Strategien zur Datenbankentwicklung und -bereitstellung (C#)
von Scott Mitchell
Bei der erstmaligen Bereitstellung einer datengesteuerten Anwendung können Sie die Datenbank in der Entwicklungsumgebung blind in die Produktionsumgebung kopieren. Durch ausführen einer blinden Kopie in nachfolgenden Bereitstellungen werden jedoch alle daten überschrieben, die in die Produktionsdatenbank eingegeben werden. Stattdessen müssen beim Bereitstellen einer Datenbank die Änderungen, die seit der letzten Bereitstellung an der Entwicklungsdatenbank vorgenommen wurden, auf die Produktionsdatenbank angewendet werden. In diesem Tutorial werden diese Herausforderungen untersucht und verschiedene Strategien zur Unterstützung bei der Chronik und Anwendung der Änderungen an der Datenbank seit der letzten Bereitstellung bereitgestellt.
Einführung
Wie in den vorherigen Tutorials erläutert, umfasst die Bereitstellung einer ASP.NET Anwendung das Kopieren der relevanten Inhalte aus der Entwicklungsumgebung in die Produktionsumgebung. Die Bereitstellung ist kein einmaliges Ereignis, sondern ein Ereignis, das jedes Mal auftritt, wenn eine neue Version der Software veröffentlicht wird oder wenn Fehler oder Sicherheitsbedenken erkannt und behoben wurden. Wenn Sie ASP.NET Seiten, Images, JavaScript-Dateien und andere solche Dateien in die Produktionsumgebung kopieren, müssen Sie sich nicht darum kümmern, wie diese Datei seit der letzten Bereitstellung geändert wurde. Sie können die Datei blind in die Produktion kopieren und den vorhandenen Inhalt überschreiben. Leider erstreckt sich diese Einfachheit nicht auf die Bereitstellung der Datenbank.
Bei der erstmaligen Bereitstellung einer datengesteuerten Anwendung können Sie die Datenbank in der Entwicklungsumgebung blind in die Produktionsumgebung kopieren. Durch ausführen einer blinden Kopie in nachfolgenden Bereitstellungen werden jedoch alle daten überschrieben, die in die Produktionsdatenbank eingegeben werden. Stattdessen müssen beim Bereitstellen einer Datenbank die Änderungen , die seit der letzten Bereitstellung an der Entwicklungsdatenbank vorgenommen wurden, auf die Produktionsdatenbank angewendet werden. In diesem Tutorial werden diese Herausforderungen untersucht und verschiedene Strategien zur Unterstützung bei der Chronik und Anwendung der Änderungen an der Datenbank seit der letzten Bereitstellung bereitgestellt.
Die Herausforderungen beim Bereitstellen einer Datenbank
Bevor eine datengesteuerte Anwendung zum ersten Mal bereitgestellt wurde, gibt es nur eine Datenbank, nämlich die Datenbank in der Entwicklungsumgebung, weshalb Sie bei der erstmaligen Bereitstellung einer datengesteuerten Anwendung die Datenbank in der Entwicklungsumgebung blind in die Produktionsumgebung kopieren können. Sobald die Anwendung bereitgestellt wurde, gibt es jedoch zwei Kopien der Datenbank: eine in der Entwicklung und eine in der Produktion.
Zwischen Bereitstellungen können Entwicklungs- und Produktionsdatenbanken nicht mehr synchronisiert werden. Während das Schema der Produktionsdatenbank unverändert bleibt, kann sich das Schema der Entwicklungsdatenbank ändern, wenn neue Features hinzugefügt werden. Sie können Spalten, Tabellen, Sichten oder gespeicherte Prozeduren hinzufügen oder entfernen. Es kann auch wichtige Daten geben, die der Entwicklungsdatenbank hinzugefügt werden. Viele datengesteuerte Anwendungen enthalten Nachschlagetabellen, die mit hartcodierten, anwendungsspezifischen Daten aufgefüllt werden, die nicht vom Benutzer bearbeitet werden können. Beispielsweise kann eine Auktionswebsite über eine Dropdownliste mit Auswahlmöglichkeiten verfügen, die den Zustand des versteigerten Artikels beschreiben: Neu, Wie neu, gut und Fair. Anstatt diese Optionen direkt in der Dropdownliste hart zu codieren, ist es in der Regel besser, sie in einer Datenbanktabelle zu platzieren. Wenn während der Entwicklung der Tabelle eine neue Bedingung mit dem Namen Poor hinzugefügt wird, muss bei der Bereitstellung der Anwendung dieser Datensatz der Nachschlagetabelle in der Produktionsdatenbank hinzugefügt werden.
