How a log file structure can affect database recovery time
We frequently come across situations where databases take a long time to recover. A common scenario is where the recovery process has to roll forward or back several transactions for a database after a SQL Server restart. However, you might also see one of the following symptoms which can result in databases take long time to recover (even if there are not many transactions in the log file).
1. Startup of database from restart of SQL Server or Backup/Restore or Attach/Detach or from auto close.
2. Log reader latency when a database is used in transactional replication: The reader thread of the log reader process is responsible for scanning the transaction log to identify which transactions need to be replicated.
CAUSE:
This can happen if the log file has grown several times (usually as a result of very small auto-growth setting). As a result, the log will have several 1000 to several million VLFs (you can read more about VLFs in Transaction Log Physical Architecture). The first phase of recovering a database is called discovery where all the VLFs are scanned (in serial and single threaded fashion) before actual recovery starts. Since this happens much before the analysis phase, there are no messages indicating the progress in the SQL Server error log. Depending on the number of VLFs this initial discovery phase can take several hours even if there are no transactions in the log that need to be processed.
COLLECT THE FOLLOWING DATA TO DETERMINE IF YOU ARE RUNNING INTO THIS PROBLEM:
1. Error log from the time where a database is taking a long time to recover.
2. From Management Studio, execute DBCC LOGINFO(dbname)--for the database in question. This will have to be collected when the database is online. Note: This query can take a long time to run depending on number of VLFs. Use caution when running this on a live production server. You can use a script similar to the following to identify number of VLFs per log file.
NOTE: This script can cause a growth in tempdb if the database contains several million VLFs.
NOTE: Running DBCC LOGINFO against a database snapshot is not supported.
SET NOCOUNT ON
GO
CREATE TABLE #VLFs (
FileId INT NOT NULL,
FileSize BIGINT NOT NULL,
StartOffset BIGINT NOT NULL,
SeqNo INT NOT NULL,
Status INT NOT NULL,
Parity INT NOT NULL,
CreateLSN DECIMAL (25,0))
GO
INSERT #VLFs EXEC ('DBCC LOGINFO (dbname) WITH NO_INFOMSGS')
GO
SELECT FileId , COUNT(*) AS VLF_Count FROM #VLFs GROUP BY FileId
GO
DROP TABLE #VLFs
GO
WHAT TO LOOK FOR:
1. To confirm that you are running into this problem, check the error log for the database in recovery. The last message you will see for that database(while in recovery) in the log:
2008-06-26 10:29:20.48 spid58 Starting up database 'pubs'.
Once the pre-recovery has completed, you will see the following message which indicates that recovery has actually started reading the transactions. In this example, you can see that it took almost 9 minutes before the following message appeared.
2008-06-26 10:38:23.25 spid58 Analysis of database 'pubs' (12) is 37% complete (approximately 0 seconds remain). This is an informational message only. No user action is required.
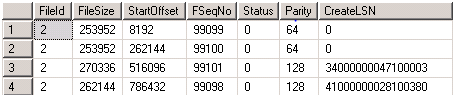
2. DBCC LOGINFO(dbname) -- Since you will not be able to collect this during recovery of the database in question, run the script above as soon as recovery finishes to give you an idea of how many VLFs each log file has. For one of the databases that I recently came across, the log file had 1.9 million VLFs. (Hint: The number of rows returned by the DBCC command correlates to number of VLFs). The FileSize column indicates size of each VLF in bytes. Here is a sample output of DBCC LOGINFO:
SOLUTION:
Several fixes have been made to improve recovery time of databases from VLF issues. Apply all applicable fixes as listed in the following KB article:
2028436 Certain database operations take a very long duration to complete or encounter errors when the transaction log has numerous virtual log files
https://support.microsoft.com/kb/2028436/EN-US
As an alternate solution, reduce the number of VLs using the steps listed below:
1. Run DBCC SHRINKFILE to reduce the ldf(s) to a small size, thereby reducing the number of VLFs.
NOTE: Running DBCC LOGINFO against a database snapshot is not supported.
2. Run DBCC LOGINFO(dbname) or the script above and make sure the number of VLFs is < 500-1000.
3. Expand(resize) the log file to the desired size using a single growth operation. This can be achieved by setting a new Initial Size for the ldf(s) in the Database Properties->Files->Database files section.
4. Run DBCC LOGINFO(dbname) or the script above and verify that the number of VLFs is still a small number. NOTE: Step 3 may create multiple VLFs even if you specify a large size. However, each VLF will be large.
5. Turn-off auto close option for the database. This can have adverse effects every time a database has to be started.
6. Backup the database.
We have also seen Database Mirroring affected by a large number of VLFs in the transaction log. See
979042 FIX: The principal database is not recovered if the database has a large number of virtual log files in SQL Server 2005
Here are some references regarding the topics discussed above:
949523 The latency of a transactional replication is high in SQL Server 2005 when the value of the "Initial Size" property and the value of the Autogrowth property are small
907511 How to use the DBCC SHRINKFILE statement to shrink the transaction log file in SQL Server 2005
317375 A transaction log grows unexpectedly or becomes full on a computer that is running SQL Server
On a related topic, our recommendation to customers is to not rely on auto-grow for sizing a data/log file. Auto-grow should be used a fallback mechanism and a good database design takes into account capacity planning needs so that they are sized appropriately upfront according to application needs. Physical operations like growth/shrink during OLTP operations can be expensive and cause performance issues. The articles below give guidelines on using these settings as well as some diagnostics/known issues as a result of auto-grow operations.
315512 Considerations for the "autogrow" and "autoshrink" settings in SQL Server
305635 PRB: A Timeout Occurs When a Database Is Automatically Expanding
822641 Additional diagnostics added to diagnose long-running or canceled database autogrow operations in SQL Server
Ajay Jagannathan | Microsoft SQL Server Escalation Services
Comments
Anonymous
May 21, 2009
PingBack from http://microsoft-sharepoint.simplynetdev.com/how-a-log-file-structure-can-affect-database-recovery-time/Anonymous
May 25, 2009
I have a demo of how this can affect database mirroring with sample code here http://blogs.msdn.com/grahamk/archive/2008/05/09/1413-error-when-starting-database-mirroring-how-many-virtual-log-files-is-too-many.aspxAnonymous
May 26, 2009
My understanding is that for large log files, shrinking the file down and then growing it back out in one operation can result in a different problem wherein there are too few VLFs for the database. I believe that this can result in problems clearing the log. I have been following Kimberly Tripp's recommendation to re-grow the log file in a given unit: http://www.sqlskills.com/BLOGS/KIMBERLY/post/Transaction-Log-VLFs-too-many-or-too-few.aspxCan you please comment on this?Anonymous
May 20, 2011
If you experience this problem, please install the fix to prevent it in future:2455009 FIX: Slow performance when you recover a database if there are many VLFs inside the transaction log in SQL Server 2005, in SQL Server 2008 or in SQL Server 2008 R2support.microsoft.com/default.aspxAnonymous
November 07, 2014
I like you way and used this tool is good but I have an another tool to repair and recover all over MDF files from corrupt or damged SQL server. Visit here:-Anonymous
June 20, 2015
Go through sqldatabaserecoverysoftware.blogspot.com/.../recover-sql-server-database-file.html to know about Run DBCC CHECKDB command to repair SQL Server Database.Anonymous
April 27, 2016
Nice Read... I also have a small suggestion to sdhare with every one of you... One can go to http://www.dataretrieval.us/ to take advice from experts... I got my damaged hard drive and laptop drive recovered from them. ..