Verwenden von DISKSPD zum Testen einer Workloadspeicherleistung
Gilt für: Azure Stack HCI, Versionen 22H2 und 21H2; Windows Server 2022, Windows Server 2019
Wichtig
Azure Stack HCI ist jetzt Teil von Azure Local. Die Umbenennung der Produktdokumentation wird ausgeführt. Ältere Versionen von Azure Stack HCI, z. B. 22H2, verweisen jedoch weiterhin auf Azure Stack HCI und spiegeln die Namensänderung nicht wider. Weitere Informationen
Dieses Thema enthält Anleitungen dazu, wie DISKSPD verwendet wird, um eine Workloadspeicherleistung zu testen. Sie haben einen Azure Stack HCI-Cluster eingerichtet, der einsatzbereit ist. Super, aber woher wissen Sie, ob Sie die versprochenen Leistungsmetriken erreichen, etwa bei Wartezeit, Durchsatz oder IOPS? Dies ist der Punkt, an dem Sie das Tool DISKSPD verwenden möchten. Nachdem Sie dieses Thema gelesen haben, können Sie DISKSPD ausführen, kennen Sie eine Teilmenge der Parameter, können Sie die Ausgabe interpretieren und haben Sie ein grundsätzliches Verständnis der Variablen, die die Workloadspeicherleistung beeinflussen.
Was ist DISKSPD?
DISKSPD ist ein E/A-generierendes Befehlszeilentool für Mikrobenchmarking. Großartig, aber was bedeuten diese Ausdrücke? Jede Person, die einen Azure Stack HCI-Cluster oder physischen Server einrichtet, hat dafür einen Grund. Dieser Grund kann das Einrichten einer Webhostingumgebung oder das Ausführen von virtuellen Desktops für Mitarbeiter sein. Was auch immer der echte Anwendungsfall sein mag, Sie möchten wahrscheinlich einen Test simulieren, bevor Sie Ihre tatsächliche Anwendung bereitstellen. Das Testen Ihrer Anwendung in einem echten Szenario ist jedoch oft schwierig – an dieser Stelle kommt DISKSPD ins Spiel.
DISKSPD ist ein Tool, das Sie anpassen können, um Ihre eigenen synthetischen Workloads zu erstellen und Ihre Anwendung vor der Bereitstellung zu testen. Das tolle an dem Tool ist, dass es Ihnen die Möglichkeit bietet, die Parameter zu konfigurieren und zu optimieren, um ein bestimmtes Szenario zu erstellen, das Ihrer echten Workload nahe kommt. DISKSPD kann Ihnen vor der Bereitstellung einen Einblick in die Fähigkeiten Ihres Systems geben. Im Wesentlichen gibt DISKSPD lediglich eine Reihe von Lese- und Schreiboperationen aus.
Jetzt wissen Sie, was DISKSPD ist, aber wann sollten Sie es nutzen? DISKSPD ist nicht wirklich in der Lage, komplexe Workloads zu emulieren. Aber DISKSPD ist großartig, wenn Ihre Workload nicht genau durch eine Dateikopie mit einem einzigen Thread angenähert werden kann wird und Sie ein einfaches Tool benötigen, das akzeptable Basisergebnisse liefert.
