Schnellstart: Erstellen einer Objekterkennung mit der Custom Vision-Website
In diesem Schnellstart erfahren Sie, wie Sie mithilfe der Custom Vision-Website ein Objekterkennungsmodell erstellen. Nachdem Sie ein Modell erstellt haben, können Sie es mit neuen Bildern testen und in Ihre eigene Bilderkennungs-App integrieren.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Eine Reihe von Bildern, mit denen Sie Ihr Erkennungsmodell trainieren können. Sie können den Satz von Beispielbildern auf GitHub verwenden. Sie können auch eigene Bilder mit den folgenden Tipps auswählen.
- Ein unterstützter Webbrowser.
Erstellen von Custom Vision-Ressourcen
Für die Verwendung des Custom Vision-Diensts müssen Sie Azure-Ressourcen für Custom Vision-Training und -Vorhersage erstellen. Verwenden Sie im Azure-Portal die Seite Custom Vision-Ressource erstellen, um sowohl eine Trainingsressource als auch eine Vorhersageressource zu erstellen.
Erstellen eines neuen Projekts
Navigieren Sie im Webbrowser zur Custom Vision-Website. Melden Sie sich mit demselben Konto an, mit dem Sie sich auch beim Azure-Portal angemeldet haben.
Um Ihr erstes Projekt zu erstellen, wählen Sie New Project (Neues Projekt) aus. Das Dialogfeld Neues Projekt erstellen wird angezeigt.
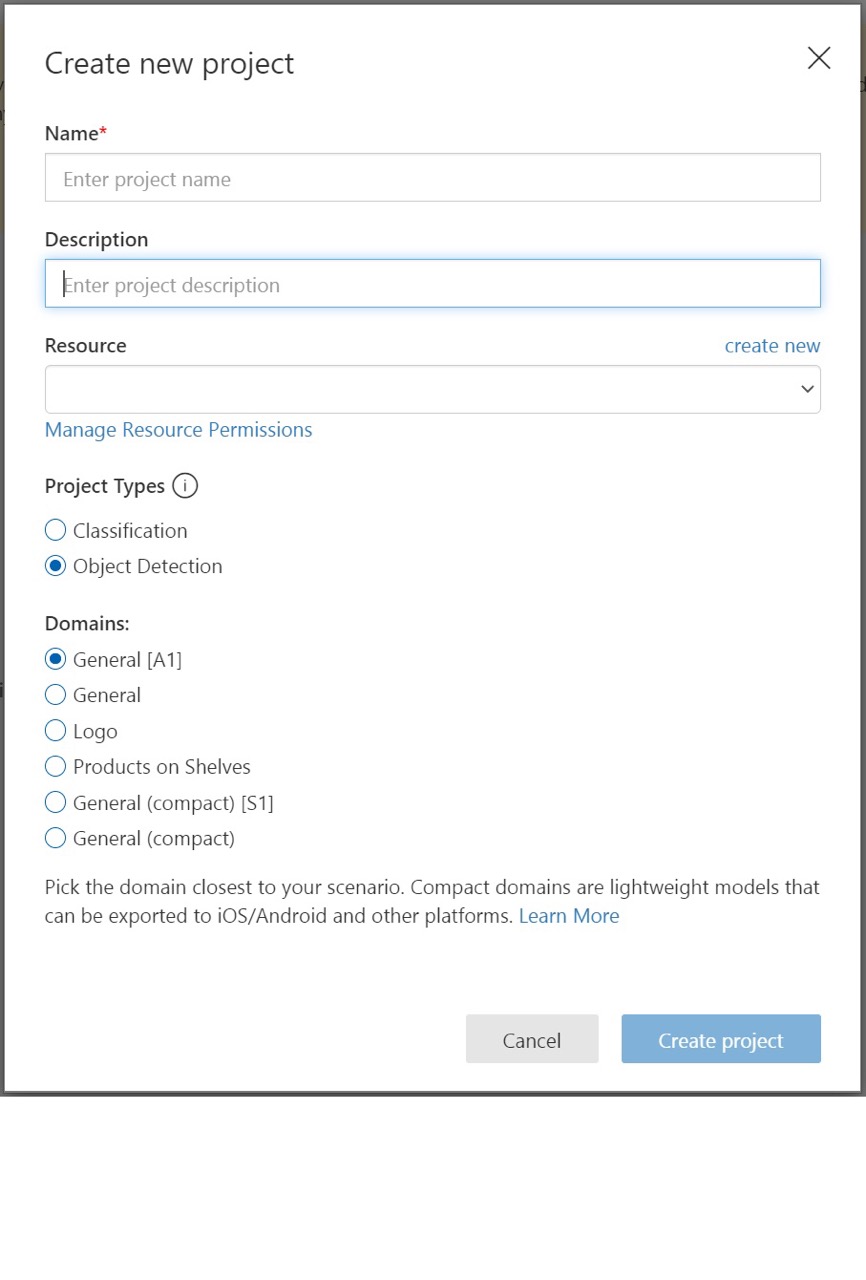
Geben Sie einen Namen und eine Beschreibung für das Projekt ein. Wählen Sie dann Ihre Custom Vision-Trainingsressource aus. Wenn Ihr angemeldetes Konto einem Azure-Konto zugeordnet ist, werden in der Dropdownliste Ressource alle Ihre kompatiblen Azure-Ressourcen angezeigt.
Hinweis
Wenn keine Ressource verfügbar ist, vergewissern Sie sich, dass Sie bei customvision.ai mit demselben Konto angemeldet sind, das Sie auch für die Anmeldung im Azure-Portal verwendet haben. Stellen Sie darüber hinaus sicher, dass Sie im Custom Vision-Portal dasselbe Verzeichnis wie im Azure-Portal gewählt haben, in dem sich Ihre Custom Vision-Ressourcen befinden. An beiden Orten können Sie Ihr Verzeichnis jeweils oben rechts im Dropdownmenü mit den Konten auswählen.
