【Azure】 使用 Azure Machine Learning Studio 體驗機器學習!
Azure 所提供的機器學習是架構在雲端之上的預測性服務,讓使用者可以不用購買昂貴的硬體以及自行建設基礎配置,同時也可以讓使用者快速地建立預測模型。
接下來的幾篇文章,是 MSP 們接受微軟傳教士 Ching Chen 的委託所翻譯的技術文章,透過這幾篇文章會使用 Microsoft Azure Machine Learning Studio,從如何存取資料開始,一路帶著大家建立並使用預測模型,最後則是展示如何使用 R 語言以及 Python 所撰寫的腳本。
想要了解更多,請看:
第二篇:【Azure】開發和使用 AzureML 模型
第三篇:【Azure】在 AML 上執行自定的 Scripts
1. 總覽
在本實驗中,我們將從之前實驗產生的各式來源,使用 Azure Machine Learning(AML)輸入模組讀取資料集。我們將探索連接不同資料源的方法,擷取資料,獲得基礎統計和資料視覺化技術。了解這些技術後,對於下一階段開發ML解決方案將更得心應手。
1.1 目標
本實驗針對不同資料 1.來源的存取、2.資料擷取和 3.擷取的資料中內含的統計資訊來說明操作方法。
1.2 需求
必須完成先前的實驗部分,擁有準備存取的資料集。
2. 建立 Azure Machine Learning 實驗
在本階段我們將建立第一個AML實驗並帶大家習慣 AML Studio 的操作環境。
- 進入 https://studio.azureml.net 入口
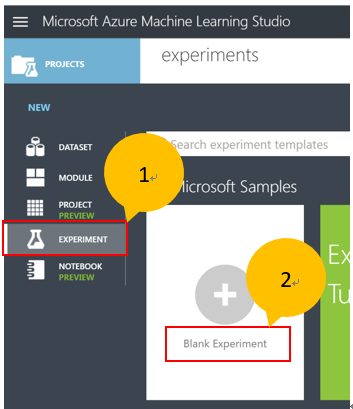
- 一旦成功登入後,點選“+ NEW”建立一個空白的實驗

- 點擊左方的EXPERIMENT 按鈕,然後選擇“Blank Experiment”
