7 Motivos para não usar o Entity Framework
Vamos falar sobre 7 motivos para não usar o Entity Framework (EF) e 1 ótimo motivo para usá-lo imediatamente!
Nos artigos anteriores, fui levantando alguns problemas que encontramos ao longo do nosso projeto ARDA.
- Entity Framework: Code-First, Database-Never
- Entity Framework: Broken LINQ
- Entity Framework: A vida do DBA
Antes de comentar sobre o bom motivo para usar o Entity Framework, deixo começar falando sobre os 7 motivos negativos.
1. Nomenclatura
Os nomes de tabelas e colunas são importantes em um banco de dados relacional. Entretanto, nosso modelo ficou terrível com os nomes WorkloadBacklogTechnologies, WBUTechnologyID e TechnologyTechnologyId, que não explicam o significado da entidade e seus atributos.
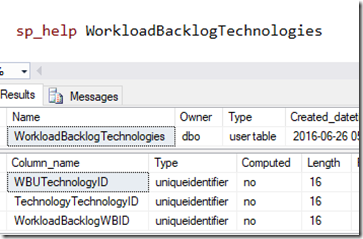
Esse é o exemplo mais absurdo que temos no ARDA. “Por que fomos usar o EF???”
Eu sei, eu sei.. o framework não tem culpa se o desenvolvedor fez errado. Em nossa própria defesa como responsável pela bagunça, o problema do nome aconteceu por uma série de fatores (ex: mudança de comportamento do EF Core RC1, falta de conhecimento sobre os relationships e shadow properties, falta de revisão do modelo de dados).
Depois dá uma lida nesses links de Shadow Properties e Relationships e veja se é tão óbvio assim a questão de nome. Infelizmente, não foi uma preocupação nossa durante o estágio inicial de desenvolvimento.
2. Tipos de dado genéricos
Por padrão, Entity Framework Core adota NVARCHAR(max) para armazenar strings e DATETIME2, para datas.
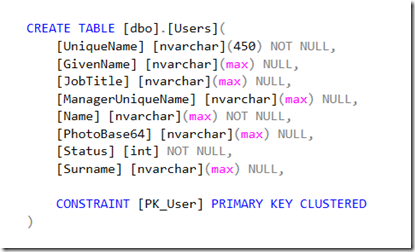
O correto é especificar a precisão numérica ou o tamanho máximo do campo. Essa é uma mudança relativamente simples de se fazer no banco de dados, ajustando o modelo correspondente.
A questão do tipo de dado também abrange a escolha de NVARCHAR x VARCHAR x CHAR ou UNIQUEIDENTIFIER x INTEGER. Por exemplo, campos GUID podem soar natural para o desenvolvedor, mas não é uma recomendação no desenho do banco de dados.

Provavelmente precisamos de um retrabalho para adequar o modelo de dados. Note que normalmente esses pontos são preocupações constantes do DBA, mas que frequentemente são ignoradas durante a tarefa de desenvolvimento.
[UPDATE 12/JUL] Estava vendo o vídeo do Baltieri e ele comentou sobre o GUID. Com certeza esse é um campo importante para os desenvolvedores. Então o que seria melhor: ter um campo ID ou GUID? Resposta: não existe nada de errado em criar uma tabela com ambos os campos ID e GUID representando dois identificadores. Assim como podemos ter uma tabela com campos de PessoaID e PessoaCPF. Enfim, uma tabela pode ter vários identificadores e eles não precisam ser expostos para a aplicação. O objetivo de ter um campo INT IDENTITY é facilitar a escolha de uma chave clusterizada. Logo, ID = clustered index, Guid = non-clustered index, e o problema está resolvido.
3. Campos nullable
Em campos string que não fazem parte de chave primária, o Entity Framework adota “nullable” por padrão.
O ideal é especificar o campo como NOT NULL. Infelizmente, ouço algumas pessoas argumentando que o tipo NULLable é melhor porque ocupa menos espaço e blablabla… isso é um grande erro de conceito.
NULL or NOT NULL: Qual a diferença?
https://blogs.msdn.microsoft.com/fcatae/2010/10/26/null-or-not-null-qual-a-diferena/
Se você acha que tanto faz escolher NULL ou NOT NULL, então veja esse trecho de código e identifique o erro:

Encontrou o trecho que está completamente errado no ANSI SQL?
…
Entenda que o NULL possui uma semântica diferente no banco de dados, pois ele não é exatamente um valor. Portanto, você não deve usar um operador de igualdade.
Se você entendeu o problema anterior, então fica mais fácil dizer porque, no próximo exemplo, o campo JobTitle deveria ser NOT NULL.

Conclusão: sempre prefira os campos definidos como NOT NULL.
4. Falta de constraints
Temos um campo chamado WBComplexity, que possui valores válidos de 0 a 5. A modelagem em Code-First normalmente ignora as restrições dos valores do lado do banco de dados. Como que eu faço a validação por constraint? Ou triggers?