Im Idealfall würde die Bereitstellung der Datenbank das Kopieren der Datenbank von der Entwicklung in die Produktion umfassen. Beachten Sie jedoch, dass die Produktionsdatenbank nach der Bereitstellung der Anwendung und der Wiederaufnahme der Entwicklung mit echten Daten von echten Benutzern aufgefüllt wird. Wenn Sie also die Datenbank bei der nächsten Bereitstellung einfach aus der Entwicklung in die Produktion kopieren würden, würden Sie die Produktionsdatenbank überschreiben und ihre vorhandenen Daten verlieren. Das Nettoergebnis ist, dass die Bereitstellung der Datenbank darauf hinaus läuft, die Änderungen anzuwenden, die seit der letzten Bereitstellung an der Entwicklungsdatenbank vorgenommen wurden.
Da das Bereitstellen einer Datenbank das Anwenden der Änderungen am Schema und möglicherweise der Daten seit der letzten Bereitstellung umfasst, muss ein Änderungsverlauf beibehalten (oder zum Zeitpunkt der Bereitstellung bestimmt werden), damit diese Änderungen auf die Produktion angewendet werden können. Es gibt eine Vielzahl von Techniken zum Verwalten und Anwenden von Änderungen am Datenmodell.
Definieren der Baseline
Um die Änderungen an der Datenbank Ihrer Anwendung beizubehalten, benötigen Sie einen Startzustand, eine Baseline, auf die die Änderungen angewendet werden. In einem Extrem kann der Anfangszustand eine leere Datenbank ohne Tabellen, Sichten oder gespeicherte Prozeduren sein. Eine solche Baseline führt zu einem umfangreichen Änderungsprotokoll, da es die Erstellung aller Tabellen, Sichten und gespeicherten Prozeduren der Datenbank zusammen mit allen Änderungen umfassen muss, die nach der ersten Bereitstellung vorgenommen wurden. Am anderen Ende des Spektrums können Sie die Baseline als Version der Datenbank festlegen, die ursprünglich in der Produktionsumgebung bereitgestellt wird. Diese Auswahl führt zu einem viel kleineren Änderungsprotokoll, da es nur die Änderungen enthält, die nach der ersten Bereitstellung an der Datenbank vorgenommen wurden. Dies ist der Ansatz, den ich bevorzuge. Und natürlich können Sie einen eher mittleren Ansatz wählen, indem Sie die Baseline als einen Punkt zwischen der ersten Erstellung der Datenbank und dem Zeitpunkt der ersten Bereitstellung der Datenbank definieren.
Nachdem Sie eine Baseline ausgewählt haben, sollten Sie ein SQL-Skript generieren, das ausgeführt werden kann, um die Baselineversion neu zu erstellen. Ein solches Skript ermöglicht es, die Basisversion der Datenbank schnell neu zu erstellen. Diese Funktionalität ist besonders nützlich in größeren Projekten, in denen mehrere Entwickler an dem Projekt arbeiten, oder in zusätzlichen Umgebungen, z. B. Tests oder Stagings, die jeweils eine eigene Kopie der Datenbank benötigen.
Es stehen eine Vielzahl von Tools zur Verfügung, um ein SQL-Skript der Basisversion zu generieren. In SQL Server Management Studio (SSMS) können Sie mit der rechten Maustaste auf die Datenbank klicken, zum Untermenü Aufgaben wechseln und die Option Skripts generieren auswählen. Dadurch wird der Skript-Assistent gestartet, den Sie anweisen können, eine Datei zu generieren, die die SQL-Befehle zum Erstellen Ihrer Datenbankobjekte enthält. Eine weitere Option ist der Datenbankveröffentlichungs-Assistent, der die SQL-Befehle generieren kann, um nicht nur das Datenbankschema, sondern auch die Daten in den Datenbanktabellen zu erstellen. Der Datenbankveröffentlichungs-Assistent wurde im Tutorial Bereitstellen einer Datenbank ausführlich untersucht. Unabhängig davon, welches Tool Sie verwenden, sollten Sie letztendlich über eine Skriptdatei verfügen, die Sie verwenden können, um die Baselineversion Ihrer Datenbank neu zu erstellen, falls dies erforderlich ist.