- 在新視窗的左方,你能看到用來開發 AML 實驗的模組。這些模組被分類在像是“Data Input and Output”或“Machine Learning”等標題的底下。由於模組數量太多,有時可能很難找到其中一個,在這種情況下,只要在左上方搜尋欄輸入少許模組名稱的關鍵字就能快速找到。開發一個實驗,需拖放模組到實驗畫布,互相連接,並設置每個模組的屬性(選擇模組並在視窗右方設置屬性),即能儲存並執行實驗。
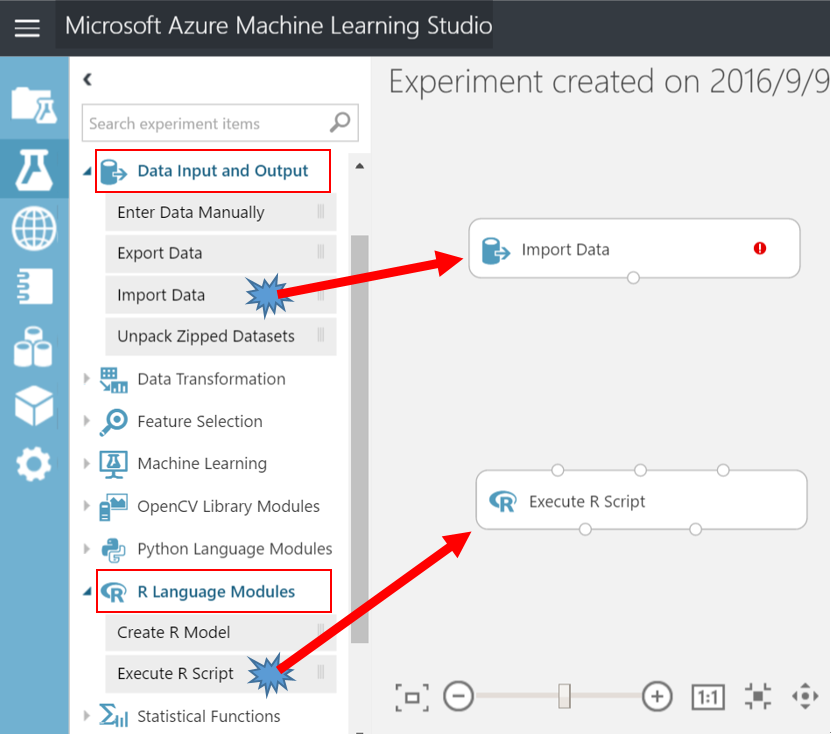
- 拖放兩個模組到畫布上。第一個模組為 Data Input and Output 類別中的“Import Data”,第二個模組為 R Language Modules 類別中的“Execute R Script”。
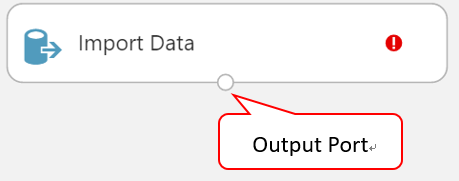
- 可以看到每個模組有至少一個輸入或輸出端或是兩個都有。輸出端在模組的下方,輸入端在模組的上方。也就是說, Import Data 只有一個輸出端。
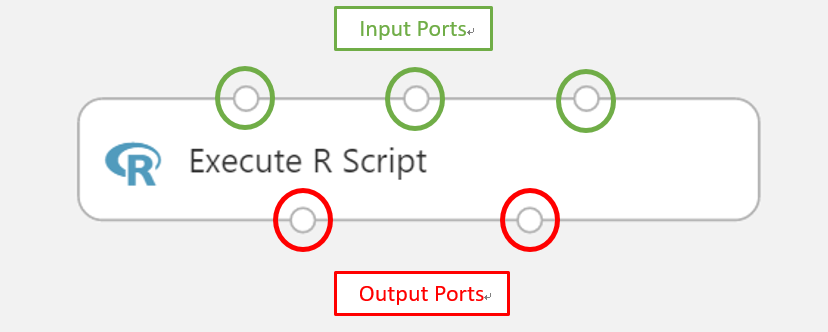
- “Execute R Script”模組有3輸入2輸出,各有特定的用途。
- 像是 Import Data 模組中的驚嘆號標示,在各個模組中能看到符號在右邊(紅色驚嘆號或綠色勾勾)。這意味著模組有問題或它是完好的。如果沒有標示,表示你還未執行,不會有模組狀態的線索。

- 點擊 Import Data 選取模組。其他模組也一樣,當被選取,模組的外框會顯示得較為顯眼,屬性視窗也會更新為被選取模組的資訊。
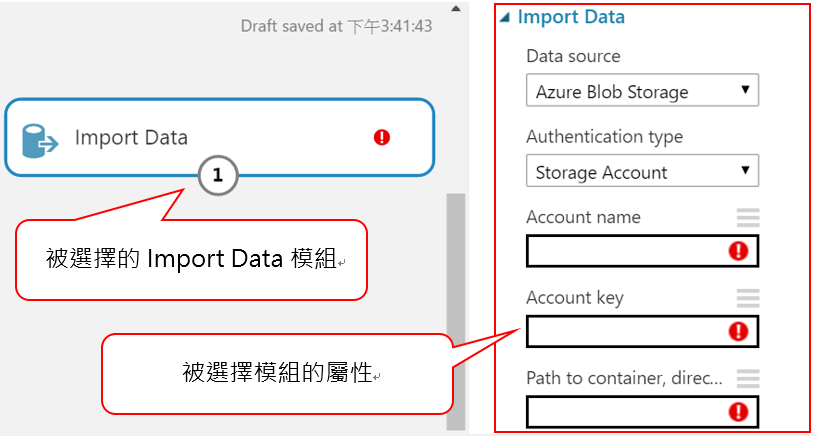
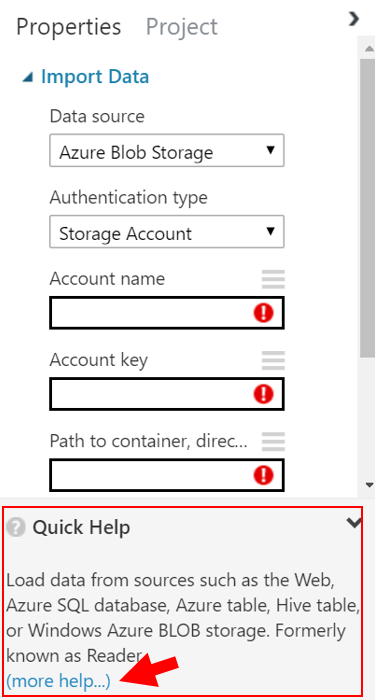
