Bewährte Methoden zur Verwendung der API zur Erkennung von univariaten Anomalien
Wichtig
Ab dem 20. September 2023 können Sie keine neuen Ressourcen für die Anomalieerkennung mehr erstellen. Der Anomalieerkennungsdienst wird am 1. Oktober 2026 eingestellt.
Die Anomalieerkennungs-API ist ein zustandsloser Dienst zur Erkennung von Anomalien. Folgende Aspekte können sich auf die Genauigkeit und Leistung ihrer Ergebnisse auswirken:
- Wie Ihre Zeitreihendaten vorbereitet werden
- Welche Parameter der Anomalieerkennungs-API verwendet wurden
- Wie viele Datenpunkte Ihre API-Anforderung erfasst
Lernen Sie in diesem Artikel Best Practices für die Verwendung der API kennen, um optimale Ergebnisse für Ihre Daten zu erzielen.
Zeitpunkt zum Verwenden der Anomalieerkennung über die Batcherkennung (gesamt) oder Erkennung des aktuellsten (letzten) Punkts
Mit dem Endpunkt der Batcherkennung der Anomalieerkennungs-API können Sie Anomalien in Ihren gesamten Zeitreihendaten erkennen. In diesem Erkennungsmodus wird ein einzelnes statistisches Modell erstellt und auf jeden Punkt im Dataset angewendet. Wenn Ihre Zeitreihe die folgenden Merkmale aufweist, wird empfohlen, die Batcherkennung zu verwenden, um Ihre Daten in einem einzelnen API-Aufruf vorab anzuzeigen.
- Eine saisonale Zeitreihe mit gelegentlichen Anomalien.
- Eine flache Trendzeitreihe mit gelegentlichen Spitzen/Abfällen.
Es wird nicht empfohlen, die Batchanomalieerkennung für die Datenüberwachung in Echtzeit oder sie für Zeitreihendaten zu verwenden, die nicht über die oben genannten Merkmale verfügen.
Die Batcherkennung erstellt nur ein Modell und wendet es an. Die Erkennung für die einzelnen Punkte erfolgt im Kontext der gesamten Zeitreihe. Wenn die Zeitreihendaten ohne Saisonalität einen Auf- oder Abwärtstrend zeigen, werden einige Änderungspunkte (Abfälle und Spitzen in den Daten) vom Modell möglicherweise übersehen. Ebenso können einige Änderungspunkte, die weniger signifikant sind als diejenigen, die an einer späteren Position im Dataset folgen, nicht als ausreichend signifikant eingestuft werden, um in das Modell integriert zu werden.
Die Batcherkennung ist aufgrund der Anzahl der zu analysierenden Punkte langsamer als das Erkennen des Anomaliestatus des letzten Punkts bei der Datenüberwachung in Echtzeit.
Für die Datenüberwachung in Echtzeit wird empfohlen, nur den Anomaliestatus Ihres neuesten Datenpunkts zu ermitteln. Durch die fortlaufende Anwendung der Erkennung des aktuellsten Punkts kann die Überwachung von Streamingdaten effizienter und genauer durchgeführt werden.
Im folgenden Beispiel wird beschrieben, welche Auswirkungen diese Erkennungsmodi auf die Leistung haben können. Das erste Bild zeigt das Ergebnis der fortlaufenden Erkennung des Anomaliestatus des aktuellsten Punkts entlang von 28 zuvor angezeigten Datenpunkten. Die roten Punkte sind Anomalien.

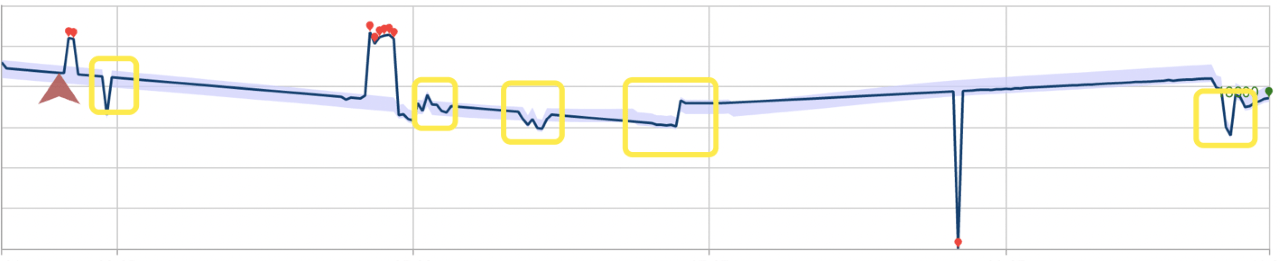
Nachfolgend ist dasselbe Dataset unter Verwendung der Batchanomalieerkennung aufgeführt. Das für den Vorgang erstellte Modell hat mehrere Anomalien ignoriert, die durch Rechtecke gekennzeichnet sind.
