Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Piece jointe pour le billetData_Jupyter
Pour faire suite à notre première introduction sur les évolutions d'Azure Machine Learning (Azure ML) et sur la configuration de l' « établi » et des services associés, nous souhaitons vous donner à présent au travers de ce billet (en deux parties) un premier aperçu des capacités du nouvel environnement Azure ML, c.à.d. le service d'expérimentation, le service de gestion des modèles et bien sûr l' « établi » (Azure ML Workbench), sur un jeu de données en rapport avec la maintenance prédictive.
Après une rapide présentation des objectifs et des prérequis, cette première partie aborde le jeu de données que nous nous proposons d'utiliser pour la circonstance et l'étape clé de préparation de celui-ci. Une seconde partie couvrira sur cette base l'apprentissage de nos modèles à proprement parler.
J'en profite pour remercier Paul Jenny actuellement en stage de fin d'étude au sein de Microsoft France pour cette contribution.
Nos objectifs pour ce billet
Comme souligné ci-avant, ce billet vise à proposer une illustration de bout en bout du nouvel environnement Azure ML. Pour ce faire, cette illustration simple utilise un algorithme d'apprentissage profond (Deep Learning) avec comme objectif de pouvoir prédire si un équipement va tomber en panne prochainement pour optimiser la maintenance de celui-ci. Le modèle obtenu pourra être déployé directement sur/à proximité de l'équipement au sein de son informatique embarquée par exemple : un cas d'usage typique des scenarii de l'Internet de vos objets (IoT).
Cette illustration utilise pour cela un jeu de données provenant de capteurs d'un moteur d'un moteur d'avion. (Une étude réalisée à partir de ce jeu de données sur la modélisation de la propagation des dommages est disponible ici sur la forge GitHub.)

L'algorithme utilisé pour la classification binaire est ici un réseau de neurones récurrents de type LSTM (Long-Short Term Memory), qui s'avère particulièrement efficace lorsqu'il s'agit d'étudier des « tendances » dans des données périodiques. En effet, les données sont remontées régulièrement par les capteurs et nécessitent donc d'être analysées par « cycle » pour obtenir une tendance générale (notamment à cause du bruit induit par le capteur).
En résumé, les objectifs pour ce billet sont :
- L'utilisation de l' « établi » Azure ML Workbench,
- L'utilisation d'un bloc-notes Jupyter,
- La création d'un algorithme de classification binaire pour prédire si le moteur va se dégrader, dans une fenêtre de temps donnée (ici un cycle moteur),
- L'utilisation du service d'expérimentation d'Azure ML,
- L'utilisation du service de gestion de modèles pour un déploiement futur sur un équipement. (IoT, etc.).
Avertissement : ce tutoriel n'a pas pour but de générer le modèle le plus « précis ». De nombreuses pistes d'amélioration sont exposées à la fin de ce billet pour les lectrices et lecteurs de ce blog souhaitant aller plus en profondeur. Il s'agit ici de couvrir une première utilisation de bout ne bout du nouvel environnement Azure ML.
Quelques prérequis
Pour les besoins de l'exercice, ce tutoriel suppose les prérequis suivants :
- Disposer de bases en Machine Learning (et notamment les réseaux de neurones),
- Bénéficier d'un compte Azure actif (Cf. billet précédent),
- Avoir installé les nouveaux services d'Azure (voir le billet précédent ici),
- Avoir créé un compte de stockage Azure pour le stockage des jeux de données via un blob,
- Avoir téléchargé le jeu de données utilisé ici issu de la NASA,
- Disposer des bases en Python,
- Avoir téléchargé les scripts Python et les fichiers de configuration du projet en pièce jointe de ce billet.
Le jeu de données
La première étape d'un scénario d'analyse de données consiste à explorer le jeu de données à la recherche de tendances, d'incohérences, de valeurs manquantes, etc.
Les fichiers texte sont des jeux de données séparées par un espace. Chaque ligne représente une capture des différentes données provenant des capteurs des moteurs sur un cycle donné.
