How It Works: SQL Server 2005 NUMA Basics
The Senior Escalation Engineers do various training and mentoring activities. As I do this I thought I would try to propagate some of this information on the blog.
I have received several questions on the SQL Server NUMA implementation this week. Much of this was covered in my 2006 PASS presentation in Seattle but allow me to summarize. This is not a complete document by any means but it should be helpful.
Hard NUMA
Hard NUMA is the NUMA configuration indicated to the operating system by the physical computer.
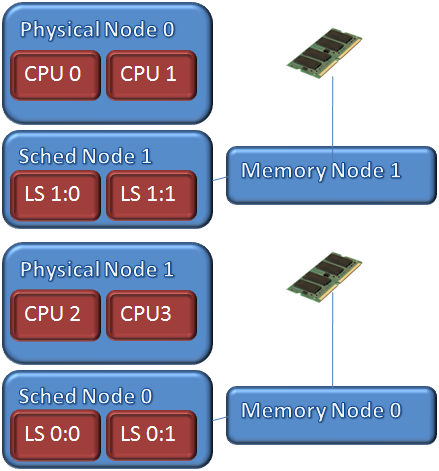
The following diagram shows a system with 2CPUs per NODE. SQL Server creates a logical scheduler and memory node that matches the hardware configuration. Notice that I have not drawn any specific lines between the logical schedulers (LS) and the physical CPUs. You must use the sp_configure affinity mask values to directly associate a scheduler with a CPU and the affinity mask setting can change the alignment behavior. SQL Server does restrict the schedulers to the same node. LS 1:0 is not allowed to execute on CPU2 or 3 unless the entire node is brought offline.
Soft NUMA
Soft NUMA is SQL Server specific and is used to configure how SQL Server looks at and uses the available hardware. This is accomplished using registry settings. Soft NUMA allows you to create various node combinations.
One point of emphasis is that soft NUMA disables the buffer pools use of memory locality.
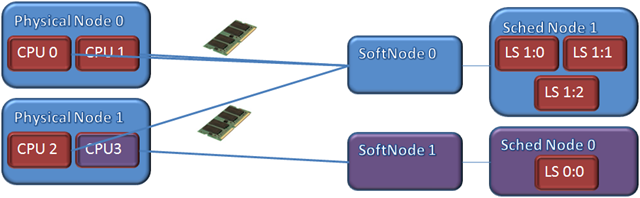
Soft NUMA allows you to sub-divide a physical hardware node but you are NOT allowed to combine CPUs from separate hardware nodes into a single, soft NUMA node. The diagram below shows an ILLEGAL, soft NUMA configuration. CPU1 from Physical node 1 can’t be part of SoftNode0.
Port Binding
There are various reasons that soft NUMA is considered, one of the primary is port binding for connection assignments.
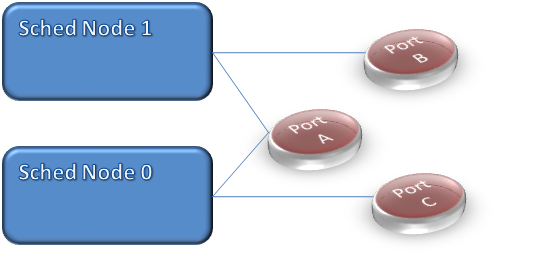
SQL Server allows the network ports to be bound to one or more scheduler nodes as shown in the diagram below. The default is to bind the default port to all scheduler nodes as shown by Port A. When a connections are made to Port A they are assigned between the scheduler nodes in round-robin order. So connection 1 goes to scheduler node 1, connection 2 to scheduler node 0, connection 3 to scheduler node 1 and so forth.
Binding a specific port binds all connections to that port to the specified node. This is often used to target specific application requirements. One customer I know of bound the default 1433 port to soft node 1 as shown in the above diagram. This forced all the connections on to the single node, single CPU. They then bound the production purchase order and shipping applications to a port associated with soft node 0. This made sure that the critical line of business application got more resources and someone running an Excel report would not be assigned so many resources.
Buffer Pool Locality
During buffer pool initialization soft or hard NUMA is determined. When soft NUMA is enabled all memory is considered local and the locality of the memory is not tracked.
