Private Cloud Principles, Patterns and Concepts (de-DE)
Ein wesentliches Ziel ist es, IT-Organisationen den sinnvollen Einsatz der Prinzipien und Konzepte der Referenz-Architektur für Private Cloud zu ermöglichen, um darauf aufbauend Infrastructure as a Service (IaaS ) anzubieten, sodass jede auf dieser Infrastruktur gehostete Arbeitslast automatisch eine Reihe von Eigenschaften einer Cloud erbt. Im Wesentlichen sollten die Verbraucher die Wahrnehmung einer unendlichen Kapazität und einer ständigen Verfügbarkeit der verwendeten Dienste besitzen. Ebenfalls sollte sie einen eindeutigen Zusammenhang zwischen der Anzahl der verwendeten Dienste und dem Preis für diese Dienste erkennen.http://blogs.technet.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-85-24-metablogapi/5658.image_5F00_64BCDD48.png
{kind=link}
Um das zu erreichen erfordert es die Virtualisierung aller Elemente der Infrastruktur (Rechenpower [Verarbeitung, Arbeitsspeicher], Netzwerk, Speicher) in ein Gesamtgefüge welches einem Container oder ein virtuellen Maschine präsentiert wird. Es erfordert auch die Annahme eines Service-Provider Ansatzes durch die IT-Organisation für die Bereitstellung der Infrastruktur und verlangt einen hohen Reifegrad der IT-Service-Management Prozesse. Darüber hinaus müssen die meisten operativen Funktionen automatisiert werden, um die Varianz soweit wie möglich zu minimieren und gleichzeitig vorhersagbare Modelle zur Vereinfachung des Managements zu erstellen.
Letztendlich ist es von entscheidender Bedeutung sicherzustellen, dass die Infrastruktur auf eine Art und Weise entworfen wird, die es ermöglicht das Dienste, Anwendungen und Arbeitslasten, unabhängig von wo sie ursprünglich bezogen oder bereitgestellt wurden, geliefert werden können. So ist es eines der Hauptziele die Portabilität zwischen einer Private Cloud des Kunden und externen Public Cloud Plattformen und Anbietern zu ermöglichen.

Daher erfordert es einen starken Service-Qualität- und Verbraucher-orientierten Ansatz im Gegensatz zu einem Funktions- oder Fähigkeiten-orientierten Ansatz Obwohl dieser Ansatz nicht orthogonal zu anderen Ansätzen ist, mag es zunächst kontraintuitiv erscheinen. Diese Dokumentation definiert die Prozesselemente für die Planung, den Aufbau und das Management einer Private Cloud Umgebung mit einem allgemeinen Satz von Best Practices.
Hinweis:
Dieses Dokument ist Teil einer Sammlung von Dokumenten, die gemeinsam eine Ref beschreiben. Die Lösung für Private Cloud ist ein gemeinschaftliches Projekt innerhalb der Microsoft Community. Bitte zögern Sie nicht dieses Dokument zu bearbeiten, um die Qualität zu verbessern. Wenn Sie für Ihre Arbeit an der Verbesserung dieses Dokumentes anerkannt werden möchten, geben Sie bitte Ihren Namen und Ihre Kontaktinformationen am Ende dieser Seite an.
1 Prinzipien
Die Prinzipien, welche in diesem Abschnitt erläutert werden, dienen als allgemeine Regeln und Richtlinien, um die Entwicklung einer Cloud-Infrastruktur zu unterstützen. Sie sind dauerhaft, selten zu verändern und informieren und unterstützen die Art und Weise, wie eine Cloud Aufgaben und Ziele erfüllt. Sie sind zudem bestrebt überzeugend und in mancher Hinsicht inspirierend zu sein, da es eine Verbindung mit den betriebswirtschaftlichen Argumenten für eine Änderung geben muss. Die Prinzipien sind oft voneinander abhängig und bilden gemeinsam die Grundlage, auf der eine Cloud-Infrastruktur geplant, konzipiert und erstellt werden kann.
1.1 Wertschöpfung durch gemessene, kontinuierliche Verbesserung erreichen
Behauptung:
Die produktive Nutzung von Technologien zur Wertschöpfung sollte über einen Prozess der kontinuierlichen Verbesserung gemessen werden.
Argumentation:
Alle Investitionen in IT-Services müssen klar und messbar in Beziehung zur Wertschöpfung stehen. Oft wird die Rendite größerer Investitionen in strategische Initiativen in den frühen Phasen verwaltet, dann aber fallengelassen was zu abnehmenden Erträgen führt. Durch die kontinuierliche Messung der Wertschöpfung einer Dienstleistung können Verbesserungen vorgenommen werden, um den maximalen Ertrag zu erzielen. Dies gewährleistet die Nutzung der sich entwickelnden Technologie zu einem produktiven Nutzen des Verbrauchers und die Leistungsfähigkeit des Anbieters. Eingehalten, führt dieses Prinzip zu einer ständigen Evolution von IT-Dienstleistungen, die agile Fähigkeiten zur Verfügung stellen die ein Unternehmen benötigt um einen Wettbewerbsvorteil zu erreichen und zu halten.
Auswirkung:
Die wichtigste Auswirkung dieses Prinzips ist die Anforderung, ständig die aktuelle und zukünftige Rendite von Investitionen zu kalkulieren. Dieser Governance-Prozess muss feststellen, ob durch die aktuelle Service-Architektur immer noch eine Wertschöpfung für das Unternehmen stattfindet und, falls nicht, festzustellen welches Element der Strategie angepasst werden muss.
1.2 Wahrnehmung unendlicher Kapazität
Behauptung:
Aus Sicht des Verbrauchers sollte ein Cloud-Dienst Kapazität „on Demand“ bereitstellen, nur begrenzt durch den Betrag den der Verbraucher bereit ist für Kapazität zu bezahlen.
Argumentation:
Historisch betrachtet hat die IT Dienste entworfen um Spitzenlasten abzufangen, was zu einer Unterauslastung führte, für die der Verbraucher bezahlen musste. Ebenso, wurde die Kapazität einmal erreicht, muss die IT oftmals einen monumentalen Aufwand an Zeit, Ressourcen und Geld betreiben, um die vorhandenen Kapazitäten zu erweitern, was sich negativ auf die geschäftlichen Ziele auswirken könnte. Der Verbraucher will Hilfsdienste bei denen nur bezahlt wird was wirklich verwendet wird und Kapazitäten „on Demand“ nach oben oder unten skaliert werden können.
Auswirkung:
Eine gut durchdachte Management-Strategie für die Kapazität muss von dem Provider eingesetzt werden, um die Kapazität bei Bedarf liefern zu können. Vorhersehbare Einheiten an Netzwerk, Speicher und Rechenleistung sollten als vordefinierte Einheiten zur Skalierung definiert werden. Die Beschaffung und die Bereitstellungszeit für jede skalierbare Einheit sollte gut verstanden und geplant werden. Daher müssen Management-Tools entwickelt werden, die mit der Intelligenz ausgestattet sind skalierbare Einheiten, Beschaffung und Bereitstellung sowie den Bedarf an weiteren skalierbaren Einheiten auf der Basis von aktuellen und historischen Kapazitäts-Trends zu verstehen. Schlussendlich muss der Anbieter (IT) eng mit dem Verbraucher zusammenarbeiten, um neue und wechselnde Anforderungen zu verstehen, die Kapazitäts-Trends verändern. Der Prozess zur Identifizierung von wechselnden geschäftlichen Anforderungen und die Einbeziehung dieser Änderungen in die Kapazitätsplanung wird ein entscheidender Faktor für die Management-Prozesse des Anbieters.
1.3 Wahrnehmung kontinuierlicher Dienstverfügbarkeit
Behauptung:
Aus Sicht des Verbrauchers sollte ein Cloud-Dienst bei Bedarf von überall und auf jedem Gerät zur Verfügung stehen.
**Argumentation:
**Traditionell wurde die IT durch die Anforderungen an die Verfügbarkeit gefordert. Technologische Einschränkungen, Architekturentscheidungen und eine mangelnde Prozessreife führten zu einer erhöhten Wahrscheinlich und Dauer von Verfügbarkeitsausfällen. Hochverfügbare Dienste können angeboten werden, aber nur durch eine enorme Investition in eine redundante Infrastruktur. Der Zugriff auf viele Dienste war oft aufgrund von Auswirkungen auf die Sicherheit nur vor Ort möglich. Cloud-Dienste müssen eine kosteneffektive Möglichkeit bieten, Hochverfügbarkeit zu gewährleisten und Sicherheitsbedenken zu adressieren, damit Dienste über das Internet verfügbar gemacht werden können.
**Auswirkung:
**Um hochverfügbare Dienste kosteneffektiv bereitzustellen, muss die IT eine belastbare Infrastruktur aufbauen und redundante Hardware wo immer möglich vermeiden. Belastbarkeit lässt sich nur durch ein hoch automatisiertes Management des Gesamtgefüges und eine hohe Reife der IT-Service-Management Prozesse erreichen. In einer hochbelastbaren Umgebung wird erwartet das Hardwarekomponenten ausfallen. Ein robustes und intelligentes Programm zum Management des Gesamtgefüges ist notwendig, um frühzeitige Anzeichen von bedeutenden Fehlern zu erkennen, damit Arbeitslasten schnell von der fehlerhaften Komponente verschoben werden können, wodurch der Verbraucher weiterhin die gleiche Verfügbarkeit des Dienstes wahrnimmt. Ältere Anwendungen sind wahrscheinlich nicht für die Verwendung in einer belastbaren Infrastruktur geschaffen und einige Anwendungen müssen neu entworfen oder ersetzt werden, um kosteneffektive Hochverfügbarkeit zu erreichen.
Ebenso, um Zugang zu einem Dienst von jedem Ort aus über das Internet zu ermöglichen muss nachgewiesen werden, dass die Sicherheitsanforderungen erfüllt werden können. Für eine echte Cloud-ähnliche Erfahrung sollten deshalb Überlegungen angestellt werden, um sicherzustellen, dass auf den Dienst durch die breite Palette heute existierender mobilen Geräten zugegriffen werden kann.
1.4 Verwendung des Service-Provider Ansatzes
Behauptung:
Der Anbieter einer Cloud sollte wie ein Service-Provider denken und handeln, anstatt wie eine IT-Abteilung innerhalb eines Unternehmens.