- 只要查看被選擇模組的屬性視窗中的 Quick Help 部分。點選“more help…”連結,會進入一個瀏覽器視窗,視窗中將顯示被選擇模組更詳盡的描述,即可獲得更快速且詳細的支援。
- 在 AML Studio 視窗底部也有進度通知。假如背景有工作在執行或有通知,會被顯示在這個區域。
3. 存取資料
在本實驗中,我們不靠任何函式開發簡易的 Azure ML 實驗,藉由不同來源輸入資料像是 Azure SQL Database, Azure Storage, Manual Input, URL Reader 等。接著我們將使用這些資料集開發來 ML。
3.1 存取資料,使用存在的資料集
- 點擊 DATASETS 並切換到 SAMPLES 。這裡你能找到預先安裝好可以讓你使用的樣本。這個步驟只是告知樣本資料集列表的位置。
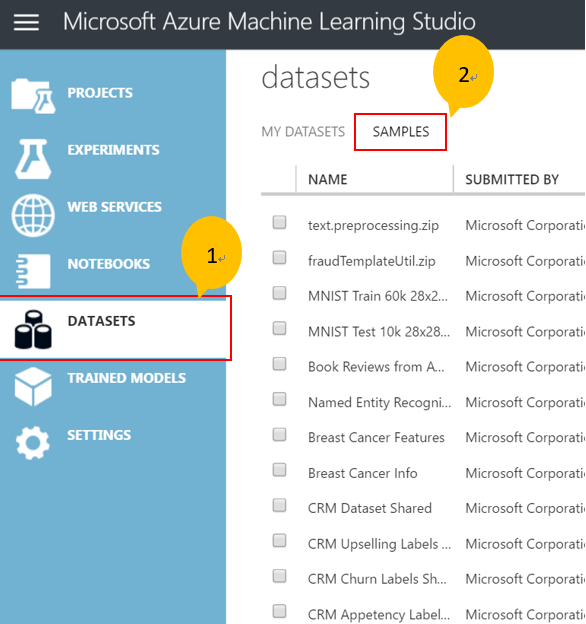
- 點選頁面左下角“+ NEW”,開始創建一個空白的實驗。

- 點擊左方的 EXPERIMENT ,然後選擇“Blank Experiment”。
- 在左邊視窗中,依序展開“Saved Datasets”和“Samples”。在“Samples”下,將會看到同步驟 1 預先安裝的資料集列表。
- 在 Samples 底下找到“Automobile price data (Raw)”資料集模組,拖拉到實驗畫布中。

- 點選模組能在右方視窗看到被選擇模組的屬性。以這個樣本模組而言,只有唯讀的屬性像是大小、格式和一個可下載連結(“view dataset”)。
- 除了屬性視窗外,可以藉由輸出端與模組互動。有些模組互動前需要實驗被執行。點擊模組的輸出端,會出現選單。選擇選單中的“Visualize” 指令。