Schnellstart: Installieren und Ausführen von DISKSPD
Um DISKSPD zu installieren und auszuführen, öffnen Sie PowerShell als Administrator auf Ihrem Verwaltungs-PC, und führen Sie dann die folgenden Schritte aus:
Führen Sie die folgenden Befehle aus, um die ZIP-Datei für das DISKSPD-Tool herunterzuladen und zu erweitern:
# Define the ZIP URL and the full path to save the file, including the filename $zipName = "DiskSpd.zip" $zipPath = "C:\DISKSPD" $zipFullName = Join-Path $zipPath $zipName $zipUrl = "https://github.com/microsoft/diskspd/releases/latest/download/" +$zipName # Ensure the target directory exists, if not then create if (-Not (Test-Path $zipPath)) { New-Item -Path $zipPath -ItemType Directory | Out-Null } # Download and expand the ZIP file Invoke-RestMethod -Uri $zipUrl -OutFile $zipFullName Expand-Archive -Path $zipFullName -DestinationPath $zipPathFühren Sie den folgenden Befehl aus, um
$PATHder Umgebungsvariable das DISKSPD-Verzeichnis hinzuzufügen:$diskspdPath = Join-Path $zipPath $env:PROCESSOR_ARCHITECTURE if ($env:path -split ';' -notcontains $diskspdPath) { $env:path += ";" + $diskspdPath }Führen Sie DISKSPD mit dem folgenden PowerShell-Befehl aus. Ersetzen Sie eckige Klammern durch die entsprechenden Einstellungen.
diskspd [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]Hier ist ein Beispielbefehl, den Sie ausführen können:
diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtHinweis
Wenn Sie keine Testdatei haben, verwenden Sie den Parameter -c, um eine zu erstellen. Wenn Sie diesen Parameter verwenden, müssen Sie den Namen der Testdatei einfügen, wenn Sie Ihren Pfad definieren. Beispiel: [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat. Im Beispielbefehl ist „IO.dat“ der Name der Testdatei, und „test01.txt“ ist der Name der Ausgabedatei von DISKSPD.
Angeben von Schlüsselparametern
Das war einfach, nicht wahr? Leider gibt es mehr dafür. Sehen Sie sich an, was bisher passiert ist. Zunächst gibt es verschiedene Parameter, mit denen experimentiert werden kann, und dies kann speziell werden. Bisher wurden die folgenden Basisparameter verwendet:
Hinweis
Für die DISKSPD-Parameter wird die Groß-/Kleinschreibung beachtet.
-t2: Dies gibt die Anzahl der Threads pro Ziel-/Testdatei an. Diese Anzahl basiert häufig auf der Anzahl der CPU-Kerne. In diesem Fall wurden zwei Threads verwendet, um alle CPU-Kerne zu belasten.
-o32: Dies gibt die Anzahl der ausstehenden E/A-Anforderungen pro Ziel pro Thread an. Dies wird auch als Warteschlangentiefe bezeichnet, und in diesem Fall wurde „32“ verwendet, um die CPU zu belasten.
-b4K: Dies gibt die Blockgröße in Bytes, KiB, MiB oder GiB an. In diesem Fall wurde die Blockgröße „4K“ verwendet, um einen zufälligen E/A-Test zu simulieren.
-r4K: Dies gibt die zufällige E/A an, die an der angegebenen Größe in Bytes, KiB, MiB, Gib oder Blöcken ausgerichtet ist (Überschreibt den Parameter -s ). Die übliche Größe von „4K“ wurde verwendet, um ordnungsgemäß mit der Blockgröße auszurichten.
-w0: Dies gibt den Prozentsatz der Vorgänge an, die Schreibanforderungen sind (-w0 entspricht 100 % Lesezugriff). In diesem Fall wurden 0 % Schreibanforderungen verwendet, um den Test einfach zu halten.
-d120: Dies gibt die Dauer des Tests an, nicht einschließlich Abkühlen oder Aufwärmen. Der Standardwert ist 10 Sekunden. Es empfiehlt sich jedoch, für jede ernsthafte Workload mindestens 60 Sekunden zu verwenden. In diesem Fall wurden 120 Sekunden verwendet, um jegliche Ausreißer zu minimieren.
-Suw: Deaktiviert das Zwischenspeichern von Software und Hardware (entspricht -Sh).
-D: Erfasst IOPS-Statistiken, z. B. die Standardabweichung, in Intervallen von Millisekunden (pro Thread, pro Ziel).
-L: Misst Latenzstatistiken.
