Procedure used for applying Database Compression to Microsoft SAP ERP system
As promised, we are publishing the stored procedure used to compress Microsoft’s SAP ERP system in this location. This procedure is not the only way getting SQL Server 2008 database compression applied.
The easiest one to use is the tool SAP provides as an attachment to OSS note #991014. It imports an additional report which can be used to assemble the list of tables in a specific schema of the SAP database. It allows compressing a select list of tables or all tables. It allows as well compressing in online and offline mode. For cases where we look at a few hundred GB databases and the chance to perform compression within a downtime, it is the easiest way to use this tool, just select all the tables and go for an ‘offline’ compression using all CPU resources on the table. The goal clearly is to use this tool and only move to use the second tool described here in cases where the situation gets too complicated using the first and simple method. Dependent on the underlying hardware one easily should be able to compress around 500GB-1TB database volume in an offline fashion within 24h.
The strategy also clearly is to compress all tables of the database. With SAP in future releases using SQL Server 2008 Row level compression by default, it doesn't make sense for going for large tables only, but really move the complete database into the state of Row Level Compression. Later on, the same approach might apply to Page Level compression.
The case where compressing a SAP database with a few Terabytes needs to be done ‘online’ with selected time slices in times of low activity (like weekends) needs some more testing, some more planning and eventually a more complex tool which is more like an expert tool. This will be the tool we talk about here.
So what is the tool we used in Microsoft? In the attachment to this blog you find T-SQL coding which when executed will create a stored procedure called sp_use_db_compression. It got developed for the operation conditions we encountered at Microsoft’s SAP landscape:
· The SAP ERP Production System had more or less 6.5TB of data volume to be compressed completely into ROW level compression
· Compression activities only were allowed to run between 6pm Friday evening and Sunday noon
· Compression of data only could be done online with 2-4 CPU resources out of 16 available only
· No additional downtime could be taken beyond the regular 2h every month
· Some weekends needed to be spared due to quarter end reporting
· There were requests not to compress certain tables on specific weekends
· The largest table was 700GB
· Microsoft uses Database Mirroring, hence Full Recovery Model was a given and couldn’t be changed to reduce the transaction log volume created
· Monitoring the progress since Log-shipping was used as well and one needed to know how far the copies of the transaction log backups to the secondary fell back (Transaction log backups are executed every minute)
Steps taken to get to the compression phase
In order to get to the actual compression of the productive SAP ERP system the following steps were done:
· Added another SAN partition to the database server of the test database server on the principal as well as on the mirror side
· A second transaction log file got added on the new partition on the principal side and grew it to a size of a few hundred GB in order to have enough space in the transaction log. The new log file is automatically getting created on the mirror. For this purpose synchronous Database Mirroring got switched to asynchronous. After the extension of the transaction log Database Mirroring got switched into synchronous mode again
· Ran the stored procedure sp_use_db_compression out of the SAP ERP schema with this call:
sp_use_db_compression 'ROW', @online='ON', @maxdop=2
The stored procedure opens a cursor over all tables in the specific database schema, joins data of those tables against some system tables and then works through the list of tables. The procedure has a set of tables which are excluded (tables starting with ‘sap’ or ‘sp’ and which will not be handled. The activity is reported in the table sp_use_db_compression_table. In this table run times, data sizes before and after the compression are reported (see more in the monitoring section). While this process was running, operations on the test system continued including stress tests. After a few days the whole execution finished. Checking the table sp_use_db_compression_batch_input one can find entries like this:
Tab_Name |
Target_Type |
Compression_Type |
Online |
Status |
APQD |
DATA |
ROW |
OFF |
TO_BE_DONE |
CIF_IMOD |
DATA |
ROW |
OFF |
TO_BE_DONE |
D342L |
DATA |
ROW |
OFF |
TO_BE_DONE |
Tables reported with the Status ‘TO_BE_DONE’ are some of the larger table with varbinary(max) columns. This tables can’t be rebuilt in an online manner and require to be done in a downtime or in low workload times
In a downtime executed the stored procedure again with the following syntax:
sp_use_db_compression 'ROW', @maxdop=0, @batch_input=1
This time the stored procedure took the entries marked with a Status of ‘TO_BE_DONE’ in the table sp_use_db_compression_batch_input as input of tables to be compressed and worked through the list of tables in an online fashion (see more later).
At the end of such a run through a test or sandbox system with production like data one has a pretty comprehensive idea about the run time under eventually even more strenuous conditions than one could expect in production. Going through the table sp_use_db_compression_table with a select like this:
select * from sp_use_db_compression_table order by Date DESC
one could get a list of tables in the reverse order of the compression. With the following statement:
select sum(Compression_Time) from sp_use_db_compression_table
one gets the sum of the time taken to compress the whole test system in milliseconds. In the particular case of Microsoft’s system one calculated that one probably needs 6 weekends to perform compression of different set of tables. To remain on the conservative side one calculated on spending 30h per weekend. It also figured out that the largest table would require one weekend for itself.
