SQL Server chez les clients – Optimisation du modèle analytique

Cet article présente les bonnes pratiques à suivre afin d’optimiser l’implémentation d'un modèle multidimensionnel dans SQL Server Analysis Services, puis propose une approche de gestion dynamique du partitionnement des données de faits dans les cubes afin d'accélérer la mise à disposition des données et leurs restitutions.
Problématique
- La modélisation multidimensionnelle et son impact sur les performances de traitement et d’analyse
- Permettre le partitionnement dynamique en fonction des données
- Gérer le partitionnement du cube SSAS sans modifier le processus d’alimentation du datamart
Bénéfices
- Utilisation d’une procédure de partitionnement réutilisable par plusieurs projets Analysis Services
- Automatiser les tâches de gestion des partitions
- Ajuster le design du cube pour obtenir de meilleures performances
L'optimisation du modèle dimensionnel
Le design et le paramétrage des dimensions est un point majeur lors de la mise en œuvre d'un cube Analysis Services, qui permettra par la suite d'assurer un bon niveau de performance en phase de restitution.
La partie suivante liste des techniques utilisées pour optimiser le design du cube et des ces dimensions:
- Choix du l’attribut clé de la dimension : Chaque dimension doit posséder un attribut clé, qui permette d’identifier de manière unique un membre de la dimension, et qui est généralement utilisé pour définir le niveau de granularité des groupes de mesures du cube.
Cet attribut clé est bien souvent construit à partir de la clé primaire de la table sous-jacente à la dimension, un champ dont le type et la taille peuvent avoir un impact sur le temps de traitement de la dimension et d'exécution des requêtes.
Il est important de privilégier l’utilisation de type numérique (INTEGER) au lieu de caractère (VARCHAR), et d’utiliser une seule colonne au lieu de plusieurs (composite key) via la création de clé surrogate (clé technique numérique) si nécessaire.
- Eviter les attributs non utilisés : Par défaut, un attribut d’une dimension correspond à une hiérarchie d’attribut (niveau unique), et reste utilisable pour naviguer dans les données du cube.
Lors du design de la dimension, il est recommandé de se référer au besoin d’analyse exprimé pour cette dimension, afin d'implémenter les attributs nécessaires pour la navigation et ajouter en tant que propriétés de membres, les informations utilisées uniquement pour de l'affichage.
- Désactiver l’optimisation des attributs rarement utilisés : SSAS par principe considère que si l’on modélise un attribut, c’est que ce dernier sera régulièrement utilisé pour la navigation dans le cube, et c'est la raison pour laquelle les valeurs de cet attribut sont indexées pour optimiser son utilisation.
En configurant la propriété AttributeHierarchyOptimizedState à NotOptimized, l'opération de traitement de la dimension est optimisée en termes de durée et de ressources sollicitées, en évitant de créer l’indexation associée.
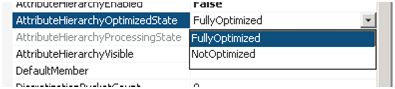
- Désactiver la hiérarchie d’un attribut : Après avoir retiré les attributs non utiles lors des analyses et des restitutions, il peut subsister certains autres attributs qui ne sont pas utiles lors de la segmentation des faits.
Par exemple, un utilisateur n’utilisera pas l’attribut téléphone ou Numéro de sécurité social pour segmenter les données dans un tableau croisée dynamique.
Cependant, l'utilisateur peut souhaiter un affichage de ces informations en complément du nom de l’employé.
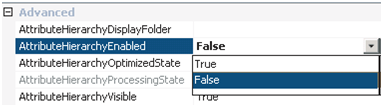
Dans ce cas, il est utile de désactiver la propriété AttributeHierarchyEnabled pour indiquer à SSAS de ne pas construire de hiérarchie pour cet attribut, mais de le conserver en tant que propriété d'un autre attribut de la dimension.
Cette optimisation réduit à la fois la durée et l’espace nécessaire lors du traitement de la dimension.