-c5g: Legt die im Test verwendete Beispieldateigröße fest. Die Größe kann in Bytes, KiB, MiB, GiB oder Blöcken festgelegt werden. In diesem Fall wurde eine Zieldatei mit 5 GB verwendet.
Eine vollständige Liste der Parameter finden Sie im GitHub-Repository.
Verstehen der Umgebung
Die Leistung hängt stark von Ihrer Umgebung ab. Also, wie sieht diese Umgebung aus? Die Spezifikation umfasst einen Azure Stack HCI-Cluster mit Speicherpool und „Direkte Speicherplätze“ (S2D). Genauer gesagt gibt es fünf VMs: DC, Knoten1, Knoten2, Knoten3 und den Verwaltungsknoten. Der Cluster selbst ist ein Cluster mit drei Knoten und einer gespiegelten Dreiwege-Resilienzstruktur. Daher werden drei Datenkopien verwaltet. Jeder „Knoten“ im Cluster ist eine Standard_B2ms-VM mit einer maximalen IOPS-Anzahl von 1920. In jedem Knoten gibt es vier Premium-P30-SSD-Laufwerke mit einer maximalen IOPS-Anzahl von 5000. Schließlich hat jedes SSD-Laufwerk eine Speicherkapazität von 1 TB.
Sie generieren die Testdatei unter dem einheitlichen Namespace, den das freigegebene Clustervolume (FCV) bereitstellt (C:\ClusteredStorage), um den gesamten Laufwerkspool zu verwenden.
Hinweis
Die Beispielumgebung liegt ohne Hyper-V oder eine geschachtelte Virtualisierungsstruktur vor.
Wie Sie feststellen können, ist es durchaus möglich, unabhängig voneinander entweder die IOPS- oder die Bandbreitenobergrenze an der VM- oder Laufwerksgrenze zu erreichen. Daher ist es wichtig, die Größe und den Laufwerkstyp Ihres virtuellen Computers zu verstehen, da beide einen maximalen IOPS-Grenzwert und eine Bandbreitengrenze aufweisen. Dieses Wissen hilft Ihnen, Engpässe zu finden und Ihre Leistungsergebnisse zu verstehen. Weitere Informationen über die Größe, die für Ihre Workload geeignet sein kann, finden Sie in den folgenden Artikeln:
Verstehen der Ausgabe
Mit Ihrem Verständnis der Parameter und der Umgebung sind Sie nun in der Lage, die Ausgabe zu interpretieren. Ziel des vorherigen Tests war es, die IOPS-Anzahl ohne Rücksicht auf die Wartezeit (Latenz) zu maximieren. Auf diese Weise können Sie visuell erkennen, ob Sie die künstliche IOPS-Grenze in Azure erreichen. Wenn Sie die IOPS-Gesamtanzahl grafisch visualisieren möchten, verwenden Sie entweder Windows Admin Center oder den Task-Manager.
Das folgende Diagramm zeigt, wie der DISKSPD-Prozess in der vorliegenden Beispielumgebung aussieht. Es zeigt ein Beispiel für einen 1-MiB-Schreibvorgang von einem Nicht-Koordinatorknoten. Die Dreiwege-Resilienzstruktur führt, zusammen mit dem Vorgang von einem Nicht-Koordinatorknoten, zu zwei Netzwerkhops, wodurch die Leistung verringert wird. Wenn Sie sich Fragen, was ein Koordinatorknoten ist, seien Sie beruhigt! Sie werden dies im Abschnitt Zu beachtende Aspekte erfahren. Die roten Quadrate entsprechen den VM- und Laufwerksengpässen.

Nachdem Sie nun ein visuelles Verständnis erhalten haben, sollen nun die vier Hauptabschnitte der ausgegebenen TXT-Datei ausgewertet werden:
Eingabeeinstellungen
In diesem Abschnitt sind der Befehl, den Sie ausgeführt haben, die Eingabeparameter und weitere Details zum Testlauf beschrieben.