Building the Packages for the different weekends
After a lot of discussions with the user community using the MS SAP ERP system an agreement on the weekends for the online row level compression work was reached. At the same time, tables were identified which could not be converted on certain weekends. The next step was to create six tables of the structure of 'sp_use_db_compression_batch_input' which would contain all the tables of the SAP ERP database. The different portions of the tables in those 6 different tables (functioning as work packages per weekend) were structured according to the run time. Important rule: The available freespace in the database has to be at least the size of the table to be compressed. The easiest way to achieve this, is to start with the smallest tables and work the way up to the largest table. Why is this? Tables in the database are typically fragmented and are rebuilt during the compression. The released fragmentation space + the space saved by the compression will increase the available freespace. In the case of the MS SAP ERP system the first package contained all but around 70 tables. The other 6 packages contained less and less tables up to the last one, which only consisted of one single table. The format and content of one of the tables/packages looked like:
Tab_Name |
Target_Type |
Compression_Type |
Online |
Status |
YPUMAWIP |
DATA |
ROW |
ON |
TO_BE_DONE |
VBAP |
DATA |
ROW |
ON |
TO_BE_DONE |
HRP1001 |
DATA |
ROW |
ON |
TO_BE_DONE |
VBPA |
DATA |
ROW |
ON |
TO_BE_DONE |
SWFREVTLOG |
DATA |
ROW |
ON |
TO_BE_DONE |
GLPCA |
DATA |
ROW |
ON |
TO_BE_DONE |
PPOIX |
DATA |
ROW |
ON |
TO_BE_DONE |
The work packages were called like 'sp_use_db_compression_batch_input_week<x>'. Each weekend prior to the compression work, to renames had to be executed: rename of 'sp_use_db_compression_batch_input' to 'sp_use_db_compression_batch_input_week<prior week>' and rename of 'sp_use_db_compression_batch_input_week<x>' to 'sp_use_db_compression_batch_input'. It is important to keep the content of table 'sp_use_db_compression_batch_input' after the compression was finished to identify tables which have to be done in offline mode. The last step in the compression work is to execute the offline compression for all left-over tables. One has to combine all the rows of the different batch_input tables which had the Status ‘TO_BE_DONE’ and with the column Online being set to ‘OFF’ into the finale 'sp_use_db_compression_batch_input' table. A regular downtime was used then to compress those tables to Row level compression. New tables created out of the SAP Data Dictionary will be automatically created in the Row Level compression format.
Monitoring while compression is running
There are two possibilities for monitoring while the compression procedure runs. With this query:
select * from sp_use_db_compression_table order by Date desc
one basically gets an output as shown in the screenshot below:
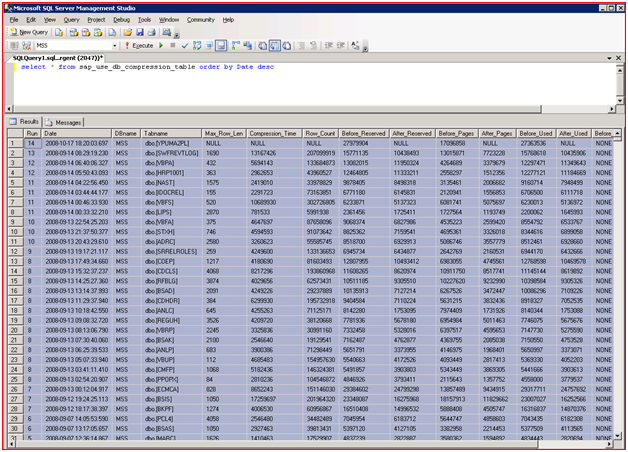
Please note the first row with NULL values in columns like Compression_Time, Row_Count, After_Reserved. This is an indication that this table is currently being worked at.
If sp_use_db_compression is executed with <'@batch_input=1'> set as parameter then another possibility for monitoring is:
select * from sp_use_db_compression_batch_input
The result then could look like:
Tab_Name |
Target_Type |
Compression_Type |
Online |
Status |
YPUMAWIP |
DATA |
ROW |
ON |
DONE |
VBAP |
DATA |
ROW |
ON |
DONE |
HRP1001 |
DATA |
ROW |
ON |
IN_WORK |
VBPA |
DATA |
ROW |
ON |
TO_BE_DONE |
SWFREVTLOG |
DATA |
ROW |
ON |
DONE |
GLPCA |
DATA |
ROW |
ON |
TO_BE_DONE |
PPOIX |
DATA |
ROW |
ON |
TO_BE_DONE |
The table with the Status field set to ‘IN_WORK’ will indicate the table which is being compressed at the moment.
Experiences with Row Level Compression so far
From a space savings point of view, the MS SAP ERP system experienced savings of 29%. Sure this included effects of database re-organization as well. However one needs to take into account that a lot of content in major tables were not too fragmented anyway. Reason was a Unicode Migration which took place in 2007. The Unicode Migration left the database in a complete re-organized state. Nevertheless, 29% were more than 1.76TB freespace released. Given the fact that images of the productive database in the Microsoft SAP landscape is stored for at least 10 times the overall saving amount to more than 17TB. There was a wide bandwidth of compression efficiency on different tables. There were some tables like ANLC which compressed down to ¼ of their original size. There were other tables which were cut to half of their volume. We saw a great effect on one of our customer tables which was 700 GB with 1.6 billion rows. After applying row level compression the table ended up with 280GB of volume.
Other positive side effects were:
· One could observe a reduction of I/O. However a visible improvement of the database response time could not be immediately observed. Reasons are manifold starting with the fact that the cache hit ratio of the SAP ERP system anyway was beyond 99% before already. Other reasons are that the database response time on daily basis varies by a range of 25-30% anyway dependent on load and season
· Online backups and differential backups became smaller. Thanks to SQL Server 2008 Backup Compression, backups were reduced dramatically anyway. However a reduction could be observed again after Row level compression got applied
What about performance of specific jobs? Honestly in Microsoft one didn’t investigate in the many hundreds of different jobs which are running on the systems. One only can tell one thing which is that no jobs runtime has increased due to row level compression. An increase of CPU consumption also couldn’t be observed. However that also would be difficult due to changes in the 10% range on a daily basis. Stress tests in the test environment after row level compression also showed a performance neutral behavior in the system.