Les colonnes représentent :
- Le n° du moteur
- Le moment auquel la capture a été faite, en cycles,
- Le paramètre n°1 du moteur,
- Le paramètre n°2 du moteur,
- Le paramètre n°3 du moteur,
- La mesure du capteur n°1,
- La mesure du capteur n°2,
- ...
- La mesure du capteur n°26.
Quatre scénarios (FD001, FD002, FD003, FD004) ont été simulés pour tester le moteur sous différentes conditions (altitude de l'avion et dégradation du moteur).
Les données ont déjà été séparées en données d'entraînement (train_FDXXX.txt)et données de test (test_FDXXX.txt) :
- Dans les données d'entraînement, les observations sont récoltées à chaque cycle jusqu'à la panne du moteur. La dernière ligne pour chaque moteur représente ainsi son dernier cycle avant ladite panne moteur.
- Dans les données de test, la dernière observation ne représente pas le dernier cycle avant panne moteur.
Afin de valider nos modèles, le temps restant réel pour les données de test a été ajouté dans des fichiers distincts (RUL_FDXXX.txt).
Pour les besoins de notre illustration, nous allons nous consacrer uniquement sur un seul scénario : FD001. Dans les jeux de données, nous avons ainsi :
- Train_FD001.txt : ~20 000 lignes et 100 moteurs,
- Test_FD001.txt : ~13 000 lignes et 100 moteurs,
- RUL_FD001.txt : 100 lignes (une pour chaque moteur).
Nous voulons répondre à la question suivante dans le cas de la classification binaire :
Est-ce que le moteur va tomber en panne dans les X prochains jours ? (X est un paramètre choisi par le client).
La préparation du jeu de données
Nous allons commencer par créer notre projet sur l' « établi » Azure ML Workbench. Pour cela, lancez l'application Azure ML Workbench et cliquer sur le + situé sur la droite de votre espace de travail puis sur New Project :
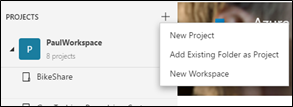
Nous vous laissons le soin de donner un nom à ce projet et choisissez pour cela Blank Project. Copiez ensuite dans le dossier du projet les fichiers fournis en pièce jointe de ce billet. Ceux-ci sont les scripts Python pour l'apprentissage et la configuration du projet.
Nous allons ensuite importer nos différents fichiers dans le projet :
- Cliquez sur l'icône Data
 puis sur le + et Add Data Source.
puis sur le + et Add Data Source. - Choisissez ensuite File(s) / Directory puis Local et recherchez votre fichier train_FD001.txt.
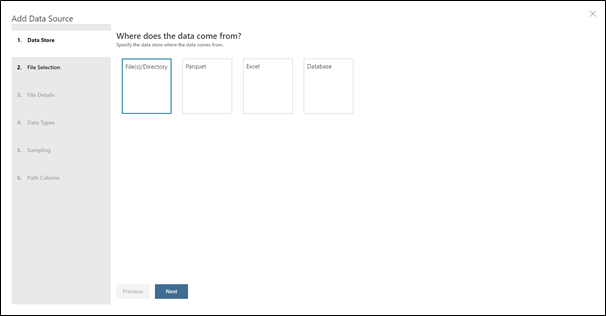
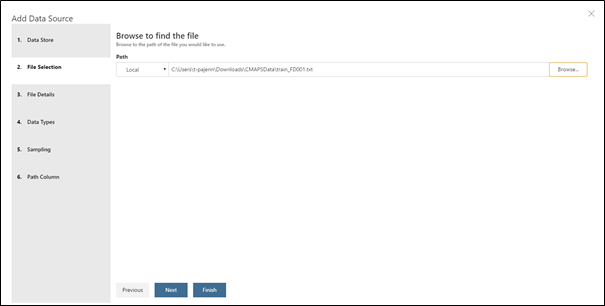
Dans la fenêtre suivante, dans la liste déroulante de Promote Headers Mode, sélectionnez No headers. Cela a pour effet d'indiquer à AML Workbench de ne pas sélectionner la première ligne du fichier en tant que libellés de colonnes.
Ensuite, vous pouvez sélectionner le type (Numeric, String, Date, Boolean) de vos colonnes. Azure ML Workbench a essayé de déterminer pour vous le type.