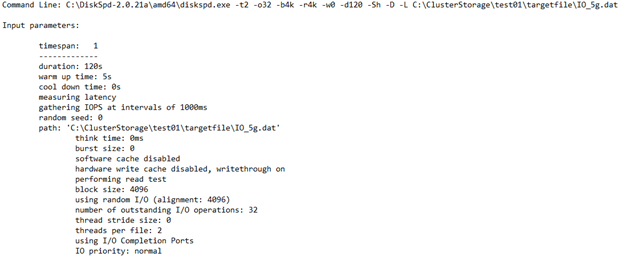
CPU-Auslastungsdetails
In diesem Abschnitt sind Informationen wie die Testzeit, die Anzahl der Threads, die Anzahl der verfügbaren Prozessoren und die durchschnittliche Auslastung jedes CPU-Kerns während des Tests aufgeführt. In diesem Fall gibt es zwei CPU-Kerne mit einer durchschnittlichen Nutzung von ca. 4,67 %.

E/A gesamt
Dieser Abschnitt hat drei Unterabschnitte. Der erste Abschnitt enthält die Gesamtleistungsdaten, die sowohl die Lese- als auch die Schreibvorgänge umfassen. Im zweiten und dritten Abschnitt sind die Lese- und Schreibvorgänge in eigene Kategorien aufgeteilt.
In diesem Beispiel können Sie sehen, dass die Gesamtzahl der E/A-Vorgänge während der Dauer von 120 Sekunden 234408 betragen hat. Daher ergibt sich: IOPS = 234408/120 = 1953,30. Die durchschnittliche Wartezeit betrug 32,763 Millisekunden, und der Durchsatz betrug 7,63 MiB/s. Aus früheren Informationen ist bekannt, dass sich die 1953,30 IOPS in der Nähe der 1920-IOPS-Einschränkung für die Standard_B2ms-VM befinden. Das glauben Sie nicht? Wenn Sie diesen Test mit anderen Parametern erneut ausführen, z. B. nach Vergrößern der Warteschlangentiefe, werden Sie feststellen, dass die Ergebnisse weiterhin bei dieser Anzahl gekappt sind.
Die letzten drei Spalten zeigen die Standardabweichung von IOPS mit 17,72 (vom -D-Parameter), die Standardabweichung der Latenz mit 20,994 Millisekunden (vom -L-Parameter) und den Dateipfad.
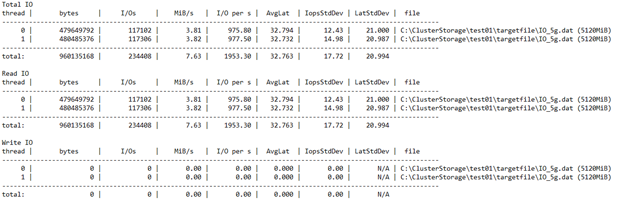
Anhand der Ergebnisse können Sie schnell feststellen, dass die Clusterkonfiguration miserabel ist. Sie können sehen, dass die Konfiguration die VM-Beschränkung von 1920 vor der SSD-Beschränkung von 5000 erreicht hat. Wäre Sie die Konfiguration durch den SSD-Datenträger statt durch die VM beschränkt, hätten Sie bis zu 20000 IOPS (4 Laufwerke * 5000) nutzen können, indem Sie die Testdatei über mehrere Laufwerke verteilen.