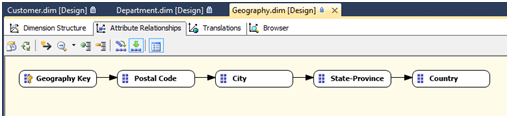
- Définir les relations entre les attributs : Si un attribut dans une dimension possède une relation un à plusieurs (one-to-many) avec un autre attribut, il faut le matérialiser dans l’onglet Attribute Relationships.
Par exemple dans une dimension géographique, nous avons naturellement pour un pays, un à plusieurs états ou régions, puis une à plusieurs villes, suivies d'un à plusieurs codes postaux.
Dans ce cas, les relations sont définies comme suit :
La définition des relations accompagnée de la définition d’une hiérarchie naturelle à plusieurs niveaux va significativement améliorer le temps d’exécution des requêtes utilisateurs mais aussi les temps de traitement.
La définition des relations entre les attributs indique à SSAS comment construire des indexes efficaces.
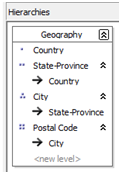
Pour comprendre cette optimisation de modélisation de dimension, il faut comparer le fonctionnement du moteur lors de l’utilisation d’une hiérarchie naturelle et non naturelle.
Par défaut dans une dimension, tous les attributs sont reliés à l’attribut clé car il est unique et donc ce dernier possède une relation une à plusieurs avec chacun des attributs de la dimension.
Une hiérarchie est dite naturelle s’il existe une relation "un à plusieurs" entre chaque attribut constituant les niveaux de la hiérarchie utilisateur (comme dans le cas présenté précédemment).
En s'appuyant sur la définition de ces relations, le moteur SSAS créé des indexes lors du traitement (process) des données pour accélérer la navigation.
Cela permettra par la suite de faciliter les opérations du moteur, qui pourra récupérer la liste des villes appartement à la région IDF via l’interrogation de l’index Ville à Région (City à State-Province).
Dans le cas des hiérarchies non naturelles, seul l’attribut clé possède une relation avec les autres attributs (cas par défaut de la configuration de la dimension).

Dans cette configuration de relation, SSAS va construire des indexes pour la relation City vers Geography Key, State-Province vers Geography Key, …
Contrairement à une hiérarchie naturelle, la matérialisation de la hiérarchie (identification du passage d’un niveau de la hiérarchie au niveau inférieur) a lieu durant l’exécution de la requête.
Pour revenir sur l’exemple précédent de récupération des villes appartenant à la région IDF, SSAS doit récupérer toutes les Geography Key en relation avec l’attribut State-Province, puis utiliser la relation Geography Key vers City pour récupérer la liste des villes appartenant à la région IDF.
Dans le cas où l’attribut clé est composé de plusieurs millions de lignes, le temps d'exécution de la requête sera rallongé.
- Referenced Dimensions : Dans le cas où le cube possède une dimension référencée (Referenced dimension), il est important de comprendre l’importance et le fonctionnement de l’option Materialize.
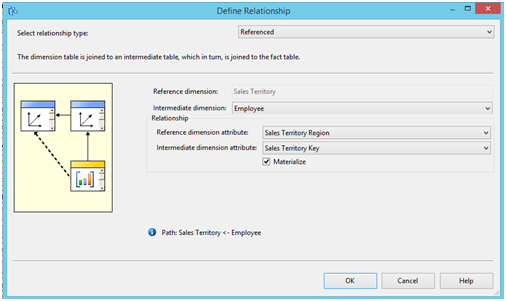
Cette option permet lors du traitement des partitions, de matérialiser la clé de la dimension référencée dans la partition (groupe de mesures). En d’autres termes, SSAS va traiter cette dimension comme une dimension classique.
Du point de vue performance, si la dimension n’est pas matérialisée, un lookup dynamique a lieu lors de l’exécution d’une requête utilisateur pour joindre les faits à la dimension référencée au travers la dimension intermédiaire.