**Argumentation:
**Unternehmens IT wird oft durch Geschäftsinitiativen angetrieben und gefördert, was zu einem Silo-Ansatz und zu Ineffizienzen führt. Architekten haben vielleicht das Gefühl es sei zu riskant wichtige Infrastruktur in verschiedenen Lösungen zu verwenden. Die Auswirkungen einer Lösung auf eine andere kann nicht beseitig werden, wodurch jede Lösung auf einer eigenen Infrastruktur aufbaut und nur Fähigkeiten der Lösung genutzt werden, in die ein hohes Vertrauen existiert. Das Resultat ist die Erstellung von Projekten welche die Effizienz steigern (z.B. Virtualisierung und die Konsolidierung von Rechenzentren).
Ein Cloud-Dienst ist ein gemeinschaftlicher Dienst und muss daher in einer klaren Weise definiert sein, welche dem Verbraucher das Vertrauen gibt diesen zu verwenden, inklusive der Fähigkeiten, Performance und Verfügbarkeitscharakteristika. Gleichzeitig muss die Cloud einen Mehrwert für das Unternehmen zeigen. Da Service Provider an Kunden verkaufen, gibt es eine klare Trennung zwischen dem Anbieter und dem Kunden / Verbraucher.
Diese Beziehung treibt den Anbieter, um Dienste nach den Perspektiven von Leistungsfähigkeit, Kapazität, Performance, Verfügbarkeit und finanziellen Perspektiven zu definieren. Die Unternehmens IT muss den gleichen Ansatz übernehmen, um Dienste anzubieten.
**Auswirkung:
**Die Übernahme des Service Provider Ansatzes erfordert ein hohes Maß an IT Service Management Reife. Die IT muss ein klares Verständnis für die Service-Level haben die sie erreichen können und muss diese Ziele auch konsequent erreichen. Die IT muss ein klares Verständnis der tatsächlichen Kosten der Diensterbringung haben und muss in der Lage sein, die Kosten der Konsumierung des Dienstes im Unternehmen zu kommunizieren. Es muss eine robuste Management-Strategie für die Kapazität existieren, um sicherzustellen, dass die Nachfrage nach dem Dienst ohne Unterbrechung und mit minimaler Verzögerung eingehalten werden kann. Die IT muss auch einen genauen Blick auf den Zustand eines Dienstes haben und über automatisierte Management-Tools zur Überwachung und zur schnellen und pro-aktiver Reaktion fehlerhafter Komponenten verfügen, sodass keine Unterbrechung des Dienstes stattfindet.
1.5 Optimierung der Ressourcennutzung
Behauptung:
Die Cloud sollte die effiziente und effektive Nutzung der Infrastruktur-Ressourcen automatisieren.
**Argumentation:
**Ressourcenoptimierung treibt die Effizienzsteigerung und die Kostensenkung und wird vor allem durch die gemeinsame Nutzung von Ressourcen erreicht. Die Abstrahierung der Plattform von der physischen Infrastruktur ermöglicht die Verwirklichung dieses Prinzips durch die gemeinsame Nutzung von zusammengefassten Ressourcen. Die Verwendung von gemeinsamen Ressourcen durch mehrere Vebraucher führt zu einer höheren Ressourcenauslastung und einer effizienterer und effektiverer Nutzung der Infrastruktur. Optimierung durch Abstraktion ermöglicht viele der anderen Prinzipien und hilft letztlich Kosten zu senken und die Flexibilität verbessern.
**Auswirkung:
**Die dienstleistungserbringende IT-Organisation muss die Business-Treiber klar verstehen um entsprechende Schwerpunkte beim Design und Betrieb zu gewährleisten. Das Niveau der Effizienz und Effektivität ist abhängig von Zeit / Kosten / Qualitätstreiber für eine Cloud. In einem Extremfall kann die Cloud verwendet werden um die Kosten zu minimieren, wobei Design und Betrieb die Effizienz durch ein hohes Maß an gemeinsamer Nutzung maximieren. In einem anderen Extremfall ist der Business-Treiber die Flexibilität, wobei sich das Design darauf fokussiert, wie lange es dauert auf Änderungen zu reagieren und dadurch die Effektivität vor die Effizienz gestellt wird.
1.6 Ein Ganzheitlicher Ansatz für Hochverfügbarkeit
Behauptung:
Eine Hochverfügbarkeitslösung sollte alle Ebenen einer Umgebung einbeziehen und wenn möglich Widerstandsfähigkeit herstellen und unnötige Redundanzen entfernen.
Argumentation:
Traditionell hat die IT hochverfügbare Dienste mit Hilfe einer auf Redundanz ausgelegten Strategie zur Verfügung gestellt. Fällt eine Komponente aus, übernimmt eine der redundanten Komponenten die Arbeit. Redundanz kommt dabei oft auf verschiedenen Ebenen einer Umgebung zum Einsatz, da eine aufbauende Schicht nie darauf vertraut, dass die darunter liegende Schicht redundant ausgelegt ist. Diese Redundanz, besonders auf der Infrastruktur-Ebene, ist nicht nur in der Anschaffung kostenintensiv, sondern auch im Betrieb.
Einer der Grundsätze einer Cloud ist es Hochverfügbarkeit durch Widerstandsfähigkeit bereitzustellen. Anstatt die Lösung für Fehlervermeidung zu entwickeln, akzeptiert und erwartet die Cloud, bzw. das Design der Cloud, sogar Ausfälle von Komponenten. Das Cloud-Design fokussiert sich dabei auf das reduzieren der Auswirkung eines Ausfalls und das schnelle wiederherstellen eines Dienstes im Fehlerfall. Durch Virtualisierung, Echtzeitüberwachung und automatische Zustandsmeldungen können Prozesse oft von den fehlerhaften Infrastruktur-Komponenten genommen werden ohne eine Auswirkung auf einen darüber liegenden Dienst zu haben.
Auswirkung:
Da die Cloud auf Widerstandsfähigkeit fokussiert ist werden unerwartete Ausfälle von Infrastrukturkomponenten (z.B.: Hosting-Server) geschehen und auch Einflüsse auf die Systeme haben. Deshalb muss der Nutzer mit solchen Ausfällen rechnen und auf der Applikationsebene diese einplanen. Mit anderen Worten, die Lösung muss auf der Widerstandsfähigkeit der Cloud aufbauen und Redundanz und\oder Widerstandsfähigkeit auf der Applikationsebene herstellen um die Verfügbarkeitsziele zu erreichen. Bestehende Applikationen sind dafür wahrscheinlich nicht die geeignetsten Kandidaten, da sie häufig zustandsbehaftet sind und von einer redundanten Infrastruktur ausgehen. Durch zustandslose Prozesse kann eine Applikation oder ein Load-Balancer diese Widerstandsfähigkeit ehr bereitstellen.
1.7 Menschliche Eingriffe reduzieren
Behauptung:
Der tägliche Betrieb einer Cloud sollte möglichst ohne menschliche Eingriffe geschehen.
Argumentation:
Die benötigte Widerstandsfähigkeit um eine Cloud zu betreiben kann nicht ohne einen hohen Grad der Automatisierung erreicht werden. Wenn auf menschliche Eingriffe für das finden und reagieren auf Fehler vertraut wird, kann eine durchgängige Dienstverfügbarkeit nicht ohne vollständig redundante Infrastruktur gewährleistet werden. Deshalb muss eine vollautomatische Managementlösung für die Systeme genutzt werden um Aufgaben des Betriebs dynamisch durchzuführen, wie beispielsweise Fehler automatisch zu erkennen und auf diese zu reagieren oder Ressourcen variabel und nach aktuellem Bedarf der Prozesse bereitzustellen oder zu entfernen. Wichtig ist zu verstehen, dass zwischen manuellen und automatischen Eingriffen ein Kontinuum besteht.
Ein manueller Prozess ist es, wenn alle Schritte einen menschlichen Eingriff erfordern. Ein mechanischer Prozess ist es, wenn einige Schritte automatisiert ablaufen aber immer noch menschliche Eingriffe notwendig sind (zum Beispiel feststellen, wann ein Prozess gestartet werden muss oder starten eines Skriptes). Um vollautomatisch abzulaufen darf nichts von einem Prozess, von der Erkennung bis hin zur Reaktion, irgendeinen menschlichen Eingriff erfordern.
Auswirkung:
Vollautomatische Managementlösungen bedürfen spezifischer architektonischer Muster um zu funktionieren, welche später beschrieben werden. Der Managementlösung müssen diese Muster bewusst sein und sie muss ein Verständnis von der „Gesundheit“ des Systems haben. Das wiederum bedarf eines hohen Grads der Anpassung von jedem automatisiertem Prozess in der Umgebung.
1.8 Berechenbarkeit herstellen
Behauptung:
Eine Cloud muss ein berechenbares Umfeld anbieten, da die Nutzer eine kontinuierliche Qualität und Funktionsweise erwarten der genutzten Dienste erwarten.
Argumentation:
Traditionell hat die IT oft nicht berechenbare Level der Service-Qualität geboten. Dieser Umstand behindert die Wirtschaft dabei das volle strategische Potenzial, das die IT bieten könnte, zu erkennen. Mit dem Aufkommen von mehr Public-Cloud Angeboten entscheidet sich die Wirtschaft eventuell ehr für diese, anstatt für interne IT Abteilungen, um so eine bessere Berechenbarkeit zu erzielen. Um weiterhin eine praktikable Option für die Wirtschaft zu sein müssen Enterprise-IT Abteilungen berechenbare Services auf Augenhöhe mit den Public-Cloud Angeboten liefern.
Auswirkung:
Damit die IT einen berechenbaren Service anbieten kann muss die Infrastruktur den auf ihr laufenden Prozessen ein konsistentes Erlebnis bieten. Diese Konsistenz wird durch eine Homogenisierung der physikalischen Server, Netzwerkegeräte und Speichersysteme geschaffen. Zusätzlich zu dieser Homogenisierung ist eine hohe Qualität der IT Service Managements Prozesse notwendig. Change-Management, Konfigurations- und Veröffentlichungsprozesse müssen genau eingehalten werden, hocheffektive und automatisierte Störungs- und Problem-Management Prozesse müssen etabliert sein.
1.9 Anreize für ein gewünschtes Verhalten
Behauptung:
IT wird die wirtschaftlichen Bedürfnisse besser bedienen können, wenn die Services, die sie anbietet, bei dem Konsumenten Anreize für bestimmte Verhaltensweisen schafft.
Argumentation:
Die meisten Business-Anwender verlangen für eine bestimmte Anwendung oft 99,999% oder 100% Verfügbarkeit, wenn sie diese bei der IT als einen Service anfragen. Dieses Verhalten kommt häufig vom Unwissen über die tatsächlichen Kosten, die beim Liefern eines solchen Services, sowohl beim Kunden und als auch bei der IT, entstehen. Bietet der IT Provider aber eine Auswahl an verschiedenen Service-Level, bei der die Kosten für die Anforderungen, wie beispielsweise 99,999% Verfügbarkeit, sofort ersichtlich werden, würde dies die Erwartung an den tatsächlichen Business-Need und an die IT sofort der Realität anpassen.
