Типичные ошибки администраторов Configuration Manager и лучшие практики: часть 1
В одной из предыдущих статей этого блога мой коллега Андрей Борзенко рассказывал о мерах предосторожности, которые позволяют избежать очень неприятных проблем при использовании Configuration Manager (далее ConfigMgr). Однако дизайн продукта таков, что некоторые ошибки администрирования продукта приводят к менее критичным, но все еще болезненным последствиям – вплоть до остановки работы самого сервера ConfigMgr и открытия кейса в поддержке с высоким уровнем срочности.
В данной статье я постараюсь описать несколько потенциально опасных сценариев, избежав которых вы сэкономите как свои время и нервы, так и инженеров поддержки.
Инвентаризация
Инвентаризация является одной из базовых частей функционала продукта: чтобы использовать её вам не нужно делать почти ничего, кроме как установить и немного настроить серверную часть, а также развернуть агенты ConfigMgr. Напомню кратко, как работает данный функционал:
1) Администратор определяет интервал сбора данных и параметры метода инвентаризации (например, собираемые классы WMI для Hardware Inventory) в настройках клиентов.
2) Клиенты получают эти настройки и с заданным интервалом отправляют на сервер файлы с собранными данными.
3) В идеальном случае в первый раз отправляется полная инвентаризация, далее же отправляются только дельты.
4) Сервер хранит в БД как актуальные данные, так и исторические, а также ведет лог изменений.
Однако инвентаризацию можно настроить так, что даже если ваш сервер не перестанет работать, то будет работать заметно медленнее. Ниже я приведу несколько таких настроек.
Классы WMI, которые просто собирают слишком много данных
Частой ошибкой администраторов является добавление в настройки инвентаризации таких классов WMI, как Win32_Process и/или Win32_Service. Благая цель инвентаризации процессов и сервисов на клиентских машинах, разумеется, будет достигнута, однако произойдет это ценой раздувания каждого отчета инвентаризации в отдельности и объема собранных данных в БД в целом. С очень большой вероятностью в данных, собираемых этими классами, что-то поменяется к следующему циклу инвентаризации (например, PID процесса или вообще появится новый процесс), а значит будет отправлен дельта-отчет. Сервер, обработав отчет, заботливо заархивирует предыдущие данные и обновит актуальные в базе данных.
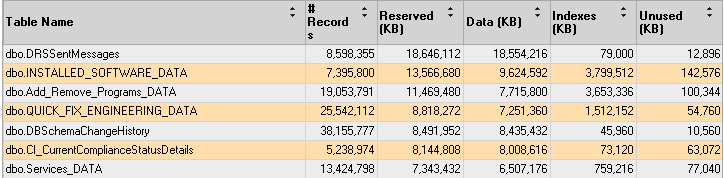
Характерным признаком бездумного добавления таких классов WMI является огромный размер (как по количеству рядов, так по объему места на диске) таблиц в БД, отвечающих за хранение данных инвентаризации (их имена обычно написаны в верхнем регистре и имеют суффиксы _DATA и _HIST). Данную статистику вы можете посмотреть, запустив стандартный отчет “Disk Usage by Top Tables” в SQL Server Management Studio.
Особняком стоит класс CCM_RecentlyUsedApps, который включается в клиентской настройке, если вы разрешите автоматическое создание правил Software Metering, и обслуживается агентом ConfigMgr. По умолчанию в нём деактивирован сбор свойства Launch Count, но даже без этого имейте в виду, что средний размер и количество отчетов инвентаризации от клиентов может заметно вырасти после включения класса – поэтому в больших инфраструктурах правила Software Metering лучше создавать вручную.
Класс WMI, который может остановить работу всей инфраструктуры: Win32_UserAccount
Частой задачей начинающего администратора является инвентаризация локальных пользователей на клиентских рабочих станциях и членства в локальных группах. Поиск по WMI-классам в консоли ConfigMgr приводит незадачливого администратора к классу Win32_UserAccount, название которого очень похоже на то, что требуется собрать. Однако достаточно включить его в клиентской настройке по умолчанию, чтобы получить целый набор проблем.
Тестовый опрос экземпляров этого класса через Wbemtest на доменной машине занимает подозрительно долгое время… и выдает всех пользователей домена, в который включена машина, помимо локальных пользователей. Поэтому в достаточно большом доменном окружении незадачливый администратор, скорее всего, получит телефонный звонок от администраторов домена с просьбой объяснить внезапный всплеск нагрузки от клиентов на контроллеры домена. Если же возникшая нагрузка окажется не слишком велика, то многомегабайтовые отчеты инвентаризации могут серьезно загрузить канал от клиентов к серверу ConfigMgr, компоненты сервера, отвечающие за обработку отчетов, и, разумеется, саму БД ConfigMgr.
Поэтому внимательно читайте описание классов на MSDN перед тем, как включать их инвентаризацию.
P.S. Для решения изначальной задачи необходимо создавать свой класс инвентаризации, например так: Сбор членства в локальных группах
Слишком частое расписание инвентаризации
Еще одна типичная ошибка – сбор данных инвентаризации слишком часто. Простая математика: N клиентов раз в M дней обеспечат вам N/M отчетов инвентаризации на сервере в день. Много это или мало для вашего сервера сильно зависит от его вычислительной мощности. Не забывайте также про исторические данные инвентаризации: сбор данных класса Win32_Process раз в час может обеспечить быстрое заполнение диска с БД SQL.
Кроме того, часть нагрузки распределяется и на клиентские машины. Типичная Hardware Inventory занимает порядка минуты, однако Software Inventory может длиться часами – особенно на больших и медленных дисках с множеством мелких файлов.
