All About Iterators
Design patterns have been all of the rage for a number of years now. We have design patterns for concurrency, user interfaces, data access, object creation, and so many other things. The seminal work on the topic is the Gang of Four's book, Design Patterns. When used appropriately they are a fantastic way to codify the wisdom gleaned from the battles we have fought building software systems.
One of the criticisms leveled at design patterns is that they are simply formalisms to address weaknesses in programming languages. They require the human compiler to generate code whenever a specific recurring problem is encountered that cannot be solved directly with language support. Now this might sound like heresy to some, but there is some truth to the criticism. Programmers adapt to the shortcomings in the languages they use by generating pattern like code either by hand or with metaprogramming (generics, dynamic code generation, reflection, expression trees, macros).
Let's take a look at one such example.
The Iterator Design Pattern
Among the many patterns in the literature is the iterator pattern.
In .NET this pattern is embodied by IEnumerable/IEnumerable<T> and IEnumerator/IEnumerator<T>.

An IEnumerable<T> is something that can be enumerated (iterated) by calling GetEnumerator which will return an IEnumerator<T> (iterator). The IEnumerator<T> is used to move a virtual cursor over the items that are iterated.
Implementing the iterator pattern is a bit onerous. For example, here is the suggested iterator implementation for List<T> from the Design Pattern book.
class ListIterator<T> : IEnumerator<T>
{
List<T> list;
int current;public ListIterator(List<T> list)
{
this.list = list;
current = -1;
}public T Current { get { return list[current]; } }
public bool MoveNext()
{
return ++current < list.Count;
}public void Reset()
{
current = -1;
}
}
Since we can't change the list itself, we can introduce a ListIterable<T> that wraps a list.
class ListIterable<T> : IEnumerable<T>
{
List<T> list;public ListIterable(List<T> list)
{
this.list = list;
}public IEnumerator<T> GetEnumerator()
{
return new ListIterator<T>(list);
}}
And finally, we can write a method called GetElements which returns an IEnumerable<T> over the elements of a List<T>.
static IEnumerable<T> GetElements<T>(this List<T> list)
{
return new ListIterable<T>(list);
}
Iterators in C#
Fortunately in most cases programmers don't need to deal with the iterator design pattern directly since the introduction of iterators in C# 2.0. Instead of writing the iterator above, we can simply write the following:
static IEnumerable<T> GetElements<T>(this List<T> list)
{
for (int index = 0; index < list.Count; ++index)
yield return list[index];
}
When the C# compiler sees this method, it translates it into something very similar to the ListIterator<T> and ListIterable<T> above. Using Reflector or ILDasm we can see that the GetElements method is rewritten as (the names have been changed for clarity as the compiler generates unspeakable names;):
private static IEnumerable<T> GetElements<T>(this List<T> list)
{
GetElementsIterator<T> temp = new GetElementsIterator<T>(-2);
temp.listParameter = list;
return temp;
}
This is remarkably closer to the first GetElements we wrote rather than the second. Like in the first GetElements, we create an object that implements IEnumerable<T> and parameterize this object with the list that was passed in. The only other thing that happens in this implementation that doesn't in the first GetElements method is a -2 is passed into the object. I'll come back to this later, but first let's take a look at the GetElementsIterator<T> class (I omitted a few details and changed names for clarity).
private sealed class GetElementsIterator<T> : IEnumerable<T>, IEnumerator<T>
{
int state;
T current;
public List<T> listParameter;
int initialThreadId;
public int index;
public List<T> list;public GetElementsIterator(int state);
private bool MoveNext();
IEnumerator<T> IEnumerable<T>.GetEnumerator();
void IEnumerator.Reset();T IEnumerator<T>.Current { get; }
}
The most important thing to note at this time is that GetElementsIterator implements both IEnumerable<T> and IEnumerator<T>. A strange combination, but we will see why in a little while. Now let's look at what actually happened when we ran the constructor.
public GetElementsIterator(int state)
{
this.state = state;
this.initialThreadId = Thread.CurrentThread.ManagedThreadId;
}
Did the constructor run the for loop? No, it didn't. It took some variable called state in and marked what thread created the iterator (if you look at Whidbey code the initialThreadId stuff won't be there...I'll get to that). The state variable marks what state the GetElementsIterator is in. The number -2 is the "I'm an IEnumerable<T>" state. Now, let's look at the GetEnumerator method.