- “Visualize”指令會進入一個新的視窗,內含資料審查,和一些被選擇行的統計/視覺化資料。

- 展開右方的統計和視覺化資訊。選擇資料審查區“make”這行,能找到該行最小、最大值,獨特的值等等。你也可以在視覺化區塊底下以長條統計圖分析資料的分布。
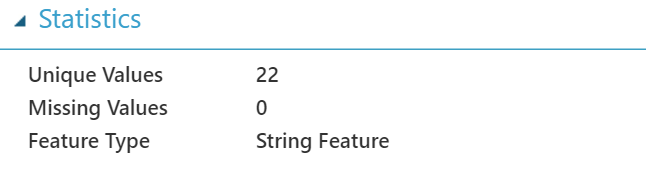
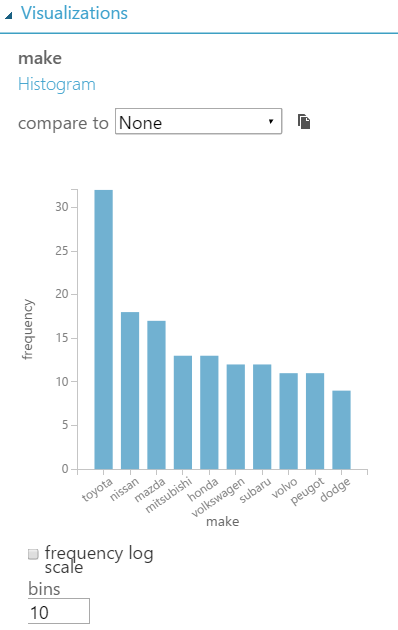
- 在以上例子中,因為被選擇的行由字母與數字組成,所以統計值是 NaN 。如果你選擇的行只有數字組成,就會即時的被更新。
從長條圖中,可以發現資料集中 Toyota 車比 Dodge 車數量還多或是“make” 的分佈不均等。(Toyota比其他多很多,Nissan比Volvo多一點)
3.2 上傳自己的資料集
在先前的範例中,我們使用預先安裝好的樣本資料集。本實驗中將輸入儲存在本機我們自己的資料集(在上回實驗中所提)。
- 要上傳儲存在本機的資料集,點擊 AML Studio 頁面左下角的 “+ NEW”。

- 點擊選單上的“Dataset”,然後選擇“From Local File”
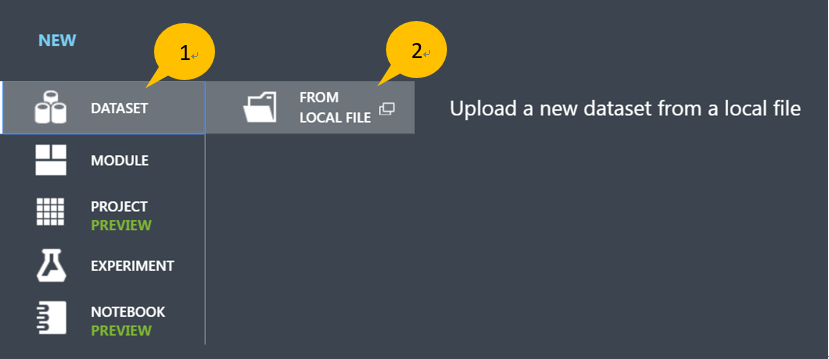
- 點擊“選擇檔案”後找到之前實驗產生的 linoise.csv 檔案。如果想更改默認的檔案名稱就輸入新的,選擇檔案形式(在本案例中是 CSV 檔,默認的選項),最後點擊右下角的打勾標示開始上傳檔案。
- 檔案上傳成功後,建立一個空白的 ML 實驗,然後依序展開 “Saved Datasets”和“My Datasets”。你會在“My Datasets”發現上傳的檔案,拖放到實驗畫布中。

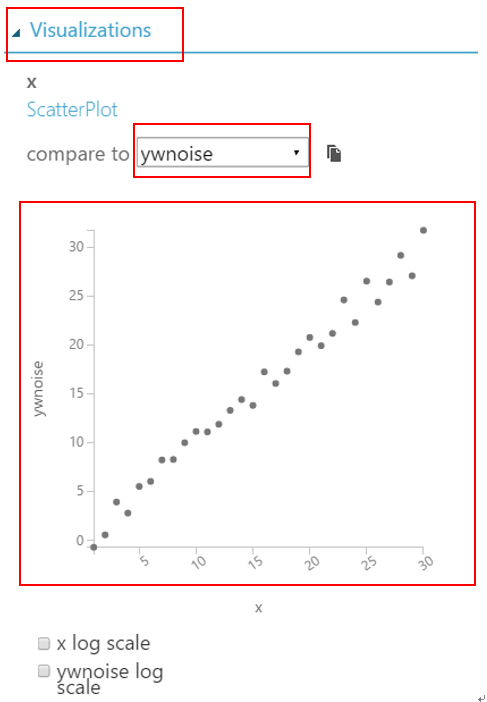
