Tuning Enovia SmarTeam – Indexes – Part 2
[Prior Post in Series] [Next Post in Series]
In this post I continue on with index analysis from my prior post. First, I will intentionally walk you into a dead end to illustrate when things go wrong and what you should do. Second I will take the right path and show the results.
I took the wrong turn…
Eyeballing the recommendations and the database, I decided to put an index on this pattern:
- [Creation_Date],[User_Object_ID],[User_ID_Mod]
It was one of the recommendations that I thought I would generalize.
The results of applying it and running DTA again are shown below:
Time taken for tuning |
Expected percentage improvement |
Number of indexes recommended to be created |
User Actions |
1 Hour 40 Minutes |
43.35 |
15 |
|
1 Hour 45 Minutes |
43.30 |
14 |
Key on Creation_Date,User_Object_ID, User_ID_Mod |
Clearly, this does not have the type of impact that I wished. I removed these indexes because the basic rule is to add the indexes with the most impact first. This impact was not that. An alternative way of removing indexes would be to do a backup copy before each change and simply restore the database from the backup if the results are not acceptable.
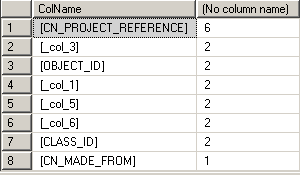
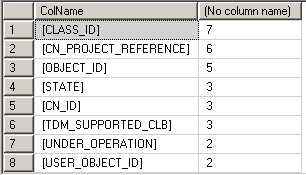
While I was writing up this post, I reprocessed the XML that I had saved and got the following results
Clustered Index Recommendations |
Index Recommendations |
{kind=link}
{kind=link}
My choice should have been an index with [CN_PROJECT_REFERENCE]. Checking the recommendations, the pattern became obvious:
- [CN_PROJECT_REFERENCE]
- [OBJECT_ID]
- [FILE_TYPE]
- [FILE_NAME]
Some of the recommendations had more columns, but reasonableness-check suggests that anything beyond File_Name would be overkill.
Code Solution
The code to implement this pattern is shown below.
SET NOCOUNT ON
DECLARE @CMD nvarchar(max)
DECLARE @Schema nvarchar(max)
DECLARE @Table nvarchar(max)
-- STEP A
DECLARE PK_Cursor CURSOR FOR
Select o.Table_Schema, O.Table_Name
FROM Information_Schema.Columns O
JOIN Information_Schema.Columns C
ON O.Table_Name=C.Table_Name
AND O.Table_Schema=C.Table_Schema
JOIN Information_Schema.Columns D
ON O.Table_Name=D.Table_Name
AND O.Table_Schema=D.Table_Schema
JOIN Information_Schema.Columns E
ON O.Table_Name=E.Table_Name
AND O.Table_Schema=E.Table_Schema
JOIN Information_Schema.Tables T
ON O.Table_Name=T.Table_Name
AND O.Table_Schema=T.Table_Schema
WHERE O.Column_Name='CN_PROJECT_REFERENCE'
AND C.Column_Name='OBJECT_ID'
AND D.Column_Name='FILE_TYPE'
AND E.Column_Name='FILE_NAME'
AND T.Table_Type='BASE TABLE'
ORDER BY T.Table_Name
OPEN PK_Cursor;
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
WHILE @@FETCH_STATUS = 0
BEGIN
SET @CMD='CREATE /*UNIQUE*/ CLUSTERED INDEX [PK_'
+@TABLE+'] ON ['+@Schema+'].['+@Table
+']([CN_PROJECT_REFERENCE] ASC, [OBJECT_ID] ASC, [FILE_TYPE] ASC,[FILE_NAME] ASC,[DIRECTORY] ASC)'
IF NOT EXISTS(SELECT 1 FROM sys.indexes WHERE Name='PK_'+@Table)
BEGIN TRY
EXEC (@CMD)
END TRY
BEGIN CATCH
SET @CMD='Error: '+@CMD
Print @CMD
END CATCH
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
END;
CLOSE PK_Cursor;
DEALLOCATE PK_Cursor;
Next Pass
I will skip the analysis detail and just state the pattern:
- For any table that has [OBJECT_ID] add a clustered key (PK_)
- Exclude all tables that already have a clustered key
- For any table that has [CLASS_ID] add a clustered key (PK_)
- Exclude all tables that already have a clustered key
Remember we are still adding no more than one index per table. A table can only have one clustered key (physical write sequence).
SET NOCOUNT ON
DECLARE @CMD nvarchar(max)
DECLARE @Schema nvarchar(max)
DECLARE @Table nvarchar(max)
DECLARE PK_Cursor CURSOR FOR
Select o.Table_Schema, O.Table_Name
FROM Information_Schema.Columns O
JOIN Information_Schema.Tables T
ON O.Table_Name=T.Table_Name
AND O.Table_Schema=T.Table_Schema
WHERE O.Column_Name='OBJECT_ID'
AND T.Table_Type='BASE TABLE'
ORDER BY T.Table_Name
OPEN PK_Cursor;
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
WHILE @@FETCH_STATUS = 0
BEGIN
SET @CMD='CREATE /*UNIQUE*/ CLUSTERED INDEX [PK_'
+@TABLE+'] ON ['+@Schema+'].['+@Table+']([Object_ID] ASC)'
IF NOT EXISTS(SELECT 1 FROM sys.indexes WHERE Name='PK_'+@Table)
BEGIN TRY
EXEC (@CMD)
END TRY
BEGIN CATCH
SET @CMD='Error: '+@CMD
Print @CMD
END CATCH
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
END;
CLOSE PK_Cursor;
DEALLOCATE PK_Cursor;
DECLARE PK_Cursor CURSOR FOR
Select o.Table_Schema, O.Table_Name
FROM Information_Schema.Columns O
JOIN Information_Schema.Tables T
ON O.Table_Name=T.Table_Name
AND O.Table_Schema=T.Table_Schema
WHERE O.Column_Name='CLASS_ID'
AND T.Table_Type='BASE TABLE'
AND O.Table_Name NOT IN (
SELECT Table_Name
FROM Information_Schema.Columns
WHERE Column_Name='OBJECT_ID')
ORDER BY T.Table_Name
OPEN PK_Cursor;
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
WHILE @@FETCH_STATUS = 0
BEGIN
SET @CMD='CREATE /*UNIQUE*/ CLUSTERED INDEX [PK_'
+@TABLE+'] ON ['+@Schema+'].['+@Table+']([Class_ID] ASC)'
IF NOT EXISTS(SELECT 1 FROM sys.indexes WHERE Name='PK_'+@Table)
BEGIN TRY
EXEC (@CMD)
END TRY
BEGIN CATCH
SET @CMD='Error: '+@CMD
Print @CMD
END CATCH
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
END;
CLOSE PK_Cursor;
DEALLOCATE PK_Cursor;
Summary
Above we looked at both an arbitrary index evaluation (not good yield) and three recommendations produced by logically examining the recommendations from DTA. In this analysis we have been very fortunate to have every recommendation being a clustered key.