When hard NUMA is used the configured (max server memory) memory for SQL Server is divided equally among the 'active nodes'. This means that you should always make sure the configured memory is evenly divisible and installed evenly among logical and physical nodes. You don't want one node to have 4GB and the other 8GB and configure SQL Server to use 12GB because SQL Server will use 6GB for each node and 2GB of that is going to be remove for one of the nodes.
Remote memory access times vary based on the hardware but requires additional access time (~100ns). Running under hard NUMA SQL Server buffer pool tracks the physical memory locations when allocating memory when ramping up. If the memory was allocated on a different physical node the buffer pool will redo the memory allocation to get a local memory allocation instead.
By tracking the memory all the memory and limiting the workers to only the schedulers within that node memory allocations are localized for best performance.
Lazy Writer per Node
When running under hard NUMA a lazy writer process is created for each node. This allows each node to watch its memory usage and take appropriate LRU actions. This allows additional optimizations. For example when a checkpoint executes it normally issues the page writes. When running under hard NUMA the I/O request is submitted to the lazy writer associated with the node. This makes sure the node that owns the memory does the write, reducing remote memory access and streamlining the I/O path as well.
Offline Node
Using the sp_configure affinity mask values you can take schedulers and nodes offline. As long as one scheduler within a node is online the node is considered online. If all schedulers on a node are taken offline the node is taken offline as well. This puts several things in motion that you should be aware of.
The memory associated with the node is drained and redistributed among the remaining nodes. You should reconfigure the max memory setting or you will get remove memory assigned to the remaining nodes.
The workers associated with the offline schedulers are always moved to a viable scheduler. So if I take LS 0:1 offline it will share the resources with LS 0:0. Any remaining work on the LS 0:1 scheduler (commands already in progress) will compete for resources within the node.
If you take both LS 0:0 and LS 0:1 offline the node associated the logical processing with physical node 0 to complete remaining work and will compete for resources with LS 1:0 and LS 1:1.
Node 1 and 0 Reversed
The diagrams seems to have node 1 and 0 incorrectly reversed. This is not the case because SQL Server understands that the physical node 0 is often the startup location of the operating system and has less available physical memory. SQL Server will move its default node 0 away from the physical node 0 so the core data structures for SQL Server are created on a node that commonly has more physical memory available.
Single CPU per Node
Some computers report physical NUMA with a single CPU per node. I have seen this most often with a dual core machine that has a single memory bank. Under these conditions SQL Server will assume the computer is not a NUMA based machine and start up SQL Server as if it is just a simple SMP computer.
SQL Data Structures
Several of the SQL Server data structures have been updated to be NUMA aware (locks, execution plans, ...). These structures track their origination location and return to that location when released. Take a lock for example. A lock structure is associated with a transaction structure. If you engage in a DTC transaction using multiple sessions the sessions could be assigned to different nodes based on the round-robin connection assignments. Once one session can commit the transaction and would have access to the entire lock list. For the same reason the buffer pool maintains locality for performance the lock structures are returned to the free lock list for the owning memory node.
SQL Server uses a single compiled plan to described the query execution but the individual execution plans use node local memory. This means the SQL Server will maintain the same plan across all nodes but during execution of the plan local memory is used.
DAC Node
Dedicated Admin Connections (DAC) are supported by the NUMA concept. SQL Server creates a purely logical scheduling and memory nodes and binds the DAC port only to that node. The DAC node is always a logical node that can execute anywhere. This allows DAC a level of isolation and the logical design can be used on SMP machines as well.
REFERENCE: For addition details refer to Slava's blog: https://blogs.msdn.com/slavao/
-----------------------------------------------------------------------------------------------
[RDORR Jan 28, 2008]
I had a couple of good questions posted about this blog from the good folks at https://www.sqlservercenteral.com which I will try to clear up.
The 'Lost In Translation' segment points out that NUMA is hard to understand. This is exactly how I felt many years ago when the SQLOS team started talking about the NUMA design needs. The key for the majority of customers is that SQL Server does a bunch of work so you don't have to understand many of the NUMA complexities.
