SQL Server Performance Tuning: Data Access Method
Writing Queries in SQL Server is not all that hard. But, writing Queries by understanding the different patterns SQL Server uses to fetch your data from the disk, resource utilization which can help build efficient query writing skills.
There are multiple ways how SQL Server accesses data from the tables. To illustrate the point I make, I shall query a heap and a clustered tables in AdventureWorksDW2012 in a few different ways
The clustered table taken for the example is FactInternetSales which has a Clustered Index on attributes SalesOrderNumber and SalesOrderLineNumber.
I shall create a heap table , like so

To draw a comparative analysis between the two tables, I have dropped all non-clustered indexes from table FactInternetSales. In addition, I have turned on the Actual Execution Plan and STATISTICS IO , TIME to understand the execution pattern for the below queries.
Query 1 : Execute the Query on the Heap Table

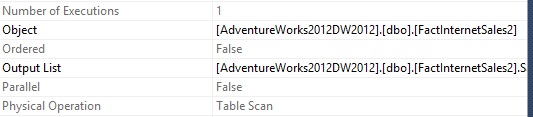

Query 2: Execute the below query on the clustered Table without an Order By Clause

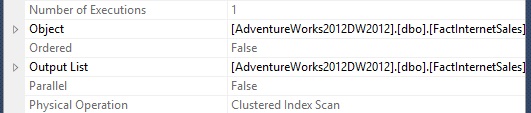

Query 3: Execute the below query on the clustered Table with an Order By Clause



Let's us list the differences between the above 3 queries -
- Query1 as expected was a Table Scan with Ordered Property Value as "False". Logical Reads measure 1313. CPU Time = 350 ms
- Query2 was a Clustered Index Scan with Ordered Property Value as "False". Logical Reads measure 2062. CPU Time = 364 ms
- Query3 was a Clustered Index Scan with Ordered Property Value as "True" and a new Property Scan Direction as "FORWARD". Logical Reads measure 2061. CPU Time = 393 ms
These above differences may be summarized into the following buckets, like so
- Logical Reads Measure
- CPU Time
- Ordered Property
Logical Reads Measure
If we can use the DBCC IND command to get the number of data pages for both the tables , it will explain the difference in Logical measure between the Clustered Table and the Heap table. In this case, the clustered index is fragmented which means more IO as compared to that of the Heap Table. To understand more around the DBCC IND command, there is an excellent post by Paul Randal which can be referred from here.

CPU Time
In the event of a fragmented index (FactInternetSales Clustered Index is fragmented) , An Unordered Scan (Query2) may consume (not necessarily though!!) lesser resource (IO or/and CPU time) than an Ordered Scan (Query3).
Ordered Property
In Query2, SQL Server did an Unordered Clustered Scan while Query3 was an Ordered Scan. Both were full scans as expected. The first query however, had no requirement for an ordered set. SQL Server uses different algorithms to fetch the data -
- For Query2, SQL Server reads the IAM Pages to fetch the list of pages which holds the data. Refer the sys.system_internal_allocation_units table to know more. This type of scan is called the allocation order scan (or a Unordered Clustered Scan) and it will not ensure the order of the dataset as per the clustered key.
- Where as in Query3, when we exclusively asked SQL Server to fetch the data in an ordered fashion, it scans through the binary tree of the Clustered Index.
I do hope you find this useful. Thanks for reading. Do share your views/learnings on this.