IEnumerator<T> IEnumerable<T>.GetEnumerator()
{
GetElementsIterator<T> temp;
if ((Thread.CurrentThread.ManagedThreadId == initialThreadId) && (state == -2))
{
state = 0;
temp = this;
}
else
{
temp = new GetElementsIterator<T>(0);
}
temp.list = this.listParameter;
return temp;
}
The method first checks to see if the thread that is calling GetEnumerator is the same thread that created the GetElementsIterator object. If it is the same thread and if the GetElementsIterator is in the "I'm an IEnumerable<T>" state then the state is changed to the "I'm an initialized IEnumerator<T>" state. Otherwise, a new object of the same type is created but it is immediately put in the "I'm an initialized IEnumerator<T>" state so that thread safety is maintained. Finally, in either case the list that was passed from the GetElements method is copied into the list field for consumption by the MoveNext method.
In Whidbey code, you will see that the if statement is different because an Interlock.Exchange was used to perform the same task. The change was made to improve performance (especially for iterators that have 0 or 1 items to iterate over).
Now we have seen why GetElementsIterator implements both IEnumerable<T> and IEnumerator<T>, because it can morph from the IEnumerable<T> role into the IEnumerator<T> role without creating any new objects in most cases.
The Current property is very simple.
T IEnumerator<T>.Current
{
get
{
return current;
}
}
The Reset method simply throws a NotSupportedException.
This leaves us with only the MoveNext to examine. We still haven't seen where the for loop went. Hopefully, it is in the MoveNext. The following code is produced with the /o+ compiler option (optimizations turned on).
private bool MoveNext()
{
switch (state)
{
case 0:
state = -1;
index = 0;
break;case 1:
state = -1;
index++;
break;default:
goto Done;
}
if (index < list.Count)
{
current = list[index];
state = 1;
return true;
}
Done:
return false;
}
Hm...a switch statement over a variable called state with a number integer case labels. It looks like a state machine and indeed it is. When MoveNext is first called, state is equal to 0, so the state is set to -1 (the "I'm finished" state) and the index is set to 0. Then we check to see if the index is less than the number of things in the list. If so then we set current to the current list element based on the index and set the state to 1. We return true indicating that there is something to consume.
The second call to MoveNext will run case 1 since the state is equal to 1. It will again set the state to -1 and increment the index. If we still have elements in the list then the current will be set appropriately and the state will be set to 1 (the "we need to check again" state) and true will be returned.
This continues until there nothing left to consume and false is returned.
Finally, we found our for loop. It is encoded in the MoveNext. But note that on each call to MoveNext is only computes the part of the for loop that is relevant to realize the next element. It never computes more than it needs to. This is why iterators are an example of deferred execution. When the actual GetElements method was called, no elements were realized at all! Later as MoveNext is called, one element at a time is realized. This of course enables all of sorts of great scenarios such as the pay-as-you-go model and the ability to have infinite lists.
The Cost of Iterators
Iterators are very performant. In almost all situations that I have encountered they are more than performant enough and they simplify the code drastically as we have seen. But sometimes you can get into trouble.
Consider the definition of the Concat sequence operator in Linq to Objects. It looks something like this:
static IEnumerable<T> Concat<T>(this IEnumerable<T> sequence1, IEnumerable<T> sequence2)
{
foreach (var item in sequence1)
yield return item;
foreach (var item in sequence2)
yield return item;
}
Let's write a little benchmark to evaluate the performance of concat.
var stopWatch = new Stopwatch();
for (int length = 0; length <= 10000; length += 1000)
{
var list = new[] { 1 };
IEnumerable<int> ones = list;
for (int i = 0; i < length; ++i)
ones = ones.Concat(list);stopWatch.Reset();
stopWatch.Start();foreach (var item in ones) ;
stopWatch.Stop();
Console.WriteLine("Length: {0} Time: {1}", length, stopWatch.ElapsedMilliseconds);
}
The results may be perhaps surprising. The time to evalute the foreach statement is not linearly proportional to the number of concats that are composed together. In fact it is proportional to the square of the number of concats composed together.