Ein anderes, mehr technisches Beispiel: Viele Unternehmen, die Virtualisierung eingeführt haben, haben herausgefunden, dass diese zu einem neuen Phänomen führt, neue virtuelle Maschinen (VM) werden bei Bedarf erstellt, aber es gibt keine Anreize diese VM‘s wieder zu stoppen oder zu entfernen. Die Vorstellung von grenzenloser Kapazität führt eventuell dazu, dass Nutzer diese als Ersatz für effektives Prozess-Management nutzen. Während unendliche Kapazitäten eventuell als Verbesserung der Qualität und der Flexibilität eines Services wahrgenommen werden, wirkt sich das unverantwortliche nutzen dieses Services negativ auf die Kosten der Cloud Dienste aus.
Auf den Im oben bezogen, möchte ein Cloud Anbieter Anreize für den Kunden schaffen, Ressourcen nur nach Bedarf zu nutzen, kann er das durch Abrechnen oder Reporten des Verbrauchs schaffen.
Die Förderung eines gewünschten Nutzerverhaltens ist ein Schlüssel-Prinzip und ist verwandt mit dem Prinzip eines Service-Anbieter-Ansatzes.
Auswirkung:
Eine IT Organisation muss die Verhaltens, die sie hervorrufen will, identifizieren. Das Beispiel oben bezog sich auf ineffizientem nutzen von Ressourcen, andere Beispiele beinhalten eine Reduzierung der HelpDesk-Calls (Abrechnung pro Anruf) oder dem richtigen Level für Redundanz (Höhere Kosten für höhere Redundanz). Jedes dieser Beispiele setzt eine ausgereifte Service Management Möglichkeit voraus; z.B.: Messen und Reporten des Verbrauchs pro Geschäftsbereich, verschiedene Service-Level in dem Produkt\Service Katalog und ein Wandel hin zu einem Service Anbieter mit eine Geschäftsbeziehung. Die Anreize sollten während der Designphase definiert werden.
1.10 Schaffen einer nahtlosen User-Experience
Behauptung:
Nutzer eines IT Services sollten auf nichts stoßen, was das Nutzen eines Services unterbrechen könnte, nur weil eine Grenze des Service-Anbieters passiert wird.
Argumentation:
IT Strategien berücksichtigen mehr und mehr die Services mehrerer Anbieter, um die kostengünstigste Lösung anbieten zu können. Auf Grund dessen, dass mehr Services von diversen Anbietern bereitgestellt werden, steigt das Potenzial für Unterbrechungen bei der Nutzung, da Geschäftstransaktionen Anbieter-Grenzen passieren. Die Tatsache, dass eine Vielzahl an Services dem Nutzer durch verschiedene Anbieter bereitgestellt wird, sollte für den Nutzer völlig verborgen bleiben und er sollte keinen Bruch bei der Nutzung bemerken.
Ein Beispiel ist eventuell ein Nutzer, der via Geschäftsportal, auf verschieden Information über die gesamte Organisation hinweg zugreift, wie der Status einer Bestellung. Dieser Nutzer sieht die Bestellung mit Hilfe des on-premise Bestellsystems und klickt darin auf einen Link für mehr Details, welche in dem CRM-System in der Public Cloud gespeichert sind. Während des passieren der Grenze zwischen dem On-Premise-System und dem System aus der Public-Cloud sollte der Nutzer keine Hindernisse bemerken, welche die Produktivität herabsetzen würden. Es sollte keine erneute Verifikation notwendig sein, es sollte ein einheitliches „Look and Feel“ ersichtlich sein und die Performance sollte über die gesamte Nutzung einheitlich sein. Dies sind nur einige Beispiele wie dieses Prinzip erreicht werden kann.
Auswirkung:
Der IT Anbieter muss potenzielle Quellen für die Unterbrechung einer Nutzeraktivität über verschiedene Services identifizieren. Sicherheitssysteme müssen eventuell verbunden werden um den nahtlose Nutzung von Systemen zu gewährleisten, Datentransformation ist unter Umständen notwendig um eine konsistente Widergabe von geschäftlichen Unterlagen zu ermöglichen, ein einheitliches Design muss vielleicht genutzt werden um dem Nutzer das Gefühl zu geben in einer konsistenten Umgebung zu arbeiten.
Das Gebiet wo dies die meisten Einflüsse hat ist bei der Lösung von Nutzerproblemen. Wenn ein Problem auftritt ist die Quelle nicht unbedingt sofort ersichtlich und es bedarf eines komplexen Managements zwischen den verschiedenen Anbietern bis die Wurzel des Problems gefunden wurde. Der Nutzer sollte diese Anstrengungen nicht mitbekommen, welche hinter eine „Songle Point of Contact“ innerhalb der Services gekapselt sind.
2 Konzepte
Die folgenden Konzepte sind Abstraktionen oder Strategien, welche die Leitsätze und die Definition einer Cloud unterstützen. Sie werden von den oben beschriebenen Prinzipien gesteuert und unterstützen eine oder mehrere dieser Prinzipien.
2.1 Berechenbarkeit
Die Qualität des IT Service ist traditionell oft unkalkulierbar. Die fehlende Berechenbarkeit hindert Unternehmen daran, den vollen strategischen Vorteil, den eine IT liefern könnte, zu nutzen. Durch das vermehrte Aufkommen von Public Cloud Angeboten können Unternehmen entscheiden, ob sie Teile ihrer Services in die "Cloud" auslagern, um eine höhere Berechenbarkeit des Services zu ermöglichen. Die Enterprise IT muss eine, der Public Cloud gleichgestellten vorhersehbaren Service, anbieten können, um in Zukunft eine valide Option bleiben zu können.
Um eine kalkulierbare IT Service Qualität zu bieten, muss von die zugrunde liegende Infrastruktur auf der übereinstimmenden Erfahrung mit gehosteten Workloads beruhen.
Diese Kontinuität wird durch die Homogenisierung der zugrundeliegenden physischen Server und der Netzwerkgeräte, sowie der Speichersysteme ermöglicht. Zusätzlich zur Homogenisierung der Infrastruktur wird ein sehr hoher Reifegrad des eingesetzten Service Managements benötigt, um eine Kalkulierbarkeit zu gewährleisten. Eine gut eingespieltes Change-, Configuration und ein Releasemanagement, sowie ein hochautomatisiertes Incident- und Problemmanagement sind unabdingbar für eine Lösung.
2.2 Elastizität über Redundanz
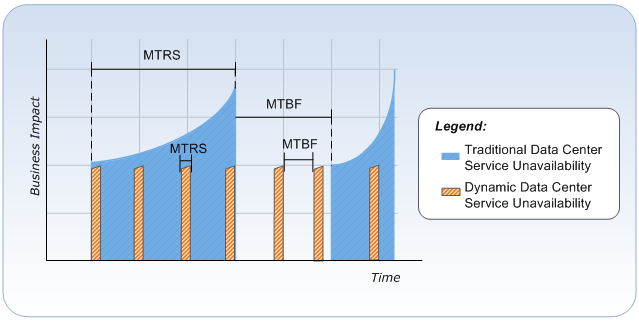
Um möglichst ununterbrochene Verfügbarkeit zu erreichen, muss ein ganzheitlicher Ansatz gewählt werden. Klassisch wird Verfügbarkeit immer als primäres Messkriterium für den Erfolg einer IT Service Erbringung gesehen. Es ist durch Service Level Targets (SLT) definiert, welche die Maschinen- bzw. Serviceverfügbarkeit in Prozent ausdrücken.
Allerdings ist es zu wenig, den Erfolg einer Service Bereitstellung ausschließlich mittels Verfügbarkeitszielen zu bewerten. Es schafft eine falsche Vorstellung von "je mehr Neunen desto besser". Die Verfügbarkeit die der Kunde wirklich benötigt wird nicht betrachtet.
Es gibt zwei wesentliche Annahmen bei der Nutzung von Verfügbarkeit als ein Erfolgskriterium. Zum einen hat jeder Service Ausfall eine so signifikante Länge, dass der Kunde sie feststellen kann. Zum anderen gibt es bei jedem Ausfall einen signifikanten, negativen Einfluss auf den Geschäftsbetrieb. Die begründete Annahme ist: Je länger es dauert einen Service wiederaufzunehmen, desto größer ist die Auswirkung auf das Geschäft.
Es gibt zwei Hauptfaktoren, die die Verfügbarkeit beeinflussen: Zuverlässigkeit, die mittels „Mean-Time-Between-Failures“ (MTBF) bewertet wird. Es wird die Zeit zwischen Serviceausfällen gemessen. Die zweite ist Dienstelastizität, welche mittels „Mean-Time-to-Restore-Service“ (MTRS) gemessen wird. Die MTRS misst die Zeit zwischen dem Beginn des Ausfalls und der Wiederherstellung des Service. Aufgrund der Tatsache, dass normalerweise menschliches Eingreifen nötig ist, um einen Störung zu erkennen und zu lösen, ist es schwer, den MTRS zu verkleinern. Daher konzentrieren sich Firmen in den Regeln auf den MTBF um Verfügbarkeitsziele zu erreichen. Das Erreichen einer höheren Verfügbarkeit durch höhere Zuverlässigkeit verlangt eine höhere Investition in redundante Hardware und damit einen exponentiellen Anstieg der Kosten für die Implementierung und Wartung dieser Hardware.
Bei Nutzung dieses ganzheitlichen Ansatzes erreicht die Cloud einen höheren Level an Verfügbarkeit und Elastizität. Das traditionelle Model mit physischer Redundanz wird durch Software-Werkzeuge ersetzt.
Das erste Werkzeug, welches hilft dies zu erreichen, ist Virtualisierung. Sie bietet eine Abstraktion des Services von einer dedizierten Hardware an und erhöht so dessen Portierbarkeit auf andere Systeme. Das zweite Werkzeug ist der Hypervisor. Der Hypervisor bietet die Möglichkeit, Workloads transparent auf andere Hosts zu verteilen oder erneut zu starten. Dadurch werden die Elastizität und die Verfügbarkeit erhöht, ohne dass eine weitere Software innerhalb des Workloads ausgeführt werden muss. Das letzte Werkzeug ist ein "Health Model" welches es der IT erlaubt, den Hardwarestatus vollständig zu erfassen und automatisiert auf Fehler zu reagieren, indem betroffene Services/Workloads auf ein nicht betroffenes System migriert werden.