- 點擊“linoise.csv”資料集模組的輸出端然後選擇“Visualize”。按照順序,選擇資料集的“X”行,接著在視覺化區塊底下選擇“ywnoise”跟x行的值做比較。將會看到跟在 Excel, Python, R 實驗相同的圖。
如果你看下方的圖,可發現 x 行的統計表示最小值是 1 ,最大值是30 ,平均值、中位數是 15.5 ,特徵類型是“數值特徵”。一般人可能認為可以知道這些資訊是因為資料量少,如果資料集較大,會想藉由單一各點來得到全部的資訊。也許你會想知道是否一行當中的每一列都包含數值,或在百萬資料中是否某一列有資料遺失。
在視覺化區域之下,你將看到 x 跟 ywnoise 繪製成的圖。這張圖會帶給你的第一手消息,是“x” 跟 “ywnoise”這兩個特徵是強烈相依的,這將在之後的階段做更詳細的說明。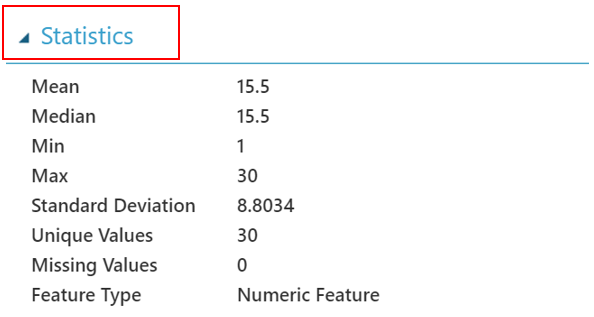
3.3 更新自己壓縮的資料集
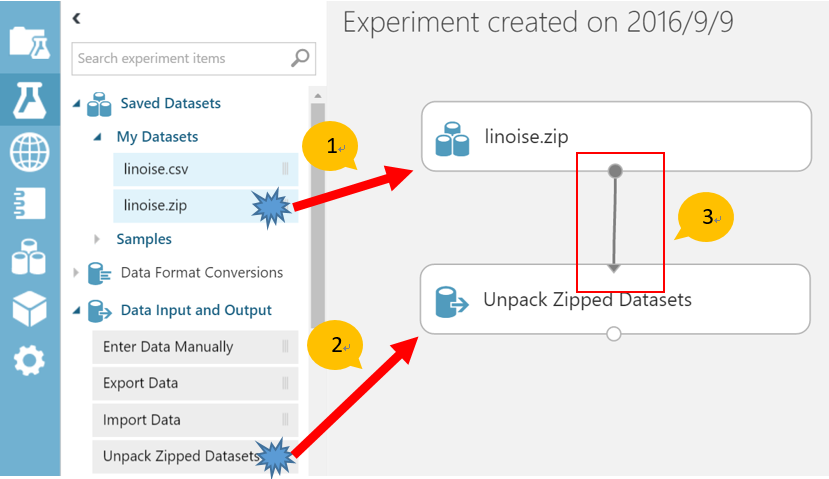
- 先前部份我們上傳 CSV 檔案到 Azure ML 工作環境。假設 CSV 檔案非常大,我們也可以利用壓縮工具將他壓縮成原本檔案大小的 1/10 。Azure ML 也可以處理壓縮的 ZIP 檔案。將“linoise.csv”壓縮成 “linoise.zip”,並將壓縮後的版本上傳到 Azure ML 工作環境。
- 首先將壓縮檔案模組“linoise.zip” 拖放到實驗畫布。接著在模組工具中拖放“Data Input and Output”下的“Unpack Zipped Datasets”模組。最後將他們互相連在一起。
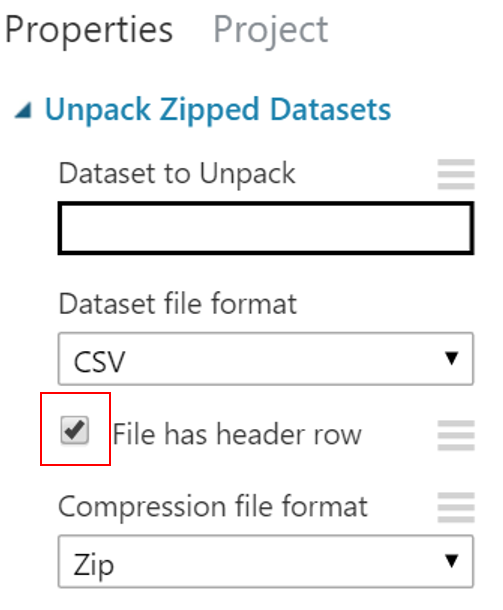
- 選擇“Unpack Zipped Datasets”模組。到屬性視窗做適當的設定,如下圖。