Schließlich müssen Sie entscheiden, welche Werte für ihre jeweilige Workload akzeptabel sind. In der folgenden Abbildung sind einige wichtige Beziehungen veranschaulicht, anhand denen Sie die Kompromisse einordnen können:
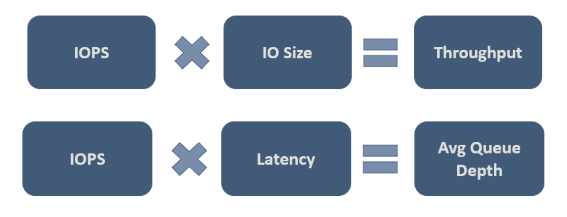
Die zweite Beziehung in der Abbildung ist wichtig, und sie wird manchmal als Littles Gesetz bezeichnet. Das Gesetz fußt auf der Idee, dass es drei Merkmale gibt, die das Prozessverhalten steuern, und dass nur ein Merkmal geändert werden muss, um die beiden anderen Merkmale und damit den gesamten Prozess zu beeinflussen. Und daher haben Sie, wenn Sie mit der Leistung Ihres Systems unzufrieden sind, drei Freiheitsgrade, diese Leistung zu beeinflussen. Littles Gesetz bestimmt, dass in diesem Beispiel IOPS der „Durchsatz“ (E/A-Vorgänge pro Sekunde), Latenz (Wartezeit) die „Warteschlangenzeit“ und Warteschlangentiefe das „Inventar“ ist.
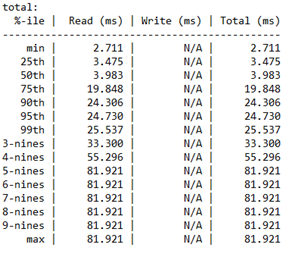
Analyse der Wartezeitperzentile
In diesem letzten Abschnitt sind die Wartezeitperzentile pro Vorgangstyp der Speicherleistung vom Minimalwert bis zum Maximalwert aufgeführt.
Dieser Abschnitt ist wichtig, weil er die „Qualität“ Ihres IOPS bestimmt. Er zeigt, für wie viele der E/A-Operationen ein bestimmter Wartezeitwert (Latenzwert) erreicht werden konnte. Es liegt an Ihnen, die akzeptable Wartezeit für dieses Quantil festzulegen.
Zudem beziehen sich die „nines“ (Neunen) auf die Anzahl der Neunen. Beispielsweise entspricht „3-nines“ dem 99. Perzentil. Die Anzahl der Neunen gibt an, wie viele E/A-Vorgänge in diesem Perzentil ausgeführt wurden. Schließlich wird ein Punkt erreicht, ab dem es nicht mehr sinnvoll ist, die Wartezeitwerte zu berücksichtigen. In diesem Fall können Sie sehen, dass die Wartezeitwerte nach „4-nines“ konstant bleiben. An diesem Punkt basiert der Wartezeitwert nur auf einem E/A-Vorgang aus den 234408 Vorgängen.





Zu beachtende Aspekte
Nachdem Sie nun begonnen haben, DISKSPD zu verwenden, gibt es einige Dinge zu beachten, um Testergebnisse für die echte Welt zu erhalten. Dazu gehört es, Folgendes genau im Auge zu haben: die von Ihnen festgelegten Parameter, die Speicherplatzintegrität und -variablen, die FCV-Eigentümerschaft und der Unterschied zwischen DISKSPD und Kopieren einer Datei (Dateikopie).
DISKSPD im Vergleich zur echten Welt
Der künstliche Test mit DISKSPD liefert Ihnen relativ vergleichbare Ergebnisse für Ihre echte Workload. Sie müssen jedoch genau auf die Parameter, die Sie festlegen, und darauf achten, ob diese Ihrem echten Szenario entsprechen. Es ist unerlässlich zu wissen, dass synthetische Workloads niemals perfekt die echte Workload Ihrer jeweils bereitgestellten Anwendung darstellen.
Vorbereitung
Bevor Sie einen DISKSPD-Test ausführen, gibt es einige empfohlene Aktionen, die ausgeführt werden sollten. Dazu gehören das Verifizieren der Integrität des Speicherplatzes, das Überprüfen Ihrer Ressourcennutzung, damit der Test nicht durch ein anderes Programm gestört wird, und das Vorbereiten eines Leistungs-Managers, wenn Sie zusätzliche Daten sammeln möchten. Da in diesem Artikel das Ziel verfolgt wird, DISKSPD schnell zum Laufen zu bringen, wird aber nicht auf die Besonderheiten dieser Aktionen eingegangen. Weitere Informationen finden Sie unter Testen der Leistung von Speicherplätzen mithilfe synthetischer Workloads in Windows Server.