Wählen Sie unter Projekttypen die Option Objekterkennung aus.
Wählen Sie eine der verfügbaren Domänen aus. Jede Domäne optimiert das Erkennungsmodul für bestimmte Bildtypen, wie in der folgenden Tabelle beschrieben. Sie können die Domäne bei Bedarf später ändern.
Domäne Zweck Allgemein Für eine Vielzahl von Aufgaben der Objekterkennung optimiert. Wenn keine der anderen Domänen geeignet erscheint oder Sie unsicher sind, welche Domäne Sie wählen sollen, verwenden Sie die allgemeine Domäne. Logo Für die Suche nach Markenlogos in Bildern optimiert. Produkte in Regalen Für die Erkennung und Klassifizierung von Produkten in Regalen optimiert. Kompaktdomänen Für die Bedingungen der Echtzeitobjekterkennung auf Mobilgeräten optimiert. Die von Kompaktdomänen generierten Modelle können für die lokale Ausführung exportiert werden. Wählen Sie schließlich Create Project (Projekt erstellen) aus.
Auswählen von Trainingsbildern
Es wird empfohlen, im ersten Trainingssatz mindestens 30 Bilder pro Tag zu verwenden. Sie sollten auch einige zusätzliche Bilder sammeln, um Ihr Modell nach dem Training zu testen.
Verwenden Sie zum effektiven Trainieren Ihres Modells Bilder mit optischer Vielfalt. Wählen Sie Bilder aus, die sich nach folgenden Aspekten unterscheiden:
- Kamerawinkel
- Belichtung
- background
- Visueller Stil
- Einzelne/gruppierte Motive
- size
- type
Stellen Sie außerdem sicher, dass alle Ihre Trainingsbilder die folgenden Kriterien erfüllen:
- JPG-, PNG-, BMP- oder GIF-Format erforderlich
- Max. 6 MB groß (4 MB bei Vorhersagebildern)
- Mindestens 256 Pixel an der kürzesten Seite; kürzere Bilder werden vom Custom Vision-Dienst automatisch hochskaliert.
Hochladen und Kennzeichnen von Bildern
In diesem Abschnitt werden Bilder hochgeladen und manuell gekennzeichnet, um das Erkennungsmodul zu trainieren.