Point d’attention à retenir : Comme la clé de la dimension référencée est matérialisée dans les partitions, le rafraichissement de la relation en effectuant un Process update de la dimension intermédiaire n’a aucun effet sur la matérialisation effectuée précédemment. Pour la mettre à jour, il est nécessaire de traiter également les partitions.
L'optimisation du cube par le partitionnement
Le partitionnement dans un cube consiste à séparer le contenu des groupes de mesures (les données factuelles) en plusieurs fichiers stockés sur le disque ayant chacun leur mode stockage propre (MOLAP, ROLAP ou HOLAP).
Cette configuration affecte la structure physique organisationnelle des données, mais n'impacte pas le modèle de données sémantique proposé aux utilisateurs.
Le sujet du partitionnement ayant déjà été traité dans l’article SQL Server chez les clients – Le Partitionnement Analysis Services, ce billet va s'attacher à décrire les avantages du partitionnement sur 3 axes, suivi d’un exemple d’implémentation du partitionnement dynamique sur un cube existant :
Axe 1 : Accès utilisateur
Le partitionnement permet de répondre à des besoins de performance des requêtes.
Le fait de scinder physiquement un groupe de mesures en plusieurs partitions apporte les avantages suivants lors de l’accès utilisateur :
- Elimination de partition : Basé sur la définition du partitionnement, le moteur Analysis Services identifie les partitions ne répondant pas aux critères de la requête et les exclut de l'opération de lecture, ce qui réduit le volume de données à traiter par le moteur.
- Répartition des données : Les différentes partitions d’un groupe de mesures peuvent être localisées sur des volumes disques différents avec des niveaux de performances différents. Une stratégie de partitionnement permet donc de répartir les partitions de données les plus utilisées sur un sous-système disque performant et de placer les autres partitions (Historique, rétention en ligne,…) sur un sous-système disque moins onéreux.
- Stratégie d’agrégation : Chaque partition peut s'appuyer sur sa propre stratégie d’agrégation, ce qui permet d’adapter une stratégie d’agrégation différente sur les partitions ayant le moins d’accès ou simplement des accès différents (sur les données du mois courant pour sur l’année passée par exemple)
Axe 2 : Chargement du cube
Le partitionnement améliore significativement les temps de traitement des cubes MOLAP à forte volumétrie, et permet ainsi de réduire les délais de mise à disposition des données.
Lors de processus de chargement des données dans le système de données (généralement un datamart), il est aisé d’identifier quel jeu de données a été ajouté ou mis à jour, et donc de définir quelle partition SSAS nécessite une mise à jour.
L'intérêt est de pouvoir réaliser des retraitements partiels plutôt que de recharger l'intégralité des données dans le cube.
Axe 3 :
Un autre avantage du partitionnement est la gestion des données dans le cube.
En séparant un groupe de mesure en plusieurs partitions, un administrateur de base de données SSAS bénéficie des avantages suivants :
- Conserver des données d’historique en ligne : Contrairement à un groupe de mesure avec une seule partition, un groupe de mesure avec plusieurs partitions permet de garder en ligne dans la base SSAS des données n’existant plus dans le datamart tout ne continuant de mettre à jour les données existantes.
Une partition MOLAP charge les données dans SSAS, si les données n’existent plus dans le datamart (suite à une purge par exemple), elles continueront à perdurer dans le cube tant que la partition ne sera pas retraitée ou supprimée.
- Supprimer rapidement un volume de données : Dans le cas d’une gestion multi partitions, la purge des données d’une partition revient à supprimer la partition.
Si le groupe de mesure n’est pas partitionné, il faut supprimer les données du datamart puis recharger le groupe de mesure pour que les données n’apparaissent plus dans le cube.
La gestion dynamique des partitions
Pour répondre à ce besoin redondant d’utilisation des partitions SSAS, nous avons mis en place des solutions de gestion de partitionnement dynamique basées sur la lecture des données du datamart mais aussi de la définition des partitions dans le cube.
En combinant ces deux informations, il devient aisé de gérer dynamiquement les partitions d’un cube.