Während die "Computer Komponente" keine Hardware-Redundanz mehr benötigt, ist sie bei den Speichersubsystemen nach wie vor unerlässlich. Darüber hinaus wird bei den Netzwerk Komponenten eine Hardware-Redundanz gefordert, um den Anforderungen eines Storage-Systems gerecht zu werden. Derzeitige Netzwerk-und Speichersystemanforderungen verhindern jedoch die komplette Beseitigung von Hardware-Redundanz. Signifikante Kosteneinsparungen durch Einsparung der Hardware-Redundanz für die "Computer Komponenten" können trotzdem erreicht werden.
In einem klassischen Rechenzentrum kann der MTRS durchschnittlich durchaus über eine Stunde dauern, wohingegen eine Cloud sich innerhalb von Sekunden von einem Ausfall einzelner Komponenten erholen kann. Zusammen mit der automatisierten Erkennung und Reaktion auf Fehler und Warnungen innerhalb der Infrastruktur, kann dies die MTRS dramatisch reduzieren (Aus der Infrastructure-as-a-Service (IaaS) Perspektive).
Die dadurch erreichte signifikante Steigerung der Elastizität macht den Zuverlässigkeitsfaktor noch unwichtiger. In einer Cloud ist Verfügbarkeit y (Minuten uptime/Jahr) nicht mehr der alleinige Leistungsindikator für eine erfolgreiche IT Service Bereitstellung.
Die Wahrnehmung der Verfügbarkeit und die geschäftliche Auswirkungen der Nichtverfügbarkeit werden die Erfolgsmesskriterien.
2.3 Homogenisierung von physischer Hardware
Homogenisierung von physischer Hardware ist der Schlüsselbegriff um die Berechenbarkeit zu erhöhen. Die zugrundeliegende Infrastruktur muss eine konsistente Verhalten für die gehosteten Workloads bieten, um eine Berechenbarkeit zu erreichen.
Diese Konsistenz wird durch die Homogenisierung der zugrundeliegenden Servern, dem Netzwerk und der Speichersysteme erreicht. Die Trennung des Service von der Hardwareschicht, mittels Visualisierung aus der "server stock-keeping units (SKU) Unterscheidung", ist eher ein logisches, als ein physisches Konstrukt. Dies beseitigt den Bedarf an Differenzierung auf dem physischen Server-Level. Größere Homogenisierung von "Computer Komponenten" führen zu einer Reduktion der Variabilität. Diese Reduktion der Variabilität vergrößert die Berechenbarkeit der Infrastruktur, was wiederum die Servicequalität verbessert.
Ziel ist es, letztendlich die Schichten Computer, Speicher und Netzwerk soweit zu homogenisieren, dass es keine Unterscheidung mehr zwischen den jeweiligen Servern gibt. In anderen Worten: Jeder Server hat den gleichen Prozessor und den gleichen Arbeitsspeicher (RAM); Jeder Server verbindet sich mit der gleichen Speicherplatz und jeder Server verbindet sich zum gleichen Netzwerk. Das bedeutet, dass jeder virtuelle Service auf jedem physischen Server ausgeführt und im Fehlerfall unterbrechungsfrei auf einen anderen Server verschoben werden kann.
Es ist verständlich, dass eine volle Homogenisierung der physischen Infrastruktur nicht immer machbar ist. Obwohl es empfohlen ist, dass eine Homogenisierungs-Strategie verfolgt wird, so sollte, wo dies nicht möglich ist, die Computer-Komponente so weit wie möglich standardisiert werden. Egal ob die Kunden ihre Computer Ressourcen homogenisieren oder nicht, das Modell erfordert eine homogene Netzwerk- und Speicher-Infrastruktur, so dass ein Ressourcen-Pool für das Hosting der virtuellen Services ermöglicht wird.
Es sollte erwähnt werden, dass Homogenisierung im großen Stil das Potenzial hat Kosteneinsparungen durch spezielle, strategische Kooperationen mit Hardwareherstellern zu ermöglichen. Wenn eine kritische Größe nicht erreicht wird, kann dies allerdings auch zu einem negativen Effekt führen. Eine Multi-Vendor-Strategie könnte dann günstiger sein.
Homogenisierung von physischer Hardware ist der Schlüsselbegriff um die Berechenbarkeit zu erhöhen. Die zugrundeliegende Infrastruktur muss eine konsistente Verhalten für die gehosteten Workloads bieten, um eine Berechenbarkeit zu erreichen.
Diese Konsistenz wird durch die Homogenisierung der zugrundeliegenden Servern, dem Netzwerk und der Speichersysteme erreicht. Die Trennung des Service von der Hardwareschicht, mittels Visualisierung aus der "server stock-keeping units (SKU) Unterscheidung", ist eher ein logisches, als ein physisches Konstrukt. Dies beseitigt den Bedarf an Differenzierung auf dem physischen Server-Level. Größere Homogenisierung von "Computer Komponenten" führen zu einer Reduktion der Variabilität. Diese Reduktion der Variabilität vergrößert die Berechenbarkeit der Infrastruktur, was wiederum die Servicequalität verbessert.
Ziel ist es, letztendlich die Schichten Computer, Speicher und Netzwerk soweit zu homogenisieren, dass es keine Unterscheidung mehr zwischen den jeweiligen Servern gibt. In anderen Worten: Jeder Server hat den gleichen Prozessor und den gleichen Arbeitsspeicher (RAM); Jeder Server verbindet sich mit der gleichen Speicherplatz und jeder Server verbindet sich zum gleichen Netzwerk. Das bedeutet, dass jeder virtuelle Service auf jedem physischen Server ausgeführt und im Fehlerfall unterbrechungsfrei auf einen anderen Server verschoben werden kann.
Es ist verständlich, dass eine volle Homogenisierung der physischen Infrastruktur nicht immer machbar ist. Obwohl es empfohlen ist, dass eine Homogenisierungs-Strategie verfolgt wird, so sollte, wo dies nicht möglich ist, die Computer-Komponente so weit wie möglich standardisiert werden. Egal ob die Kunden ihre Computer Ressourcen homogenisieren oder nicht, das Modell erfordert eine homogene Netzwerk- und Speicher-Infrastruktur, so dass ein Ressourcen-Pool für das Hosting der virtuellen Services ermöglicht wird.
Es sollte erwähnt werden, dass Homogenisierung im großen Stil das Potenzial hat Kosteneinsparungen durch spezielle, strategische Kooperationen mit Hardwareherstellern zu ermöglichen. Wenn eine kritische Größe nicht erreicht wird, kann dies allerdings auch zu einem negativen Effekt führen. Eine Multi-Vendor-Strategie könnte dann günstiger sein.
2.4 Pooling von Computer-Ressourcen
Die Etablierung eines gemeinsam genutzten Pools von Computer-Ressourcen ist der Schlüssel zum Cloud Computing. Dieser Ressource-Pool ist eine Sammlung von gemeinsam genutzten Ressourcen, bestehend aus Computer, Speicher und Netzwerkressourcen, welche die Struktur bereitstellen, die die virtualisierten Workloads hosten. Eine Untermenge dieser Ressourcen wird für Kunden nach Bedarf allokiert und umgekehrt wieder in den Pool zurückgegeben wenn sie nicht mehr benötigt werden. Idealerweise sollte der Ressource-Pool homogen sein. Allerdings, wie bereits erwähnt, die Realität der gegenwärtigen Kundeninfrastruktur könnte einen voll homogenisierten Pool unmöglich machen.

2.5 Virtualisierte Infrastruktur
Virtualisierung ist die Abstraktion von Hardware Komponenten in logische Einheiten. Obwohl Virtualisierung in jeder Infrastruktur-Komponente (Server, Netzwerk und Speicher) anders abgebildet wird sind die Vorteile sind grundsätzlich die Gleichen, inklusive weniger oder keinen Ausfall durch Ressource Management Aufgaben, verbesserter Transportfähigkeit, vereinfachte Verwaltung von Ressourcen sowie der Möglichkeit Ressourcen gemeinsam zu nutzen.
Virtualisierung ist der Beschleuniger der anderen Konzepte, wie z.B. elastische Infrastructure, Aufteilung von gemeinsamen Ressourcen und Pools von Computer Ressourcen. Die Virtualisierung von Infrastruktur-Komponenten muss nahtlos integriert sein, um eine Infrastruktur zu ermöglichen, die in der Lage ist, je nach Bedarf, dynamisch zu wachsen oder zu schrumpfen.
2.6 Fabric Management
Fabric ist der Begriff der für den Sammlung der Computer, Netzwerk und Speicherressourcen verwendet wird. Fabric Management ist eine Ebene der Abstraktion über der Virtualisierung. in der gleichen Weise wie Virtualisierung physische Hardware abstrahiert, so abstrahiert "Fabric Management" Services von Hypervisoren und Netzwerk-Switches. Fabric Management kann man sich als Orchestrierungs-Engine vorstellen, die für das Verwalten des Lebenszyklus eines Kunden-Workload verantwortlich ist. In einer Cloud reagiert das Fabric Management auf Service-Anfragen, Systems Management Ereignisse und Service Management Richtlinien.
Herkömmlich werden Server, Netzwerke und Speichersysteme getrennt, oft auf einer "Basis für Projekte, verwendet. Um Stabilität zu gewährleisen muss eine Cloud in der Lage sein, automatisch zu ermitteln ob eine Hardware-Komponente mit verminderter Leistung läuft, oder ausgefallen ist. Dies erfordert das Verständnis aller Hardware-Komponenten, die dabei zusammenspielen um einen Service zu liefern und die Beziehungen zwischen diesen Komponenten herstellen. Fabric Management nutzt dieses Verständnis der Zusammenhänge um Services die von einem Komponenten-Ausfall betroffen sind zu identifizieren. Das ermöglicht es dem Fabric Management System zu ermitteln ob eine automatisierte Reaktion nötig ist, um einen Ausfall zu vermeiden, oder einen ausgefallenen Service auf einem anderen Knoten innerhalb der Fabric erneut zu starten.
Aus Sicht des Providers ist das Fabric Management System der Schlüssel um zu ermitteln welche Mengen an Reservekapazitäten verfügbar sind und wie der Gesundheitszustand der Fabric sind. Dies stellt sicher, dass Services den definierten Service Level, der mit dem Kunden vereinbart wurde, erfüllen.