Dokumentieren der Datenbankänderungen in Prosa
Die einfachste Möglichkeit, ein Protokoll von Änderungen am Datenmodell während der Entwicklungsphase zu verwalten, besteht darin, die Änderungen in Prosa aufzuzeichnen. Wenn Sie z. B. während der Entwicklung einer bereits bereitgestellten Anwendung der Tabelle eine neue Spalte Employees hinzufügen, eine Spalte aus der Orders Tabelle entfernen und eine neue Tabelle hinzufügen (ProductCategories), würden Sie eine Textdatei oder ein Microsoft Word Dokument mit dem folgenden Verlauf verwalten:
| Änderungsdatum | Ändern von Details |
|---|---|
| 2009-02-03: | Spalte DepartmentID (int, NOT NULL) zur Employees Tabelle hinzugefügt. Es wurde eine Fremdschlüsseleinschränkung von Departments.DepartmentID zu Employees.DepartmentIDhinzugefügt. |
| 2009-02-05: | Spalte TotalWeight aus der Orders Tabelle entfernt. Daten, die bereits in zugeordneten OrderDetails Datensätzen erfasst wurden. |
| 2009-02-12: | ProductCategories Die Tabelle wurde erstellt. Es gibt drei Spalten: ProductCategoryID (int, , NOT NULLIDENTITY), CategoryName (nvarchar(50), NOT NULL), und Active (bit, NOT NULL). Es wurde eine Primärschlüsseleinschränkung zu ProductCategoryIDund der Standardwert 1 zu Activehinzugefügt. |
Dieser Ansatz hat eine Reihe von Nachteilen. Für den Anfang gibt es keine Hoffnung auf Automatisierung. Immer wenn diese Änderungen auf eine Datenbank angewendet werden müssen , z. B. wenn die Anwendung bereitgestellt wird, muss ein Entwickler jede Änderung einzeln manuell implementieren. Wenn Sie außerdem eine bestimmte Version der Datenbank aus der Baseline mithilfe des Änderungsprotokolls rekonstruieren müssen, nimmt dies immer mehr Zeit in Anspruch, wenn die Größe des Protokolls zunimmt. Ein weiterer Nachteil dieser Methode ist, dass die Klarheit und Detailebene jedes Änderungsprotokolleintrags der Person überlassen wird, die die Änderung erfasst. In einem Team mit mehreren Entwicklern können einige detailliertere, lesbarere oder präzisere Einträge erstellen als andere. Auch Tippfehler und andere Fehler bei der Eingabe von Daten sind möglich.
Der Hauptvorteil der Dokumentation der Datenbankänderungen in Prosa ist die Einfachheit. Sie benötigen keine Kenntnisse mit der SQL-Syntax zum Erstellen und Ändern von Datenbankobjekten. Stattdessen können Sie die Änderungen in Prosa aufzeichnen und über SQL Server Management Studio grafische Benutzeroberfläche implementieren.
Die Verwaltung Ihres Änderungsprotokolls in Prosa ist zugegebenermaßen nicht sehr anspruchsvoll und funktioniert nicht gut mit bestimmten Projekten, z. B. projekten mit großem Umfang, häufigen Änderungen am Datenmodell oder mehreren Entwicklern. Ich habe jedoch gesehen, dass dieser Ansatz in kleinen Einzelprojekten recht gut funktioniert, die nur gelegentlich Änderungen am Datenmodell aufweisen und bei denen der Soloentwickler keinen starken Hintergrund in der SQL-Syntax zum Erstellen und Ändern von Datenbankobjekten hat.
Hinweis
Während die Informationen im Änderungsprotokoll technisch nur bis zur Bereitstellung benötigt werden, empfehle ich, einen Verlauf der Änderungen zu führen. Anstatt jedoch eine einzelne, ständig wachsende Änderungsprotokolldatei zu verwalten, sollten Sie für jede Datenbankversion eine andere Änderungsprotokolldatei verwenden. In der Regel sollten Sie die Datenbank bei jeder Bereitstellung versionieren. Indem Sie ein Protokoll mit Änderungsprotokollen verwalten, können Sie ab der Baseline eine beliebige Datenbankversion neu erstellen, indem Sie die Änderungsprotokollskripts ab Version 1 ausführen und fortfahren, bis Sie die neu zu erstellende Version erreicht haben.
Aufzeichnen der SQL-Änderungsanweisungen
Der Hauptnachteil der Verwaltung des Änderungsprotokolls in Prosa ist die fehlende Automatisierung. Im Idealfall ist die Implementierung der Datenbankänderungen an der Produktionsdatenbank zur Bereitstellungszeit so einfach wie das Klicken auf eine Schaltfläche, um ein Skript auszuführen, anstatt eine Liste mit Anweisungen manuell ausführen zu müssen. Eine solche Automatisierung ist möglich, indem ein Änderungsprotokoll verwaltet wird, das die SQL-Befehle enthält, die zum Ändern des Datenmodells verwendet werden.