Wählen Sie zum Hinzufügen von Bildern Bilder hinzufügen und anschließend Lokale Dateien durchsuchen aus. Wählen Sie Öffnen aus, um die Bilder hochzuladen.
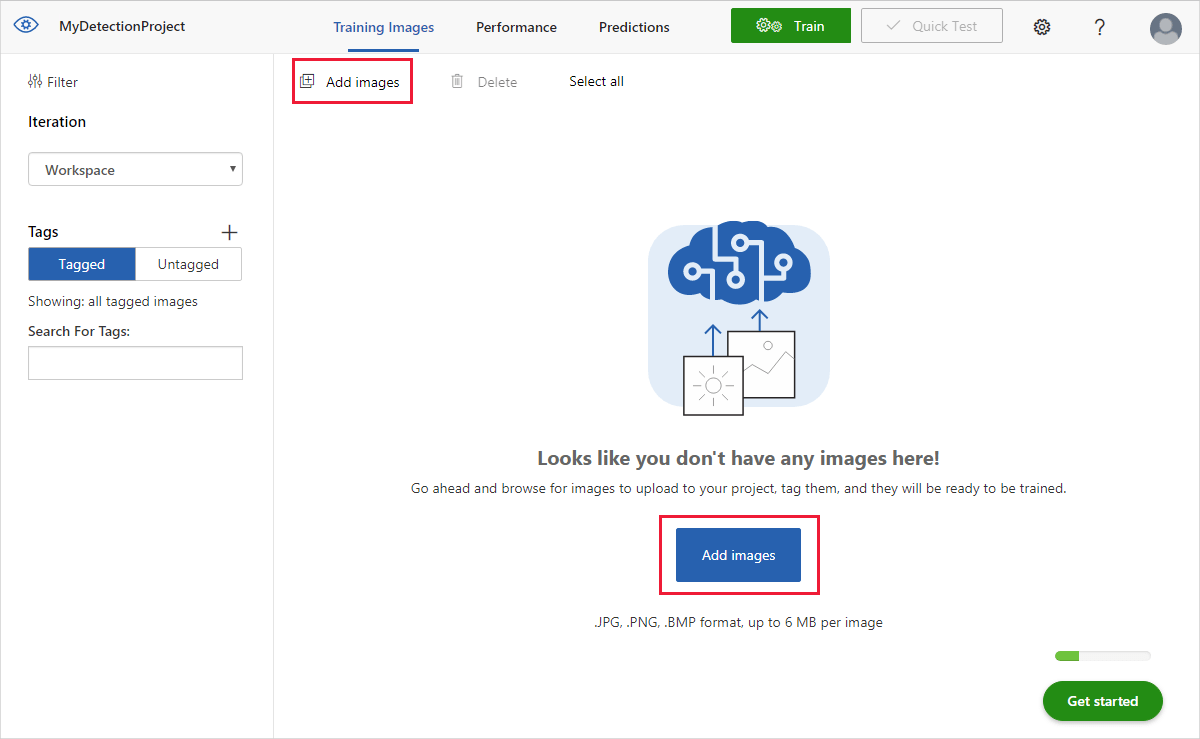
Die hochgeladenen Bilder werden im Abschnitt Ohne Markierungen der Benutzeroberfläche angezeigt. Der nächste Schritt besteht darin, die Objekte manuell zu kennzeichnen, die vom Erkennungsmodul erkannt werden sollen. Wählen Sie das erste Bild aus, um das Dialogfenster für das Tagging zu öffnen.
