Revisitando a Persistência - LINQ, Entity Framework, Object-relational mapping, entre outros.
Olá pessoal, tudo certo?
Falar de LINQ e persistência de dados é mesmo desafiador? Estive navegando pela Web e existem diversos blogs, artigos, whitepapers, pdf's, ppt's, wikis e exemplos que realmente deixam o leitor confuso. E algumas perguntas ainda aparecem no meio da discussão, como: "usando LINQ, onde é melhor colocar minha lógica de negócio, em banco de dados ou em componentes extra banco?" ou ainda "para toda arquitetura devo utilizar um modelo de persistência e mapeamento relacional?" e outras como "Qual a diferença entre LINQ, XPO, SubSonic, Ibatis, Nhibernate ou algo doméstico?".
Bom, este post não pretende esgotar o assunto, mas colocar uma rápida visão sobre o tema, com um foco sobre o ADO.NET Entity Framework e seus componentes. Para começar, vamos rever algumas definições.
Revisitando a persistência
Quando falamos em persistência de dados pensamos no armazenamento "eterno" dos dados, ou seja, enquanto o dispositivo físico de armazenamento dure. Quando se grava um arquivo no disco, por exemplo, o dado está sendo "eternizado" ou "persistido", deixando de ser volátil na memória RAM e passando a ser escrito num dispositivo que armazena a informação de modo que ela não desapareça facilmente.
Assim, podemos dizer que a persistência de dados envolve um meio físico que permita recuperação de dados, como um banco de dados, um arquivo em disco, etc, o que garante a persistência das informações e sua posterior recuperação. Ao longo da execução de um sistema, a persistência de dados é fator crítico, pois determina o modelo de acesso aos dados persistidos, assim como o desempenho, a facilidade de acesso, a dificuldade de manutenção, a capacidade de rastreabilidade dos dados, o modelo de programação, etc.
De modo geral, o modelo de persistência mais comum no mercado é o baseado em banco de dados relacional, onde através de SQL (Structured Query Language), fazemos a navegação pelos dados persistidos. Nossas consultas são escritas em SQL e executadas sobre o banco, para a recuperação de informações específicas. Essa tecnologia é muito madura, difundida e padroniza, porém, apresenta muitos problema de acoplamento com a orientação a objetos. Vamos considerar que a orientação a objetos hoje é o modelo de programação de sistemas dominante. Assim, quando falamos sobre persistir nossos objetos de um modelo OO, falamos da persistência de objetos, o que exige um mapeamento. De fato, a persistência de objetos utilizando um modelo relacional envolve a discussão sobre o chamado Object-Relational Mappings, ou mapeamento Objeto-Relacional.
Revisitando o mapeamento objeto-relacional (ORM - Object-relational mapping)
Como vimos, o mapeamento objeto-relacional é uma técnica que visa diminuir a chamada impedância entre o modelo de objetos e o modelo relacional em banco de dados. Existe muita discussão em torno do assunto, já que alguns aspectos de ambos os modelos são conflitantes. Algumas vezes, você vai desejar um modelo de persistência que simplesmente faça a serialização de seus objetos para armazenamento. Em cenários de longo prazo, onde versionamento dos objetos persistidos é importante, você vai precisar ainda de algum mecanismo mais sofisticado, que faça um mapeamento objeto relacional considerando a versão dos objetos envolvidos.
Mas a necessidade de se tornar transparente a persistência de dados, instâncias de objetos e informações de sistemas OO é uma constante. Frequentemente somos confrotados com a decisão sobre utilizar uma camada de persistência de nossos dados ou simplesmente manter o acoplamento de classes com estruturas relacionais de forma explícita.
Por exemplo, quando pensamos num modelo objeto-relacional, pensamos numa tabela por classe, com artibutos primitivos representados por colunas. Da mesma forma, atributos complexos são representados por múltiplas colunas ou tabelas adicionais. E todo esse mapeamento é feito de forma transparente para o sistema, isolando o desenvolvedor desses detalhes durante a codificação da lógica de negócio. Agora, algumas otimizações ainda podem ser necessárias no modelo objeto-relacional, como reduções e transformações de schemas, para eliminação de colunas redundantes, validações, verbalizações para eliminação de ambiguidades, entre outras.
Visitando o ADO.NET Entity Framework
Depois dessa introdução, vamos falar um pouco sobre o ADO.NET Entity Framework. Ele está disponível através do link abaixo:
ADO.NET Entity Framework Beta 3
Ref.: https://www.microsoft.com/downloads/details.aspx?FamilyId=15DB9989-1621-444D-9B18-D1A04A21B519&displaylang=en
Você ainda vai precisar de um pacote de ferramentas para trabalhar com ele, obtido aqui:
ADO.Net Entity Framework Tools Dec 07 Community Technology Preview
Ref.: https://www.microsoft.com/downloads/details.aspx?FamilyId=D8AE4404-8E05-41FC-94C8-C73D9E238F82&displaylang=en
De fato, o ADO.NET Entity Framework é um pacote que integra as funcionalidades do ADO.NET 2.0 (com seus mecanismos de DataSet, DataAdapter, DbConnection, DbCommand , etc), adicionando 2 novos componentes: o Entity Data Model e o LINQ - Language Integrated Query.
