Learn SQL 2016 Polybase with HDP – Part 2 – Learning Polybase along with Hadoop Tutorials
In part 1, I showed you how you can create a Hortonworks sandbox and a SQL 2016 instance with Polybase. In this post, I will show you how to query Hadoop data with Polybase as well as how you can follow along with some of the Hortonworks tutorials and mimic some of the same actions within Polybase.
First, you will want to make sure you can connect to Ambari from to ensure that Hadoop is running on your sandbox VM.
Then you can utilize some sample data already on the sandbox to validate that Polybase is configured properly.
I created a database called PolybaseSandbox on my SQL 2016 VM. In order to connect to a data source with Polybase you basically need 3 objects, an external data source, an external file format, and an external table. The data source is what points you to hdfs in this case. The file formats describe what type of files you will be querying within hdfs. Then the external table puts those 2 together along with a URI to the specific data you want to query in Hadoop.
[sql]
USE [PolyBaseSandbox]
GO
--create external data source to the hadoop sandbox
--here I used the internal IP address
CREATE EXTERNAL DATA SOURCE [HDP24] WITH (TYPE = Hadoop, LOCATION = N'hdfs://10.0.0.4:8020')
GO
-- create file format for the sample within the hadoop sandbox
CREATE EXTERNAL FILE FORMAT [TSV] WITH (FORMAT_TYPE = DelimitedText, FORMAT_OPTIONS (FIELD_TERMINATOR = N'\t', DATE_FORMAT = N'MM/dd/yyyy', USE_TYPE_DEFAULT = False))
GO
--create the external table to the sample data in the sandbox
CREATE EXTERNAL TABLE [dbo].[sample_07]
(
[code] [nvarchar](255) NULL,
[description] [nvarchar](255) NULL,
[total_emp] [int] NULL,
[salary] [nvarchar](255) NULL
)
WITH (LOCATION = N'/apps/hive/warehouse/sample_07', DATA_SOURCE = HDP24, FILE_FORMAT = TSV)
GO
[/sql]
Then you can select the data to confirm that you can get query results like the screenshot below:
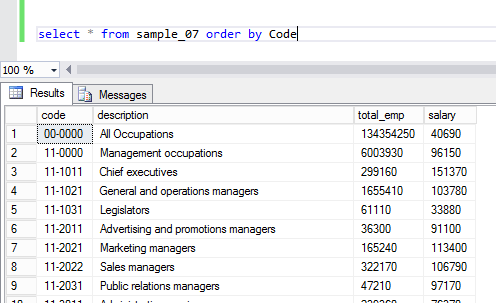
Looking in HIVE view in Ambari, you can see the same data:

Pretty cool that you can use SSMS and TSQL that you know and love to query data in Hadoop!
Now let's look at the labs. There is a great set of tutorials that go along with the Hortonworks sandbox. Note, that I am skipping forward a little in the tutorials, but I highly suggest you start from the beginning. I am starting at tutorial 2, lab 1 here. https://hortonworks.com/hadoop-tutorial/hello-world-an-introduction-to-hadoop-hcatalog-hive-and-pig/#section_3 
I am not going to walk through all the tutorial labs in this post, but you will need that data in order to do the next lab and mimic the same result set in Polybase.
Once you get through lab 2.6.2, you have the truck_mileage table with data. Here is how you would create an external file format and external table and query that same data. You do not need to create an external data source, as you will use the same one that you created with the previous script:
[sql]
USE [PolyBaseSandbox]
GO
--create a new file format since this table is in ORC
CREATE EXTERNAL FILE FORMAT [ORC] WITH
(FORMAT_TYPE = ORC)
GO
--create table using the new file format but existing data source from previous script
CREATE EXTERNAL TABLE[dbo].[truck_mileage]
(
[truckid] nvarchar(255) NULL,
[driverid] nvarchar(255) NULL,
[rdate] nvarchar(255) NULL,
[miles] bigint NULL,
[gas] bigint NULL,
[mpg] float NULL
)
WITH (LOCATION = N'/apps/hive/warehouse/truck_mileage', DATA_SOURCE = HDP24, FILE_FORMAT = ORC)
select top 100 * from truck_mileage order by trucked;
[/sql]
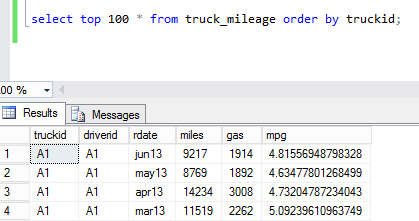
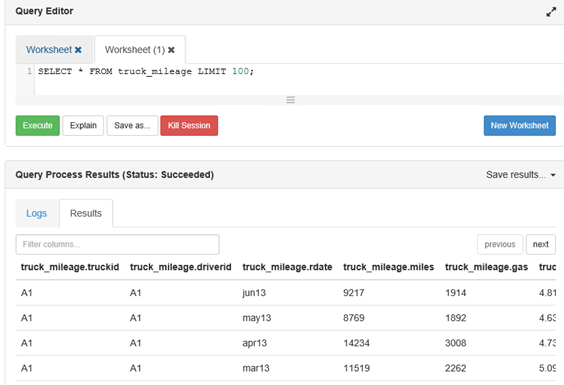
Just like with the previous sample data, you can see the same results in SSMS and in HIVE.
SSMS:
Hive:
Lab 2.6.3 in the tutorial shows you how to calculate an aggregate from the data within HIVE. Here is where you can do the same thing with Polybase, but then store it as a table to be used later.
[sql]
--Similar to lab 2.6.3 - select the data just to see it
SELECT truckid, avg(mpg) avgmpg FROM truck_mileage GROUP BY truckid;
--Create a table to persist the data
CREATE TABLE [dbo].[truck_mpg](
[truckid] [nvarchar](50) NULL,
[avgmpg] [float] NULL
) ON [PRIMARY]
GO
--Insert data into the table by querying the external table
--Now you have the aggregate data that you need persisted locally in SQL Server
--There is no need to store all the sensor data if you don't need all the details
INSERT INTO truck_mpg
SELECT truckid, avg(mpg) avgmpg FROM truck_mileage GROUP BY trucked;
[/sql]
What this allows you to do, for example, is that you may have more data on the truck inventory in a database. This allows you to join your structured data about your truck inventory to the unstructured truck mileage data which is received from truck sensors. This could allow a company to figure out which truck models/years get the best mileage and/or which drivers and/or routes tend to get better gas mileage, etc. All kinds of analysis could be done to help make the fleet more efficient. As a best practice, it is a good idea to persist data from the external tables into tables in SQL Server if you plan to access it more than once (like I did in the sample above).
This has been a bit of a long blog post, but I hope it helps you understand what Polybase can do for you and how it can really help be a bridge between your structured and unstructured data. If you have a Hadoop environment at your company, I suggest you play around with Polybase as there can be a lot of insight that can be gained by combining this data. You can also use Polybase almost like an ETL tool. With Polyabse scaleout, it can perform much faster than doing this ETL with SSIS in many cases.
Take the time to understand other technologies in your organization. It will help your employer and your career to be able to bridge the gap between them and unlock more opportunities to learn about your business.