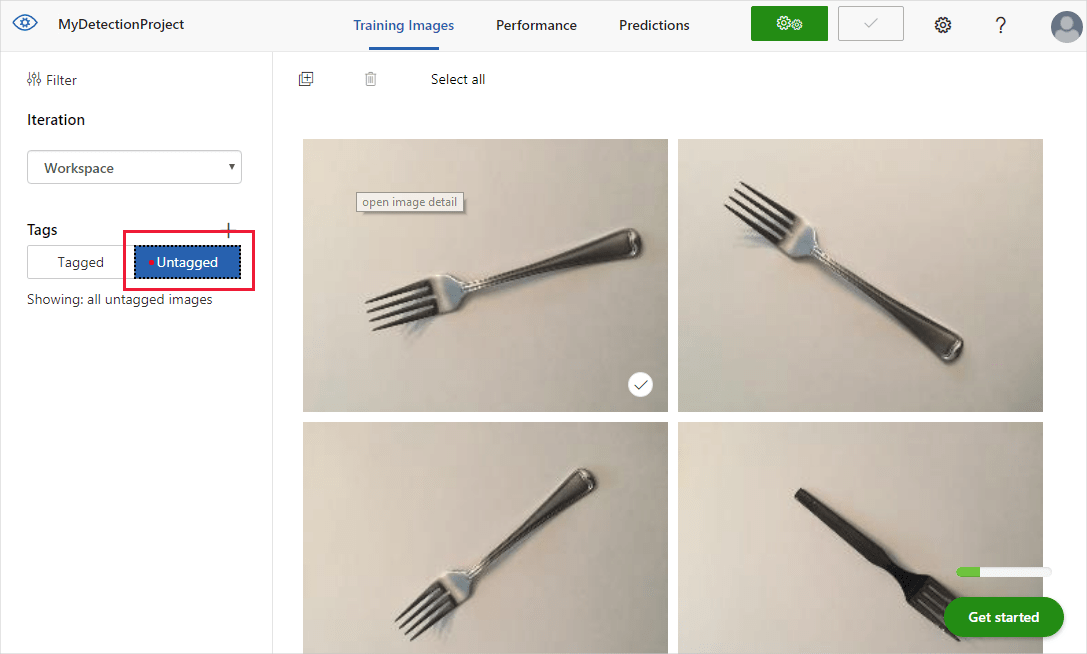
Ziehen Sie ein Auswahlrechteck um das Objekt in Ihrem Bild. Geben Sie dann mit der Schaltfläche + einen neuen Tagnamen ein, oder wählen Sie ein vorhandenes Tag aus der Dropdownliste aus. Es ist wichtig, jede Instanz der Objekte, die Sie erkennen möchten, zu kennzeichnen, da das Erkennungsmodul den nicht gekennzeichneten Hintergrundbereich beim Trainieren als negatives Beispiel verwendet. Wenn Sie mit dem Tagging fertig sind, wählen Sie den Pfeil rechts aus, um Ihre Tags zu speichern und zum nächsten Bild zu gelangen.
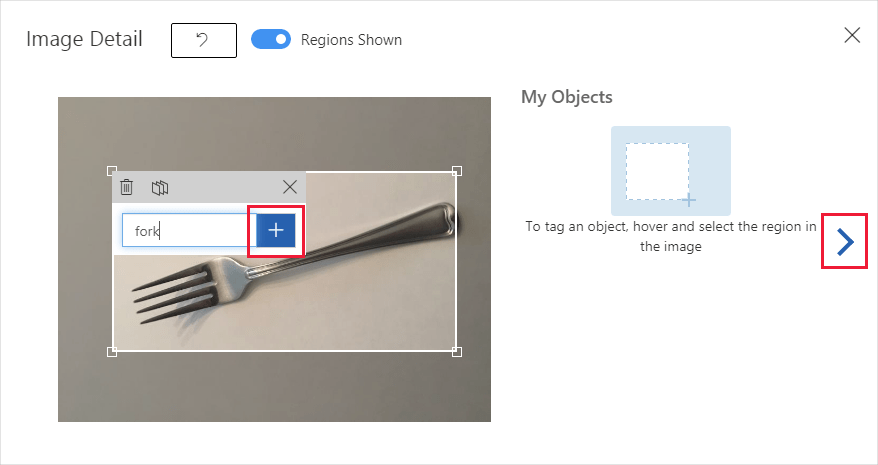
Zum Hochladen eines weiteren Bildersatzes kehren Sie zum Anfang dieses Abschnitts zurück und wiederholen die Schritte.