Veja a figura a seguir que representa bem o pacote:

De forma resumida, o Entity Framework permite o mapeamento do modelo relacional para o modelo de negócio orientado a objetos na aplicação. Assim, parte importante da arquitetura do Entity Framework são suas camadas internas: camada conceitual, camada de mapeamento e camada lógica. Essas 3 camada garantem o mapeamento ORM (Object-relational mapping) conforme discutido anteriormente:
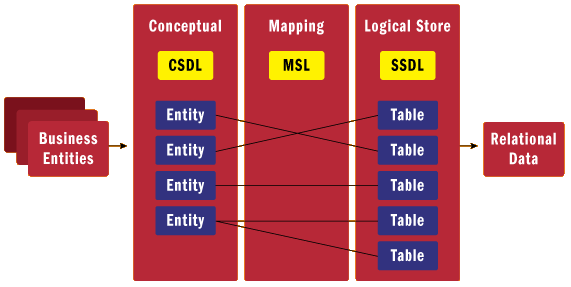
No ambiente do Visual Studio, esse mapeamento é disponibilizado através da ferramenta Entity Model Code Generator Tool, instalada com o pacote ADO.Net Entity Framework Tools, citado acima. Veja uma figura da ferramenta em ação:
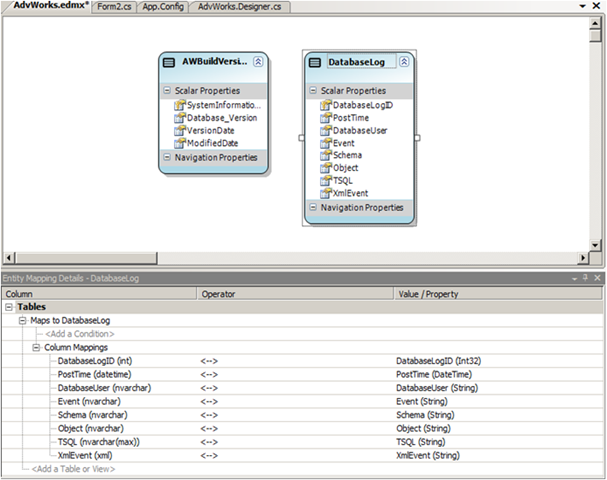
Observamos a parte inferior com o mapeamento entre colunas e propriedades das classes envolvidas no mapeamento objeto-relacional. Esse mapa é mantido pelo EDM - Entity Data Model presente na aquitetura.
Nesse contexto surge o LINQ. LINQ é um conjunto de recursos introduzidos no .NET Framework 3.5 que permite a realização de consultas diretamente em base de dados, documentos XML, estrutura de dados, coleção de objetos, etc. usando uma sintaxe parecida com a linguagem SQL. Como resultado, o desenvolvedor obtêm maior legibilidade no código final, assim como maior transparência sobre os detalhes de implementação de cada fonte de dados.
Assim, sobre o Entity Framework é possível aplicar consultas LINQ em uma de suas variações. Veja:

Alguns exemplos de variações LINQ são:
- LINQ to Objects
- LINQ to DataSets
- LINQ to SQL
- LINQ to Entities
- LINQ to XML
Cada variação ainda contempla as características da fonte de dados alvo.
Um exemplo de consulta LINQ to Entities segue abaixo:
string city = “London”;
var query = from c in northwindContext.Customers
where c.City == city
select c;
foreach (Customers c in query) Console.WriteLine(c.CompanyName);
Algumas considerações
Quando devemos utilizar um modelo objeto relacional para a persistência de dados? De fato, alguns desenvolvedores e arquitetos têm iniciado o uso de camadas de persistência ORM em todas as suas soluções. Isso é um erro. Um dos grandes problemas no uso dessa camada é o desempenho final obtido. Muitas vezes, devido a presença de mecanismos de cache durante a execução das consultas e retorno de objetos, uma camada ORM pode significar um desempenho deteriorado para a aplicação. Concordamos que muitos cenários não são aderentes ao modelo ORM por serem críticos quanto ao SLA definido. Nesses casos, o mais indicado é um middleware de banco de dados de alto desempenho. Precisamos entender que existem cenários onde a fronteira entre a lógica de programação e a camada de persistência de dados simplesmente não precisa ser escondida, ao contrário, é importante estar bem definida para os componentes da arquitetura. Um exemplo semelhante ocorreu na discussão do CORBA sobre os objetos distribuídos. As estruturas internas para tornar transparente a localização de um objeto ou esconder o fato de que tínhamos uma rede entre os componentes envolvidos trouxe grande complexidade para algumas soluções, assim como um desempenho ruim em muitos cenários.