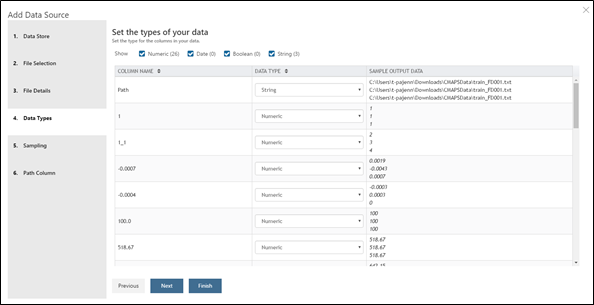
- Enfin, dans la fenêtre Sampling, vous pouvez séparer vos données pour ne pas charger l'ensemble du jeu ce qui pourrait amener à une consommation excessive de mémoire vive. Néanmoins, comme le jeu de données est ici relativement léger, nous pouvons considérer de charger l'ensemble du jeu en mémoire. En conséquence, cliquez sur Edit puis dans Sample Strategy la méthode Full File.
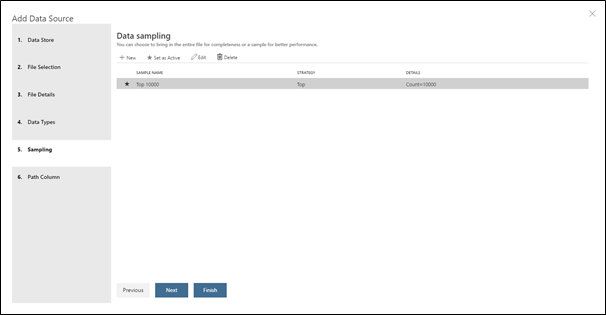
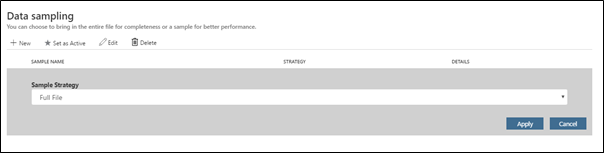
- Dans la dernière fenêtre Path column handling, sélectionnez Do Not Include Path Column. Le chemin du fichier peut être utile pour pouvoir extraire des informations qui ne sont pas présents autrement dans le jeu de données. (Par exemple, nous pourrions ici filtrer par scénario moteur si l'on mélangeait tous les jeux de données disponible dans le dossier de la NASA).
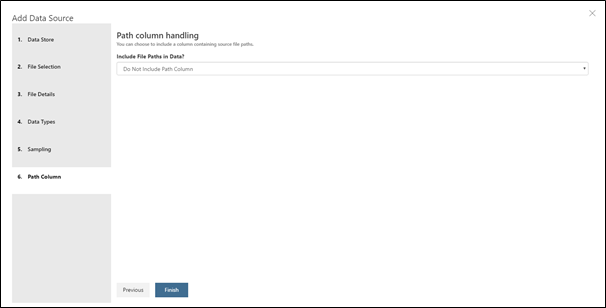
- Cliquez enfin sur Finish.
Vous pouvez vous déplacer dans ce tableau sans éditer les données ou les colonnes. Cette étape permet d'explorer un jeu de données, de gérer les valeurs manquantes, etc.
La barre verte située sous le nom des colonnes représente la proportion de valeurs présentes (vert), valeurs manquantes (gris) et erreurs (rouge). On peut donc ainsi facilement déduire que notre jeu de données d'entraînement ne comprend aucune valeur manquante. Ensuite, on remarque deux colonnes vides situées à la fin sont présentes. Il convient donc de (penser à) les supprimer. Cela est vraisemblablement dû à une erreur de formatage du fichier source.

Nous pouvons enfin aussi regarder des métriques (distribution, fréquence, moyenne) sur nos colonnes en cliquant sur la commande Metrics juste au-dessus du tableau.
