SP2013: Understanding storage locations for files gathered by the Crawl Component
When gathering files from a content source, the SharePoint 2013 Crawl Component can be very I/O intensive process – locally writing all of the files it gathers from content repositories to its to temporary file paths and having them read by the Content Processing Component during document parsing. This post can help you understand where the Crawl Components write temporary files, which can help in planning and performance troubleshooting (e.g. Why does disk performance of my C:\ drive get so bad – or worse, fill up – when I start a large crawl?)
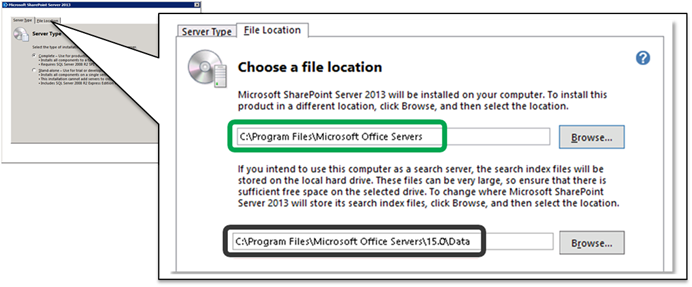
By default, all Search data files will be written within the Installation Path
The Data Directory (by default, a sub-directory of the Installation Path) specifies the path for all Search data files including those used by I/O intensive components (Crawl, Analytics, and Index Components)
- The Data Directory can only be configured at the time of Installation (e.g. it can only be changed if uninstalling/re-installing SharePoint on the given server)
- From the Installation Wizard, choose the "File Location" tab as seen below
- IMPORTANT: Before uninstalling SharePoint, first modify your Search topology by removing any Search components from the applicable server. Once SharePoint is re-installed, you can once again deploy the components back to this server.
- The defined path can be viewed in the registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Setup\DataDirectory
- Advanced Note: The Index files (by default, written to the Data Directory) path can be configured separately when provisioning an Index Component via PowerShell using the "RootDirectory" parameter
- The Data Directory can only be configured at the time of Installation (e.g. it can only be changed if uninstalling/re-installing SharePoint on the given server)
(As a side note: the graphic is only intended to display the default locations specified at install time. It is recommended to change these to a file path other than C:\ drive)
For the Crawl Component:
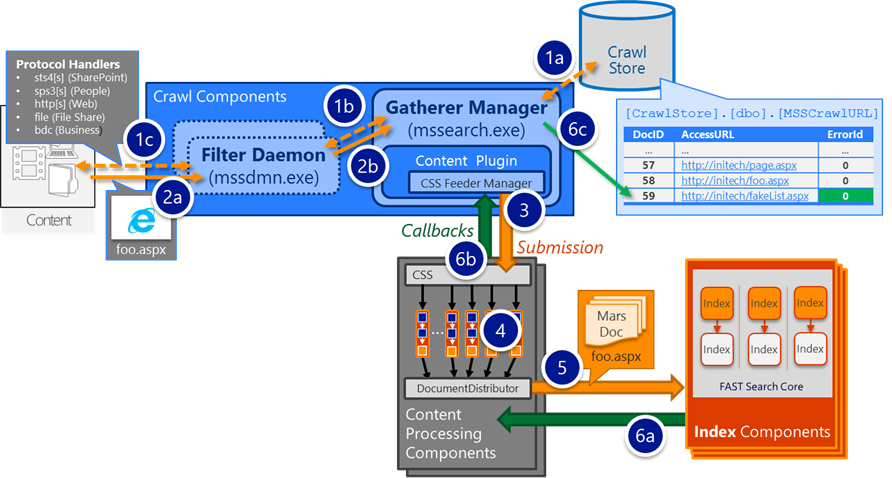
- When crawling [gathering] an item, the filter daemon (mssdmn.exe – a child process of the Crawl Component that actually interfaces with an end content repository using a Search Connector/Protocol Handler) will download any applicable file blobs to the SSA's "TempPath" (e.g. an HTML file, a Word document, a PowerPoint presentation, etc)
- In the graphic below, this is step 2a
- The defined path can be viewed either:
In the registry (of a Crawl server)
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Global\Gathering Manager\TempPath
Or as a property of the SSA:
$SSA = Get-SPEnterpriseSearchServiceApplication
$SSA.TempPath
- When the filter daemon completes the gathering of an item, it is returned to the Gathering Manager (mssearch.exe – responsible for orchestrating a crawl of a given item) and the applicable blob is moved to the "GathererDataPath", which is a path relative to the DataDirectory mentioned above.