Voici les différentes étapes d'un mécanisme de gestion automatisée des partitions d'un cube :
- Mettre à jour les dimensions : Du fait de la gestion de multiples partitions par groupe de mesure, il est nécessaire de procéder à un rafraichissement des données des dimensions par la commande Process update. Contrairement au traitement complet(Process Full), les partitions qui utilisent ces dimensions ne seront pas vidées. Seuls les indexes et agrégations devront être reconstruits.
- Identifier les partitions à construire dans le cube : Les tables de faits dans le datamart nécessitent l’utilisation d’une colonne de partitionnement (colonne existante, calculée ou créée spécialement pour mixer des valeurs de plusieurs colonnes) et d’une colonne de date de modification pour identifier la date de dernière modification des données.
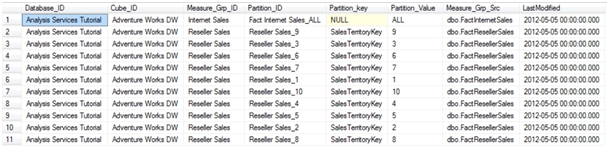
- Identifier l'état du partitionnement actuel : A l’instar de la récupération des données depuis le datamart, le mécanisme effectue la récupération des informations liées aux partitions SSAS depuis le cube directement via du code AMO en C# pour identifier les différentes partitions ainsi que leurs dernières dates de mise à jour.
Exemple de récupération des informations sur les partitions directement dans le cube :


- Rafraichir le cube : Après avoir récupéré les partitions cibles issues des données du datamart et les partitions existantes depuis le cube, le mécanisme va orchestrer les actions suivantes en créant les scripts XMLA (via la connexion AMO, il n’y a pas de scripts XMLA template à maintenir) associés et en maximisant l’exécution en parallèle des actions :
- Supprimer les partitions sans données dans le datamart
- Créer de nouvelles partitions : La création d’une nouvelle partition s’effectue par la duplication d’une partition existante pour conserver sa structure et sa stratégie d’agrégation.
- Mettre à jour les partitions ayant une date de dernier chargement inférieure aux données présentes dans le datamart
- Faire une mise à jour des indexes et des agrégations invalidées, suite à la mise à jour des dimensions
Le prérequis est donc de créer dans chaque groupe de mesures, une partition labélisée du suffixe _DEFAULT filtré pour ramener 0 lignes.
Exemple du dataflow SSIS et du script de création via la fonction clone :


{kind=link}
{kind=link}

Cette solution est exécutée dans un package SSIS et se déploie sur un projet SSAS dès son développement ou sur un cube déjà place, en implémentant les objets suivants :
- Un jeu de tables avec ses procédures stockées d’alimentation comprenant la définition du partitionnement à appliquer selon le groupe de mesure (à déployer dans le DMT)

- Une colonne indiquant la date de modification des lignes de la table de fait, et identifier la colonne de partitionnement (colonne existante, calculée ou créée spécialement pour mixer des valeurs de plusieurs colonnes)
- Ajouter une partition par défaut dans chaque groupe de mesures à partitionner avec une requête filtrant les données (where 1=0)
L’expertise Microsoft Consulting Services au service de ses clients
La démarche qui est présentée dans cet article est une offre de service MCS qui peut tout aussi bien être mise en œuvre dans le cas d’un projet géré par Microsoft Services, que dans le cadre d’une assistance technique sur certains aspects du projet (architecture, optimisation, validation…).
L’outil spécifique présentée dans cet article pour industrialiser le processus de rafraichissement d’un cube SSAS à multiple partition est un des nombreux exemples de solutions permettant d’accélérer la mise en œuvre de solution, l’alignement des configurations et d’améliorer la maintenance au quotidien.
Cet outillage est utilisé par de nombreux clients Microsoft Consulting Services, dont voici des exemples de domaines d’activité :
- Retail
- Finance
- Télécommunication
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Antoine Richet, Consultant BI/SQL, Microsoft Consulting Services J’interviens dans les projets SQL Server pour les aspects d’architectures, optimisations et intégration de données décisionnelles. |