Datenaufbereitung
Die Anomalieerkennungs-API akzeptiert als JSON-Anforderungsobjekt formatierte Zeitreihendaten. Eine Zeitreihe kann aus beliebigen numerischen Daten bestehen, die über die Zeit sequenziell erfasst werden. Sie können Fenster Ihrer Zeitreihendaten an den Anomalieerkennungs-API-Endpunkt senden, um die Leistung der API zu verbessern. Dabei können zwischen 12 (Minimum) und 8640 (Maximum) Datenpunkten gesendet werden. Die Granularität wird als die Rate definiert, mit der Stichproben für die Daten erstellt werden.
Datenpunkte, die an die Anomalieerkennungs-API gesendet werden, müssen einen gültigen Zeitstempel der koordinierten Weltzeit (UTC) und einen numerischen Wert aufweisen.
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
Werden Ihre Daten in einem nicht standardmäßigen Zeitintervall erfasst, können Sie es durch Hinzufügen des Attributs customInterval in Ihrer Anforderung angeben. Wenn Ihre Reihe beispielsweise alle fünf Minuten erfasst wird, können Sie Ihrer JSON-Anforderung Folgendes hinzufügen:
{
"granularity" : "minutely",
"customInterval" : 5
}
Fehlende Datenpunkte
Fehlende Datenpunkte kommen häufig bei gleichmäßig verteilten Zeitreihendatensätzen vor, insbesondere bei solchen mit einer feinen Granularität (d. h. einem kurzen Samplingintervall, bei dem alle paar Minuten Daten erfasst werden). Wenn weniger als 10 % der erwarteten Anzahl von Punkten in Ihren Daten fehlen, dürfte dies keine negativen Auswirkungen auf Ihre Erkennungsergebnisse haben. Sie können Lücken in Ihren Daten anhand ihrer Eigenschaften schließen, indem Sie beispielsweise Datenpunkte aus einer früheren Periode als Ersatz einfügen, oder eine lineare Interpolation bzw. einen gleitenden Durchschnitt verwenden.
Aggregieren verteilter Daten
Die Anomalieerkennungs-API funktioniert am besten mit einer gleichmäßig verteilten Zeitreihe. Wenn Ihre Daten zufällig verteilt sind, sollten Sie diese nach Zeiteinheiten zusammenfassen, beispielsweise nach Minuten, stündlich oder täglich.
Erkennen von Anomalien in Daten mit saisonalen Mustern
Wenn Sie wissen, dass Ihre Zeitreihendaten ein saisonales Muster haben (eines, das in regelmäßigen Abständen auftritt), können Sie die Genauigkeit und die Antwortzeit der API verbessern.
Das Angeben einer period beim Erstellen Ihrer JSON-Anforderung kann die Wartezeit bei der Anomalieerkennung um bis zu 50 % verkürzen. period ist eine ganze Zahl, die ungefähr angibt, nach wie vielen Datenpunkten der Zeitreihe sich ein Muster wiederholt. Beispielsweise hätte eine Zeitreihe mit einem Datenpunkt pro Tag den period-Wert 7, und eine Zeitreihe mit einem Datenpunkt pro Stunde (bei gleichem wöchentlichem Muster) hätte den period-Wert 7*24. Wenn Sie das Muster Ihrer Daten nicht kennen, müssen Sie diesen Parameter nicht angeben.
Verwenden Sie für optimale Ergebnisse Datenpunkte für das Vierfache der period plus einen zusätzlichen Datenpunkt. Stündliche Daten mit einem wöchentlichen Muster wie oben beschrieben sollten im Anforderungstext beispielsweise 673 Datenpunkte bereitstellen (7 * 24 * 4 + 1).
Samplingdaten für die Überwachung in Echtzeit
Wenn Ihre Streamingdaten in einem kurzen Intervall (wie Sekunden oder Minuten) erfasst werden, kann durch das Senden der empfohlenen Anzahl von Datenpunkten die maximal zulässige Anzahl der Anomalieerkennungs-API (8640 Datenpunkte) überschritten werden. Wenn Ihre Daten ein stabiles saisonales Muster aufweisen, sollten Sie in Betracht ziehen, in einem größeren Zeitintervall (z. B. Stunden) eine Stichprobe Ihrer Zeitreihendaten zu senden. Indem Sie auf diese Weise Stichproben Ihrer Daten erfassen, kann auch die API-Reaktionszeit deutlich verbessert werden.