Die SQL-Syntax enthält eine Reihe von Anweisungen zum Erstellen und Ändern verschiedener Datenbankobjekte. Beispielsweise erstellt die CREATE TABLE-Anweisung bei Ausführung eine neue Tabelle mit den angegebenen Spalten und Einschränkungen. Die ALTER TABLE-Anweisung ändert eine vorhandene Tabelle und fügt deren Spalten oder Einschränkungen hinzu, entfernt oder ändert sie. Es gibt auch Anweisungen zum Erstellen, Ändern und Löschen von Indizes, Sichten, benutzerdefinierten Funktionen, gespeicherten Prozeduren, Triggern und anderen Datenbankobjekten.
Kehren Sie zu unserem früheren Beispiel zurück, dem Image, dass Sie während der Entwicklung einer bereits bereitgestellten Anwendung der Employees Tabelle eine neue Spalte hinzufügen, eine Spalte aus der Orders Tabelle entfernen und eine neue TabelleProductCategories () hinzufügen. Solche Aktionen führen zu einer Änderungsprotokolldatei mit den folgenden SQL-Befehlen:
-- Add the DepartmentID column
ALTER TABLE [Employees] ADD [DepartmentID]
int NOT NULL
-- Add a foreign key constraint between Departments.DepartmentID and Employees.DepartmentID
ALTER TABLE [Employees] ADD
CONSTRAINT [FK_Departments_DepartmentID]
FOREIGN
KEY ([DepartmentID])
REFERENCES
[Departments] ([DepartmentID])
-- Remove TotalWeight column from Orders
ALTER TABLE [Orders] DROP COLUMN
[TotalWeight]
-- Create the ProductCategories table
CREATE TABLE [ProductCategories]
(
[ProductCategoryID]
int IDENTITY(1,1) NOT NULL,
[CategoryName]
nvarchar(50) NOT NULL,
[Active]
bit NOT NULL CONSTRAINT [DF_ProductCategories_Active] DEFAULT
((1)),
CONSTRAINT
[PK_ProductCategories] PRIMARY KEY CLUSTERED ( [ProductCategoryID])
)
Das Übertragen dieser Änderungen zur Bereitstellungszeit in die Produktionsdatenbank ist ein 1-Klick-Vorgang: Öffnen Sie SQL Server Management Studio, stellen Sie eine Verbindung mit Ihrer Produktionsdatenbank her, öffnen Sie ein Fenster Neue Abfrage, fügen Sie den Inhalt des Änderungsprotokolls ein, und klicken Sie auf Ausführen, um das Skript auszuführen.
Verwenden eines Vergleichstools zum Synchronisieren der Datenmodelle
Das Dokumentieren von Datenbankänderungen in Prosa ist einfach, aber die Implementierung der Änderungen erfordert, dass ein Entwickler jede Änderung an der Produktionsdatenbank einzeln vor nimmt. Die Dokumentation der SQL-Befehle zur Änderung macht die Implementierung dieser Änderungen in der Produktionsdatenbank so einfach und schnell wie das Klicken auf eine Schaltfläche, erfordert jedoch das Erlernen und Beherrschen der SQL-Anweisungen und der Syntax zum Erstellen und Ändern von Datenbankobjekten. Datenbankvergleichstools nutzen beide Ansätze am besten und verwerfen die schlechtesten.
Ein Datenbankvergleichstool vergleicht das Schema oder die Daten von zwei Datenbanken und zeigt einen Zusammenfassungsbericht an, der zeigt, wie sich die Datenbanken unterscheiden. Anschließend können Sie mit einem Klick auf eine Schaltfläche die SQL-Befehle zum Synchronisieren eines oder mehrerer Datenbankobjekte generieren. Kurz gesagt, Sie können ein Datenbankvergleichstool verwenden, um die Entwicklungs- und Produktionsdatenbanken zur Bereitstellungszeit zu vergleichen und eine Datei zu generieren, die die SQL-Befehle enthält, die bei der Ausführung die Änderungen auf das Schema der Produktionsdatenbank anwenden, sodass es das Schema der Entwicklungsdatenbank widerspiegelt.
Es gibt eine Vielzahl von Datenbankvergleichstools von Drittanbietern, die von vielen verschiedenen Anbietern angeboten werden. Ein Beispiel hierfür ist SQL Compare von Red Gate Software. Lassen Sie uns den Prozess der Verwendung von SQL Compare durchlaufen, um die Schemas der Entwicklungs- und Produktionsdatenbanken zu vergleichen und zu synchronisieren.