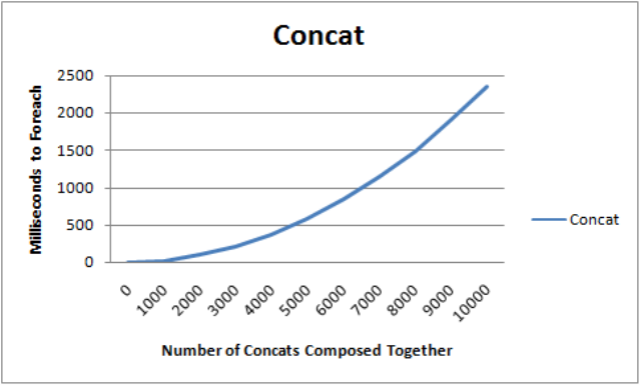
Upon closer inspection the reason why is obvious. The time complexity of Concat is O(m+n) where m is the number of items in the first sequence and n is the number of items in the second sequence. But note that in this example, n is always 1. The outermost call is O(m+1). The next call has O((m-1)+1), then O((m-2)+1), ... O(1+1). There are m of these calls so the running time should be O(m^2). Essentially, composing concats together like this causes O(m^2) yield returns to be executed.
Of course, using a List<T> here and adding on the sequences would have been much more performant because it eliminates the redundant calculations but it would not have been evaluated lazily.
Iterators are even more fun if the data structure that is being enumerated is more complicated. For example, consider iterating over n-ary trees. Here is a quick definition of a n-ary tree.
class Tree<T>
{
public T Value { get; private set; }
public Tree<T> NextSibling { get; private set; }
public Tree<T> FirstChild { get; private set; }public Tree(T value, Tree<T> nextSibling, Tree<T> firstChild)
{
Value = value;
NextSibling = nextSibling;
FirstChild = firstChild;
}public IEnumerable<Tree<T>> GetChildren()
{
for (var current = FirstChild; current != null; current = current.NextSibling)
yield return current;
}
}
Now it is easy to define an iterator that performs a preorder traversal of a n-ary tree.
static IEnumerable<T> PreOrderWalk<T>(this Tree<T> tree)
{
if (tree == null)
yield break;
yield return tree.Value;
foreach (var subTree in tree.GetChildren())
foreach (var item in subTree.PreOrderWalk())
yield return item;
}
Just the way that I like code: clear and concise. The only problem is that the iterator could be more efficient. This may or may not be a problem. In a library it will almost certainly be a problem.
We can improve the efficiency somewhat by changing the code:
static IEnumerable<T> PreOrderWalk<T>(this Tree<T> tree)
{
var stack = new Stack<Tree<T>>();
if (tree != null)
stack.Push(tree);
while (stack.Count > 0)
{
for (var current = stack.Pop(); current != null; current = current.FirstChild)
{
yield return current.Value;
if (current.NextSibling != null)
stack.Push(current.NextSibling);
}
}
}
This second iterator doesn't recursively call iterators thus avoiding both the recursive call and the extra allocations. Instead, it maintains a stack of work to do after the leftmost path has been exhausted. Once the leftmost path has been exhausted then a node is popped off and the leftmost traversal is resumed at that node.
When we measure the difference, we see that the improvement is noticeable but that the number of nodes, O(b^d) where b is the branching factor and d is depth, dominates the cost of the traversal. In the graph below, the green line indicates the total number of nodes in the tree. The trees have a branching factor of 2.

So the key takeaway here is that iterators have great performance but as always measure the performance of your code. If you find that performance is suffering, use a combination of profiling and analysis to find the problem. If the problem is an iterator, you might be able to increase the performance by reworking the iterator as in the n-ary tree case. In other cases, it might be the usage of the iterators as with pathological Concats.
One Possibility for Language Improvement (not in Orcas)
The Concat sequence operator is interesting because there is a lot of code that is seemingly redundant. It takes two sequences and then has to iterate over them and yield their elements. It's like it needs to expand their insides just to package them up together again. As we have seen this doesn't lead to the best performance and the code is overly verbose.
Bart Jacobs, Erik Meijer, Frank Piessens, and Wolfram Shulte wrote a very interesting paper on a possible language improvement that would improve both the usability and the performance of iterators. The second half of the paper details what they call nested iterators which avoid the multiple evaluation problem of the composed Concats and implicitly keep an internal stack like the modified n-ary tree iterator.
