Machine Learning para principiantes – Capítulo 2: creando el proyecto e importando datos
Lo primero que necesitamos para nuestro experimento son los datos que usaremos para entrenar/evaluar nuestro modelo, y los que usaremos para generar predicciones futuras con nuestro modelo entrenado. Usando la herramienta Azure ML Studio podemos importar nuestros datos de múltiples maneras (directamente desde las bases de datos SQL, DocumentDB, Azure Storage...y otras opciones de almacenamiento, usando el módulo "Import Data" de la herramienta), pero vamos a hacerlo más fácil subiendo tres archivos csv a nuestra cuenta de Azure ML:
- leagues_NBA_totals_master: archivo que contiene las estadísticas totales (puntos, asistencias, rebotes, robos, partidos jugados, minutos jugados, etc.) para cada jugador de la NBA desde 1981 hasta 2016, que será utilizado para entrenar y evaluar nuestro modelo
- leagues_NBA_advanced_master: archivo que contiene las estadísticas avanzadas (PER, porcentaje de tiros reales, porcentaje de victorias ofensivas, cuota de victorias defensivas, porcentaje de victorias totales, etc.) para cada jugador de la NBA desde 1981 hasta 2016, que será utilizado para entrenar y evaluar nuestro modelo
- nba_2017_players_input: archivo que contiene la información para cada jugador que jugó en la temporada de la NBA 2016-2017 (rookies incluidos), que se utilizará para crear las predicciones
Ten en cuenta que cada archivo CSV comparte 5 campos comunes (Player, Pos, Age, Tm y Season), que serán las características que usaremos para nuestro experimento.
Una vez descargados, vamos a cargar nuestros tres archivos en el espacio de trabajo de Azure ML:
1. Comenzamos cambiando la vista a la pestaña "Datasets" y haciendo clic en el botón "New" en la esquina inferior izquierda:

2. En el blade de "New", haz click en "From local file" y selecciona el archivo que deseas subir (repite este paso para cada archivo):
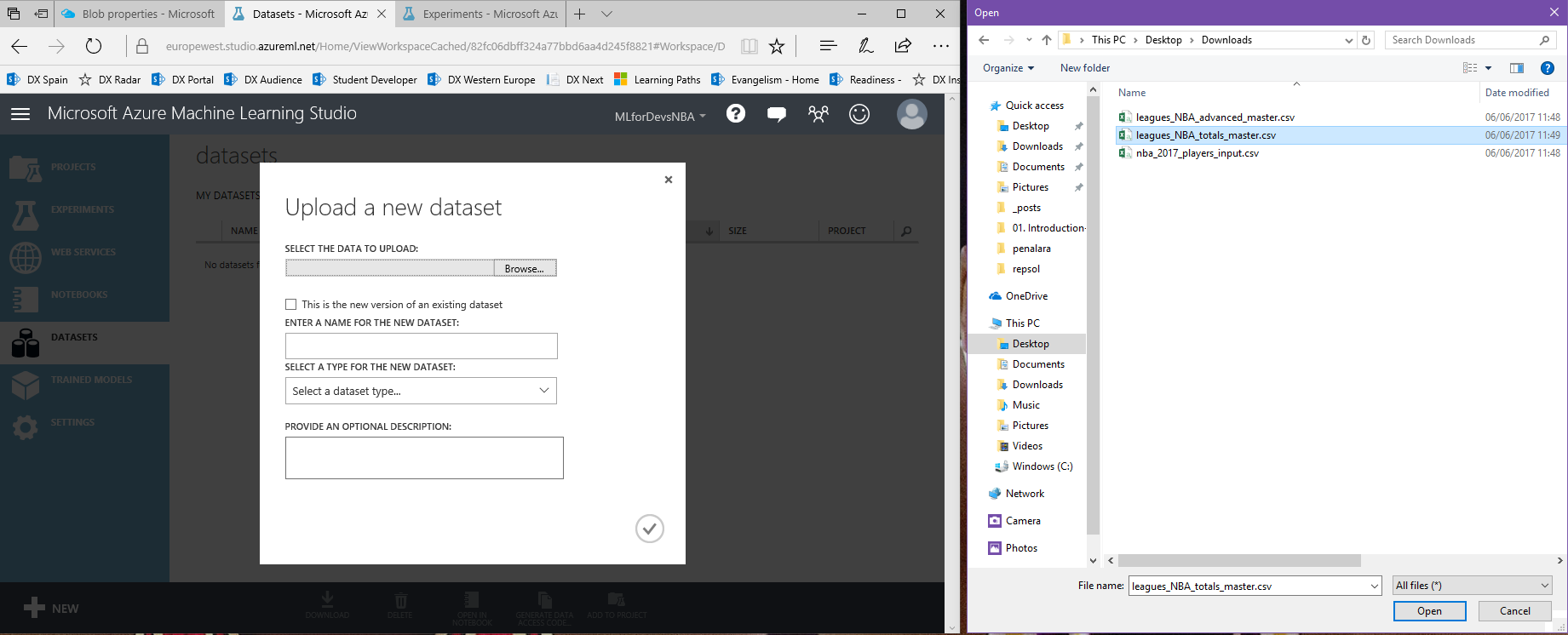
3. Una vez cargado, podemos encontrar nuestros tres archivos en la lista de "Datasets":
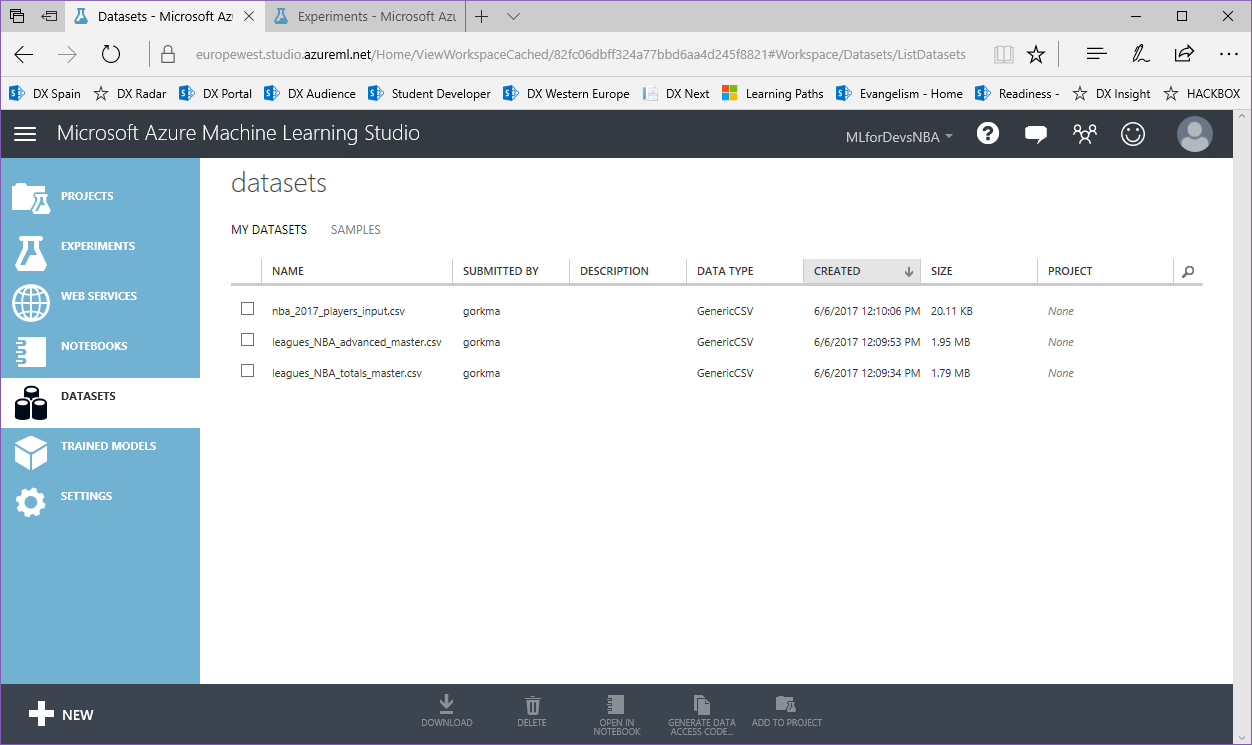
Como puedes ver, hay una columna llamada "Project" que está vacía. Los proyectos nos permiten organizar nuestros conjuntos de datos, experimentos y otros componentes agrupándolos en el mismo lugar. Vamos a crear un nuevo proyecto para añadir nuestros conjuntos de datos subidos recientemente y los experimentos que estamos a punto de crear.