Hinweis
Zum Zeitpunkt dieses Schreibens war die aktuelle Version von SQL Compare Version 7.1, wobei die Standard Edition 395 USD kostete. Sie können eine kostenlose 14-tägige Testversion herunterladen.
Wenn SQL Compare startet, wird das Dialogfeld Vergleichsprojekte mit den gespeicherten SQL-Vergleichsprojekten geöffnet. Erstellen Sie ein neues Projekt. Dadurch wird der Projektkonfigurations-Assistent gestartet, der zur Eingabe von Informationen zu den zu vergleichenden Datenbanken auffordert (siehe Abbildung 1). Geben Sie die Informationen für die Datenbanken der Entwicklungs- und Produktionsumgebung ein.
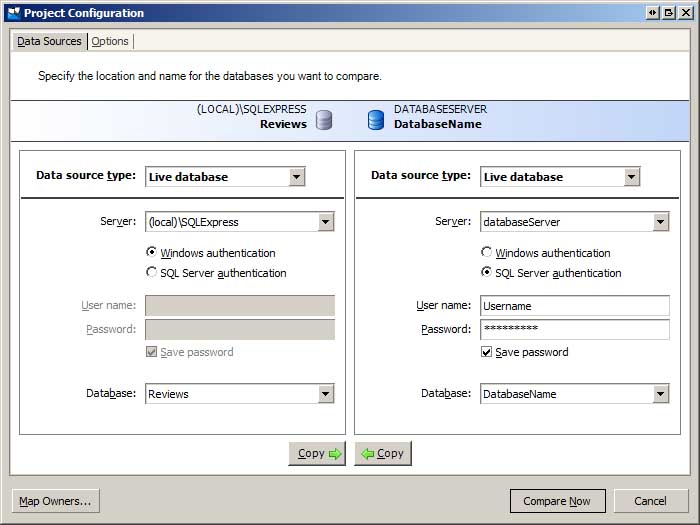
Abbildung 1: Vergleichen der Entwicklungs- und Produktionsdatenbanken (Klicken Sie hier, um das bild in voller Größe anzuzeigen)
{kind=link}
Hinweis
Wenn ihre Entwicklungsumgebungsdatenbank eine SQL Express Edition-Datenbankdatei im App_Data Ordner Ihrer Website ist, müssen Sie die Datenbank im SQL Server Express Datenbankserver registrieren, um sie im Dialogfeld in Abbildung 1 auswählen zu können. Die einfachste Möglichkeit besteht darin, SQL Server Management Studio (SSMS) zu öffnen, eine Verbindung mit dem SQL Server Express Datenbankserver herzustellen und die Datenbank anzufügen. Wenn Sie SSMS nicht auf Ihrem Computer installiert haben, können Sie die kostenlose SQL Server Management Studio herunterladen und installieren.
Neben der Auswahl der zu vergleichenden Datenbanken können Sie auch eine Vielzahl von Vergleichseinstellungen auf der Registerkarte Optionen angeben. Eine Option, die Sie möglicherweise aktivieren möchten, ist die Option "Einschränkungs- und Indexnamen ignorieren". Erinnern Sie sich daran, dass wir im vorherigen Tutorial die Anwendungsdienste-Datenbankobjekte den Entwicklungs- und Produktionsdatenbanken hinzugefügt haben. Wenn Sie das aspnet_regsql.exe Tool verwendet haben, um diese Objekte in der Produktionsdatenbank zu erstellen, werden Sie feststellen, dass sich der Primärschlüssel und die Namen eindeutiger Einschränkungen zwischen den Entwicklungs- und Produktionsdatenbanken unterscheiden. Daher weist SQL Compare alle Anwendungsdiensttabellen als unterschiedlich aus. Sie können entweder die Option "Einschränkungs- und Indexnamen ignorieren" deaktiviert lassen und die Einschränkungsnamen synchronisieren oder SQL Compare anweisen, diese Unterschiede zu ignorieren.
