HDInsight の開発
このポストは、3 月 22 日に投稿された Developing for HDInsight の翻訳です。
Windows Azure HDInsight は、ビッグ データを処理するために、Apache Hadoop を実行するクラスターを動的にプロビジョニングする機能を提供します。詳細は、本シリーズの第 1 回の記事を参照してください。Windows Azure ポータルから HDInsight の使用を始める際には、こちらの記事が参考になります。今回の記事では、開発者が HDInsight の操作に使用できるさまざまな方法を紹介します。まず、種類の異なるシナリオを挙げ、次にそれを基に HDInsight の多彩な機能を解説します。HDInsight は Apache Hadoop を基盤として作成されているので、活用できるツールや機能に関しては充実した大規模なエコシステムが存在します。
シナリオについては、これまでのお客様との経験から、2 種類の異なるシナリオが特定されています。ジョブを作成するシナリオでは、ユーザーがツールを使ってビッグ データを処理します。HDInsight をアプリケーションに統合するシナリオでは、ジョブの入力および出力をより大規模なアプリケーション アーキテクチャにその一部として組み込みます。HDInsight の設計の重要なポイントに、Windows Azure BLOB ストレージが既定のファイル システムとして統合されるという点があります。これは、BLOB ストレージ内のデータにアクセスするための既存のツールと API を、データ操作に使用できることを意味します。こちらのブログ記事では、BLOB ストレージの活用を詳しく説明しています。
ジョブを作成する場合、利用できるツールはたくさんあります。大まかに分類すると、既存の Hadoop エコシステムの一部であるツール、.NET 開発者が Hadoop を使用できるようにマイクロソフトが実施しているプロジェクト、JavaScript を使って Hadoop を操作するためにマイクロソフトが始めた取り組みがあります。
ジョブを作成する
既存の Hadoop ツール
HDInsight は Hortonworks Data Platform を介して Apache Hadoop を活用するので、Hadoop エコシステムへの忠実性がかなり高くなっています。このため、多くの機能はそのままで動きます。つまり、以下に示すようなツールへの投資やそこから得られた知識は、いずれも HDInsight に活用することができるのです。クラスターは、次のような分散処理用の Apache プロジェクトを使用して作成します。
- Map/Reduce (英語)
- Map/Reduce は Hadoop 内の分散処理の基盤となるものです。ジョブの作成には Java (英語) を使用するか、Hadoop Streaming (英語) の使用を通じて他の言語とランタイムを活用できます。
- HDInsight での Map/Reduce ジョブの作成については、こちら (英語) の簡単なガイドを参照してください。
- Hive (英語)
- Hive は、一連の Map/Reduce プログラムにコンパイルされるクエリを SQL に似た構文で表現します。また、SQL で想定される構造 (集約、グループ化、フィルター処理など) の多くをサポートし、クラスター内のノード間での並列化を簡単に行うことができます。
- Hive の使用についてのガイドは、こちら (英語) にあります。
- Pig (英語)
- Pig は、Pig Latin という言語を使用して一連の Map/Reduce プログラムにコンパイルされるデータフロー言語です。
- HDInsight での Pig の使用についての入門ガイドは、こちら (英語) にあります。
- Oozie (英語)
- Oozie は、アクションの有向非巡回グラフを管理するためのワークフロー スケジューラです。ここでのアクションとは、Map/Reduce、Pig、Hive などのジョブです。詳細については、クイックスタート ガイド (英語) を参照してください。
最新の Hadoop コンポーネントの一覧はこちら (英語) から参照できます。以下の表は、現在のプレビュー版での各バージョンを示しています。
Apache Hadoop |
1.0.3 |
Apache Hive |
0.9.0 |
Apache Pig |