2.7 Flexible Infrastruktur
Das Konzept einer elastischen Infrastruktur erlaubt eine Wahrnehmung von unbegrenzter Kapazität. Eine elastische Infrastruktur erlaubt es Ressourcen bei Bedarf zu allokieren und viel wichtiger, Ressourcen wieder freizugeben wenn sie nicht mehr benötigt werden. Die Möglichkeit eines "scale downs" wenn Kapazitäten nicht mehr benötigt werden, ist ein oft nicht wahrgenommener oder unterbewerteter Punkt, der zu einem "Ausuferung der Serveranzahl " und zu einer mangelnder Optimierung der Ressourcennutzung führen kann. Es ist wichtig ein verbrauchsabhängiges Preismodell zu etablieren um Kunden zu ermutigen Ressourcenschonend zu agieren. Automatisierte oder Kundeninitiierte Trigger bestimmen, wann Computer-Ressourcen allokiert oder zurückgegeben werden. Um eine elastische Infrastruktur zu erreichen, ist eine enge Abstimmung zwischen IT und dem Business erforderlich, da Lastspitzen und der Kapazitätsbedarfsanstieg im Rahmen des Kapazitäts- Management verstanden und geplant werden müssen.
2.8 Partitionierung von gemeinsam genutzten Ressourcen
Ressourcen gemeinsam nutzen zu können ist eines der Schlüsselprinzipien der Cloud, trotzdem ist es auch wichtig zu verstehen, wann diese gemeinsam genutzten Ressourcen wieder aufgeteilt werden müssen. Während eine gänzlich gemeinsam genutzte Infrastruktur optimal für die Kosten und Flexibilität ist, verlangen regulatorische Vorgaben, geschäftliche Faktoren oder Probleme der Mandaten Fähigkeit, verschiedene Niveaus der Ressourcenteilung.. Aufteilungsstrategien können auf mehreren Ebenen stattfinden, z.B. physische Isolation oder Netzwerkseitige Isolation. Ähnlich wie bei Redundanz: je niedriger sie in diesen Schichten stattfindet, desto teurer ist sie. Zusätzliche Hardware und Reserve-Kapazitäten können benötigt werden, wenn man als Partitionierung Strategie beispielsweise die Separierung von Ressourcen-Pools verfolgt. Letztlich muss ein Unternehmen die Risiken und Kosten gegenüberstellen, um seine Teilungsstrategie zu definieren. Die Cloud-Infrastruktur muss eine sichere Methode der Isolation von Infrastruktur und Netzwerkverkehr bieten und gleichzeitig von der geteilten Nutzung profitieren.
2.9 Resource Decay
Das Behandeln von Infrastruktur Ressourcen als einen einzelnen Ressourcen-Pool erlaubt kleinere Hardwareausfälle ohne signifikanten Einfluss auf die Gesamtkapazität.
Klassischerweise wird Hardware nur im Störungsfall gewartet. Die Hardware wird dann repariert oder ausgetauscht. Bei Nutzung des Ressource-Pool-Konzepts kann Hardware ein Wartungsmodell verwendet werden. Ein bestimmter Prozentsatz des Ressource-Pools kann ausfallen, bevor Services betroffen sind und ein Störfall eintritt. Fehlgeschlagene Ressourcen werden in einem regelmäßigen Wartungsintervall, oder wenn ein bestimmter Schwellwert der Laufzeit im Ressourcen-Pool erreicht wurde repariert, anstatt wie bisher, einen Austausch auf Server-für-Server Basis durchzuführen.
Dieses Model erfordert, dass der Provider festlegt, wie viele Teilkomponenten ausfallen dürfen, bevor die Komponenten ausgetauscht werden. Dies erlaubt besser vorhersehbare Wartungszyklen und verringert die Kosten die durch spontane Störungen anfallen.
Zum Beispiel hat ein Kunde einen Ressource-Pool mit 100 Servern, er definiert, dass drei Prozent des Pools ausfallen dürfen, bevor Handlungsbedarf besteht. Das bedeutet das drei Server komplett ausfallen können, ohne das weitere Aktivitäten durchgeführt werden müssen.
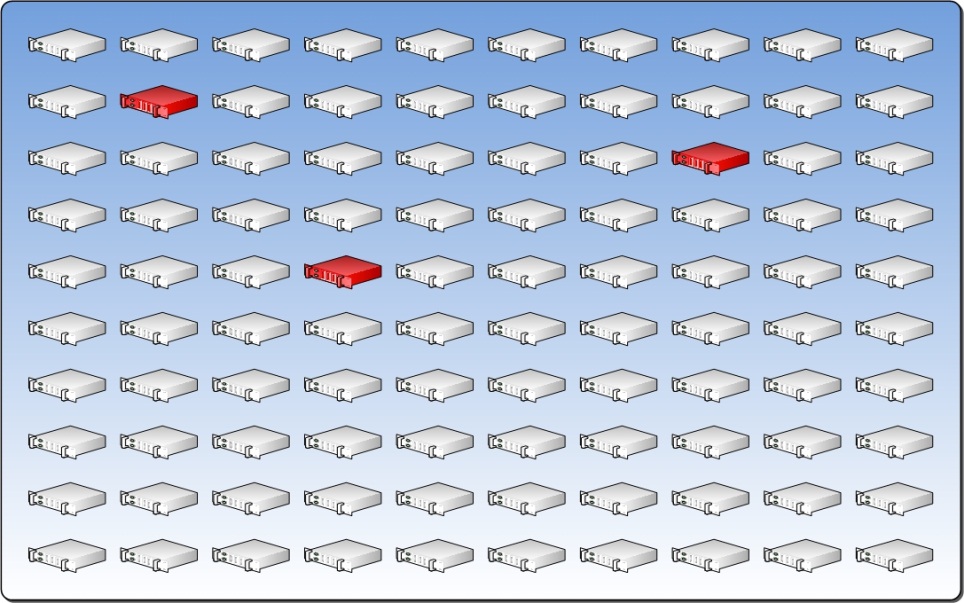
2.10 Service Klassifizierung
Die Klassifizierung ist ein wichtiges Konzept um die Berechenbarkeit des Service zu erhöhen. Jeder Service-Klasse wird im Service Katalog des Providers zusammen mit den Service Levels für die Verfügbarkeit, der Elastizität, der Zuverlässigkeit, der Performance und der der Kosten definiert. Jeder Service muss die vorher festgelegten Anforderungen für seine Klasse erfüllen. Diese Anforderungen spiegeln die unterschiedlichen Kosten zwischen Anwendungs- und Infrastrukturgetrieberer Elastizität wider.
Diese Klassifizierung erlaubt es dem Kunden den gewünschten Service in einer, seinen Ansprüchen erfüllenden Preis- und Qualitätsverhältnis zu erhalten. Die Klassifizierung ermöglicht es dem Anbieter einen standardisierten Ansatz für die Bereitstellung des Service, die Komplexität reduziert und die Berechenbarkeit verbessert. Dies verbessert die Service Bereitstellung.
2.11 Kostentransparenz
Kostentransparenz ist ein grundlegendes Konzept wenn es um die Bereitstellung einer Infrastruktur geht. In einem klassischen Rechenzentrum ist es mitunter nicht möglich festzustellen, wie groß der Anteil an Infrastrukturkosten für einen bestimmten Service ist. Dies macht Preisvergleiche am Markt unmöglich. Mit der Definition von Infrastrukturkosten durch Service Klassifizierung und einem Verbrauchsmodell kann eine fundierte Aussage zu den wahren Kosten einer genutzten Infrastruktur getroffen werden. Dies erlaubt es Unternehmen vernünftige Kostenvergleiche zwischen Serviceerbringung und den Angeboten am Markt durchzuführen, um wohlinformierte Entscheidungen zu treffen.
Die Kostentransparenz durch Service-Klassifizierung ermöglicht dem Unternehmen außerdem fundierte Entscheidungen zu treffen wenn es darum geht, neue Anwendungen zu kaufen oder zu erstellen. Anwendungen welche Redundanz per Design bieten, können in der günstigsten Service-Klasse betrieben werden. Die verursacht so ungefähr nur ein Sechstel der Kosten, die nötig wären, wenn die Infrastruktur die Redundanz liefern müsste.
Schließlich ermutigt Kostentransparenz Service Eigentümer darüber nachzudenken, einen nicht mehr benötigten Service außer Dienst zu stellen. In einem klassischen Rechenzentrum werden Service oft nicht mehr genutzt., aber oft wird nicht in Erwägung gezogen einen nicht mehr benötigten Dienst abzustellen und Ressourcen freizugeben. Die Kosten für anhaltende Wartung und Unterstützung für ungenutzte Services sind oft in den Rechenzentrumskosten versteckt. Eine private Cloud mit einer monatlichen Aufstellung der verbrauchsabhängigen Kosten pro Service, kann Service-Besitzer dazu ermuntern, unbenutzte Services abzuschalten und somit die Kosten zu reduzieren.
2.12 Verbrauchsabhängige Abrechnung
Die verbrauchsabhängige Abrechnung ist das Konzept, das nur die wirklich anfallenden Kosten berechnet werden, im Gegensatz zu einem unabhängig vom Verbrauch erhobenen Festpreis. In einem klassischen Preismodell basieren die Kosten des Kunden auf den Kosten der Kapitalausgaben für Hardware und Software und deren Betrieb und Wartung. Bei diesem Modell können die Kosten des Services in Relation zum Verbrauch zu hoch oder zu niedrig sein. In einem verbrauchsabhängigen Preismodell wirkt sich der Verbrauch direkt auf die Kosten aus.
Die Verbrauchseinheit ist in der Service-Klasse definiert und sollte so genau wie möglich die wahren Kosten wiedergeben, die mit der Nutzung der Infrastruktur und dem Vorhalten von Reservekapazitäten anfallen
2.13 Security und Identity
Die Sicherheit der Cloud ergibt sich aus zwei Paradigmen: Gesicherte Infrastruktur und gesicherter Netzwerkzugang.
Gesicherte Infrastrukturen nutzen Security und Identity Technologien um sicherzustellen, das Hosts, Informationen und Anwendungen in sämtlichen Rechenzentrumsszenarien sicher sind, inklusive physischer (on-premise) und virtueller (on-premise und Cloud) Umgebungen.
Anwendungzugriff sicherstellen bedeutet das IT Manager wichtige Anwendungen sowohl für interne Benutzer, wichtigen Geschäftspartner wie auch für Cloud Nutzer zur Verfügung stellen können
Der Zugang zum Netzwerk nutzt einen Identität-orientierten Ansatz um sicherzustellen, dass Benutzer – egal ob sie im Hauptsitz oder einer Filiale sind - unabhängig davon welches Gerät sie nutzen, einen sicheren Zugriff zu verwenden. Dies hilft die Produktivität beizubehalten und das Geschäft so zu erledigen wird, wie es sein sollte.
Am wichtigsten aus Security-Sicht ist, dass das sichere Rechenzentrum gängige integrierte Technologien nutzt, um Benutzer einen einfacheren Zugriff zu ermöglichen. Das Management ist über Physische, Virtuelle und Cloud-Umgebungen integriert, so dass Unternehmen ohne weitere finanzielle Aufwände alle Ressourcen nutzen können.