Поэтому подумайте о том, какие классы WMI вам действительно нужны, и отключите лишние. Не поленитесь отключить или по крайней мере ограничить какими-то папками инвентаризацию ПО. Увеличьте интервал инвентаризации: вам скорее всего не нужны данные «прямо сейчас», а меняются эти данные куда как реже, чем раз в день или, упаси боже, час (в этом случае собирать их вообще не стоит).
Циклы и расписания
С расписаниями связана почти вся самостоятельная деятельность сервера ConfigMgr. Именно с теми настройками, с которыми поставляется ConfigMgr, рассчитаны показатели масштабирования: такие, как максимальное число клиентов на сайт. Логично, что увеличивая частоту расписаний, вы увеличиваете нагрузку на сервер: пример мы уже рассмотрели в предыдущем разделе. Здесь же мы рассмотрим еще несколько таких опасных сценариев.
Обнаружение ресурсов
Обнаружение ресурсов из Active Directory и наполнение ими БД SQL также является базовой функциональностью ConfigMgr. Один из соблазнов, который появляется у начинающего администратора – увеличить частоту циклов полного обнаружения, чтобы ускорить появление в БД новых ресурсов.
В этом случае снова работает простая математика: каждое выполнение полного цикла обнаружения приведет к необходимости обработать столько ресурсов, сколько их будет обнаружено, не говоря уже о нагрузке на контроллеры домена. Для больших инфраструктур это количество может исчисляться сотнями тысяч (пользователи, группы, машины).
Так называемый Heartbeat Discovery является де-факто минималистичной версией инвентаризации и для этого вида обнаружения справедливы рекомендации предыдущего раздела.
Поэтому разумно подходите к настройкам обнаружения и пользуйтесь дельта-обнаружением по мере возможности для добавления в БД новых ресурсов. Детальное описание методов обнаружения и рекомендации по их использованию приведены в отличной статье этого блога Обнаружение ресурсов в Configuration Manager – обзор, рекомендации, распространенные проблемы.
Запрос политик и развертывания “As soon as possible”
Еще один соблазн начинающего администратора – увеличить частоту цикла запроса политик для ускорения процессов развертывания ПО. Серьезно загрузить запросами политик сервер достаточно сложно, однако в сочетании с развертыванием ПО с расписанием «As soon as possible» (ASAP) это может привести к негативным последствиям.
Начнем с того, что обязательные развертывания с расписанием ASAP сами по себе являются плохой практикой: клиент начнёт закачивать дистрибутив и ставить ПО как только он получит политику – а если это делают сразу много клиентов, то вы рискуете загрузить каналы связи и обеспечить серверу массовую одномоментную обработку отчетов об установке от клиентов.
Интервал запроса политик по умолчанию в 60 минут естественным образом рандомизирует начало установки ПО в том случае, если вы таки решились на развертывание ПО ASAP, однако и этого может быть недостаточно.
Поэтому планируйте развертывание ПО, не торопитесь и устанавливаейте дедлайн развертывания на несколько дней вперед. Напомню, клиент начинает закачивать дистрибутивы назначенных как Required пакетов и приложений в кэш в момент Available Time: это позволит не торопясь и с использованием BITS добиться наличия контента в кэше на момент дедлайна. При установке клиент возьмет контент из кэша и не будет загружать канал. Также не включайте настройку “Disable Deadline Randomization” в настройках клиента при прочих равных: по умолчанию дедлайн рандомизируется на 2 часа - однако помните об окнах обслуживания, без 2 часов их может не хватить.
Сканирование и оценка обновлений
Аналогичный соблазн – увеличить частоту циклов сканирования и оценки обновлений в клиентских настройках для ускорения процессов развертывания обновлений.
Технически первый цикл приводит к синхронизации БД агента Windows Update с WSUS в составе инфраструктуры ConfigMgr и отправке отчета с итогами сканирования на сервер, а второй – к попытке установки обновлений, которая включает в себя сканирование.
Поэтому ускоренные циклы особенно опасны в сочетании с WSUS, на котором давно не запускали мастер очистки и реиндексацию. Результатом такой практики является повышенная нагрузка на CPU и память как на клиентах (от службы Windows Update Agent в составе одного из svchost.exe), так и на пулах приложений IIS на сервере WSUS.
Установка данных расписаний в больших инфраструктурах поэтому также требует вдумчивого планирования и привязке к основным циклам выпуска обновлений.
Переоценка коллекций и "тяжелые" запросы
Еще один важный источник нагрузки на сервер – это переоценка содержимого коллекций. Технически этим занимается один из тредов (SMS_COLLECTION_EVALUATOR) в основной службе SMS_EXECUTIVE на каждом первичном сайте. С заданной администратором частотой происходит переоценка всех правил наполнения коллекции, сбора результатов в один список и дедупликация.
Вновь, слишком частое расписание или слишком сложный запрос может привести к проблемам с производительностью сервера при переоценке коллекций. Обсуждение лучших практик создания и наполнения коллекций достойно отдельной длинной статьи, поэтому здесь я просто порекомендую не устанавливать слишком частое расписание без необходимости, а также использовать утилиту CEViewer.exe из комплекта Configuration Manager 2012 R2 Toolkit для просмотра очередей на переоценку и времени, потраченного на обновление конкретной коллекции.

Кроме того, не злоупотребляйте установкой галочки «инкрементальное обновление»: таких коллекций мы рекомендуем иметь не более 200 на всю иерархию.
Продолжение следует...
К сожалению, на этом список типичных ошибок администраторов не ограничивается. Читайте общие рекомендации и особенности управления терминальными серверами в следующей части.