0.9.3 |
Apache Sqoop |
1.4.2 |
Apache Oozie |
3.2.0 |
Apache HCatalog |
0.4.1 |
Apache Templeton |
0.1.4 |
さらに、Mahout (こちらのサンプル (英語) を参照) や Cascading (英語) など、Hadoop 分野の他のプロジェクトも HDInsight 上で簡単に使用できます。これらのトピックについては、今後、改めてブログで説明する予定です。
.NET ツール
マイクロソフトは、.NET で培われたスキルや .NET への投資を Hadoop の使用に活用できるようにするために、各種のツールの作成に取り組んでいます。これらのプロジェクトは CodePlex で提供されており、NuGet から入手できるパッケージを使用して、HDInsight 上で実行するジョブを作成できます。これらの説明については、CodePlex サイト (英語) で入門ページを参照してください。
ジョブの実行
上記のジョブを実行する方法として、次のような選択肢があります。
ヘッド ノードから直接ジョブを実行する。クラスターに RDP で接続し、Hadoop コマンド プロンプトを開き、コマンド ライン ツールを直接使用します。
リモートから REST API を使用してジョブをクラスターに発行する。詳細については、以下の「HDInsight をアプリケーションに統合する」セクションを参照してください。
HDInsight ダッシュボード上のツールを活用する。クラスターを作成した後、クラスターのダッシュボードには、ジョブ発行のために次のような機能が提供されます。
- ジョブの作成
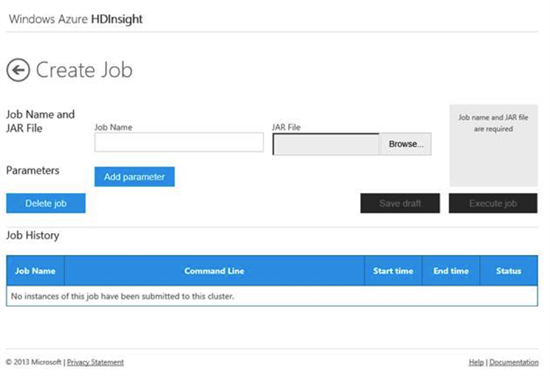
- 対話型コンソール
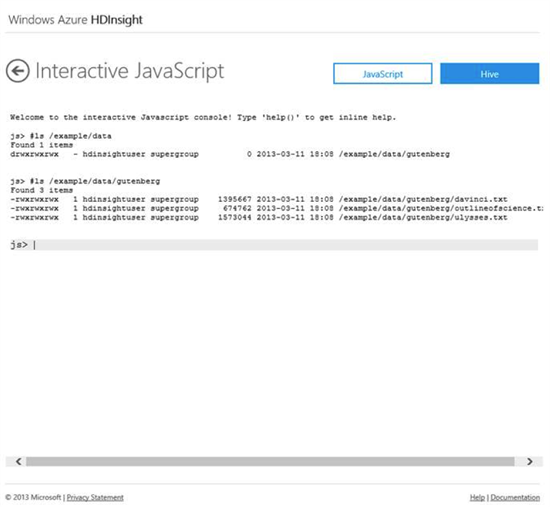
HDInsight をアプリケーションに統合する
オープン REST API
マイクロソフトでは、統合を行うクライアント アプリに対して単純な表面層を提供するため、クラスター上のすべての機能が安全な REST API セットを介して公開されるように努めました。
- WebHCatalog (英語) -- メタデータ管理と、リモート ジョブの発行、履歴、管理
- Ambari (英語) -- 実行中のクラスターの監視
- Oozie (英語) -- Oozie ワークフローの管理とスケジュール設定
現在、.NET クライアントをこれらの API (こちら (英語) から利用可能) に提供しています。これにより、HTTP 部分に他の言語を使うクライアントも簡単に構築できます。
ODBC 経由の接続
ODBC クライアントを活用すれば (こちらの説明 (英語) を参照)、既存のアプリケーション (Excel) と、HDInsight の Hive テーブルに保管されているデータを簡単に統合できます。
デバッグとテスト
マイクロソフトは、Azure で実行されるクラスターに接続せずに作業できる環境を実現するために HDInsight Developer Preview を提供しています。このプレビュー版は 1 つのセットアップとしてまとめられており、Web Platform Installer から簡単にインストールできます。これを使えば、上記のいずれのテクノロジについても、少ないデータで実験、デバッグ、テストを行うことができます。完成したら Azure に展開し、BLOB ストレージ内のビッグ データに対して改めて実行します。このプレビュー版のインストールは、Web Platform Installer の中で HDInsight を検索すれば簡単にできます。こちらをクリックして Web から直接インストールすることもできます。
まとめ
この記事では、Hadoop ジョブを作成する手段、および HDInsight をアプリケーションに統合する手段として、多くの選択肢があることを説明しました。HDInsight の開発には、自分の好きなプラットフォームとツール (Java から .NET、JavaScript まで幅広く) を使用できます。また、基盤となるクラスターは Windows Azure で簡単に展開および管理できます。
HDInsight シリーズ (全 5 回) の最終回では、HDInsight と Excel でデータを分析する方法を説明します。引き続きご注目ください。