In-Memory OLTP: Is your database just in memory or actually optimized for memory?
In my many conversations with customers during Microsoft events, people often confuse between the terms ‘In Memory’ and ‘Memory-Optimized’. Many of us think that they are one and the same. If you continue reading this blog, you will realize that they are somewhat related but can lead to very different performance/scalability.
To understand this, let us travel back in time few years when the sizes of OLTP databases were much larger than the memory available on the Server. For example, your OLTP database could be 500GB while your Server box has 128 GB of memory. We all know the familiar strategy to address it by storing data/indexes in smaller chunks in pages. SQL Server supports 8k pages. These pages are read/written in/out of memory using a complex heuristics https://technet.microsoft.com/en-us/library/aa337525(v=sql.105).aspx and it has been implemented as part of Buffer Pool in SQL Server. When running a query, if the PAGE containing the requested row(s) is not found buffer pool, an explicit physical IO is done to bring it into memory. This explicit physical IO can impact query performance negatively. Today, you can get around this issue by buying a Server class machine with say 1 TB of physical memory and keep your full 500GB database in memory. This will indeed improve the performance of your workload by removing bottleneck due to IO path. This is what I refer to as ‘your database is in memory’. However, the more important question to be asked ‘Is your database optimized for memory?’.
Let us consider a simple query on the employee table which is fully in memory including all its indexes SELECT NAME FROM Employee WHERE SSN = '123-44-4444'
Assuming you have an nonclustered index on SSN column, SQL Server fetches this row by traversing the nonclustered index starting from the root page, multiple intermediate pages and then finally landing to the leaf-page. If this index is not a covering index, the SQL Server now needs to traverse the clustered index to the data page to ultimately find the row as shown in the picture below. Assuming that each index was 4 levels deep, SQL Server needed to 8 pages and for each page, it has to take a share latch on the page, search it to find the next pointer and the releasing the latch. This is a lot of work to locate the row assuming the requested row was already in memory. Hope this clarifies the point that while the table is ‘in memory’ but it is not optimized for ‘in memory’. If you think about it, this inefficiency occurs because database or tables are organized as pages, a right decision for the time when databases were much larger than the size of available memory but not for today. 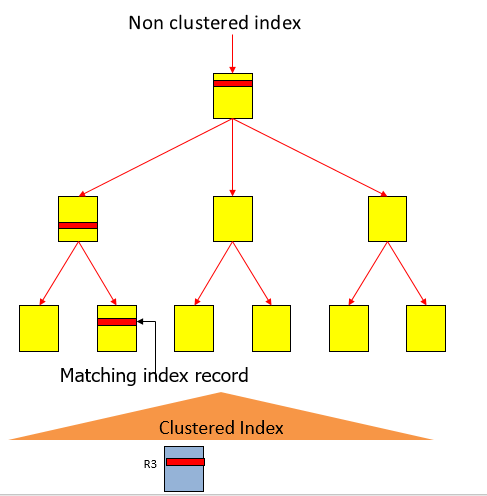
SQL Server In-Memory OLTP engine is optimized for memory and is designed for the case where table(s) are guaranteed to be in memory and it exploits this fact to deliver significantly higher performance.There are no pages and indexes can access the data rows directly. For example, a hash index, on SSN column can be used to find direct pointer to the requested row by first hashing it on the key and then traversing the pointer to find row as shown in the picture below. This is significantly much more performant than traversing 8 index pages as described earlier. 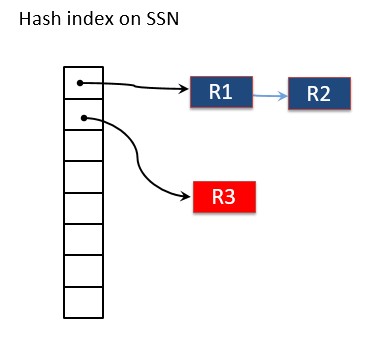
This is just one such example to show that with SQL Server In-Memory OLTP engine, your data is not only in memory but it is also optimized for in memory access. Please refer to https://blogs.technet.microsoft.com/dataplatforminsider/tag/in-memory/ for more information on In-Memory OLTP engine.
Thanks,
Sunil Agarwal
SQL Server Tiger Team
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam
Comments
- Anonymous
November 10, 2016
Great post, as always - Thanks Sunil ! - Anonymous
November 12, 2016
good post!!