2.14 Mandatenfähigkeit
Mandatenfähigkeit bezieht sich auf die Fähigkeit der Infrastruktur logisch unterteilt und mehreren Firmen oder Abteilungen zugeordnet ist.
Ein klassisches Beispiel sind Hosting-Anbieter die Server für mehrere Firmen zur Verfügung stellen. Zunehmend wird dieser Ansatz auch von IT Organisationen übernommen, welche mehrere Geschäftsbereiche bedienen. Jeder Geschäftsbereich oder jede Abteilung ist hier ein separater Kunde oder Mandant.
3 Patterns
Patterns sind spezielle, wiederverwendbare Ideen, die bestimmte bewährte Lösungen Darstellen für häufig auftretende Probleme bei der Implementation eine Private Cloud Infrastruktur. Der folgende Abschnitt beschreibt eine Reihe von fertigen Mustern die nützlich sind um die Cloud-Computing-Konzepte und Prinzipien umzusetzen. In diesem Abschnitt werden diese spezifischen Pattern genauer beschrieben und erläutert. Weiterführende Hinweise wie diese Pattern im Rahmen eines Private Cloud Design zu verwenden sind, ist in weiteren Dokumenten beschrieben.
3.1 Resource Pooling
Das Ressourcen-Pool-Pattern teilt die verfügbaren Ressourcen zur besseren Administration in Partitionen auf. Die Aufteilung wird bestimmt durch die Tools für Service-Management, Capacity Management oder Systems Management Tools.
Das Ressourcen-Pool-Pattern teilt die verfügbaren Ressourcen zur besseren Administration in Partitionen auf. This de-coupling of resources reflects that storage is consumed at one rate while compute and network are collectively consumed at another rate.
3.11 Service Management Partitions
Der Service Architect kann wählen zwischen verschiedenen Service-Klassifikationen unterscheiden Sicherheitsrichtlinien, Leistungsmerkmale oder Kunde (das ist ein dedizierter Ressourcen-Pool). Jeder dieser Klassifizierungen könnte ein separater Ressourcen-Pool sein.
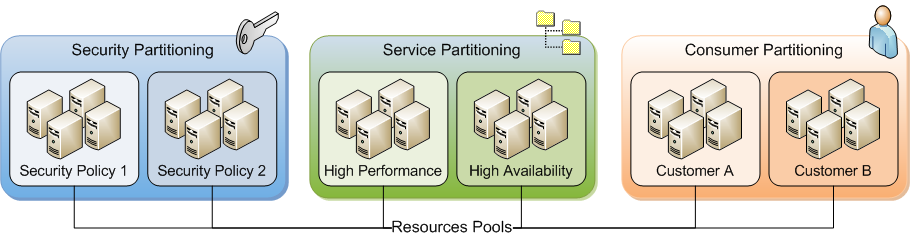
3.12 Systems Management Partitions
Systems Management Tools benötigen definierten Grenzen um sicher zu funktionieren. Zum Beispiel hängen Implementierung, Bereitstellung und automatische Wiederherstellung (VM movement) von VMs davon ab, dass die eingesetzten Tools über Informationen verfügen welche Server verfügbar sind um VMs zu hosten. Ressourcen-Pools definieren diese Grenzen und erlauben dadurch Management-Tools ihre Aktivitäten zu automatisieren.
3.13 Capacity Management Partitions
Systems Management Tools benötigen definierten Grenzen um zu funktionieren. Zum Beispiel hängen Implementierung, Bereitstellung und automatische Wiederherstellung (VM movement) von Virtuellen Machen davon ab, dass die eingesetzten Tools über Informationen verfügen welche Server verfügbar sind um VMs zu hosten. Ressourcen-Pools definieren diese Grenzen und erlauben Management-Tools Aktivitäten zu automatisieren..
Der Ressourcenpool unten stellt einen Pool von Servern dar der einem Datacenter zugeordnet ist.
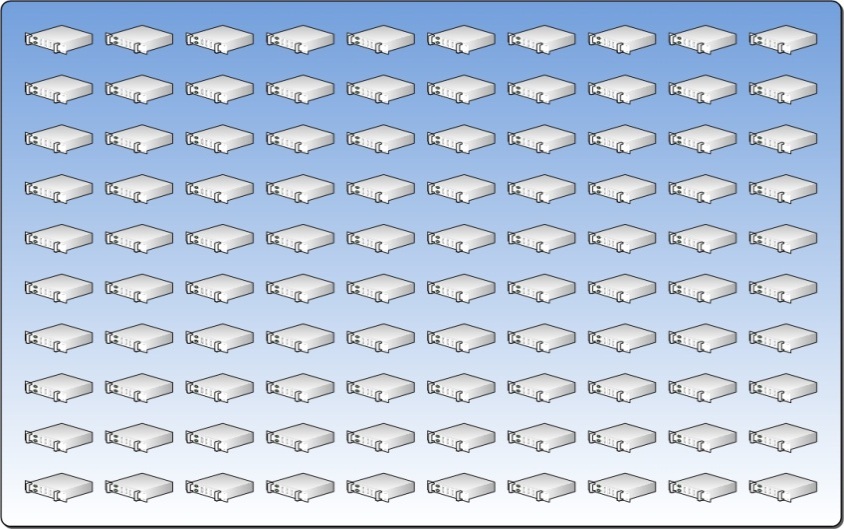
3.2 Physical Fault Domain
Es ist wichtig zu verstehen wie eine Störung des Ressourcen-Pools und damit die Verfügbarkeit der VMs beeinflusst.
Ein Rechenzentrum ist anfällig für kleiner Ausfälle wie einzelne Server Fehler oder lokalen Storage (DAS) Ausfall. Größere Mängel haben einen direkten Einfluss auf die vollständige Rechenzentrums-Kapazität ist es wichtig zu verstehen, dass die Auswirkungen eines Ausfalls einer nicht-Server-Hardware-Komponente sich auch auf den verfügbaren Ressourcenpool auswirkt.
Um die Auswirkung eines Ausfalles zu verstehen wählen sie die Hardware-Komponente aus die höchstwahrscheinlich die meisten Ausfälle haben wird und bestimmen wie viel Server von diesem Ausfall betroffen sind.
Dieses Pattern definiert die Physical-Fault-Domain. Die Anzahl der möglichen ausfallenden Hardware-Komponenten legt in diesem Fall die Anzahl der Physical-Fault-Domain fest.
Die unten aufgeführte Grafik stellt 10 Racks mit jeweils 10 Server dar. Jedes dieser Racks hat zwei Netzwerk-switche und eine USV. Angenommen die USV ist die Hardware-Komponenten mit dem am häufigsten auftretenden Ausfall. Wenn die USV ausfällt sind alle 10 Server des jeweilige Racks betroffen. In diesem Fall sind diese 10 Server die Physical-Fault-Domain.
Wenn wir davon ausgehen, dass es 9 weitere Racks mit identisch Konfiguration gibt dann gibt es insgesamt 10 Physical-Fault-Domain.
In der Praxis kann es, dass es nicht möglich ist die Komponente mit dem höchsten Fehler zu bestimmen. Dann sollte der Architekt dem Kunde die Überwachung der Ausfallraten wichtiger Hardware-Komponenten nahelegen und die USV als ursprüngliche Grenze für die Physical-Fault-Domain festlegen.
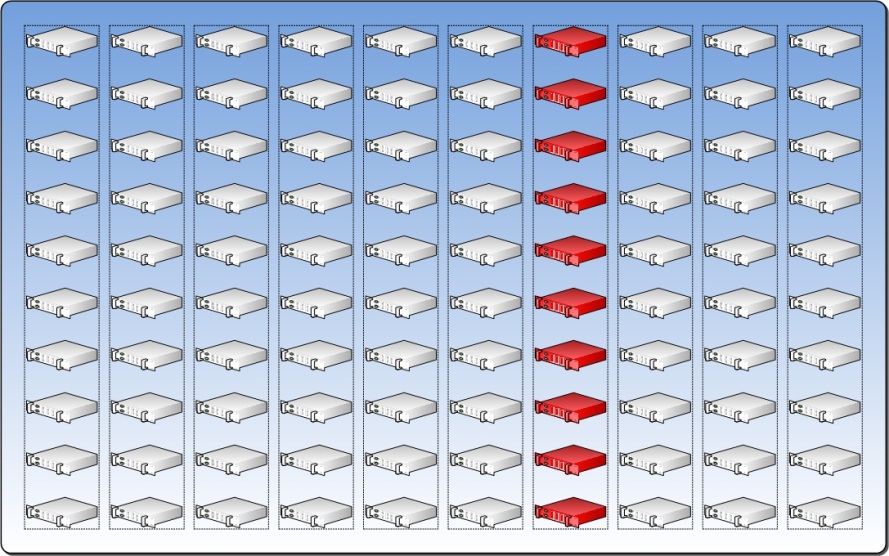
3.3 Upgrade Domain
Der Upgrade-Domain-Pattern gilt für alle drei Kategorien von Ressourcen im Rechenzentrum, Netzwerk, Rechen, und Storage.
Obwohl die VM eine Abstraktion von der physischen Server darstellt ist es ebenso notwendig Update oder Upgrade der physischen Server durchzuführen. Die Upgrade-Domain-Pattern kann verwendet werden um dies ohne Ausfall sicherzustellen, indem die Ressourcen-Pool in kleine Gruppen genannt Upgrade-Domains zusammen gefasst werden. Alle Server in einer Upgrade-Domain werden gleichzeitig aktualisiert und jede Gruppe kann gezielt aktualisiert werden.
Dieses erlaubt Workloads weg von der Upgrade-Domain zu migrieren und nach der Aktualisierung wanderten der Workload wieder auf den ursprünglichen Ressourcenpool zurück.
Im Idealfall würde ein Upgrade der Pseudo-Code-Algorithmus unten folgen:
For each ResourceDomain in n;
Free from workloads;
Update hardware;
Reinstall OS;
Return to Resource Pool;Next;
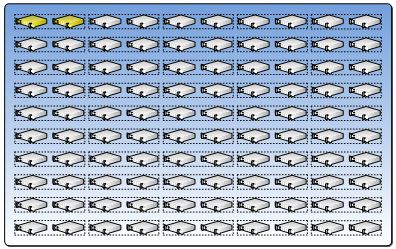
Das gleiche Konzept gilt für das Netzwerk. Da das Design des Rechenzentrums auf einem redundanten Netzwerkdesign basiert kann eine Upgrade Domain für alle primären Switche (oder eine Subnetze) und eine andere Upgrade Domain für die secondary Switche definiert werden. Das gleiche gilt für die Storage Infrastruktur.
