Exchange 2013 High Availability – II
Ilk makalede Multiple Databases Per Volume, Automatic Reseed ve Safety Net’den bahsetmistik. Burada ise Lagged Copy’deki gelismelerden ve Site Resilience’dan bahsedecegiz.
Lagged Copy’deki gelismeler
Yeni gelismelerle lagged copy’lerle çalismanin artik daha kolay oldugunu söyleyebiliriz. Örnegin 2 gün gecikmeli bir lagged copy’niz var. Safety Net ayarlari da varsayilan degerinde yani mesajlari 2 gün
tutacak sekilde konfigüre edilmis. Lagged copy’nin aktif hale getirilmesi gereken bir durumla karsilastiniz. Öncelikle bu kopya üzerindeki replication’i suspend ediyorsunuz ve her duruma karsi bir yere kopyasini aliyorsunuz. Gerekli
olan aralik disindaki tüm loglari siliyorsunuz ve database’i mount ediyorsunuz.Otomatik olarak Safety Net’den son iki güne ait mesajlarin deliver edilmesi istenecek ve sizin corruption’in yasandigi o noktayi tespit etmeniz gerekmemis
olacak.
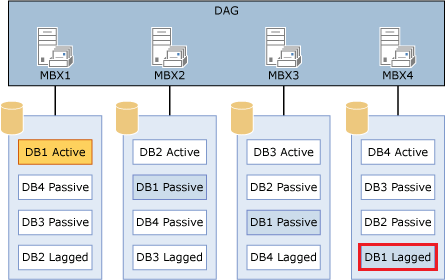
Lagged copy’ler bazi durumlarla karsilastiklarinda artik kendileri otomatik log replay’i baslatabilirler.
Bunlar:
- Bos disk alani treshold’un altina düstügünde
- Fiziksel bir corruption yasadiklarinda ve page paching gerekli oldugunda
- Son 24 saat boyunca ortamda üçten az (aktif veya pasif) healthy kopya bulundugunda
Otomatik log replay özelligi varsayilanda devredisidir. Istenirse asagidaki komutla devreye alinabilir:
Set-DatabaseAvailabilityGroup “DAGName” –ReplayLagManagerEnabled $True
Site Resilince
Exchange 2010’da CAS ve Mailbox (DAG) yapilari birbirine daha siki bagliydi. Örnegin bir site’daki tüm CAS’lari kaybetmeniz durumunda veya DAG’inizin önemli bir bölümünü kaybettiyseniz datacenter switchover yapmaniz gerekirdi. Bu islemin takip edilmesi gereken belirli adimlari vardi, kötü olan kismi zaman aliyor olmasi ve admin müdahalesi gerektirmesi idi.
Exchange 2013’de CAS array’i kaybetmis olmaniz datacenter switchover yapmanizi gerektirmiyor. Uygun konfigürasyon ile failover client seviyesinde gerçekleserek, client’lar diger datacenter’a otomatik redirect edilir. Bu datacenter’da bulunan CAS, gelen client istekleri kullanicinin Mailbox server’ina proxying yaparak iletecektir. Dolayisi ile böyle bir senaryoda herhangi bir kesinti yasamadan çalismaya devam edeceksiniz. Bunun disinda Exchange servislerinde olusan bir probleme karsi service kendisini recover etmeye çalisacak ve siz diger sorunlarla, örnegin load balancer’inizda olusan bir problem varsa, ilgilenebileceksiniz.
Exchange 2010’da DAG üyelerinizi iki datacenter arasinda seçebiliyor ve witness server’i üçüncü bir datacenter’da tutabiliyordunuz. Ancak böyle bir konfigürasyonda bile admin müdahalesi olmadan datacenter’lar arasi failover yapamiyordunuz. Çünkü namespace’in Mailbox disindaki roller için manual olarak degistirilmesi gerekiyordu.
Exchange 2013’de namespace’in DAG’la birlikte tasinmasina gerek yok. Çünkü HTTP stack ayni FQDN için çok sayida IP adresini kabul edebilir. Eger ilk denedigi IP adresi fail olursa, listeden ikinci IP adresine erismeyi dener. Soft failure durumunda ise (yani session kurulduktan sonra baglantinin kopmasi) kullanicinin browser’ini refresh etmesi gerekir.
Yani artik namespace için Exchange 2010’da oldugu gibi single point of failure durumu yok. Buradaki en büyük zorluk da kullanicilara verdiginiz FQDN’in nereye gittigi ve gittigi adresi degistirmeniz durumunda DNS’de de degisiklik yapmaniz gerektigi, bununla birlikte DNS latency durumlarini yönetmeniz ve cache’in kullanici browser’inda 30 dk duruyor olmasi nedeni ile bunu da yönetebiliyor olmaniz.
Exchange 2013’de client’lariniz artik tek bir adrese gitmek durumunda degil. Exchange 2013’de client erisimlerinin tümü HTTP based oldugu için ve yukarida bahsettigimiz gibi HTTP client’larin birden fazla IP adresi kullanabilmesinden dolayi client side failover saglanmaktadir. DNS’inizde ayni FQDN için birden fazla IP adresi girebilirsiniz. Örnegin mail.contoso.com adresi için DNS’e girdiginiz dört farkli IP adresi (dört CAS) oldugunu düsünelim. Bu dört IP adresi client tarafindan güvenilir bir sekilde kullanilir. Client’in erismeye çalistigi IP adresi erisilemez olursa, yaklasik 20 sn sonra client listeden ikinci IP adresine erismeyi dener. Bu yüzden Client Access server array için VIP’ye erisilememesi durumunda recovery islemi client tarafli 21 sn içinde otomatik olarak yapilacaktir.
Sevgi Sifyan