- “Run”實驗並點擊“Unpack Zipped Datasets”模組輸出端查看值。
3.4 手動輸入資料
當資料量很少的時候,你可能會希望直接「手動輸入」資料到 AML 環境。本階段將介紹這在 AML Studio 中的特色。
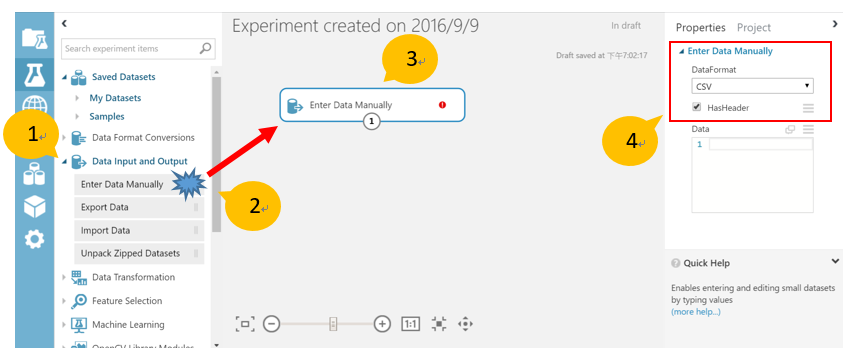
- 在 AML Studio 中建立空白的實驗。拖放模組工具箱中“Data Input and Output”下的 “Enter Data Manually”模組到實驗畫布。設定“Enter Data Manually”模組的屬性, DataFormat 是“CSV”,並將“HasHeader”選項打勾。
- 開啟之前樣本資料集的 excel 檔案,複製D, E, F行的 31 列,如下圖。
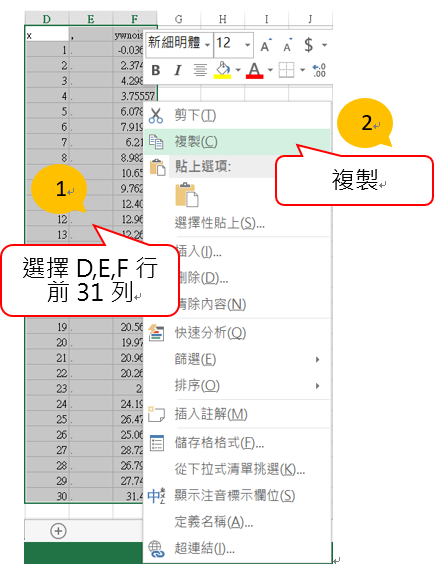
- 回到 AML Studio ,確認“Enter Data Manually”被選取。在屬性視窗中,“Data”文字格的空白處點右鍵,貼上剛從 excel 複製的資料。
(若無貼上選項,使用 ctrl + v 貼上)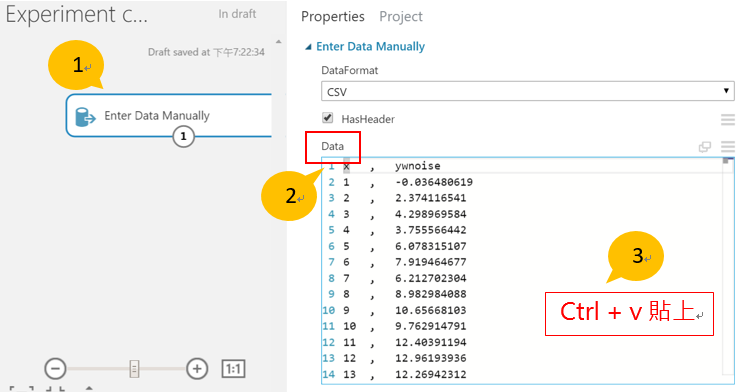
- 確認貼上資料中沒有空白的第 32 列。

- 點選“Enter Data Manually”模組的輸出端。在彈出的選單中將會看到“Visualize” 是無法點選的。我們之前提到,一些元件會在執行後才準備完成。

- 執行實驗。

- 經過幾秒後就能看到實驗名稱旁邊顯示“Finished Running”,在成功執行後也就會看到綠色勾勾出現在“Enter Data Manually” 模組右邊。最後當你再次點擊模組輸出端,將看到允許選取的 “Visualize”指令。