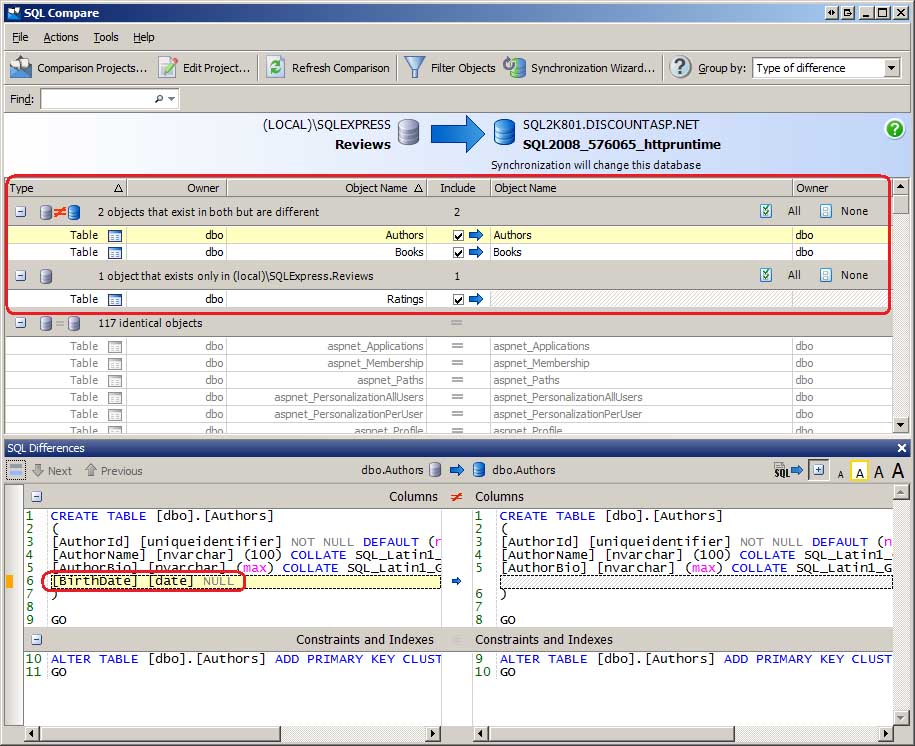
Nachdem Sie die zu vergleichenden Datenbanken ausgewählt haben (und die Vergleichsoptionen überprüft haben), klicken Sie auf die Schaltfläche Jetzt vergleichen, um mit dem Vergleich zu beginnen. In den nächsten Sekunden untersucht SQL Compare die Schemas der beiden Datenbanken und generiert einen Bericht darüber, wie sie sich unterscheiden. Ich habe absichtlich einige Änderungen an der Entwicklungsdatenbank vorgenommen, um zu zeigen, wie solche Abweichungen in der SQL-Vergleichsschnittstelle festgestellt werden. Wie Abbildung 2 zeigt, habe ich der Authors Tabelle eine BirthDate Spalte hinzugefügt, die ISBN Spalte aus der Books Tabelle entfernt und eine neue Tabelle hinzugefügt, die es Benutzern ermöglicht, Ratingsdie überprüften Bücher zu bewerten.
Hinweis
Die in diesem Tutorial vorgenommenen Datenmodelländerungen wurden mithilfe eines Datenbankvergleichstools veranschaulicht. Sie werden diese Änderungen in der Datenbank in zukünftigen Tutorials nicht finden.
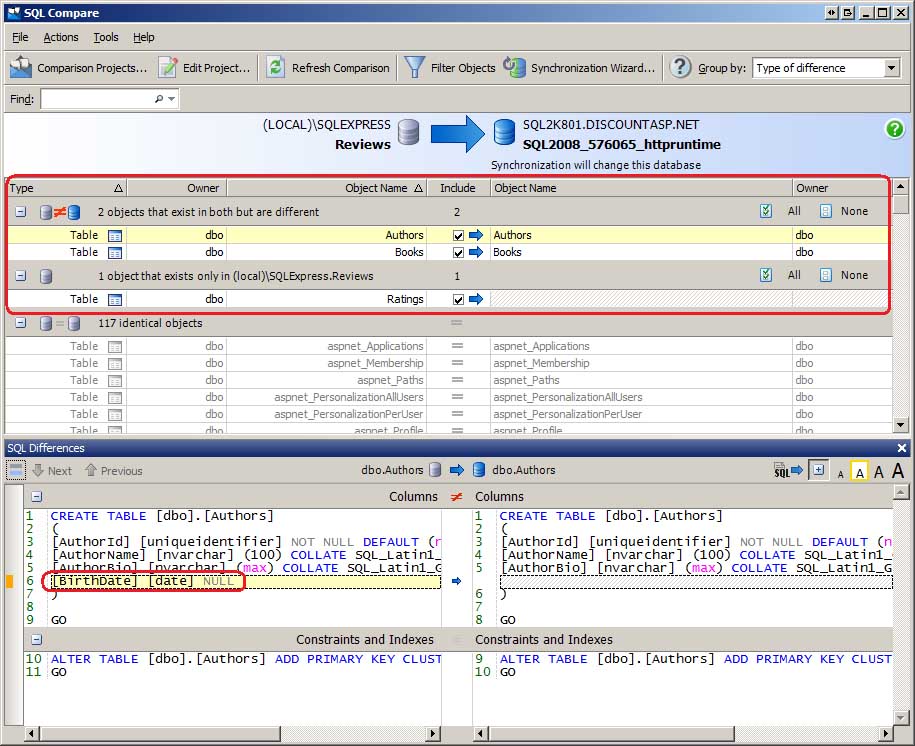
Abbildung 2: SQL-Vergleich Listen die Unterschiede zwischen den Entwicklungs- und Produktionsdatenbanken (klicken, um das bild in voller Größe anzuzeigen)
{kind=link}
SQL Compare unterteilt die Datenbankobjekte in Gruppen. Dadurch wird schnell angezeigt, welche Objekte in beiden Datenbanken vorhanden sind, aber unterschiedlich sind, welche Objekte in einer Datenbank vorhanden sind, aber nicht in der anderen, und welche Objekte identisch sind. Wie Sie sehen können, gibt es zwei Objekte, die in beiden Datenbanken vorhanden sind, aber unterschiedlich sind: die Tabelle, in der Authors eine Spalte hinzugefügt wurde, und die Tabelle, in der Books eines entfernt wurde. Es gibt ein Objekt, das nur in der Entwicklungsdatenbank vorhanden ist, nämlich die neu erstellte Ratings Tabelle. Und es gibt 117 Objekte, die in beiden Datenbanken identisch sind.