Trainieren des Erkennungsmoduls
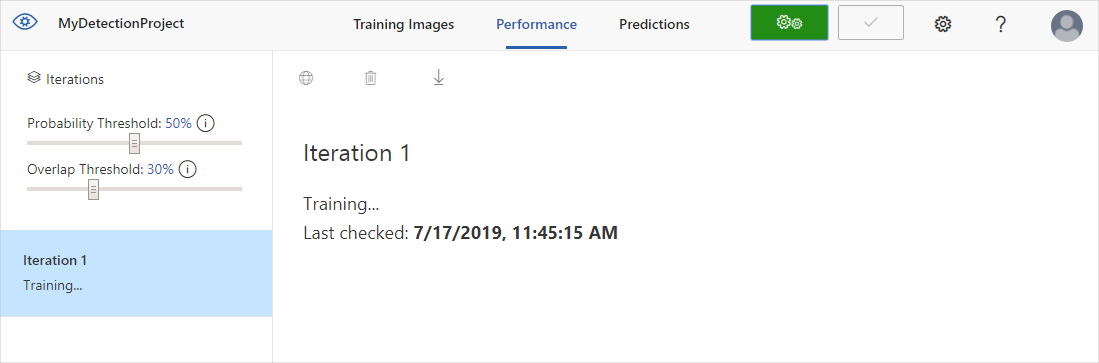
Um das Erkennungsmodell zu trainieren, wählen Sie die Schaltfläche Trainieren aus. Das Erkennungsmodul verwendet alle aktuellen Bilder und deren Tags zum Erstellen eines Modells, das die einzelnen gekennzeichneten Objekte identifiziert. Dieser Vorgang kann mehrere Minuten dauern.

Der Trainingsprozess sollte nur wenige Minuten dauern. Während dieser Zeit werden auf der Registerkarte Leistung Informationen über den Trainingsprozess angezeigt.
Auswerten des Erkennungsmoduls
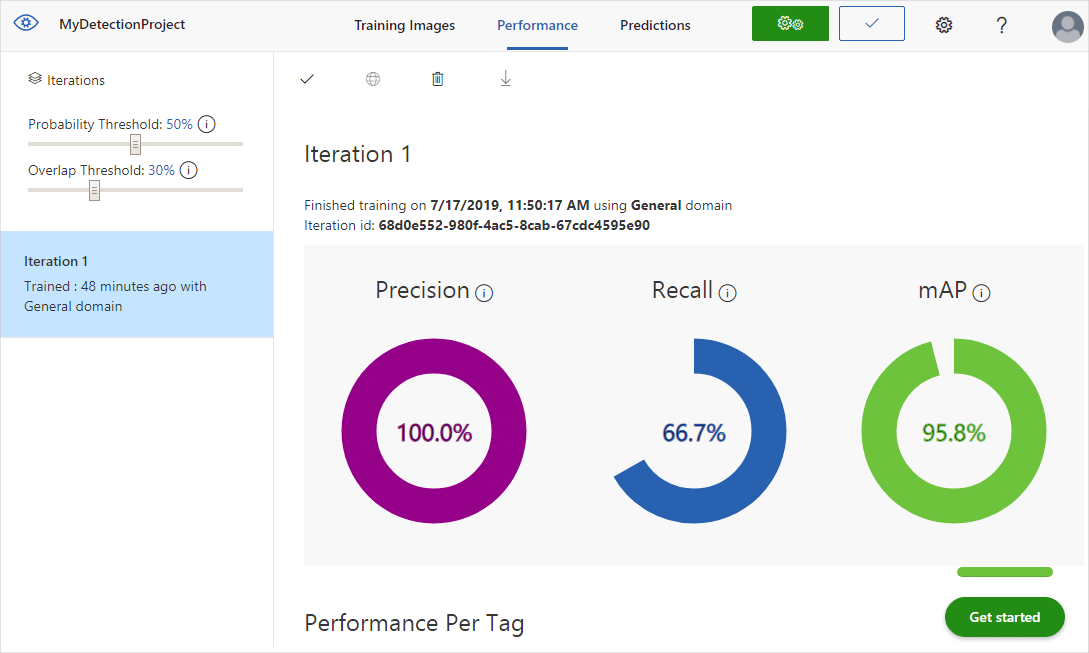
Nach Abschluss des Trainings wird die Leistung des Modells berechnet und angezeigt. Custom Vision Service verwendet die Bilder, die Sie zum Training gesendet haben, zur Berechnung von Genauigkeit, Trefferquote und mittlerer durchschnittlicher Genauigkeit. Genauigkeit und Trefferquote sind zwei unterschiedliche Messungen der Wirksamkeit eines Erkennungsmoduls:
- Die Genauigkeit gibt den Anteil der richtig identifizierten Klassifizierungen an. Beispiel: Wenn das Modell 100 Bilder als Hunde identifiziert hat und 99 davon tatsächlich Hunde zeigten, beträgt die Genauigkeit 99 %.