Variablen, die sich auf die Leistung auswirken
Die Speicherleistung ist eine heikle Sache. Das heißt, es gibt viele Variablen, die sich auf die Leistung auswirken können. Daher ist es wahrscheinlich, dass Sie auf eine Zahl stoßen, die nicht mit Ihren Erwartungen übereinstimmt. Nachstehend sind einige der Variablen aufgeführt, die die Leistung beeinflussen, wobei dies keine vollständige Liste ist:
- Netzwerkbandbreite
- Wahl des Resilienztyps
- Konfiguration des Speicherdatenträgers: NVME, SSD, HDD
- E/A-Puffer
- cache
- RAID-Konfiguration
- Netzwerkhops
- Festplattendrehzahlen
FCV-Eigentümerschaft
Ein Knoten wird als Volumebesitzer oder Koordinatorknoten bezeichnet (ein Nicht-Koordinator-Knoten wäre der Knoten, der kein bestimmtes Volume besitzt). Jedem Standardvolume ist ein Knoten zugewiesen, und die anderen Knoten können über Netzwerkhops auf dieses Standardvolume zugreifen, was zu einer geringeren Leistung führt (längere Wartezeit).
In ähnlicher Weise hat auch ein freigegebenes Clustervolume (FCV) einen „Besitzer“. Ein FCV ist jedoch „dynamisch“ in dem Sinn, dass bei jedem Neustart des Systems (RDP) ein Hop für das Volume erfolgt und sein Besitzer wechselt. Daher ist es wichtig, sich zu vergewissern, dass DISKSPD auf dem Koordinatorknoten ausgeführt wird, dem das FCV gehört. Ist dies nicht der Fall, müssen Sie die FCV-Eigentümerschaft möglicherweise manuell ändern.
So bestätigen Sie die FCV-Eigentümerschaft:
Überprüfen Sie die Eigentümerschaft, indem Sie den folgenden PowerShell-Befehl ausführen:
Get-ClusterSharedVolumeIst die CSV-Eigentümerschaft falsch (etwa wenn Sie sich auf Knoten1 befinden, aber Knote2 das FCV besitzt), verschieben Sie das FCV auf den richtigen Knoten, indem Sie den folgenden PowerShell-Befehl ausführen:
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
Dateikopie im Vergleich zu DISKSPD
Einige Leute sind der Meinung, dass sie eine „Speicherleistung testen“ können, indem sie eine riesige Datei kopieren und einfügen und dann messen, wie lange dieser Vorgang dauert. Der Hauptgrund für diese Vorgehensweise liegt wahrscheinlich darin, dass sie einfach und schnell ist. Die Idee ist nicht falsch in dem Sinne, dass eine bestimmte Workload getestet wird, aber es ist schwierig, diese Methode als „Testen der Speicherleistung“ zu kategorisieren.
Wenn es Ihr Ziel darin besteht, die Dateikopierleistung zu testen, dann könnte dies ein stichhaltiger Grund sein, diese Methode zu verwenden. Wenn Sie jedoch das Ziel haben, die Speicherleistung zu messen, ist diese Methode nicht zu empfehlen. Sie können sich den Dateikopierprozess so vorstellen, dass ein anderer Satz von „Parametern“ (etwa Warteschlange, Parallelisierung usw.) verwendet wird, der für Dateidienste typisch ist.