Wenn Sie ein Datenbankobjekt auswählen, wird das Fenster SQL-Unterschiede angezeigt, in dem angezeigt wird, wie sich diese Objekte unterscheiden. Im Fenster SQL-Unterschiede, das unten in Abbildung 2 angezeigt wird, wird hervorgehoben, dass die Authors Tabelle in der Entwicklungsdatenbank über die BirthDate Spalte verfügt, die in der Tabelle in der Authors Produktionsdatenbank nicht gefunden wird.
Nachdem Sie die Unterschiede überprüft und die Objekte ausgewählt haben, die Sie synchronisieren möchten, besteht der nächste Schritt darin, die SQL-Befehle zu generieren, die zum Aktualisieren des Schemas der Produktionsdatenbank erforderlich sind, um mit der Entwicklungsdatenbank übereinzupassen. Dies erfolgt über den Synchronisierungs-Assistenten. Der Synchronisierungs-Assistent bestätigt, welche Objekte synchronisiert werden sollen, und fasst den Aktionsplan zusammen (siehe Abbildung 3). Sie können die Datenbanken sofort synchronisieren oder ein Skript mit den SQL-Befehlen generieren, das nach Belieben ausgeführt werden kann.

Abbildung 3: Verwenden des Synchronisierungs-Assistenten zum Synchronisieren Ihrer Datenbankschemas (Klicken Sie hier, um das vollständige Bild anzuzeigen)
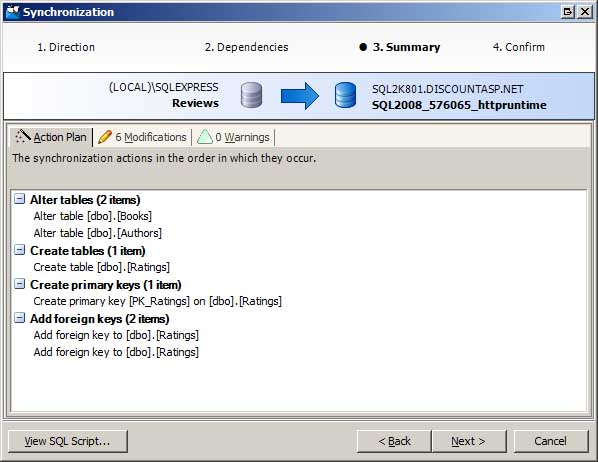{kind=link}
Datenbankvergleichstools wie Red Gate Software s SQL Compare machen das Anwenden der Änderungen am Entwicklungsdatenbankschema auf die Produktionsdatenbank so einfach wie mit Einem Klick.
Hinweis
SQL Compare vergleicht und synchronisiert zwei Datenbankschemas. Leider werden die Daten nicht in zwei Datenbanktabellen verglichen und synchronisiert. Red Gate Software bietet ein Produkt namens SQL Data Compare an, das die Daten zwischen zwei Datenbanken vergleicht und synchronisiert, aber es ist ein separates Produkt von SQL Compare und kostet weitere 395 USD.