- Die Trefferquote gibt den Anteil der tatsächlichen Klassifizierungen an, die richtig identifiziert wurden. Beispiel: Wenn tatsächlich 100 Bilder von Äpfeln vorhanden sind und das Modell 80 davon als Äpfel identifiziert, beträgt die Trefferquote 80 %.
- Die durchschnittliche Genauigkeit ist der Durchschnittswert der durchschnittlichen Genauigkeit (Average Precision, AP). Die durchschnittliche Genauigkeit ist der Bereich unterhalb der Kurve zu Genauigkeit/Abruf. (Für jede ausgeführte Vorhersage wird die Genauigkeit in Bezug auf den Abruf gezeichnet.)
Wahrscheinlichkeitsschwellenwert
Beachten Sie den Schieberegler für den Wahrscheinlichkeitsschwellenwert im linken Bereich der Registerkarte Leistung. Dies ist das Maß an Vertrauen, das eine Vorhersage aufweisen muss, um als richtig betrachtet zu werden (zur Berechnung von Genauigkeit und Trefferquote).
Wenn Sie Vorhersageaufrufe mit einem hohen Wahrscheinlichkeitsschwellenwert interpretieren, neigen sie dazu, Ergebnisse mit hoher Genauigkeit auf Kosten der Trefferquote zu liefern. Die erkannten Klassifizierungen sind richtig, aber viele bleiben unerkannt. Ein niedriger Wahrscheinlichkeitsschwellenwert bewirkt das Gegenteil. Die meisten der tatsächlichen Klassifizierungen werden erkannt, aber es gibt mehr falsch positive Ergebnisse innerhalb dieser Menge. In diesem Sinne empfiehlt es sich, den Wahrscheinlichkeitsschwellenwert gemäß den spezifischen Anforderungen Ihres Projekts festzulegen. Wenn Sie später auf der Clientseite Vorhersageergebnisse erhalten, sollten Sie denselben Wahrscheinlichkeitsschwellenwert wie hier verwenden.
Überlappungsschwellenwert
Mit dem Schieberegler für den Überlappungsschwellenwert steuern Sie, wie korrekt eine Objektvorhersage sein muss, damit sie beim Trainieren als korrekt betrachtet wird. Er legt die kleinstmögliche Überlappung zwischen dem vorhergesagten Objektbegrenzungsrahmen und dem tatsächlich vom Benutzer eingegebenen Begrenzungsrahmen fest. Wenn die Begrenzungsrahmen nicht in diesem Maße überlappen, wird die Vorhersage nicht als korrekt betrachtet.
Verwalten von Trainingsiterationen
Bei jedem Trainingsvorgang für Ihr Erkennungsmodul erstellen Sie eine neue Iteration mit eigenen aktualisierten Leistungsmetriken. Sie können alle Ihre Iterationen im linken Bereich der Registerkarte Leistung anzeigen. Im linken Bereich befindet sich auch die Schaltfläche Löschen, mit der Sie veraltete Iterationen löschen können. Beim Löschen einer Iteration werden auch alle Bilder gelöscht, die dieser eindeutig zugeordnet sind.
Weitere Informationen zum programmgesteuerten Zugriff auf die trainierten Modelle finden Sie unter Verwenden des Modells mit der Vorhersage-API.
Nächster Schritt
In diesem Quickstart haben Sie erfahren, wie Sie über die Custom Vision-Website ein Objekterkennungsmodell erstellen und trainieren. Informieren Sie sich als Nächstes über den iterativen Prozess zur Verbesserung Ihres Modells.
Eine Übersicht finden Sie unter Was ist Custom Vision?.