Localization Testing – Part II
I should be of no surprise to anyone that localization testing generally focuses on changes in the user interface, although as mentioned in the previous post these are not the only changes necessary to adapt a product to a specific target market. But, the most common category of localization class bug are usability or behavioral type issues that do involve the user interface. Bugs in this category generally include un-localized or un-translated text, key mnemonics, clipped or truncated text labels and other user interface controls, incorrect tab order, and layout issues. Fortunately, the majority of problems in this category do not require a fix in the software’s functional or business layer. Also, the majority of problems in this category do not require any special linguistic skills in order to identify, and in some cases, an automated approach can be even more effective than the human eye (more on that later).
Perhaps the most commonly reported issue in this category is “un-localized” or un-translated textual string. Unfortunately, in many cases un-translated strings is also an over-reported problem that only serves to flood the the defect tracking database with unnecessary bugs. Translating textual strings is a demanding task, and made even more difficult when there are constant changes in the user interface or contextual meaning of messages early in the product life cycle. Over-reporting of un-translated text too early in the product cycle only serves to artificially inflate the bug count, and causes undue pressure and creates extra work for the localization team.
Identifying this type of bugs is actually pretty easy. Here’s a simple heuristic; if you are testing a non-English language version in a language you are not familiar with and you can clearly read the textual string in English it is probably not localized or translated into the target language. The illustration below provides a pretty good example of this general rule of thumb. A tester doesn’t have to read German to realize that the text in the label control under the first radio button is not German.

There are several causes of un-localized text strings to appear in dialogs and other areas of the user interface. For example:
- Worse case scenario is that the string is hard-coded into the source files
- Perhaps localizers did not have enough time to completely process all strings in a particular file
- Perhaps this is a new string in a file localizers thought was 100% localized
- Strings displayed in some dialogs come from files other than the file that generates the dialog, and the localization team has not process that file
- And, sometimes (usually not often), a string may simply be overlooked during the localization process
Testing for un-localized text is often a manually intensive process of enumerating menus, dialogs, and other user interface dialogs, message boxes and form, and form elements. But, if the textual strings are located in a separate resource file (as they should be), a quick scan of resource files might more quickly reveal un-translated textual strings. Of course, there is little context in the resource file, and I also hope the localization team is reviewing their own work as well prior to handing it over to test.
Also, here are a few suggestions that might help focus localization testing efforts early in the project milestone and reduce the number of ‘known’ or false-positive un-translated text bugs being reported:
- Ask the localization team to report the percentage of translation completion by file or module for each test build. Early in the development lifecycle only modules that are reported to be 100% complete which appear to have un-translated text should be reported as valid bugs. Of course, sometimes some strings are used in multiple modules, or may be coming from external resources. But, especially early in the development lifecycle reporting a gaggle of un-translated text bugs is simply “make work.” As the life cycle starts winding down…all strings are fair game for bug hunters!
- Testers should use tools such a Spy++ or Reflector to help identify the module or other resources, and the unique resource ID for the problematic string or resource. This is much better then than simply attaching an image of the offending dialog to a defect report. Identifying the module and the specific resource ID number allows the localization team to affect a quick fix instead of having to search for the dialog through repro steps and track down the problem.
- Also remember that not all textual strings are translated into a specific target language. Registered or trademarked product names are often not translated into different languages. In case of doubt, ask the localization team if a string that appears un-localized is a ‘true’ problem or not.
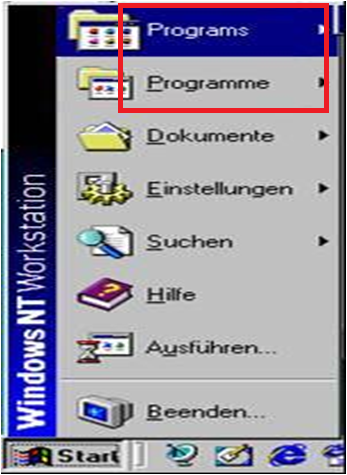
Unlocalized strings usually due to hard coded strings also tend to occur in menu items. This is especially true in the Windows Start menu or sub-menu items hard-coded in the INF or other installation/setup files. For example, the image on the right shows a common problem on European versions of Windows. Many European language versions localize the name of the Program Files folder, and the menu item in the start menu. But, often times when we install an English language version of software to Windows it creates a new "Programs" menu item (and even a new Program Files directory, rather than detecting the default folder to install to. In the example on the left, the string Accessories is a hard-coded folder name. But, there is another issue as well. This illustrates not only a problem with the non-translated string "Accesssories," but also shows one full-width Katakana string for 'Accessories' and another half-width string.

In part 3 I will discuss another often problematic area in localization….key mnemonics.