3.4 Reserve Capacity
Der Vorteil eines homogenisierten Ressourcenpool-basierten Ansatzes ist, dass alle VMs auf die gleiche Weise auf einem beliebigen Server im Pool laufen können. Dies bedeutet, dass bei einem Fehler, jede VM zu jedem physischen Host, verlegt werden kann so lange für diese VM Kapazität zur Verfügung steht. Festlegung, wie viel Kapazität reserviert werden muss, ist ein wichtiger Bestandteil bei der Entwicklung eines Designs für eine Private Cloud. Das Reservekapazitäts Pattern verbindet den Begriff des Ressource Abfall mit dem Fault Domain und Upgrade- Domain-Pattern, um die Menge der benötigten Reservekapazität eines Ressourcenpool zu bestimmen.
Zum ermitteln der Reservekapazität gehen Sie wie folgt vor:
TOTALSERVERS = the total number of servers in a Resource Pool
ServersInFD = the number of servers in a Fault Domain
ServersInUD = the number of servers in an Upgrade Domain
ServersInDecay = the maximum number of servers that can decay before maintenance
Die Formel ist: Reserve Capacity = ServersInFD + ServersInUD + ServersInDecay / TOTALSERVERS
Diese Formel trifft ein paar Annahmen:
- Es wird davon ausgegangen, dass nur eine Fault Domain scheitert. Der Kunde kann wählen, dass die Reserverkapazität erhöht wird, so dass mehr als eine Fault Domain gleichzeitig ausfallen kann. Dieses lässt jedoch mehr Kapazität ungenutzt.
- Zweitens, wenn wir nur einen Fault Domain verwenden nehmen wir an, dass der Ausfall mehrerer Fault Domains den Desaster Recovery-Plan auslöst und nicht den Fault Management Plan.
- Sie geht von einer Situation aus bei der eine Fault Domain ausfällt, wobei einige Server ausfallen und einige andere Server auf Grund von Upgrades in einer Upgrade Domain befinden.
- Schließlich geht die Formal davon aus das keine Überkapazitäten vorhanden sind.
In der Formel ist die Anzahl der Server in der Fault Domain eine festgelegte Konstante. Die Anzahl der Server die Ausfallen dürfen und die Anzahl der Server in einer Upgrade-Domain sind variabel und werden durch den Architekten festgelegt. Der Architekt muss die Reservekapazität so ausbalancierend, dass die Reservekapazität so ausgelegt ist, dass nicht zu einer schlechten Auslastung kommen kann. Wenn ein Upgrade Domain zu groß gewählt wird so wird die Reservekapazität hoch sein. Wenn die Upgrade Domian zu klein ist, werden die Upgrades einen längere Zeit in Anspruch nehmen Zyklus für den Ressourcen-Pool. Ein zu kleiner Prozentsatz Ausfall ist unrealistisch und kann eine häufige Wartung der Ressourcen-Pools bedeuten, während ein zu hoher Prozentsatz Ausfall bedeutet, dass die Reservekapazität zu hoch sein wird und dadurch unnötige Rechenkapazität vorhanden ist.
Es gibt keine "richtige" Antwort auf die Frage der Reservekapazität. Es ist Aufgabe des Architekten festzustellen, was am wichtigsten ist für den Kunden und dann maßgeschneidert die Reservekapazität in Übereinstimmung mit den Bedürfnissen des Kunden zu bestimmen.
Die Berechnung der Reservekapazität auf Basis der von uns genannten Beispiele würde in Zahlen wie folgt aussehen::
TOTALSERVERS = 100
**ServersInFD = 10
ServersInUD = 2
ServersInDecay = 3
Reserve Capacity = 15%
**Die folgende Abbildung zeigt die Verteilung der 15% Reservekapazität.
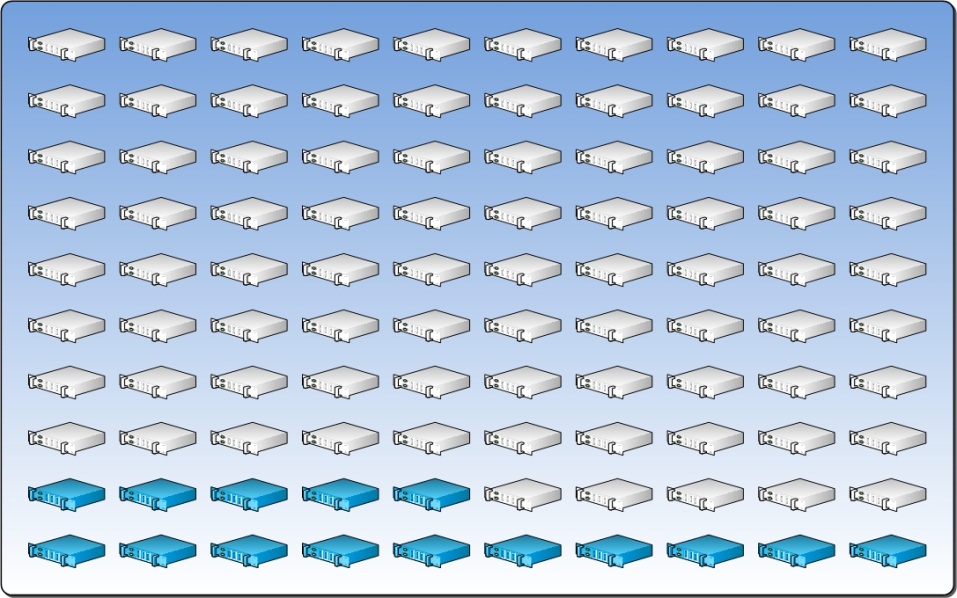
3.5 Scale Unit
Ab einem bestimmten Punkt muss neue Kapazität zum Rechenzentrum hinzugefügt werden. Dieser Punkt ist dann erreicht wenn die genutzte Kapazität nahe an der zur Verfügung stehenden Gesamtkapazität kommt (Gesamtkapazität - Reservekapazität). An einem gewissen Punkt, die Menge der Kapazität genutzt wird beginnen, um nah an der gesamten verfügbaren Kapazität (soweit verfügbar Kapazität entspricht der Gesamtkapazität abzüglich der Reserve Capacity) und neuen Kapazitäten werden müssen bis hin zum Rechenzentrum hinzugefügt werden. Im Idealfall wird der Architekt die Erhöhung des Ressourcen-Pool in standardisierten Schritten, mit bekannten ökologischen Anforderungen (wie Raum, Strom und Kühlung) unter Berücksichtigung der Vorlaufzeit für die Beschaffung auf Basis von standardisierter Technik (wie Regale, Verkabelung und Konfiguration), definieren. Ferner muss die zusätzliche Kapazität ein Gleichgewicht des zu erwartenden Wachstums und der unbenutzten Rechenkapazität sein. Damit der Architekt die optimal ausnutzen kann wird er das Scale Unit Pattern nutzen.
Die Scale-Unit stellt eine standardisierte Einheit dar die zu einem Rechenzentrum hinzugefügt wird. Es gibt zwei Arten von Scale-Unit, ein Scale-Computer Unit enthält Server-und Netzwerk , Storage Scale-Unit die Storage-Komponenten umfasst. Scale-Units zur Erhöhung der Kapazität mit einem standardisiertem Design sind die zuverlässigste, konsistenteste Art und Weise die Kapazität zu erhöhen.
Ähnlich wie die Reservekapazität, wird die Größenanpassung der Scale-Unit dem Architekten überlassen.
3.6 Capacity Plan
Das Capacity-Plan Pattern nutzt das Infrastruktur Pattern, welches oben beschrieben ist, zusammen mit dem Bedarf des Business, um sicherzustellen das die Kapazität erfüllt werden können.
Das Capacity-Plan Pattern kann nicht alleine durch IT beschrieben werden, sondern muss regelmäßig mit den Anforderungen des Business überprüft werden.
Die Kapazitätsplanung muss die Spitzenleistung wie z. B. Weihnachtsgeschäft in die Planung mit einbeziehen. Es muss ebenso für typische sowie beschleunigtes Wachstum des Unternehmens, wie z. B. geschäftliche Expansion, Fusionen und Übernahmen und Erschließung neuer Märkte betrachtet werden.
Die Kapazitätsplanung muss die aktuelle verfügbare Kapazität kennen um definieren zu können wann die Beschaffung von zusätzlichen Kapazitäten eingeleitet werden muss.
Diese Auslöser sollten durch die Menge der Kapazität die jede Einheit bietet und die Vorlaufzeit für den Kauf, Beschaffung und Installation einer neuen Einheit definiert werden.
Die Voraussetzungen für eine gut durchdachte Kapazitätsplanung kann nicht ohne einen hohen Grad an IT Service Management-Reife und einer engen Abstimmung zwischen Business und IT erreicht werden.
3.7 Health Model
Um Ausfallsicherheit zu gewährleisten, muss ein Rechenzentrum in der Lage sein, automatisch zu erkennen, ob eine Hardware-Komponente ausgefallen ist oder bestimmte Anforderungen nicht mehr erfüllt (z. B. SAN Schreib-/Lesefehler).
Dieses erfordert ein Verständnis wie alle Hardware-Komponenten mit dem bereitgestellten Service zusammenarbeiten und interagieren.
Das Health-Modell-Pattern beschreibt das Verständnis dieser Zusammenhänge welche von einer Management-Ebene genutzt werden kann, um zu bestimmen welche VMs von einem Hardware-Komponente Ausfall betroffen sind.
Diese erleichtert dem Datacenter-Management-System die Aufgabe zu ermitteln ob eine automatische Maßnahmen erforderlich ist, um den Ausfall von VMs zu verhindern oder ausgefallene VMs schnell wieder auf einem anderen System herstellen zu können.
Aus einer erweiterten Perspektive muss das Management-System den Ausfall nach Ressourcen Fehler, physikalischer Fault Domain Fehler oder generelles Versagen der gesamten Infrastruktur klassifizieren um ein entsprechende Disaster-Recovery-Reaktion auszulösen.
Bei der Erstellung des Health-Modell, ist es wichtig, die Verbindungen zwischen den Systemen einschließlich der Anschlüsse an die Stromversorgung, Netzwerk-und Storage-Komponenten zu berücksichtigen.
Der Architekt muss auch den Datenzugriff prüfen, unter Berücksichtigung der Verbindung zwischen den einzelnen Systemen. Zum Beispiel, wenn ein Server nicht auf die richtige Logical Unit Number (LUN) zugreift, kann der Dienst ausfallen oder mit einer verminderten Leistung arbeiten. Schließlich muss der Architekt verstehen, wie sich verminderte Leistungsfähigkeit auf das System auswirken kann. Zum Beispiel, wenn das Netzwerk ausgelastet ist (Nutzung größer als 80%) kann das Auswirkungen auf die Leistung kommen, die das Management-System benötigen, um VMs auf neue Hosts zu bewegen.