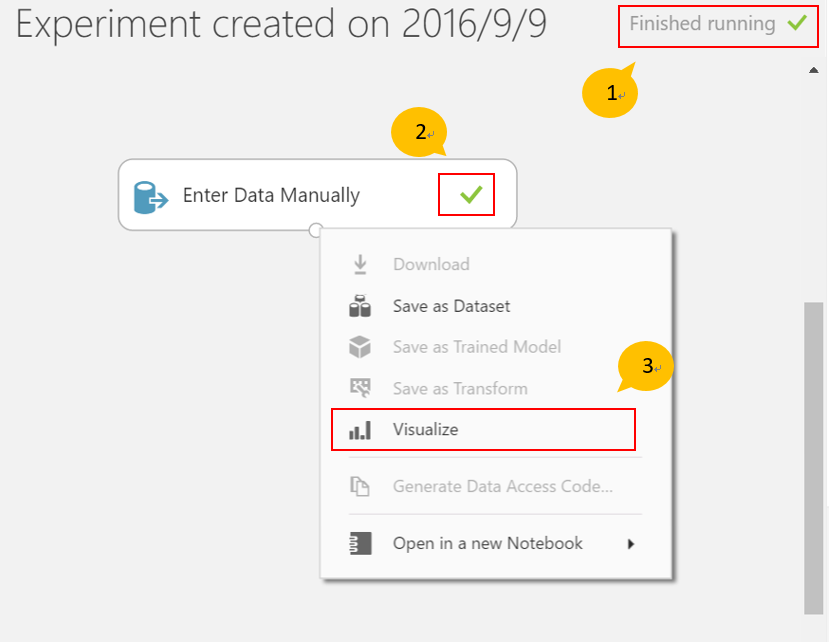
3.5 存取資料到 Azure Storage
在這個部分,我們將探究資料儲存到雲端 — Azure Storage service 的可能。
- 在 AML Studio 建立一個空白實驗。將模組工具中 “Data Input and Output” 下的”Import Data”模組拖放到實驗畫布中。
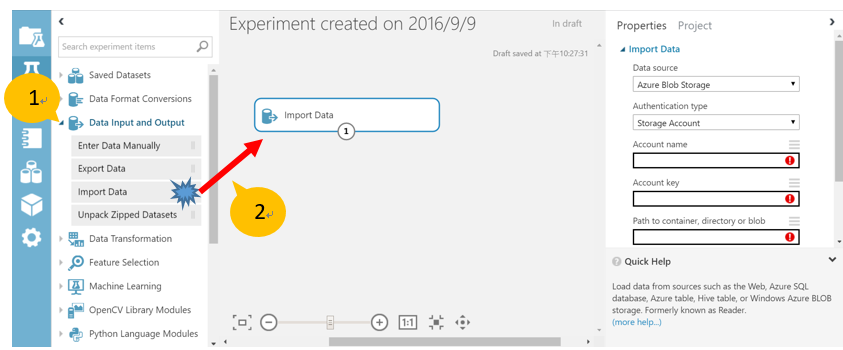
- 設置”Import Data”模組的屬性。 在“Data source”下拉式選單中選擇“Azure Blob Storage” ,即默認值。在 “Authentication type” 底下選擇 “Storage Account”因為在之前實驗中我們還未設置容器公開,所以我們必須提供存取金鑰。在 “Account Name”和“Account Key” 屬性下,輸入我們先前”Azure Storage”實驗中對應的值。
更重要的是,在“Path to container, directory or blob”底下的欄位,設置先前實驗container/blob 的名稱。這邊有大小寫之分所以要輸入正確。
因為我們的檔案有標頭(“x”跟”ywnoise”行),將“File has header row”打勾。然後因為我們不想要 Azure 實驗每次都從Azure blob storage service讀資料,所以勾選 “Use cached results”。
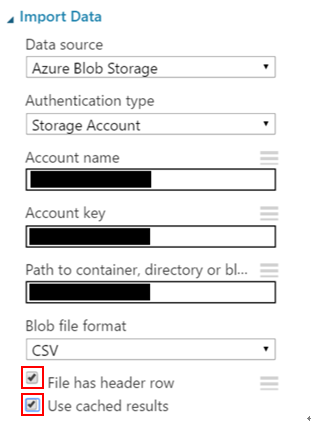
- 當你點擊”Import Data”模組的輸出端,會再次看到選單中 “Visualize” 無法選取。只要執行實驗後就能點選,資料集也將可使用。
