Running Gadgetron in Kubernetes in Azure
In my not so distant past, I started an Open Source project called the Gadgetron. There is a scientific publication that lays out the motivation and use cases. It is a medical image reconstruction engine, which has been used primarily for processing of Magnetic Resonance Imaging (MRI) raw data. Specifically, it is used to transform (reconstruct) the raw data in to images that can be viewed by a clinician.
We showed that the Gadgetron can be deployed in the cloud and that doing so enabled clinical deployment of advanced reconstruction techniques that required far more computing power than would typically be available on a modern MRI system. The deployment was based on Docker containers, but a the time we used custom orchestration scripts and tools. In this blog post, I will discuss my initial attempt at using Kubernetes running in Azure for deploying the Gadgetron.
I have created a repository with the necessary artifacts and instructions, you can find it at https://github.com/hansenms/gadgetron-kubernetes.
The deployment to Kubernetes in Azure is a two-step process:
- Creating the Kubernetes cluster.
- Deploying the Gadgetron.
Creating the Kubernetes Cluster
There are a several different ways to do this in Azure. If you are using the public Azure Cloud (Commercial Azure), then you can use the managed Azure Kubernetes Service (AKS). If you choose this route, please consult the AKS documentation for details. In the repository, I am also including instructions for setting up the cluster using ACS Engine, which is the open source engine that underpins services such as AKS. In additions to provisioning Kubernetes clusters, it can be used to provision other orchestration frameworks, e.g., Docker Swarm, DC/OS, etc.
You will find the instructions for deploying a Kubernetes cluster within the repository. Briefly, the steps are:
Clone the repository:
[shell]
git clone https://github.com/hansenms/gadgetron-kubernetes
cd gadgetron-kubernetes
[/shell]
Create resource group and service principal:
[shell]
subscription=$(az account show | jq -r .id)
#Name and Location
rgname=gtkubernetes$RANDOM
loc=eastus
#Create Group
rg=$(az group create --name $rgname --location $loc)
rgid=$(echo $rg | jq -r .id)
#Create the Service Principal and assign as contributor on group
sp=$(az ad sp create-for-rbac --role contributor --scopes $rgid)
[/shell]
Convert the template ACS Engine API model:
[shell]
cd acs-engine
./convert-api.sh -c $(echo $sp | jq -r .appId) \
-s $(echo $sp | jq -r .password) -f kubernetes.json -l $loc \
-d "${rgname}DNS" | jq -M . > converted.json
[/shell]
Deploy the cluster:
[shell]
acs-engine deploy --api-model converted.json \
--subscription-id $subscription --resource-group $rgname \
--location $loc --azure-env AzurePublicCloud
[/shell]
The deployed cluster will have cluster autoscaling on. What this feature does is to add more agent nodes when a request to deploy a pod (with a Gadgetron container) would exceed the currently available resources in the cluster. With this feature on, we can use Kubernetes Horizontal Pod Autoscaling to add more Gadgetron pods when needed and more underlying VMs will be added as needed. More on that below.
Deploying the Gadgetron
After deploying the cluster itself, we are ready to deploy the Gadgetron components into the cluster. The end result will look conceptually like this:
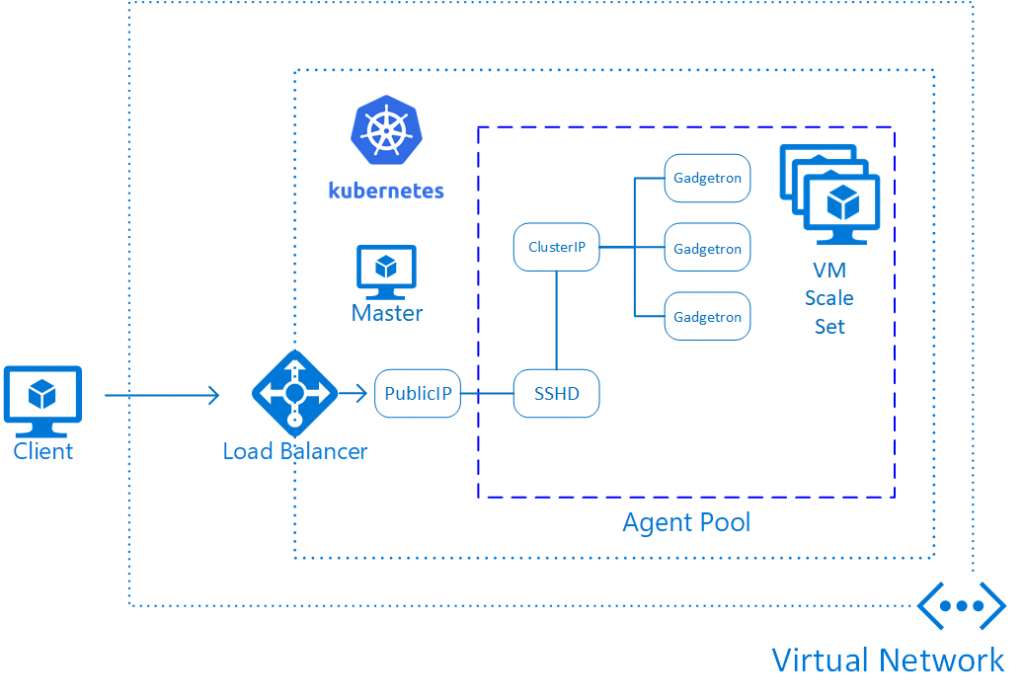
There are really 3 components in the deployment:
1. Some shared storage. Gadgetron pods need a shared storage location to store dependent measurements (noise data, etc.). In this case, we are using Azure Files to store this data. There is a script in the repository for creating the shared storage.