Não sei como implementar isso através do Code-First. Muitos desenvolvedores vão ignorar a definição de constraint, pois não acham tão importante. Discordo dessa abordagem, pois o domínio de valores faz parte do schema de dados.
No nosso caso, provavelmente seguiria o caminho do Database-First para contornar esse problema.
5. Ausência de definição do modelo física
Sempre devemos fazer a modelagem física do banco de dados. Pela documentação, não é possível definir índices através de Data Annotations – forçando o desenvolvedor a usar a Fluent API.
Desculpe o trocadinho, mas eu não tenho nada de fluente na Fluent API do Entity Framework Core. Não que seja difícil, mas é improvável que o desenvolvedor esteja escrevendo uma query LINQ e, de repente, mude para o modelo de dados para definir os índices. Quando escrevo código LINQ, gosto de olhar a tela do Visual Studio com código C# e breakpoints. Não dá tempo de ficar vendo a query e o plano de execução.
Entretanto, quando estou como responsável do banco de dados, minha primeira pergunta é saber quem foi que fez um SCAN de tabela. Nem sei qual código, aplicação ou LINQ.
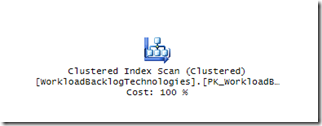
A única solução que enxergo é adotar o caminho do Database-First, analisando os planos de execução contra os índices das tabelas. Ao meu ver, isso tem tudo a ver com o próximo ponto.
A definição do modelo físico determina a ordenação da tabela, agrupamento de registro e índices presentes.
6. Transformação de LINQ em SQL
Comandos simples LINQ podem se transformar em consultas SQL complexas. Ao longo do nosso projeto, usamos o Entity Framework Core e encontramos uma série de surpresas ao longo do caminho.
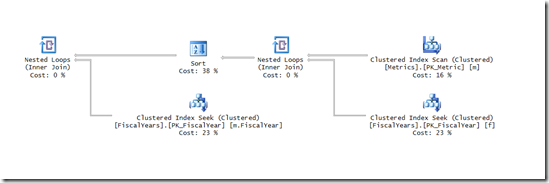
Se o mundo fosse feito apenas de consultas CRUD, então não haveria problemas. O fato é que as consultas SQL geradas pelo EF podem ter conversões implícitas. Abordei um pouco desse assunto em um artigo anterior:
Entity Framework: Broken LINQ
https://blogs.msdn.microsoft.com/fcatae/2017/07/11/entity-framework-broken-linq/
Minha recomendação é revisar as consultas individualmente e validar que os planos de execução são adequados. Veja isso em conjunto com o item dos índices e certamente não haverá problemas de desempenho.
7. Falta de suporte a Views e Stored Procedures
No momento, ainda não há suporte nativo para Views ou Stored Procedures no Entity Framework Core (EF Core). Isso faz uma falta tremenda.

As Views permitem versionar tabelas com facilidade, enquanto que as stored procedures são eficientes e possuem bom desempenho. Mas, por favor, isso não significa trazer regras de negócio para dentro do banco de dados. O objetivo é apenas encapsular os comandos de acesso a dados.
Entenda esse ponto como uma facilidade para implementar a análise de plano de execução dos itens anteriores.
Um ótimo motivo para usar Entity Framework
Se você é um desenvolvedor que quer usar Entity Framework (EF) e chegou até esse ponto sem desistir, então parabéns! É lógico que existem motivos válidos para adotar o EF na solução.
Sempre fique atento a cuidados importantes do banco de dados:
- Nomenclatura está correta?
- Tipo de dado e tamanho são adequados?
- Colunas são (preferencialmente) NOT NULL?
- Campos possuem domínio de valores?
- Adicionou os índices adequados para as consultas?
- Revisou o plano de execução das queries? Alguma coisa estranha?
- Considerou encapsular a lógica em Stored Procedures?
Se você seguiu os 7 passos, então o banco de dados está modelado.

Tenho certeza que nenhum DBA vai se preocupar com EF desde que o banco de dados esteja modelado e as consultas revisadas. Na verdade, não faz diferença se a aplicação usa EF, Dapper, ADO.NET, ODBC, JDBC, DAO, etc. O foco do DBA é garantir desempenho, não escolher frameworks ou bibliotecas.
Portanto, se você gosta do EF, agora é hora de usá-lo!
Conclusão
Nesse artigo, fiz minha conclusão com os 7 motivos que fazem uma boa modelagem de dados.
Se a modelagem do banco de dados estiver correta e as queries rodarem com os índices certos, não haverá motivo para reclamação sobre qual o framework usado. Pessoalmente gosto de usar EF com a abordagem de Database-First, que me dá uma boa segurança sobre a modelagem dos dados ao mesmo tempo que consigo ser produtivo na geração de código.
Quando é necessário um pouco mais de controle e desempenho, tenho usado o Dapper ou SqlClient por conta das stored procedures. Nada impede (tirando a bagunça) de você misturar diferentes abordagens dentro do mesmo código.
Artigos Futuros
Vou dar uma pausa nesse assunto do Entity Framework para falar um pouco sobre outras mancadas (das grandes) que fizemos no nosso projeto do ARDA. Depois retorno para falar do EF Data-First, Dapper e NoSQL.
Deixem seus comentários, críticas e sugestões!