Es ist wichtig zu verstehen, wie man proaktiv sowohl die Gesundheit als auch den Ausfall in einer vorhersagbaren Reihenfolge.
Die folgenden Diagramme zeigen typische Systeme und Zusammenhänge wie die Health-Modell-Pattern verwendet werden, um Ausfallsicherheit zu bieten.
In diesem Fall ist die Stromversorgung der Single Point of Failure. Netzwerkverbindungen und Fiber-Channel-Verbindungen zum Storage Area Network (SAN) sind redundant ausgelegt.
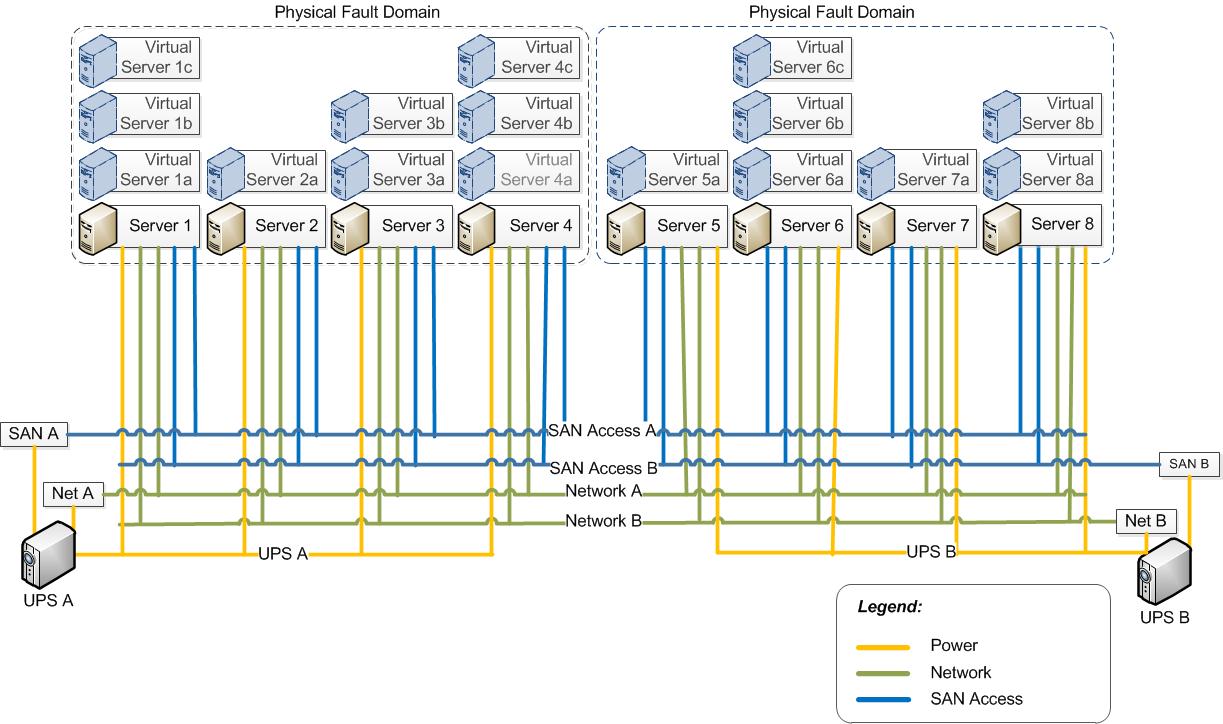
Wenn die Stromversorgung "USV A" ausfällt, fallen die Server 1-4 aus. Ebenso fällt "Network A" und "Fibre Chanel A" aus aber durch die redundante Auslegung fäält nur eine Fault Domain aus. Die anderen verlieren "nur" ihre Hochverfügbarkeit.

Das Management System erkennt den Fault Domain Ausfall und migriert oder startet die entsprechenden Workloads auf einer Funktionsfähigen Physical Fault Domains.
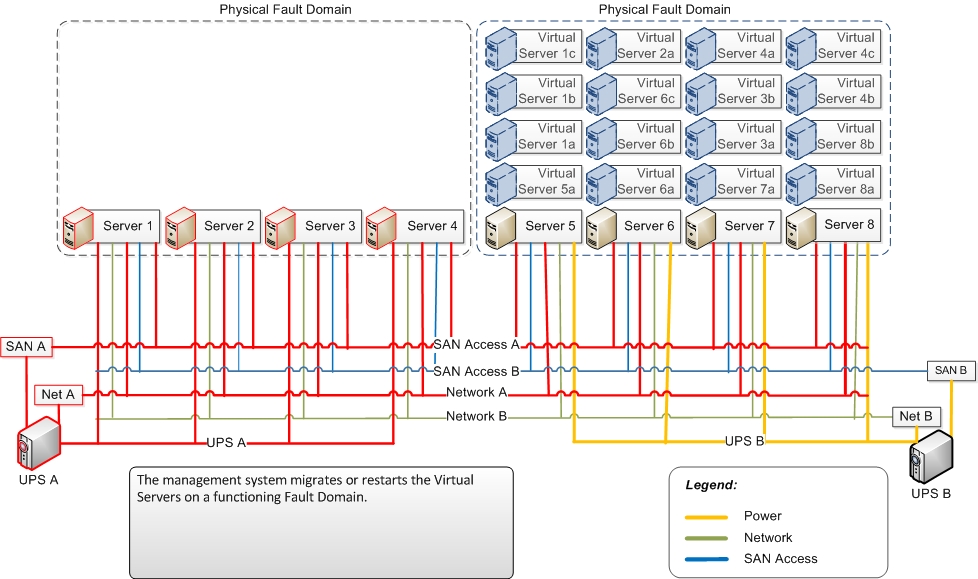
Während das Konzept eines Health-Modell nicht eindeutig ist, dadurch wird die Bedeutung dieses Modelles noch kritischer in einem Rechenzentrum. Um die notwendige Auswirkungen von Fehlermeldungen (ein Hinweis, dass ein Fehler aufgetreten ist) und Warnhinweisen (ein Hinweis darauf, dass ein Ausfall schnell auftreten kann) zu verstehen, muss man die Cloud-Infrastruktur gründlich verstehen.
Das Erkennen und Reagieren auf die verschiedenen Statusmeldungen muss verstanden, dokumentieren und automatisiert werden. Nur dann können die Vorteile der Flexibilität voll ausgeschöpft werden.
Diese dynamische Infrastruktur, die automatisch Workloads zwischen verschiedenen Fabrics auf Grund von Statusmeldungen bewegen kann, ist nur der erste Schritt in Richtung dynamische IT. Anwendungen die für mehr Ausfallsicherheit ausgelegt sind, sollte sie ebenso in das Health Models integriert werden. D. h. die Anwendung muss ebenfalls Schnittstellen zur Verfügung stellen damit eine Überwachung auf Anwendungseben stattfinden kann.
3.8 Service Class
Service Class Pattern sind nützlich bei der Beschreibung wie verschiedene Anwendungen mit dem Cloud-Plattform-Infrastruktur zu interagieren.
Während jede Umgebung einzigartige Kriterien für ihre Service-Klassen-Definitionen zu beschreibt, gibt es in der Regel drei Service Class Pattern, die die meisten Verhaltensweisen von Anwendungen und Abhängigkeiten beschreiben.
Das erste Service Class Pattern wird für stateless Anwendungen konzipiert. Es wird angenommen, dass die Anwendung für eine entsprechende Redundanz ausgelegt ist. Für dieses Pattern wird die Redundanz in der Infrastruktur auf ein absolutes Minimum reduziert und somit ist dies die am wenigsten kostspielige Service Class-Pattern.
Der nächste Service Class Pattern ist für stateful Anwendungen konzipiert. Hierzu wird nur bestimmte Services von der Infrastruktur-Schicht bereitgestellt und Ausfallsicherheit wird durch Live-Migration des Service sichergestellt. Die Kosten für diesen Service Klasse ist höher, weil zusätzliche Hardware für die Redundanz benötigt wird.
Das letzte und teuerste Service Class-Pattern ist für jene Anwendungen, die nicht mit einer Cloud Infrastruktur kompatible sind. Diese Anwendungen, die nicht in einem dynamischen Rechenzentrum gehostet werden können, müssen mit der herkömmlichen Planung eines Rechenzentrums werden.
3.9 Cost Model
Das Cost-Modell-Pattern reflektiert die Kosten für die Erbringung von Services in der Cloud und dem gewünschten Konsumverhalten der Anbieter fördern möchte.
Dieses Pattern sollten die Errichtungs-, Betriebs-und Wartungskosten berücksichtigen weiterhin müssen die Kosten für die Bereitstellung jeder einzelnen Service-Klasse sowie Spitzenzeiten und zukünftiges Wachstum berücksichtigen werden.
Das Cost-Modell-Pattern sollte auch die Einheiten definieren die für die Nutzung des einzelnen Service berechnet werden.
Den Einheiten für die Nutzung der einzelnen Services wird eine Messung der Rechen-, Storage-und Netzwerk für jeden Workload der Service Class zu Grunde gelegt. Dieses Pattern kann als Teil einer verbrauchsabhängigen Gebühr verwendet werden. Organisationen, die kein Modell für die Berechnung von IT-Dienste nutzen, sollte dennoch Einheiten für den Verbrauch im Rahmen einer fiktiven Aufladung nutzen. (Eine Fiktive Aufladung dient dazu dem Nutzer der Services zu zeigen welche Kosten er für die Nutzung zahlen müsste, ohne dass tatsächlich eine Abrechnung stattfindet).
Das Kostenmodell fördert das Verhalten der Nutzer auf zwei Arten:
Erstens, durch die Erhebung von fiktiven Kosten für die Nutzer basierend auf Grund des Verbrauches werden sie wahrscheinlich nur die Menge der Ressourcen nutzen die sie benötigen. Wenn sie vorübergehend weniger Ressourcen benötigen werden sie diese wahrscheinlich wieder freigeben.
Zweitens, indem wir verschiedene Modelle auf Kosten-Service-Klasse basiert zur Verfügung stellen werden die Nutzer ermutigt Anwendugen zu kaufen die für den kostengünstigsten Service qualifizieren sind.
REFERENCES:
ACKNOWLEDGEMENTS LIST:
If you edit this page and would like acknowledgement of your participation in the v1 version of this document set, please include your name below:
[Enter your name here and include any contact information you would like to share]
Discuss the Private Cloud Principles, Patterns, and Concepts on the Private Cloud Architecture TechNet Forum