Build & Deploy Machine Learning Apps on Big Data Platforms with Microsoft Linux Data Science Virtual Machine
This post is authored by Gopi Kumar, Principal Program Manager in the Data Group at Microsoft.
This post covers our latest additions to the Microsoft Linux Data Science Virtual Machine (DSVM), a custom VM image on Azure, purpose-built for data science, deep learning and analytics. Offered in both Microsoft Windows and Linux editions, DSVM includes a rich collection of tools, seen in the picture below, and makes you more productive when it comes to building and deploying advanced machine learning and analytics apps.
The central theme of our latest Linux DSVM release is to enable the development and testing of ML apps for deployment to distributed scalable platforms such as Spark, Hadoop and Microsoft R Server, for operating on data at a very large scale. In addition, with this release, DSVM also offers Julia Computing's JuliaPro on both Linux and Windows editions.
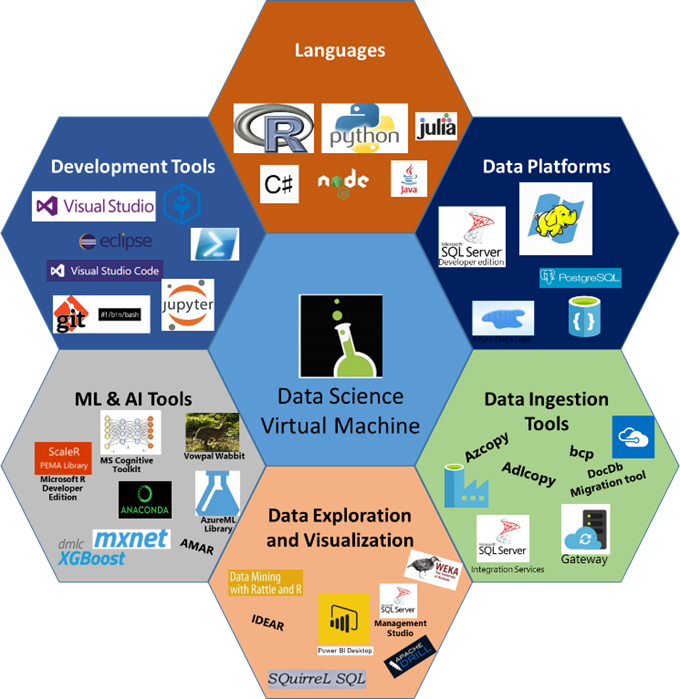
Here's more on the new DSVM components you can use to build and deploy intelligent apps to big data platforms:
Microsoft R Server 9.0
Version 9.0 of Microsoft R Server (MRS) is a major update to enterprise-scale R from Microsoft, supporting parallel and distributed computation. MRS 9.0 supports analytics execution in the Spark 2.0 context. There's a new architecture and simplified interface for deploying R models and functions as web services via a new library called mrsdeploy, whichmakes it easy to consume models from other apps using the open Swagger framework.
Local Spark Standalone Instance
Spark is one of the premier platforms for highly scalable big data analytics and machine learning. Spark 2.0 launched in mid-2016 and brings several improvements such as the revised machine learning library (MLLib), scaling and performance optimization, better ANSI SQL compliance and unified APIs. The Linux DSVM now offers a standalone Spark instance (based on the Apache Spark distribution), PySpark kernel in Jupyter to help you build and test applications on the DSVM and deploy them on large scale clusters like Azure HDInsight Spark or your own on-premises Spark cluster. You can develop your code using either Jupyter notebook or with the included community edition of the Pycharm IDE for Python or RStudio for R.
Single Node Local Hadoop (HDFS and YARN) Instance
To make it easier to develop Hadoop programs and/or use HDFS storage locally for development and testing, a single node Hadoop installation is built into the VM. Also, if you are developing on the Microsoft R Server for execution in Hadoop or Spark remote contexts, you can first test things locally on the Linux DSVM and then deploy the code to a remote scaled out Hadoop or Spark cluster or to Microsoft R Server. These DSVM additions are designed to help you iterate rapidly when developing and testing your apps, before they get deployed into large-scale production big data clusters.
The DSVM is also a great environment for self-learning and running training classes on big data technologies. We provide sample code and notebooks to help you get started quickly on the different data science tools and technologies offered.
DSVM Resources
New to DSVM? Here are resources to get you started:
Linux Edition
- Documentation: https://aka.ms/linuxdsvmdoc.
- Product Page: https://aka.ms/linuxdsvm.
- Documentation: https://aka.ms/dsvmdoc.
- Product Page: https://aka.ms/dsvm.
- Article/Tutorial – Ten things you can do on the DSVM: https://aka.ms/dsvmtenthings.
- Deep Learning Toolkit for DSVM, Product Page: https://aka.ms/dsvm/deeplearning.
The goal of DSVM is to make data scientists and developers highly productive in their work and provide a broad array of popular tools. We hope you find it useful to have these new big data tools pre-installed with the DSVM.
We always appreciate feedback, so please send in your comments below or share your thoughts with us at the DSVM community forum.
Gopi
Comments
- Anonymous
March 10, 2017
Thanks!! This seems really interesting. Will come handy for out company for sure. - Anonymous
March 15, 2017
The comment has been removed