In der folgenden kurzen Zusammenfassung wird erläutert, warum die Verwendung einer Dateikopie zum Messen der Speicherleistung möglicherweise nicht die von Ihnen gewünschten Ergebnisse liefert:
Dateikopien sind möglicherweise nicht optimiert. Es gibt zwei Parallelitätsebenen, die auftreten können, eine intern und die andere extern. Intern wendet die CopyFileEx-Engine, wenn die Dateikopie für ein entferntes Ziel bestimmt ist, eine gewisse Parallelisierung an. Extern gibt es verschiedene Methoden des Aufrufens der CopyFileEx-Engine. Beispielsweise führt Datei-Explorer Kopiervorgänge in einem einzelnen Thread aus, wogegen Robocopy Kopiervorgänge in mehreren Threads ausführt. Aus diesen Gründen ist es wichtig zu wissen, ob die Auswirkungen des Tests das sind, wonach Sie suchen.
Jede Kopie hat zwei Seiten. Wenn Sie eine Datei kopieren und einfügen, verwenden Sie möglicherweise zwei Datenträger: den Quelldatenträger und den Zieldatenträger. Ist ein Datenträger langsamer als der andere, messen Sie im Wesentlichen die Leistung des langsameren Datenträgers. Es gibt andere Fälle, in denen die Kommunikation zwischen Quelle, Ziel und der Kopier-Engine die Leistung auf jeweils spezielle Weise beeinflussen kann.
Weitere Informationen hierzu finden Sie unter Verwenden einer Dateikopie zum Messen der Speicherleistung.
Experimente und übliche Workloads
Dieser Abschnitt enthält einige weitere Beispiele, Experimente und Workloadtypen.
Bestätigen des Koordinatorknotens
Wie bereits erwähnt, sehen Sie, wenn der virtuelle Computer, den Sie derzeit testen, nicht über die CSV verfügt, einen Leistungsabbruch (IOPS, Durchsatz und Latenz) im Gegensatz zum Testen, wenn der Knoten die CSV besitzt. Dies liegt daran, dass das System jedes Mal, wenn Sie einen E/A-Vorgang ausgeben, einen Netzwerkhop zum Koordinatorknoten vornimmt, um diesen Vorgang auszuführen.
Bei einem gespiegelten System mit drei Knoten und drei Wegen führen Schreibvorgänge immer zu einem Netzwerkhop, da die Daten auf allen Laufwerken auf den drei Knoten gespeichert werden müssen. Aus diesem Grund lassen Schreibvorgänge einen Netzwerkhop egal werden. Wenn Sie jedoch eine andere Resilienzstruktur verwenden, kann sich dies ändern.
Hier sehen Sie ein Beispiel:
- Wird auf dem lokalen Knoten ausgeführt: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- Wird auf nichtlocalen Knoten ausgeführt: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
Aus diesem Beispiel können Sie in den Ergebnissen, die in der folgenden Abbildung dargestellt sind, deutlich erkennen, dass die Wartezeit (Latenz) verkürzt, IOPS vergrößert und der Durchsatz erhöht wurde, wenn der Koordinatorknoten das FCV besitzt.

OLTP-Workload (Onlinetransaktionsverarbeitung)
OLTP-Workloadabfragen (Aktualisieren, Einfügen, Löschen) konzentrieren sich auf transaktionsorientierte Aufgaben. Im Vergleich zu OLAP (Online Analytical Processing, analytische Onlineverarbeitung) fällt bei OLTP die Speicherlatenz ins Gewicht. Da bei jedem Vorgang nur ein Bruchteil der E/A-Daten ausgegeben wird, ist es für Sie entscheidend, wie viele Vorgänge pro Sekunde erledigt werden können.
Sie können einen OLTP-Workloadtest so konzipieren, das er bestens für zufällige, kleine E/A-Leistung geeignet ist. Konzentrieren Sie sich bei diesen Tests darauf, wie weit Sie den Durchsatz unter Beibehaltung akzeptabler Wartezeiten (Latenzen) steigern können.
Die grundlegende Entwurfskonzept für diesen Workloadtest sollte mindestens Folgendes umfassen:
- Blockgröße von 8 KB => dies entspricht der von SQL Server für Datendateien verwendeten Seitengröße.