2. Some pods with the Gadgetron itself. These pods are exposed with a Kubernetes Service of type "ClusterIP". This means that the Gadgetron pods will not be accessible from outside the cluster.
You can see the details of what is deployed in the gadgetron-kubernetes.yaml manifest. You can apply this manifest with:
[shell]
kubectl apply -f gadgetron-kubernetes.yaml
[/shell]
Importantly, this manifest defines a) the image being used, b) the resources required for a pod to run the Gadgetron, and c) a Horizontal Pod Autoscaler, that will automatically add more pods when a certain average CPU load is reached for the deployed Gadgetron instances. Since we also have cluster autoscaling deployed, more VMs will be added to the agent pool if the required resources exceed available capacity.
2. An SSH jump server. This is essentially an SSH server running in a pod in the cluster. This is exposed with service of type "LoadBalancer", which means that it will get a public IP address. To deploy the server allowing the current user to connect:
[shell]
#Get an SSH key, here we are using the one for the current user
#Replace with other key as needed
SSHKEY=$(cat ~/.ssh/id_rsa.pub |base64 -w 0)
sed "s/PUBLIC_KEY/$SSHKEY/" gadgetron-ssh-secret.yaml.tmpl > gadgetron-ssh-secret.yaml
#Create a secret with the key
kubectl create -f gadgetron-ssh-secret.yaml
#Deploy the jump server
kubectl apply -f gadgetron-ssh-jump-server.yaml
[/shell]
Connecting to the Gadgetron
It is beyond the scope of this blog post to explain how to create and send data to the Gagetron, but you will want to establish an SSH tunnel (through the jump server). By default the jump server gets deployed with a public key from the current user. You can connect with:
[shell]
#Public (external) IP:
EXTERNALIP=$(kubectl get svc sshd-jumpserver-svc --output=json | jq -r .status.loadBalancer.ingress[0].ip)
#Internal (cluster) IP:
GTCLUSTERIP=$(kubectl get svc gadgetron-frontend --output=json | jq -r .spec.clusterIP)
#Open tunnel:
ssh -L 9022:${GTCLUSTERIP}:9002 root@${EXTERNALIP}
[/shell]
After this you should be able to send some data with:
[shell]
ismrmrd_generate_cartesian_shepp_logan -r 10
gadgetron_ismrmrd_client -f testdata.h5 -p 9022 -o myoutput.h5
[/shell]
Conclusions and Next Steps
I have demonstrated the basics steps of deploying the Gadgetron in a Kubernetes cluster in Azure. The current configuration includes the elements needed for automatic scaling of the cluster. However, the scaling criteria are pretty simplistically based on some CPU utilization criteria. While this may suffice for some basic scenarios, it may be worth considering using custom metrics for Horizontal Pod Autoscaling. It would be necessary to implement some custom metrics server, which would include Gadgetron specific metrics such as the current number of the Gadgetron reconstructions, etc. Another possible optimization would be to add some node discovery service to allow the Gadgetron to do more sophisticated load balancing. At the moment, jobs are simply distributed through the ClusterIP service (effectively doing round robin load balancing), which may suffice in many case but it could prove less than optimal.
Let me know if you have questions/comments/suggestions.
Comments
- Anonymous
July 22, 2018
Very informative, thanks for sharing!