Assim, devemos avaliar bem os benefícios de uma camada de persistência objeto relacional em nossa arquitetura, de acordo com as demandas reais de negócio que a solução irá atender. Entre os aspectos que podemos utilizar nessa decisão temos:
- Desempenho
- Manutenabilidade
- Legibilidade
- Rastreabilidade de dados
- Facilidade de Depuração
- Escalabilidade
- Presença de múltiplos bancos de dados na solução
- etc.
Em posts futuros vamos conversar mais sobre o assunto. Fique ligado!
Como referências adicionais, veja os links:
Object-relational mapping
Ref.: https://www.orm.net/ADO.NET Entity Framework & LINQ to Relational Data
Ref.: https://code.msdn.microsoft.com/adonetefx/ADO.NET Team blog
Ref.: https://blogs.msdn.com/adonet/Data Team blog
Ref.: https://blogs.msdn.com/data/
Por enquanto é só! Até o próximo post :)
Waldemir
Comments
Anonymous
March 24, 2008
Waldemir, Ótimo post. Tocou num ponto super polêmico, principalmente na comunidade .Net, acostumada a stored procedures e SQL ad-hoc. "De fato, alguns desenvolvedores e arquitetos têm iniciado o uso de camadas de persistência ORM em todas as suas soluções. Isso é um erro." Concordo, pois nenhuma solução encaixa em todos os problemas, mas convenhamos que na maioria dos sistemas de business temos uma grande chance de usar ORM. Poucos são os casos que precisamos eliminar camadas de abstrações para, em troca, obter melhores resultados. Tipagem forte, abstração, flexibilidade de mudança de DB, velocidade de desenvolvimento, código de negócio nas camadas corretas (não em banco), etc. são alguns dos pontos que faz o ORM uma camada extremamente útil. Só estou realçando esse ponto pois penso que a aceitação do ORM no mundo .Net está sendo lenta, quando na verdade já deveria ter acontecido a algum tempo (Lembra do ObjectSpace? Faz tempo...), pois como falei, existem vantagens em ter essa camada. A maioria dos argumentos para não usarmos ORM geralmente já não são mais válidos. Porém, mudar o modo de pensar dos desenvolvedores, esse sim é o grande desafio.Anonymous
March 24, 2008
Olá David, tudo certo? Obrigado pelos comentários. Realmente, a discussão é muito abrangente e o mundo da persistência ainda maior. Discutir quais são os aspectos relevantes de cada modelo de acesso a dados é condição crítica para o bom desempenho de uma arquitetura. Veja que nessa discussão temos várias alternativas, que estão a disposição dos arquitetos e desenvolvedores, como: T-SQLC#-SQL C# DataType-SQL DataReader DataSet DAL LinqToSQL LinqToEntity...para ficar nos principais. Cada tecnologia acima trás suas vantagens e desvantagens em relação ao desempenho, manutenabilidade, depuração, escalabilidade, suporte multi-bancos, etc. Veja uma discussão que o Otávio Coelho acabou de colocar no blog sobre esses pontos. T-SQL, DAL ou ORM http://blogs.msdn.com/otavio/archive/2008/03/22/t-sql-dal-ou-orm.aspx Ou seja, ainda temos muito o que discutir sobre esse assunto... :) []s Waldemir.Anonymous
March 25, 2008
Waldemir, Gostei bastante deste post. Nossas crescentes necessidades de performance sempre conflitam com nossos desejos de padronização e melhoria de produtividade. A persistência dos dados e a forma de acessá-los é bem variada, e isso exige que nossas arquiteturas sejam mais flexiveis para atender os requisitos. Um grande abraço!Anonymous
March 25, 2008
Ótimo post do Otávio. Nada melhor como colocar cada coisa no seu lugar. E ele pergunta: "O interessante é que podemos subdividir o projeto em perfis diferentes. Por exemplo: telas de cadastro e algumas operações podem exigir menor desempenho e usar um tipo de tecnologia – outras operações podem exigir alto desempenho. É o caso de um uso misto de tecnologia?" Pra mim a resposta sempre foi sim. Uso um ORM de terceiro, o LLBLGen, mas isso não impede que eu use SPs e Datasets em situações especiais. Como o Otávio colocou, precisamos conhecer o cenário para aplicar a melhor ferramenta. Porém, novamente, penso que o ORM ainda sofre grande preconceito nas empresas que utilizam .Net. Espero que o LINQ to SQL e o ADO.NET Entity mudem essa idéia. Infelizmente o Otávio não deixa o post aberto para comentários, mas ali caberia uma ótima discussão sobre alguns dos valores que ele apontou. Abs! DavidAnonymous