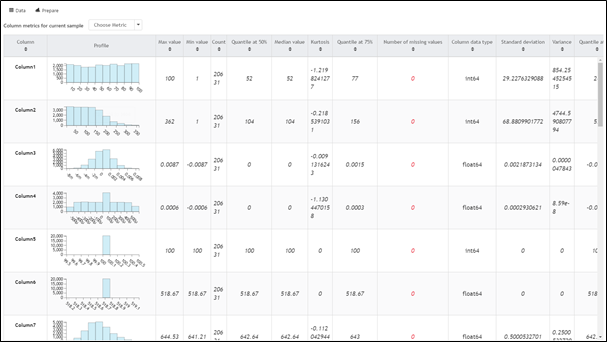
Vous pouvez à présent effectuer les mêmes opérations pour le jeu de données de test (test_FD001.txt) et le fichier de vérité (RUL_FD001.txt).
Vous devez vous retrouver ainsi avec 3 sources de données :

Deux choix s'offrent à vous ensuite pour préparer le jeu de données :
- Vous pouvez utiliser un code en Python dans un bloc-notes Jupyter (1_dataprep.ipynb) ;
-ou-
- Vous pouvez passer l'excellent outil de préparation des données d'Azure ML Workbench.
Quelle que soit l'approche, deux fichiers CSV (train.csv et test.csv) sont créés pour l'apprentissage de nos modèles dans le dossier de votre projet et/ou dans un stockage Blob dans votre compte de stockage Azure.
Voyons ce qu'il en est.
Avec un bloc-notes Jupyter
Pour accéder au bloc-notes Jupyter associé, vous pouvez cliquer sur l'icône  sur la gauche d'Azure ML puis sur le bloc-notes 1_dataprep. Vous devez ensuite lancer le serveur Jupyter en cliquant sur Start Notebook Server.
sur la gauche d'Azure ML puis sur le bloc-notes 1_dataprep. Vous devez ensuite lancer le serveur Jupyter en cliquant sur Start Notebook Server.
Vous connaissez ensuite les opérations pour pouvoir exécuter les différentes cellules.
Avec Azure ML Workbench
Pour préparer vos jeux de données, sélectionnez tout d'abord la source de données. Commençons par la source « train_FD001 ». Cliquez sur le bouton Prepare situé au-dessus du tableau.
Nommez le fichier de préparation de données « train ». Vous retrouvez ici exactement la même interface que précédemment. Cependant, vous pouvez dorénavant supprimer des colonnes, exécuter des codes Python, etc.
Commençons par exemple par supprimer les deux dernières colonnes vides. Sélectionnez les deux colonnes par l'appui de la touche CTRL puis cliques-droit sur Remove Column. Une nouvelle étape est ajoutée sur la droite de l' « établi ». Vous pouvez ainsi aisément revenir en arrière, visualiser les différentes étapes qui vont ont permis de préparer votre jeu de données.
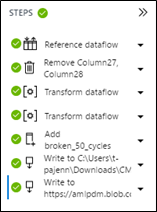
L'outil supporte également l'ajout de transformation en Python. Par exemple, vous pouvez renommer les colonnes. Pour cela, allez dans la barre de tâches / Transforms / Transform Dataflow (Script) . Une fenêtre vide s'affiche avec les instructions pour écrire vos transformations en Python. Renommez les colonnes avec le code ci-dessous :
capteurs = ["c{0}".format(i) for i in range(1,22)]
params = ["param{0}".format(i) for i in range(1, 4)]
columns = ["id","cycle"] + params + capteurs
df.columns = columns
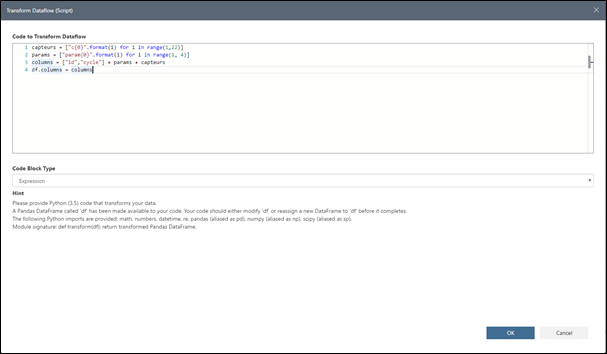
Cliquez sur OK. Après quelques secondes, vous pouvez apercevoir que vos colonnes ont changé de nom et une nouvelle étape a été ajoutée à votre préparation de données.
