What Does Installing Polybase Add to My SQL Server?
In this post, I want to show you some of the components that are added to your SQL Server when you install the Polybase feature and where they reside.
Introduction:
Polybase is a new feature with SQL 2016 that allows you to query external Hadoop data and data in Azure Blob Storage. It has been around for a little while in the Analytics Platform System appliance as a feature in Parallel Data Warehouse, but it now can be installed on SQL Server 2016. There are a number of resources to help you learn a lot more (like the MSDN Polybase Guide), and I will be following up with more posts about Polybase. Here I will describe some of the components you will see when you install the feature.
Java and Polybase Services:
One of the First things you may notice when you go to install the Polybase feature is that it has a prerequisite for installing Java Runtime. This must be done before the installer will allow you to continue. Make sure you install the 64bit Java Runtime.
There are 2 services created for Polybase.
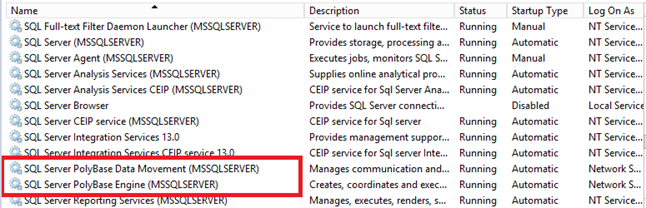
Polybase Engine: This is the brains of the operation. The engine service is the core service that parses TSQL into requests to the external data source, sends results to the client, coordinates with compute nodes (in a scale out scenario). If you have Polybase configured in a scale-out group, there will be 1 Engine service that is the control node for all the other included nodes (referred to as compute nodes.
Data Movement: If the Engine is the brain, then this is the brawn. This service (often just called DMS for Data Movement Service), temporarily moves data from the external source to SQL Server. In a scale-out scenario, you will have multiple nodes running DMS tasks in parallel to spread out the load to multiple SQL Servers. This is similar to a Hadoop data node. In order to fulfill queries, there may also be a need to shuffle some of this temporary data between various nodes in the scale-out group. This service performs that function as well.
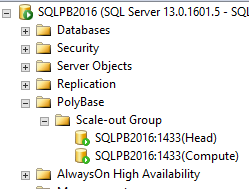
When in a scale-out scenario, you can see the members of the group via SSMS as seen below. More info about scale-out groups can be found in the Polybase Guide linked at the beginning of this post.
Files:
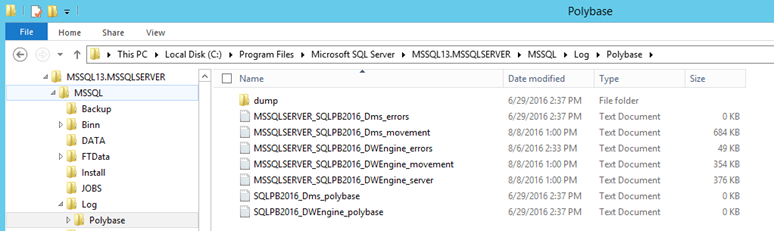
For the most part, all the files required for the services are installed in the <InstanceRoot>\MSSQL\Binn\Polybase, and for the most part, you will not touch these files. The exception will be the <instanceRoot>\Binn\Polybase\Hadoop\conf directory. Here you will see config files that you can modify to enter path information from your Hadoop environment to enable predicate pushdown and Kerberos authentication.

You will find log files in a subfolder where you have the SQL Server log files installed. In my case it is <InstanceRoot>\MSSQL\Log\Polybase. There are log files for both the Engine and Data Movement services. They log all activity for these services and data will roll over based on the size of the files, therefore there will be varying history based on activity level. Errors also log to error specific files which will have a longer retention. Along with the DMVs, these will be your best tools in troubleshooting both performance and failures with Polybase. Describing the contents separate topic all itself, and I plan to follow up with a post on that at a later date.
System Databases:
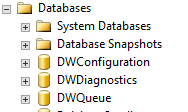
There are 3 databases created by Polybase. While they are not really system databases in the sense that they are in the "System Databases" in SSMS, I consider them system dbs similar to how I like to consider SSISDB a system database. It is not a db you want to mess with the schema or data. The three databases are DWConfiguration, DWDiagnostics, and DWQueue. For the most part, their name pretty well describes their usage, but they are not databases you will ever be querying unless directed to by Microsoft Support while troubleshooting a support case. Even then, typically log files and DMV data are all that will be requested. I suggest you leave these dbs alone. Back them up along with the other system databases, but most likely it would be easier to uninstall/reinstall Polybase then to worry about ever restoring these dbs.
Database objects:
After Polybase is installed, you will have 4 new object types that you can create, and all three are needed to successfully query external sources supported by Polybase.
External Data Source: This is the pointer to the data source. The type of information required depends on the data source. For example, Hadoop data sources require a name node IP address and port.
External File Format: This defines the file format that you will be accessing (examples are ORC, RCFILE, DELIMITED)
External Table: This is where you define the columns that you want and specify the external data source, file format, and the location within the external data source (path to folder). This is the object that you will select just as if it is a table within a SQL Server database.
Database Scoped Credential: This will only be used when configuring the external data source for Kerberos authentication.
This has been a fairly lengthy post, and it really just touches the surface of Polybase. It is a complex feature that has grown and been used for a number of years in the Parallel Data Warehouse product, but is now available in SQL Server 2016. It is very powerful, but it is also very different for a DBA. I will be posting a 2 part series here in the next few weeks on how you can build your own environment to learn and test Polybase.