- 70 % Lesevorgänge, 30 % Schreibvorgänge => dies entspricht einem typischen OLTP-Verhalten.
OLAP-Workload (Online Analytical Processing)
OLAP-Workloads konzentrieren sich auf Datenabruf und -analyse, sodass Benutzer komplexe Abfragen durchführen können, um mehrdimensionale Daten zu extrahieren. Anders als bei OLTP sind diese Workloads nicht speicherlatenzabhängig. Bei diesen Workloads liegt der Schwerpunkt darauf, viele Vorgänge in eine Warteschlange zu stellen, ohne dass die Bandbreite eine große Rolle spielt. Im Ergebnis sind für OLAP-Workloads häufig längere Verarbeitungszeiten erforderlich.
Sie können einen OLAP-Workloadtest so konzipieren, das er bestens für sequenzielle, große E/A-Leistung geeignet ist. Konzentrieren Sie sich bei diesen Tests auf die Menge der pro Sekunde verarbeiteten Daten und nicht auf die Anzahl der IOPS. Latenzanforderungen sind ebenfalls weniger wichtig, dies ist aber subjektiv.
Die grundlegende Entwurfskonzept für diesen Workloadtest sollte mindestens Folgendes umfassen:
Blockgröße von 512 KB => dies entspricht der E/A-Größe, mit der SQL Server mittels der Read-Ahead-Methode einen Batch aus 64 Datenseiten für einen Tabellenscan lädt.
1 Thread pro Datei => derzeit müssen Sie Ihre Tests auf einen Thread pro Datei beschränken, da Probleme in DISKSPD auftreten können, wenn mehrere sequenzielle Threads getestet werden. Wenn Sie mehrere Threads, z. B. zwei, und den Parameter -s verwenden, beginnen die Threads nicht vorhersehbar, E/A-Vorgänge übereinander im selben Speicherort auszugeben. Dies liegt daran, dass für jeden Thread dessen eigener sequenzieller Offset nachverfolgt wird.
Es gibt zwei „Lösungen“, um dieses Problem zu beheben:
Die erste Lösung besteht darin, den Parameter -si zu verwenden. Mit diesem Parameter teilen sich beide Threads einen einzigen gesperrten Offset, sodass die Threads kooperativ ein einziges sequenzielles Muster für den Zugriff auf die Zieldatei ausgeben. Dadurch wird verhindert, dass irgendein Punkt in der Datei mehrmals verarbeitet wird. Da die Threads aber nach wie vor darum konkurrieren, ihre E/A-Vorgänge in die Warteschlange auszugeben, kann es sein, dass die Vorgänge nicht in der richtigen Reihenfolge eintreffen.
Diese Lösung funktioniert gut, wenn sich für einen Thread eine CPU-Beschränkung ergibt. Es kann sinnvoll sein, einen zweiten Thread auf einem zweiten CPU-Kern einzubinden, um dem CPU-System mehr Speicher-E/A bereitzustellen, um es besser auszulasten.
Die zweite Lösung besteht in der Verwendung von „-T<offset>“. Auf diese Weise können Sie die Offsetgröße (Inter-E/A-Abstand) zwischen E/A-Vorgängen angeben, die von verschiedenen Threads für dieselbe Zieldatei ausgeführt werden. Beispielsweise beginnen Threads normalerweise bei Offset 0, aber mit dieser Spezifikation können Sie die beiden Threads so zueinander versetzen, dass sie nicht überlappen. In jeder Multithread-Umgebung befinden sich die Threads wahrscheinlich in unterschiedlichen Abschnitten des Arbeitsziels, und dies ist eine Möglichkeit, diese Situation zu simulieren.
Nächste Schritte
Weitere Informationen und ausführliche Beispiele zum Optimieren Ihrer Resilienzeinstellungen finden Sie auch hier: