Exchange 2007 SP1 CCR- Windows 2008 Clusters - File Share Witness (FSW) failures.
Exchange 2007 SP1 Cluster Continuous Replication (CCR) clusters built on Windows 2008 most commonly uses the quorum model "Node Majority with File Share Witness".
In the past few weeks administrators have noticed that the file share resource is sometimes in a failed state. Under normal circumstances this is not an issue since both nodes of the cluster are always available (meaning that there are two votes) and the cluster services stay running. Where this has become and issue is where the file share witness resource is failed and a node of the cluster is also unavailable.
Some background....
In Windows 2003 the file share witness is a private property of the "majority node set" quorum resource. If the file share witness was unavailable, an event would be logged but the resource would continue to remain online. (Reference https://support.microsoft.com/?kbid=921181 for information on the file share witness on Windows 2003). The file share witness resource is only used when necessary to maintain quorum for the cluster. If at that time the witness was still unavailable, the cluster would loose quorum and the cluster service would be terminated.
In Windows 2008, when using the node majority with file share witness quorum model, the file share witness resource is enumerated as an actual resource. It can be seen in failover cluster manager -> cluster core resources.
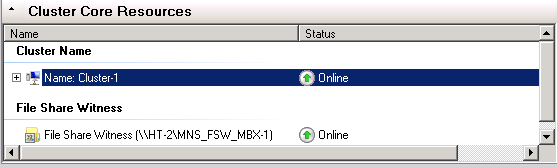
*Cluster core resources.
Now that the file share witness exists as a resource cluster can do additional health checking. One of the health checks is to ensure that the file share witness folder is online and accessible. In the event that the FSW folder is not accessible, cluster will fail the FSW resource and attempt to online the FSW on the other node. If the FSW folder continues to remain unavailable, cluster will fail the resource. By default, cluster will attempt to restart any resource that is failed every 60 minutes (1 hour). If the resource continues to fail to come online, it will remain on the node it failed on until administrator intervention is taken or the resource can be brought online during one of the 60 minute intervals.

*Failed file share witness resource in cluster core resources.
Just like Windows 2003 the file share witness in Windows 2008 is only accessed when it is necessary for the cluster to maintain quorum. If the file share witness resource is in a failed state, and the use of the FSW becomes necessary to maintain quorum, Windows 2008 will not attempt to access the file share witness resulting in a lost quorum state and termination of cluster services.
Impact to Exchange...
Where this seems to impact Exchange administrators the most is during patch management. During patch management, patches are applied to the hub transport server owning the file share which supports the FSW resource in the cluster. When the server is rebooted, the file share witness is no longer available. Cluster performs status checking, and determines that the FSW is not available. At this point the Core Cluster Group, containing the FSW, is failed over to the second node. If the hub transport server is available, the file share witness will come online. Most commonly the hub transport server is not available resulting in the file share witness failing, and remaining failed, on the second node. If left alone for 60 minutes, the resource will be automatically restarted and by this time the hub transport server will be available.
In my experience the issue arises during that 60 minutes. It is possible that a reboot or loss of a cluster node could cause the cluster to loose quorum. If the file share witness resource is failed, and I reboot the node not owning the cluster core resources, this leaves one vote in the cluster. Since cluster requires a majority of votes to be available, this results in the termination of the cluster service on the remaining node.
It is important that administrators understand this difference between Windows 2003 and Windows 2008, and account for it in how they manage their cluster.
What can be done to alleviate this condition?
As you have already read cluster automatically attempts to restart failed resources every 60 minutes. This time limit is the default setting for all resources. The rational here is that if a resource is failing, the administrator should have the opportunity to troubleshoot, identify, and correct the issue causing the resource to fail. From a monitoring standpoint, here is the entire process -- monitoring software bubbles up the alert, helpdesk notifies the admin, the admin accesses the machine, the admin reviews the logs, and the admin takes appropriate action(s). On the other hand, this process may not work as the admin may be unavailable etc, in which case the cluster will still try to self heal if no administrator intervention is taken. So essentially the first method of alleviating this condition is to understand the defaults, how the solution operates, what to look for before rebooting nodes etc (all cluster core resources healthy), and make no configuration changes.
On the properties of each resource is the retry interval to restart failed resources. The minimum value that is allowed here is 15 minutes. This would cause the cluster, in the event that the resource is failed, to be more aggressive in terms of attempting to online the resource. From an Exchange 2-Node perspective, this would limit the failure window to 15 minutes verses 60 minutes (assuming the witness is available after 15 minutes). To change this value:
1) Open the Failover Cluster Manager and connect to the cluster.
2) Select the cluster name at the top of the left hand pane.
3) In the center pane of the MMC, expand Cluster Core Resources.

4) Get the properties of the File Share Witness (\\Path\Share) resource.
5) Select the Policies tab on the resource.
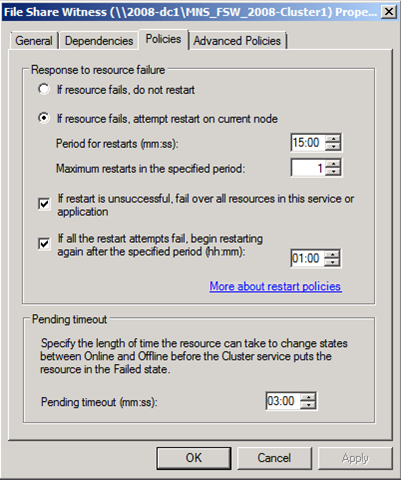
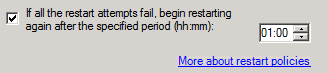
6) On the policies tab, you will see an option "If all the restart attempts fail, begin restarting again after the specified period (hh:mm) with a default of 01:00 (1 hour / 60 minutes). Here you could adjust this value to 15 minutes using the input box. If a change is made, select apply -> ok to exit properties.
Another method would be someway to issue an online command to the group, for example through a script. Post reboot it would be possible to issue a command, from the server with the failover cluster manager installed, similar to this: cluster.exe "cluster name" group "Cluster Group" /online [note, cluster group is the name of the group holding the cluster core resources, only cluster name has to be configured to the FQDN of the cluster management name.] For example, cluster.exe 2008-Cluster3.exchange.msft group "Cluster Group" /online. If this command is run manually the following output would be returned in the command window:
Bringing resource group 'Cluster Group' online...
Group Node Status
-------------------- --------------- ------
Cluster Group 2008-Node5 Online
DO NOT use any other distributed method, such as distributed file systems, to host the file share witness.
What will be done to correct this condition?
We have worked with the Windows Product Team to bring this behavior to their attention. We are working on a possible design change in the behavior of the file share witness on Windows 2008. As this progresses I will continue to update this blog with more information.
Relevant Event IDs...
- System Log - Event ID 1562 - Indicates that the file share witness is unavailable.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/7/2009 8:07:24 AM
Event ID: 1562
Task Category: File Share Witness Resource
Level: Warning
Keywords:
User: SYSTEM
Computer: 2008-Node1.exchange.msft
Description:
File share witness resource 'File Share Witness (\\2008-dc1\MNS_FSW_2008-Cluster1)' failed a periodic health check on file share '\\2008-dc1\MNS_FSW_2008-Cluster1'. Please ensure that file share '\\2008-dc1\MNS_FSW_2008-Cluster1' exists and is accessible by the cluster.
- System Log - Event ID 1069 - Indicates the file share witness resource is in failed state.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/7/2009 8:07:24 AM
Event ID: 1069
Task Category: Resource Control Manager
Level: Error
Keywords:
User: SYSTEM
Computer: 2008-Node1.exchange.msft
Description:
Cluster resource 'File Share Witness (\\2008-dc1\MNS_FSW_2008-Cluster1)' in clustered service or application 'Cluster Group' failed.
- System Log - Event ID 1564 - Indicates that the cluster cannot access the file share witness directory.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/7/2009 8:07:25 AM
Event ID: 1564
Task Category: File Share Witness Resource
Level: Critical
Keywords:
User: SYSTEM
Computer: 2008-Node1.exchange.msft
Description:
File share witness resource 'File Share Witness (\\2008-dc1\MNS_FSW_2008-Cluster1)' failed to arbitrate for the file share '\\2008-dc1\MNS_FSW_2008-Cluster1'. Please ensure that file share '\\2008-dc1\MNS_FSW_2008-Cluster1' exists and is accessible by the cluster.
- System Log - Event ID 1205 - Indicates that the cluster core resources group ("Cluster Group") is not completely online or offline due to a failure of the file share witness resource.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 1/7/2009 8:07:25 AM
Event ID: 1205
Task Category: Resource Control Manager
Level: Error
Keywords:
User: SYSTEM
Computer: 2008-Node1.exchange.msft
Description:
The Cluster service failed to bring clustered service or application 'Cluster Group' completely online or offline. One or more resources may be in a failed state. This may impact the availability of the clustered service or application.
*Thanks to Chuck Timon, Sr Support Escalation Engineer, Platforms CSS for assisting in reviewing and modifying this information.
=======================================
Updated Wednesday - 08/19/09
Jeff Guillet – a Microsoft Windows MVP – has posted a sample batch file for starting the FSW and moving the cluster core resources group to a desired node. The instructions also include how to schedule the batch file as a startup script.
https://www.expta.com/2009/06/failure-of-fsw-causes-cluster-group-to.html
=======================================
=======================================
Updated Wednesday 12/14/2011
I failed to update this blog post previously with a windows hotfix that corrects this behavior and makes work arounds not necessary.
=======================================
Comments
Anonymous
January 01, 2003
Younssi: I'm not sure that I understand your question. If you are saying that the FSW failed and caused Exchange to fail this shouldn't happen, unless you encountered a lost quorum condition. You may consider reading this blog post. http://blogs.technet.com/timmcmic/archive/2010/02/15/kb978790-update-to-windows-2008-to-change-the-failure-behavior-of-the-file-share-witness-quorum-resource.aspx If the network between the active and passive nodes has issues, or the nodes to the file share witness, then the nodes are not operating properly - this needs to be addressed.Anonymous
January 01, 2003
Soul Savior ! How to avoid that when FSW failed the Windows cluster will failover therefore the CMS ? This is happened in our CCR that for network problem, FSW share is not availbale and the CCR is failovering even if the Actif and Passif nodes are working properly. Second problem I have , the passif node still owner of the Quorum ?? Thank You a lotAnonymous
January 01, 2003
Thanks Tim, this is exactly what I needed. I hope MS is still treating you well. Email me sometime, brother.