Nous allons ensuite effectuer une seconde transformation pour pouvoir récupérer le RUL (pour rappel, Remaining Use of Life) pour chaque cycle d'un moteur.
df['cycle_max'] = df.groupby(['id'])['cycle'].transform(max)
df["RUL"] = df["cycle_max"] - df["cycle"]
del df["cycle_max"]
Pour gérer notre cas de classification binaire, il est nécessaire qu'on le puisse générer le libellé associé à la classe. (Pour rappel, nous souhaitons savoir si un moteur va tomber en panne dans X jours).
Nous allons ainsi utiliser une autre transformation d'Azure ML Workbench, à savoir Add Column (Script) :
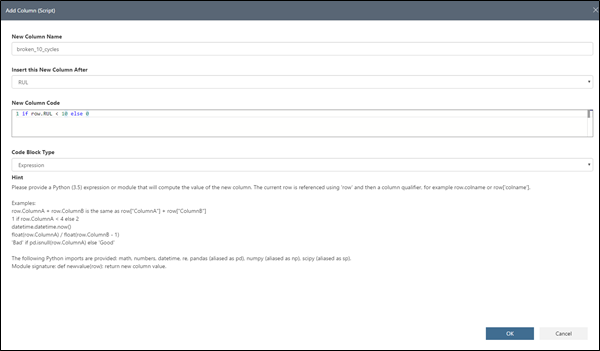
New Column Name : spécifie le nom de la colonne créée (ici, broken_30_cycles)
Insert this New Column After : indique à quelle position cette colonne doit-elle être ajoutée ?
New Column Code : précise le code pour générer la colonne
1 if row.RUL < 30 else 0
Code Block Type : indique comment votre code doit être interprété ? (Expression ou module Python)
Nous avons choisi ici un nombre de jours défini à 30 avant la panne. Grâce à l'utilitaire, vous pouvez facilement éditer cette valeur via cette étape ultérieurement sans parcourir tout votre code. Cliquez sur OK.
Notre jeu de données d'entraînement est maintenant prêt. Nous allons à présent l'exporter vers un format plus simple à manipuler aisément, un fichier CSV. Pour cela, retournez dans le menu Transforms puis sélectionnez Write to CSV.
Vous pouvez aussi exporter vers un fichier Parquet pour l'écosystème Apache Hadoop dans le cas de fichiers lourds. Exportez ce fichier :
- Dans le dossier de votre projet avec le nom « train.csv » si vous souhaitez effectuer l'entraînement en local ;
-ou-
- Sur un stockage Blob dans (un compte de stockage) Azure si vous souhaitez effectuer l'entraînement du modèle sur une cible distante.
Remarque : Vous pouvez exporter les données vers différentes cibles. Ainsi, vous pouvez créer une étape pour l'exportation vers un dossier local et une autre étape pour l'exportation vers stockage Blob dans (un compte de stockage) Azure.
Nous pouvons à présent passer à la préparation des données de test. Retournez pour cela sur la source de données test_FD001 puis cliquez sur Prepare. Choisissez bien l'option + New Data Preparation Package afin de créer un nouveau fichier de préparation de données.
Nous allons effectuer une opération identique à la précédente pour supprimer les colonnes et renommer les colonnes restantes (Cf. ci-dessus pour le code asscoié).
Un aspect intéressant de l'outil de préparation est de pouvoir fusionner plusieurs sources de données dans un seule et même fichier de préparation de données. Cliquez sur la source de données RUL_FD001 puis sur Prepare. Cette fois-ci, choisissez le dprep (Data Preparation Package) test (celui que vous venez de créer). Vous avez ainsi dans votre dprep deux flux de données, test_FD001 et RUL_FD001. Nous allons ajouter dans RUL_FD001 l'index de nos différents moteurs (qui correspond au numéro de la ligne). Pour cela, ajouter une transformation Transform Dataflow (Script) :
df.insert(loc = 0, column="moteur",value= df.index + 1)

Cliquez sur OK.
On va ensuite renommer la colonne Line par RUL_restants. Vous pouvez double-cliquer sur le nom de la colonne ou effectuer un clic-droit puis Rename Column pour effectuer cette action.