For example with this language feature, the Concat sequence operator would look something like this:
static IEnumerable<T> Concat<T>(this IEnumerable<T> sequence1, IEnumerable<T> sequence2)
{
yield foreach sequence1;
yield foreach sequence2;
}
Notice that the code is simplier and it is also more performant.
A programmer could use yield return, yield break, and yield foreach in the same iterator. An iterator FromTo can be defined recursively as follows:
static IEnumerable<int> FromTo(int b, int e)
{
if (b > e)
yield break;
yield return b;
yield foreach FromTo(b + 1, e);
}
If instead of the yield foreach, there was the foreach expansion that yielded each result then the FromTo method would suffer from quadratic performance; however, with nested iterators the performance would be linear.

The next post will pick up on understanding the performance of Linq to objects queries.
Comments
Anonymous
March 22, 2007
In the LINQ forums way-back, I'd suggested "yield enumerable" instead of "yield foreach", with the same behavior, but I think I like the foreach version better.Anonymous
March 22, 2007
Hey, another great post. I find that a very large amount of my time is spent iterating over items in a list, so the introduction of templates to C# was definitely a major advantage to me. Another great article on custom iterators that I highly recommend is one written by Bill Wagner: http://msdn2.microsoft.com/en-us/vcsharp/bb264519.aspx And the article that originally introduced me to the idea (and I always carry a copy of the MSDN magazine it was in to use as a reference): http://msdn.microsoft.com/msdnmag/issues/06/00/c20/default.aspx By the way, completely offtopic, but I noticed that code in your <pre> tags are causing some font issues with Firefox. I didn't dig into it too much, but the code is extremely small and hard to read. My guess would be that it's inheriting from its parent with a font-style of something like 0.8em.Anonymous
March 23, 2007
Sean: Thanks for the heads up about the size of the code. I guess now it's out that I don't use Firefox, I'll fix it.Anonymous
March 23, 2007
I've updated the page based on Sean's feedback. I guess when I was copying and pasting code from Reflector into Windows Live Writer that it didn't work as well as I would have liked ;). Thanks again Sean.Anonymous
March 23, 2007
Any time! You've helped me a ton. That's why I subscribe to your blog. ;-) By the way, looks great now.Anonymous
April 07, 2007
Hi Wes, I was wondering how you would compare IEnumerable to implementing an abstract ForEach method in a base class? For example: http://functional-lists.googlecode.com/svn/trunk/FunctionalList.cs Which one is likely to have better performance? What reasons would you choose one over the other? Cheers, Christopher DigginsAnonymous
April 08, 2007
Recently my time has been taken up with a series of internal issues involving Beta1, C# Samples and variousAnonymous
April 10, 2007
Hi Christopher, Hope everything is going well. I expect that the typical IEnumerable + static Foreach will do better in performance. But try it out and tell me. Specifically, try out the performance of your code against the latest LINQ CTP or Beta 1. Also, you might want to consider making your code generic (add some Ts and Us).Anonymous
April 11, 2007
Hi Wes, Your code for MoveNext() assigns this.current from an element in this.list. Your comments claim that MoveNext() only computes enough to realize the next element. But hasn't this.list been filled before the first call to MoveNext()? thanks, peterAnonymous
April 11, 2007
Now I get it. The compiler generates different versions of MoveNext() based on the code that was in the original GetElements() method. Just like you said in the text. thanks,Anonymous
May 16, 2007
When is your next article going to be posted? I'm checking this site daily for almost two months now :)Anonymous
June 16, 2007
It's fun. I "invented" the concept of iterators some time ago not knowing about this feature. Will VB ever have it?Anonymous
December 19, 2007
Lots of good comments on my previous post. To briefly follow up: One of the downsides of immutable treeAnonymous
December 19, 2007
Lots of good comments on my previous post. To briefly follow up: One of the downsides of immutable treeAnonymous
January 03, 2008
> Will VB ever have it? do you mean vb.net or vb6?Anonymous
January 11, 2008
The performance of the Concat method for multiple chained iterators could be greatly improved with a fairly trivial tweak. Simply create a container class to hold all of the concatenated iterators, and iterate over them all in sequence: foreach (IEnumerable<T> iterator in iterators) foreach (T item in iterator) { yield return item; } On my system, using your test code, the built-in Concat method for 10000 items takes 4807629 ticks, whereas my version takes 4472 ticks.Anonymous
August 10, 2010
I hope this feature can get into C# 5.0