March 25, 2008
Olá David, Pode deixar! Já pedi para o Otávio rever essa política :) Mas com certeza, LINQtoSQL, LINQtoENTITY, ADO.NET Entity Framework, DALC, C#SQL, DataSet, DataReader, T-SQL, enfim, são muitas opções de tecnologias relacionadas ao mesmo problema de acessar informações de uma base relacional a partir de um mundo orientado a objetos. Qual será a melhor tecnologia aplicável irá depender dos motivadores e do contexto da aplicação, sempre! []'s Waldemir.Anonymous
April 15, 2008
Lord Woldmort, muito legal o artigo. Indo direto ao ponto: As maiores forças que definem a aplicabilidade são Performance e Manutenibilidade. Sendo assim, acredito que se pergarmos um diagrama estático de objetos, os objetos da "periferia" são candidatos ideais para o LINQ, pois normalmente serão mapeados para entidades primárias de dados, vulgos cadastros. Para estas entidades normalmente performance não é importante, mas manutenibilidade deve ser facilitada. Já para os objetos do "miolo", acredito que devemos estudar melhor, pois neles normalmente temos um uso mais complexo, ou em outras palavras JOINS no DB. A meu ver, toda vez que cairmos em manipulações complexas com grandes volumes de dados, DEVEMOS ir para Stored Procedures (mais do que performance, podemos analisar o plano de acesso e ver se o caminho escolhido pelo Otimizador é o melhor). Você me conhece, sempre defendi que SPs devem ser usados em casos nobres :) AbraçosAnonymous
April 15, 2008
Olá Marcão, tudo certo? Obrigado pelos comentários!! :) Sem dúvida, concordo com as duas forças citadas, Performance e Manutenabilidade, como as principais na discussão pelo uso de uma camada ORM. Realmente, existem diversas forças, como Legibilidade, Rastreabilidade de dados, Facilidade de Depuração, Escalabilidade, Presença de múltiplos bancos de dados na solução, como citado no post. A escolha sempre será um equilíbrio entre a necessidade de desempenho e necessidade de mapeamento transparente entre o mundo OO e o mundo relacional. Porém, se nosso banco de dados é SQL Server e ainda estamos usando stored procedures, a camada LINQ TO SQL permite o acesso a essas stored procedures como métodos, publicados para o contexto LINQ. O desenvolvedor porém aproveitar a legibilidade do LINQ com a performance da stored procedure otimizada. Creio ser uma abordagem interessante, mas que exige ainda alguns testes de performance mais intensos. Para avaliar esse cenário, veja os videos sobre LINQ acessando stored procedure, nos links abaixo: How Do I: LINQ to SQL: Using Stored Procedures Ref.: http://www.asp.net/learn/linq-videos/video-249.aspx LINQ to SQL: Updating with Stored Procedures Ref.: http://www.asp.net/learn/linq-videos/video-273.aspx Então? Vamos fazer alguns testes de carga para avaliar esse cenário? :) Por enquanto é só! WaldemirAnonymous
April 25, 2008
Olá pessoal, tudo certo? Bom, se você tem acompanhado os posts e webcasts frequentes do Otávio , do GebaraAnonymous
May 16, 2008
Olá pessoal, tudo certo? Para quem anda acompanhando a evolução do Entity Framework, componente importanteAnonymous
June 14, 2008
Olá pessoal, tudo certo? O último TechEd 2008 trouxe algumas novidades sobre o mundo ADO.NET Entity FrameworkAnonymous
June 17, 2009
Olá, gostei muito do post. Gostaria de saber qual seria a melhor solução pra uma aplicação pra mobile. A aplicação acessará os dados através do sql ce. Minha preocupação é com a rapidez em q os dados serão retornados, e com consumo de memória. obrigadaAnonymous
June 17, 2009
Olá Mari, tudo certo? Obrigado pelo comentário no aqui no blog. Para soluções em ambiente mobile recomendo visitar o capítulo 19 do documento Application Architecture Guide, onde temos uma série de considerações importantes para esse tipo de desenho. Chapter 19: Mobile Applications - Application Architecture Guide 2.0 http://www.codeplex.com/AppArchGuide/Release/ProjectReleases.aspx?ReleaseId=20586 A partir de definição das camadas de arquitetura e componentes previstos, a próxima questão é sobre a camada de acesso a dados. Recomendo visitar o link abaixo, onde temos um belo exemplo de solução: Accessing Data from a Mobile Application http://msdn.microsoft.com/en-us/magazine/cc135982.aspx Espero que ajude! Um abraço! Waldemir.