Une fois ceci effectué, passons à la fusion de nos deux flux de données : notre fichier de vérité et notre fichier de test. Pour cela, effectuez une nouvelle transformation Join. Choisissez pour Left le flux test_FD001 et pour Right le flux RUL_FD001 puis cliquez sur Next.
Azure ML Workbench va tenter de déterminer les colonnes sur lesquelles les jointures devront être effectuées. Néanmoins, ici, cela ne fonctionne pas… Choisissez pour lui en cliquant sur la colonne id de test_FD001 et sur la colonne moteur de RUL_FD001 puis cliquez sur Next.
Azure ML Workbench affiche alors un aperçu de la jointure avec les lignes qui correspondent ainsi que les lignes qui n'ont pas trouvé de correspondance pour chacun des deux flux de données. Vous pouvez choisir le type de jointure que vous souhaitez utiliser (LEFT, RIGHT, INNER, OUTER) en cochant les cases associées à droite. Ici, nous n'allons conserver que les lignes qui ont une correspondance.

Un nouveau flux de données est créé avec votre jointure. Nous allons à présent pouvoir effectuer les mêmes opérations que sur le jeu de données d'entraînement. Effectuez la transformation Transform Dataflow (Script) pour pouvoir générer le nombre de jours restants avant que le moteur ne tombe en panne :
df['cycle_max'] = df.groupby(['id'])['cycle'].transform(max)
df["RUL"] = df["cycle_max"] - df["cycle"]
del df["cycle_max"]
del df["moteur"]
del df["RUL_restants"]
Puis ajoutez la colonne pour avoir le libellé nécessaire à la classification binaire avec la transformation Add Column :
New Column Name : spécifie le nom de la colonne à créer (ici, broken_50_cycles)
Insert this New Column After : inique à quelle position cette colonne doit être ajoutée ?
New Column Code : précise le code pour générer la colonne :
1 if row.RUL < 50 else 0
Code Block Type : indique comment votre code doit être interprété ? (Expression ou module Python)
Pour valider que le choix de 50 cycles est approprié par rapport à notre jeu de données, vous pouvez regarder le nombre de 1 et 0 dans cette colonne. Pour cela, effectuez un clic-droit sur l'en-tête la colonne broken_50_cycles puis cliquez sur Value Counts :
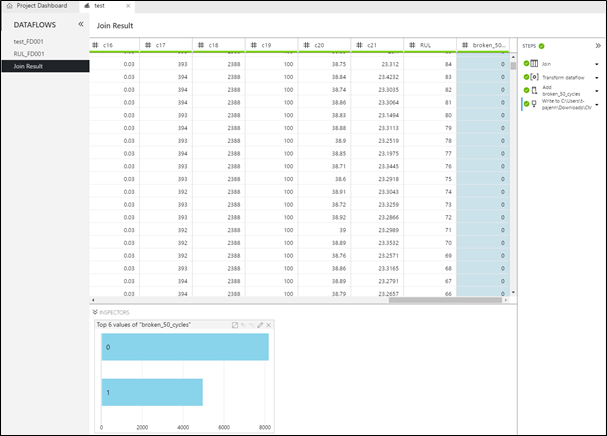
Notre jeu de test est maintenant prêt, nous allons pouvoir l'exporter en fichier .CSV ou Parquet par la transformation Write to CSV ou Write to Parquet.
Exportez dans le dossier du projet sous le nom « test.csv » si vous souhaitez effectuer l'entraînement du modèle en local ou sur un stockage Blob dans Azure si vous souhaitez effectuer l'entraînement du modèle sur une cible distante.
L'étape de préparation du jeu de données est maintenant terminée.
Avertissement : L'ensemble des opérations précédentes pouvaient être effectuées via le bloc-notes Jupyter 1_dataprep.ipynb. L'objectif était ici de démontrer avec Azure ML Workbench les facilités données d'explorer un jeu de données, de traiter les erreurs éventuelles, de formater les données dans un format utilisable pour la suite.
Nous allons donc pouvoir passer à l'apprentissage de nos modèles ! Ce sera l'objet de la seconde partie de ce billet. Stay tuned!