In the graphic below, this occurs in step 2b
The defined path can be viewed in the registry (of a Crawl server):
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Components\-GUID-of-theSSA-crawl-0\GathererDataPath
- The GathererDataPath is mapped as a network share (used by the Content Processing Components)
The shared path can be viewed in the registry (of a Crawl server):
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Components\-GUID-of-theSSA-crawl-0\GathererDataShare
Usage by the Content Processing Components:
- When the item is fed from the Crawler to the Content Processing Component (step 3 above), the item is only logically submitted to the CPC in a serialized payload of properties that represent that particular item – any related blob would remain on the Crawler and retrieved by a later stage in the processing flow
- For SharePoint list items, there would typically not be a blob (unless the list item had an attachment)
- For a document in a SharePoint library, the blob would represent the item's associated file (such as a Word document)
- During the Document Parsing stage in the processing flow (e.g. during step 4 above), the item's blob will be retrieved from the Crawl Component via the GathererDataShare
- When the Crawl Component receives a callback (success or failure) from the CPC (e.g. in step 6b above after an item has been processed), the temporary blob is then deleted from the GathererDataPath
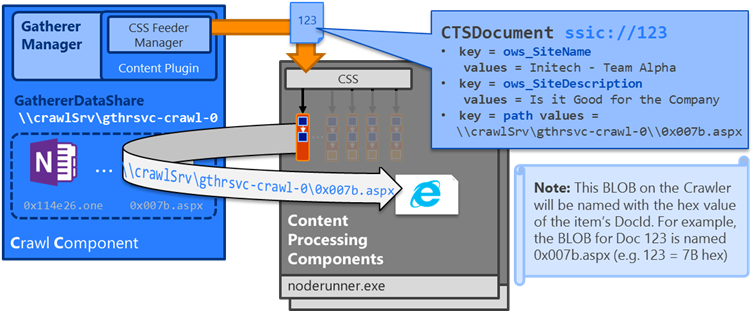
An example path to an item with DocID 933112 would look like the following:
file: //crawlSrv/gthrsvc_ 7ecdbb10-3c86-4298-ab09-04f61aaeb636 -crawl-0//f8/0xe3cf8_1.aspx
#0xe3cf8 hex = 933112 decimal
Where:
- crawlerSrv is a server running a crawl component
- gthrsvc_ -GUID-of-theSearchAdminWebServiceApp- -crawl-0 is the name of the crawl component
This GUID can be identified using the following PowerShell:
$SSA = Get-SPEnterpriseSearchServiceApplication
$searchAdminWeb = Get-SPServiceApplication –Name $SSA.id
$searchAdminWeb.id
7ecdbb10-3c86-4298-ab09-04f61aaeb636
- And the file name is actually re-named to the hex value of the docID
- For example: 0xe3cf8 hex = 933112 decimal
- Which we can see in ULS, such as:
From the Crawl Component (in this case, running on server "faceman"):
mssearch.exe SharePoint Server Search Crawler:Content Plugin af7zf VerboseEx
CTSDocument: FeedingDocument: properties : strDocID = ssic://933112 key = path values = \\FACEMAN\gthrsvc_7ecdbb10-3c86-4298-ab09-04f61aaeb636-crawl-0\\f8\0xe3cf8.aspx
From the Content Processing Component:
NodeRunnerContent2-834ebb1f-009 Search Document Parsing ai3ef VerboseEx
AttachDocParser - Parsing: 'file: //faceman/gthrsvc_7ecdbb10-3c86-4298-ab09-04f61aaeb636-crawl-0//f8/0xe3cf8.aspx'
I hope this help…
Comments
- Anonymous
August 22, 2015
The comment has been removed - Anonymous
September 01, 2016
Great article. Are there also some directories related to Analytics? TN speaks of 300 GB allowance for the drive for Analytics. And search logging?