Offline schalten der Anwendung während der Bereitstellung
Wie wir in diesen Tutorials gesehen haben, ist die Bereitstellung ein Prozess, der mehrere Schritte umfasst: Kopieren der ASP.NET Seiten, master Seiten, CSS-Dateien, JavaScript-Dateien, Images und anderer erforderlicher Inhalte aus der Entwicklungsumgebung in die Produktionsumgebung; Kopieren der produktionsumgebungsspezifischen Konfigurationsinformationen bei Bedarf und Anwenden der Änderungen auf das Datenmodell seit der letzten Bereitstellung. Abhängig von der Anzahl der Dateien und der Komplexität ihrer Datenbankänderungen können diese Schritte zwischen einigen Sekunden und mehreren Minuten dauern. Während dieses Fensters befindet sich die Webanwendung im Fluss, und benutzer, die die Website besuchen, können Fehler oder unerwartetes Verhalten auftreten.
Beim Bereitstellen einer Website ist es am besten, die Webanwendung "offline" zu schalten, bis die Bereitstellung abgeschlossen ist. Die Anwendung offline zu schalten (und nach Abschluss des Bereitstellungsprozesses wieder hochzuladen) ist so einfach wie das Hochladen einer Datei und das anschließende Löschen einer Datei. Ab ASP.NET 2.0 wird die gesamte Website durch das bloße Vorhandensein einer Datei mit dem Namen app_offline.htm im Stammverzeichnis der Anwendung "offline". Jede Anforderung an eine ASP.NET Seite auf dieser Website wird automatisch mit dem Inhalt der app_offline.htm Datei beantwortet. Sobald diese Datei entfernt wurde, wird die Anwendung wieder online.
Das Offlinestellen einer Anwendung während der Bereitstellung ist dann so einfach wie das Hochladen einer app_offline.htm Datei in das Stammverzeichnis der Produktionsumgebung vor Beginn des Bereitstellungsprozesses und das löschen (oder in etwas anderes umbenennen), nachdem die Bereitstellung abgeschlossen ist. Weitere Informationen zu diesem Verfahren finden Sie in John Petersons Artikel Taking an ASP.NET Application Offline.
Zusammenfassung
Die Standard Herausforderung bei der Bereitstellung eines datengesteuerten Anwendungscenters rund um die Bereitstellung der Datenbank. Da es zwei Versionen der Datenbank gibt - eine in der Entwicklungsumgebung und eine in der Produktionsumgebung -, können diese beiden Datenbankschemas nicht mehr synchron sein, wenn neue Features in der Entwicklung hinzugefügt werden. Darüber hinaus können Sie die Produktionsdatenbank nicht mit der geänderten Entwicklungsdatenbank überschreiben, da die Produktionsdatenbank nicht mit der geänderten Entwicklungsdatenbank aufgefüllt wird, da Sie die Dateien, aus denen die Anwendung besteht (die ASP.NET Seiten, Bilddateien usw.) nicht mit der geänderten Entwicklungsdatenbank überschreiben können. Stattdessen müssen bei der Bereitstellung einer Datenbank die genauen Änderungen implementiert werden, die seit der letzten Bereitstellung an der Entwicklungsdatenbank in der Produktionsdatenbank vorgenommen wurden.
In diesem Tutorial wurden drei Techniken zum Verwalten und Anwenden eines Protokolls mit Datenbankänderungen untersucht. Der einfachste Ansatz besteht darin, die Änderungen in der Prosa aufzuzeichnen. Diese Taktik macht die Implementierung dieser Änderungen in der Produktionsdatenbank zwar manuell, erfordert jedoch keine Kenntnisse der SQL-Befehle zum Erstellen und Ändern von Datenbankobjekten. Ein komplexerer Ansatz, der in größeren Projekten oder Projekten mit mehreren Entwicklern wesentlich besser geeignet ist, besteht darin, die Änderungen als eine Reihe von SQL-Befehlen aufzuzeichnen. Dadurch wird das Rollout dieser Änderungen an der Zieldatenbank erheblich erhöht. Das Beste aus beiden Ansätzen kann mit einem Datenbankvergleichstool wie z. B. Red Gate Softwares SQL Compare erreicht werden.
Dieses Tutorial schließt unseren Fokus auf die Bereitstellung einer datengesteuerten Anwendung ab. Im nächsten Satz von Tutorials wird untersucht, wie auf Fehler in der Produktionsumgebung reagiert werden kann. Wir sehen uns an, wie Sie anstelle des gelben Bildschirms des Todes eine benutzerfreundliche Fehlerseite anzeigen. Außerdem erfahren Sie, wie Sie die Fehlerdetails protokollieren und Sie benachrichtigen können, wenn solche Fehler auftreten.
Viel Spaß beim Programmieren!