3.6 在 Azure SQL Database 存取資料
在先前的實驗,我們使用 TSQL script 建立含值的欄位。現在我們將探討在 Azure SQL Database 存取資料的步驟。
- 如同先前部分,在 AML Studio 建立空白的實驗。將模組工具中 “Data Input and Output” 下的”Import Data”模組拖放到實驗畫布中。
- 設置”Import Data”模組的屬性。 在“Data source”下拉式選單中這次選取“Azure SQL Database”。再一次參照先前實驗中,使用Azure SQL Database 連結字串的值填入剩餘的屬性欄。輸入“Database server name”, “Database name”, “Server user account name” ,這些都在資料庫連結字串底下,可以在 Azure Management Portal 找到。只有密碼不能獲得,要記住並輸入到“Server user account password” 區塊。
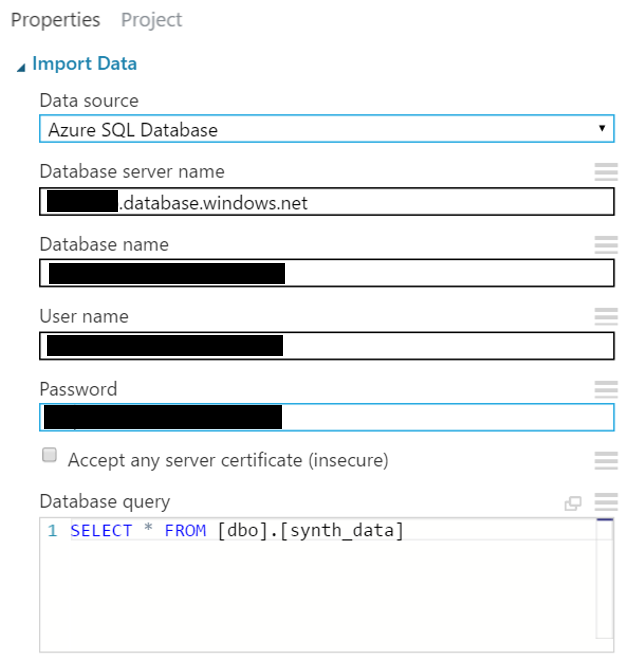
- 這裡的 “Server user account name”值必須和連結字串一樣,格式就像 username@servername 。最後在“Database Query”底下輸入適當的 TSQL Script 從資料庫取回需求的資料集。本實驗中,我們將輸入:
- SELECT * FROM [dbo].[synth_data]
- 如果你的資料沒有迅速變動,你可以選擇 “Use cached results”有更高的效能。
- 同樣的在執行實驗之前,你沒辦法從輸出端查看到資料集
原文:003-lab-data-interact
翻譯:
