The “Balanced Data Distributor” for SSIS
The “Balanced Data Distributor” for SSIS
Len Wyatt, SQL Server Performance Team
There is a new transform component available for SQL Server Integration Services. It’s called the Balanced Data Distributor (BDD) and the download is available here. The BDD provides an easy way to amp up your usage of multi-processor and multi-core servers by introducing parallelism in the data flow of an SSIS package.
Functionality of the BDD
The functionality of the BDD is very simple: It takes its input data and routes it in equal proportions to its outputs, however many there are. If you have four outputs, roughly ¼ of the input rows will go to each output. Instead of routing individual rows, the BDD operates on buffers of data, so it’s very efficient.
Some of you will already be noticing that there is no transformational value in the BDD, and no control over which data rows go to which output. You may be wondering, what the heck is the value of that?
The value of the BDD comes from the way modern servers work: Parallelism. When there are independent segments of an SSIS data flow, SSIS can distribute the work over multiple threads. BDD provides an easy way to create independent segments.
This diagram gives a trivial example:
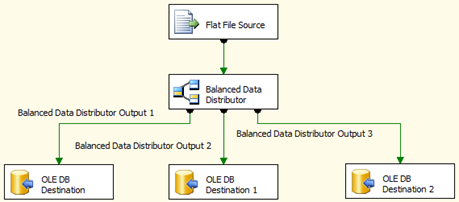
If you run this data flow on a laptop, there probably won’t be any speed advantage, and there may even be a speed cost. But suppose you run this on a server with multiple cores and many disk spindles supporting the destination database. Then there might be a substantial speed advantage to using this data flow.
When to use the BDD
Using the BDD requires an understanding of the hardware you will be running on, the performance of your data flow and the nature of the data involved. Therefore it won’t be for everyone, but for those who are willing to think through these things there can be significant benefits. Here is my summary description of when to use BDD:
- There is a large amount of data coming in.
- The data can be read faster than the rest of the data flow can process it, either because there is significant transformation work to do or because the destination is the bottleneck. If the destination is the bottleneck, it must be parallelizable.
- There is no ordering dependency in the data rows. For example if the data needs to stay sorted, don’t go and split it up using BDD.
Relieving bottlenecks in the SSIS Data Flow
Let’s talk about bottlenecks, since changing bottlenecks is what BDD is all about. A bottleneck is whatever limits the performance of the system. In general there are three places that could be the bottleneck in an SSIS data flow: The source, the transformations, or the destination.
Bottlenecks in the Source
If the limiting factor is the rate at which data can be read from the source, then the BDD is not going to help. It would be better to look for ways to parallelize right from the source.
Bottlenecks in the Transformations
If the limiting factor is the transformation work being done in the data flow, BDD can help. Imagine that there are some lookups, derived columns, fuzzy lookups and so on: These could easily be the components limiting performance. Make two or four or eight copies of the transformations, and split the data over them using the BDD. Let the processing run in parallel. If there are several transformations in the data flow, put as much as you can after the BDD, to get more things running in parallel.
Bottlenecks in the Destination
If the limiting factor is the destination, BDD might be able to help - you need to determine whether the destination can be run in parallel. You might be surprised at some times when it can. One example is when loading data into a simple heap (table with no indexes) in SQL Server. With the database properly distributed over a number of disks, it is quite possible to load in parallel with good performance. When working on the ETL World Record a while ago, we used a heap for a side experiment and found that loading 56 streams concurrently into a single heap was almost as fast as loading 56 streams into 56 independent tables. Many sites already drop or disable their indexes during data loading, so this could be more of a freebie than you would expect. More recently we saw a benefit from parallel loading into SQL Server Parallel Data Warehouse (PDW). PDW is an architecture designed for parallelism!
When the destination does not support parallel loading
A final case to consider is when the limiting factor is the transformation work being done in the data flow but the destination cannot receive data in parallel for some reason. In this case, consider using BDD to parallelize the transforms followed by a Union All to rejoin the data into a single flow; then a single destination can be used. Here is an illustration:

Best practice – balanced!
One final note: Whatever you put behind the BDD, be sure the same work is being done on all paths. It doesn’t make logical sense to have the paths be different, and from a performance point of view, you want them all to be the same speed. Remember, the “B” in BDD stands for “Balanced”.
Conclusion
Someday maybe SSIS will be able to do the work of the BDD automatically, but for now you have an easy way to amp up your usage of multi-processor and multi-core servers by introducing parallelism in the data flow of an SSIS package.
Comments
Anonymous
May 25, 2011
Is this balace data Distributor work same for all type od Data source or is there any performance difference with different Data SourceAnonymous
May 25, 2011
When i am clicking on download of balace data distributer link it just download .Doc file where i can get actuall file will pleases explain me sameAnonymous
May 26, 2011
I agree that the way to do this is not totally obvious, but there are instructions on the download page. It says: • Please download the License on this page and accept the terms. • Once you accept the License terms, a download link will display giving you the option to download the X86 or X64 version of the software The Accept button is at the bottom of the License agreement.Anonymous
May 31, 2011
Very nice inversion.Anonymous
August 02, 2011
To view a demo of the Balanced Data Distributor, go to technet.microsoft.com/.../hh369962 .Anonymous
August 23, 2011
The comment has been removedAnonymous
December 08, 2011
what would be the main advantage of having a solution using BDD or running many packages in parallel by splitting the data in the query . what is obvious is : instead of having many sources it will be one query returning all the data ... what else ?Anonymous
February 23, 2012
What's happening with the BDD and SQL Server 2012? At present I cannot get it to work with RC0. Have not tried on subsequent builds.Anonymous
May 10, 2012
We're actively working on making BDD work in SQL Server 2012.Anonymous
June 22, 2012
Thanks, great explanation...Anonymous
February 06, 2014
I was looking for the 2012 version and since there isn't a link on this page already, here it is: www.microsoft.com/.../details.aspxAnonymous
April 21, 2014
It is so nice article. I was really satisfied by seeing this article and we are also giving Tibco Online Training. Tibco <a href="http://www.tibco-online-training.com">Tibco online training</a>is best online training institute in USA.Anonymous
June 11, 2014
And the 2014 version is part of the SQL Server 2014 Feature Pack: www.microsoft.com/.../details.aspxAnonymous
July 30, 2014
thanksAnonymous
August 07, 2014
Hi there. My name is Lee McArthur - I am an account manager for a re-insurance company here in Bermuda that is doing some amazing things with SQL 2014 and Fusion IO. Fusion IO - going great. However, its being help up by SQL 2014 barfing / rejecting / blocking connection requests far before it should. Can someone help and hop on a quick call to discuss please? Client more than happy to pay as well. We are all Microsoft partners, customers, etc. Lee McArthur 441-278-5239 Thanks in advance!Anonymous
April 23, 2015
Is there a performance benefit to using this instead of a conditional split? I would normally take an ID field and split the data based on ID % 3=0, ID %3=1, ID % 3=2 and so on.Anonymous
May 10, 2015
Good one