NUMA design is all about divide and conquer. Let me start is an example. Say you are designing a hash table. If you protect it with a single critical section it does not scale well as you add more CPUs and entries. Since you already have a fixed number of hash buckets when the table is created the entire table does not need to be protected. Instead a design using a critical section for each bucket would be a better design. Upgrading that to a reader writer design would lend itself to even better scalability.
NUMA scales better when you keep your memory access local and avoid remote access when possible. While remote access is still faster than the I/O required to retrieve a page into memory it is many nano-seconds longer.
SQL Server designed the buffer pool to track the location of memory. The SQL Server buffer pool buffers can be stolen by the various memory users (sys.dm_os_memory_clerks). The memory users are designed to work like heaps backed by the buffer pool memory allocations.
A stolen buffer is an 8K buffer that is owned by a memory user and can't be touched by the lazy writer like a database page could be. For example a default memory connection (4096 packet size) allocates 1-4K input buffer and 2-4K output buffers. This memory can't be moved (AWE mapping) because it is being used as a memory pointer.
Because the buffer pool (hard NUMA) tracks the memory locality it can return a local memory buffer to the memory user. So the memory allocations in the server immediately benefit from local memory access by the way the buffer pool is designed.
With that ...One point of emphasis is that soft NUMA disables the buffer pools use of memory locality) is in italics. What does that mean for a server? It would be nice to see a link or short note on the implications of this...
I am glad this caught your eye. When you treat a NUMA machine with separate memory banks attached to separate nodes as if all memory is shared the same you can change the performance. Since the buffer pool is not tracking the locality of memory when running soft NUMA the memory is a mix of local and remote memory. It becomes the luck of the draw if a memory access will be local or remote forcing a longer retrieval time. So there is a performance difference but the penalty will be hardware specific.
Bob Dorr
SQL Server Senior Escalation Engineer
Comments
Anonymous
January 26, 2008
PingBack from http://www.ditii.com/2008/01/26/how-it-works-sql-server-2005-numa-basics/Anonymous
June 28, 2010
[Jun 2010 Update] So an example of SQL swapping node 0 – Node 0 for any instance: The code will find the first configured node for the instance (6 in the example below) and swap it. So Node 0 contains the affinity mask that was set for 6 and initialization of actions such as Buffer Pool initialization. It is just a walk down on the array for the instance; find the first configured node with a valid affinity mask and swap it as node 0 for reporting and initialization purposes. The following is the error log for INST2 Node configuration: node 7: CPU mask: 0x0000000038000000:0 Active CPU mask: 0x0000000038000000:0. Node configuration: node 6: CPU mask: 0x000000000000000f:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 5: CPU mask: 0x0000000000f00000:0 Active CPU mask: 0x0000000000000000:0. ... Node configuration: node 1: CPU mask: 0x00000000000000f0:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 0: CPU mask: 0x0000000007000000:0 Active CPU mask: 0x0000000007000000:0. Instance Soft Numa Mask Soft Node Affinity INST1 0000000F 0 0-3 1111 … INST2 0000000007000000 6 24-26 111000000000000000000000000 0000000038000000 7 27-29 111000000000000000000000000000 INST1 would look like the following Node configuration: node 7: CPU mask: 0x0000000038000000:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 6: CPU mask: 0x0000000007000000:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 5: CPU mask: 0x0000000000f00000:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 4: CPU mask: 0x00000000000f0000:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 3: CPU mask: 0x000000000000f000:0 Active CPU mask: 0x0000000000000000:0. Node configuration: node 2: CPU mask: 0x0000000000000f00:0 Active CPU mask: 0x0000000000000f00:0. Node configuration: node 1: CPU mask: 0x000000000000000f:0 Active CPU mask: 0x000000000000000f:0. <- Notice the SWAP with NODE 1 Node configuration: node 0: CPU mask: 0x00000000000000f0:0 Active CPU mask: 0x00000000000000f0:0. If you look at sys.dm_os_nodes you should always see a node 0 for any instance.
- Bob Dorr
- Anonymous
September 19, 2010
The comment has been removed