Math Language Tag
To guide proofing tools to use the correct dictionaries and autocorrect lists as well as to display preferred glyphs, it’s very handy to associate language tags with text runs. For many years, Windows has provided a language tag property called the LCID (locale identifier) consisting of a 32-bit unsigned integer. The LCID suffices for many purposes. But as time has gone on, more and more languages have been supported on computers and finer distinctions have been needed than provided by the LCID’s primary and secondary languages and sort order. Accordingly the BCP 47 language tag was invented, which offers great generality and flexibility. This post discusses how language tags are important for math zones and proposes a BCP 47 tag for math.
First, a couple of general comments about LCID deprecation in favor of BCP 47 tags: there are a myriad documents that use LCIDs and they aren’t going away any time soon. There are also many published APIs and programs that currently use LCIDs. So for backward compatibility we need to continue to support LCIDs even as we generalize programs to be fluent with BCP 47 tags. Fortunately modern XML-based document formats like Microsoft Word’s docx and PowerPoint’s pptx use BCP 47 language tags already.
Math zones need to have a language tag for three main reasons: 1) specify the math autocorrect list, 2) prevent natural language proofing tools from changing or commenting on mathematical text, and 3) identify mathematical text for math-oriented tools, such as equation solvers and graphing programs. Partly for these purposes, Windows created the math LCID 0x0001007F. In fact, the Microsoft Office math autocorrect file is named mso0127.acl, where 0127 = 0x007F. The question arises as to what the corresponding BCP 47 tag should be.
Note that file formats (HTML5, RTF, docx, pptx, odf, etc.) do not need a math language tag. Math zones are handled in structured ways by MathML, OMML, RTF and TeX. The math language tag is only needed for in-memory processing, such as for proofing tools.
The Windows functions LCIDtoLocaleName and LocaleNameToLCID translate between LCIDs and locale names, which are essentially BCP 47 language tags. These functions work faithfully for simple BCP 47 tags such as “en-US” for English as used for the most part in the United States of America. But they fail for BCP 47 tags that don’t have LCIDs. Interestingly enough, the functions do have a locale name for the math LCID 0x0001007F, namely “x-IV_mathan”. This choice has to do with the way the LCID is used in sorting the math alphanumerics. The ‘x’ means private use, which is not appropriate for text interchange and the underscore is illegal in BCP 47 syntax. So “x-IV_mathan” isn’t appropriate for a math BCP 47 language tag. LCIDtoLocaleName clearly needs to continue to return this tag, but proofing programs can use a more suitable tag.
A BCP 47 tag consists of one or more subtags separated by hyphens. The first subtag is the human language subtag, e.g., “en” for English. It’s interesting to ponder whether math is a human language. Certainly math has been created by humans to communicate a wealth of ideas and relationships. But in the ISO-639 or BCP 47 sense, math isn’t a human language and ISO and IANA would never add a language subtag for math. Accordingly, let’s use the currently defined “und” for “undefined language”. What really identifies a BCP 47 tag for math is the math ISO script subtag, which is “Zmth”. So the proposed math BCP 47 language tag is “und-Zmth”. Thanks are due to several people on the Unicode Technical Committee who recommended this choice (Steven Loomis, Peter Constable, Mark Davis).
Math is usually associated with a natural language substrate, like English, and different substrates may use different typographical features. For example, in Europe it’s common to use an upright i or j for the square root of -1, whereas in the United States of America, a math italic ?? or ?? is used. In Russia, limits of integrals in display math zones are usually displayed above and below the integral sign instead of to-the-side like superscripts and subscripts. OMML (Office MathML) has ways to specify these properties on a document level, while MathML needs to “hard wire” them in each math zone. In some Arabic locales, right-to-left math is used. While an enhanced math language tag might be useful for identifying such differences, they are probably better handled in other ways, such as by default document properties. Substrate language text that appears inside a math zone, such as in
is tagged with the corresponding BCP 47 tag. In this case, the “if” is tagged with “en-US” while the rest of the math zone would use “und-Zmth”. That way embedded normal text is manipulated using the appropriate proofing language and the math text is handled by math proofing tools.
Comments
Anonymous
February 16, 2015
At least in Word 2010 and earlier, proofing doesn't work well together with mathematics. For instance, if I write "What if x = 2?" in a Microsoft Word document, where "x = 2" is a math region, I will get a green wavy underline at "if ", suggesting me to replace it by "if", so that the text becomes "What ifx=2?".Anonymous
February 17, 2015
I don't repro this problem with Word 2013 or OneNote 2013. Hopefully it's fixed.Anonymous
March 06, 2015
I noticed that the green underlining appears when putting the '?' outside of the math zone, whereas it does not appear when putting the '?' inside of the math zone, so maybe just that's the difference. I don't know though if putting punctuation marks into math zones has any further implications. I do so all the time, because of the proofing difference and because finishing sentences with formulas and a '.' would transform those formulas to inline style. While writing my bachelor thesis in mathematics with Word 2013 (all those LaTeX guys at my university always looking at me unbelievingly :) ) I noticed another quirk: Putting a display style math zone with a mathematical set like {n in doubleN | sum_(i=1)^n of a_i < 20} with a separator | within that set (or any middling operator like mid) will make the sum appear inline style. I wonder if you know the reason for that behaviour? I know it's offtopic and you are probably sick of hearing about it, but is there any information if equation numbering is getting some love in Office 2016? While the three cell table approach you outlined is working, I don't like installing 3rd party plugins, and this isn't even possible on my Surface 2. Greetings from Germany!Anonymous
March 13, 2015
@Henning: That doesn't happen to me in Word 2010. See privat.rejbrand.se/wordeq20150314.pngAnonymous
March 14, 2015
Oh, lucky you! Hmm, I tried it again, but every big operator like sum, int or bigcap is being squeezed to inline-style when put within a set with a separator. :( Thanks for your feedback though.Anonymous
October 02, 2015
Murray, It looks really dangerous to declare math as being a (universal) language. sen(2πn) should be in Spanish while sin(2πn) would be in English! kgV(15,3) should be in German... paulAnonymous
October 23, 2015
Good point. Math zones often have embedded ordinary text and that text is described by appropriate language tags. It might be good to have a convention that if such tags are missing, ordinary text in a math zone inherits the locale info of the parent of the math zone. At least that's what Microsoft Office software does. This convention is handy for spell checking and autocorrect. OTOH, Word uses a default set of English function names and allows the user to customize the function name list, rather than localize it. It'd be interesting to have a table of function names versus language. But certainly understanding math around the world is facilitated by its relative independence from natural language.
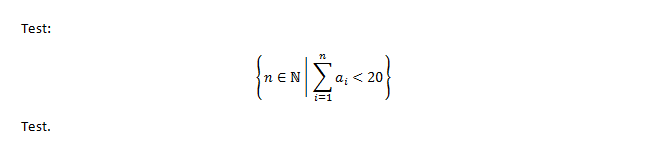{kind=link}