Model Collation vs. Database Collation
When you are using the latest CTP of the GDR release, you might have noticed that we introduced a new collation, named the "model collation". However if you go to the Database.sqlsettings file, which contains all the database properties, you will also find the "Database collation" like we had this in the previous releases. What is the difference and why should you care?
Model Collation
Model collation if a provider agnostic project setting, this means that every provider that will be installed, will expose this information. As you might know, as part of the GDR release we changed the underlying architecture to be truly model based. All schema objects are represented as model elements, relationships and annotations stored inside what we call the model store. When you compare two model elements or two complete models, there are strings involved. As soon as there are strings involved this brings up the question, how to compare those strings? Case-sensitive or case-insensitive? Which locale to use? This is what the "model collation" reflects. If you select "English (United States) (1003) - CS" all strings are compared using a case sensitive, according to the 1033 (US English) locale.
You can set / change this information by going to the project properties, on the Project Setting tab you will find a drop down listbox with all the possible model collations.
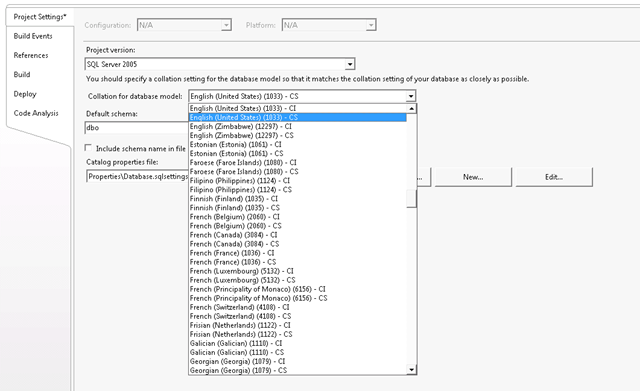
NOTE: When you change the model collation, we have to re-interpret and re-resolve the schema model, which can be a time consuming operation. Therefore you will explicitly asked you to OK the change.
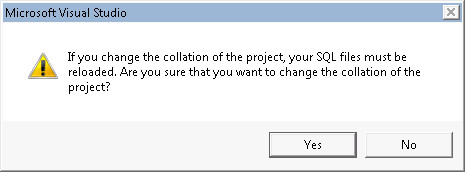
Database Collation
The database collation, is a SQL Server specific setting. Therefore it is no longer stored inside the project file, but inside the Database.sqlsettings file. The settings inside this file are provide specific, in this case SQL Server specific. The database collation property reflects the SQL Server database collation that you expect/want for this specific database project. Changing it will only change the deployment output, or when you compare the project with a target database inside Schema Compare.

Why have two?
The main reason is that this is the result of the architectural changes underneath the product. The introduction of the schema model and the database schema providers required the separation of infrastructure and provider specific settings. The model store and how we compare model elements is functionality that is equivalent between providers. A SQL Server database collation is a specific SQL Server artifact.
There are advantages of separating the two collations as well. The main one being that you can now setup you project to compare all elements in a case-sensitive fashion while your target database is case-insensitive, which is the default in the SQL Server installer. The will result in a schema and code that has higher level of consistency when it comes to naming of objects, while you do not have to change the SQL Server collation settings. In the previous releases this was not possible, without changing the project collation to case-sensitive during development and to case-insensitive at deployment time.
I hope this makes the difference and the use case more clear.
-GertD
Comments
Anonymous
October 04, 2008
PingBack from http://blog.a-foton.ru/index.php/2008/10/05/model-collation-vs-database-collation/Anonymous
October 09, 2008
The Developer Support Team Foundation Server Blog on Setting up TFS 2008 for HTTPS/SSL Charles Sterling...Anonymous
February 07, 2009
[ Nacsa Sándor , 2009. február 8.] Ez a Team System változat az adatbázis változások kezeléséhez és teszteléséhez