1. Selecciona los 3 archivos csv y haz click en el botón "Add to project" en la barra inferior:
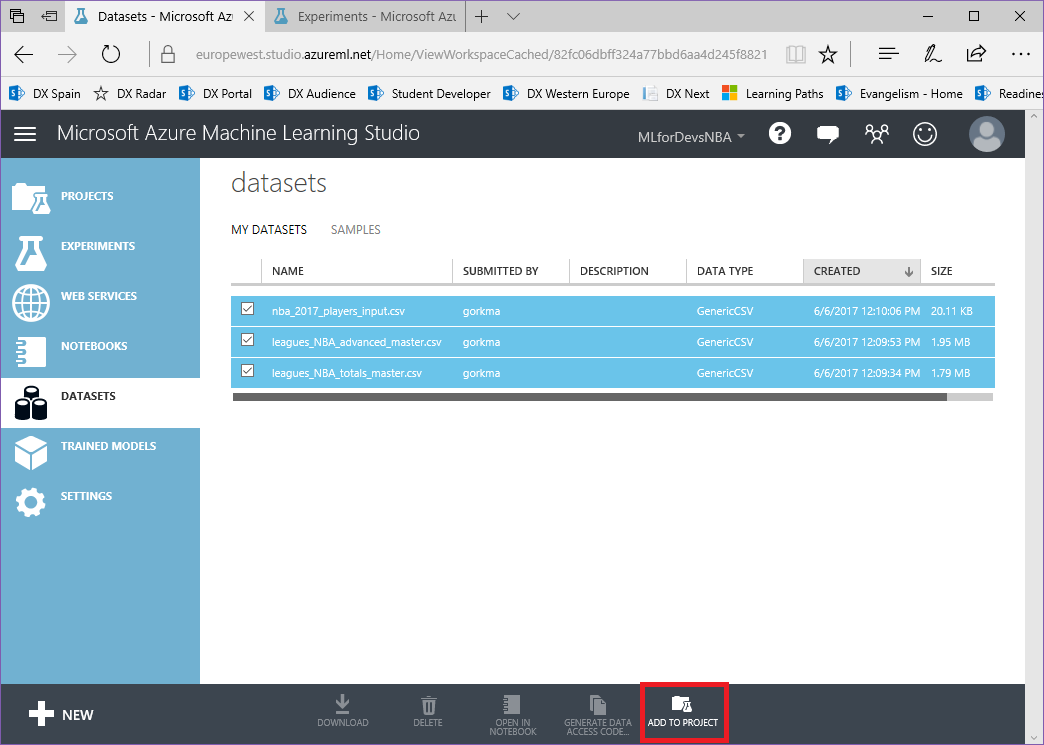
2. Haz click en "New project" e introduce el nombre deseado para tu proyecto:
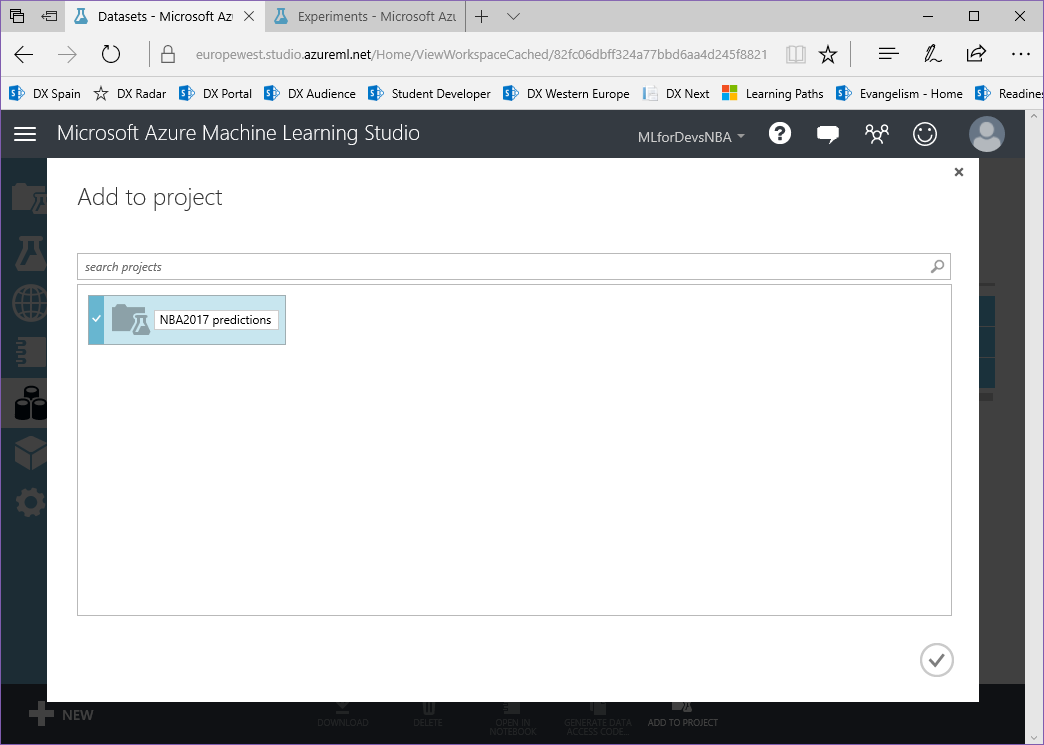
3. Puedes comprobar que el proyecto con nuestros 3 conjuntos de datos se ha creado cambiando a la vista "Projects":

Ahora, vamos a crear nuestro primer experimento, en el que definiremos el flujo para limpiar y preparar nuestros datos, y donde también vamos a entrenar a nuestro modelo para generar las predicciones para la temporada 2016-2017:
1. Cambia a la vista "Experiments" y haz click en el botón "New" en la esquina inferior izquierda:
2. En el blade de "New", selecciona "Blank experiment" para continuar:

3. Una vez creado, cambie el nombre del experimento a uno menos genérico:
Como no podemos guardar un experimento sin módulos, comencemos agregando nuestros conjuntos de datos de training y uniéndolos utilizando los campos que tienen en común:
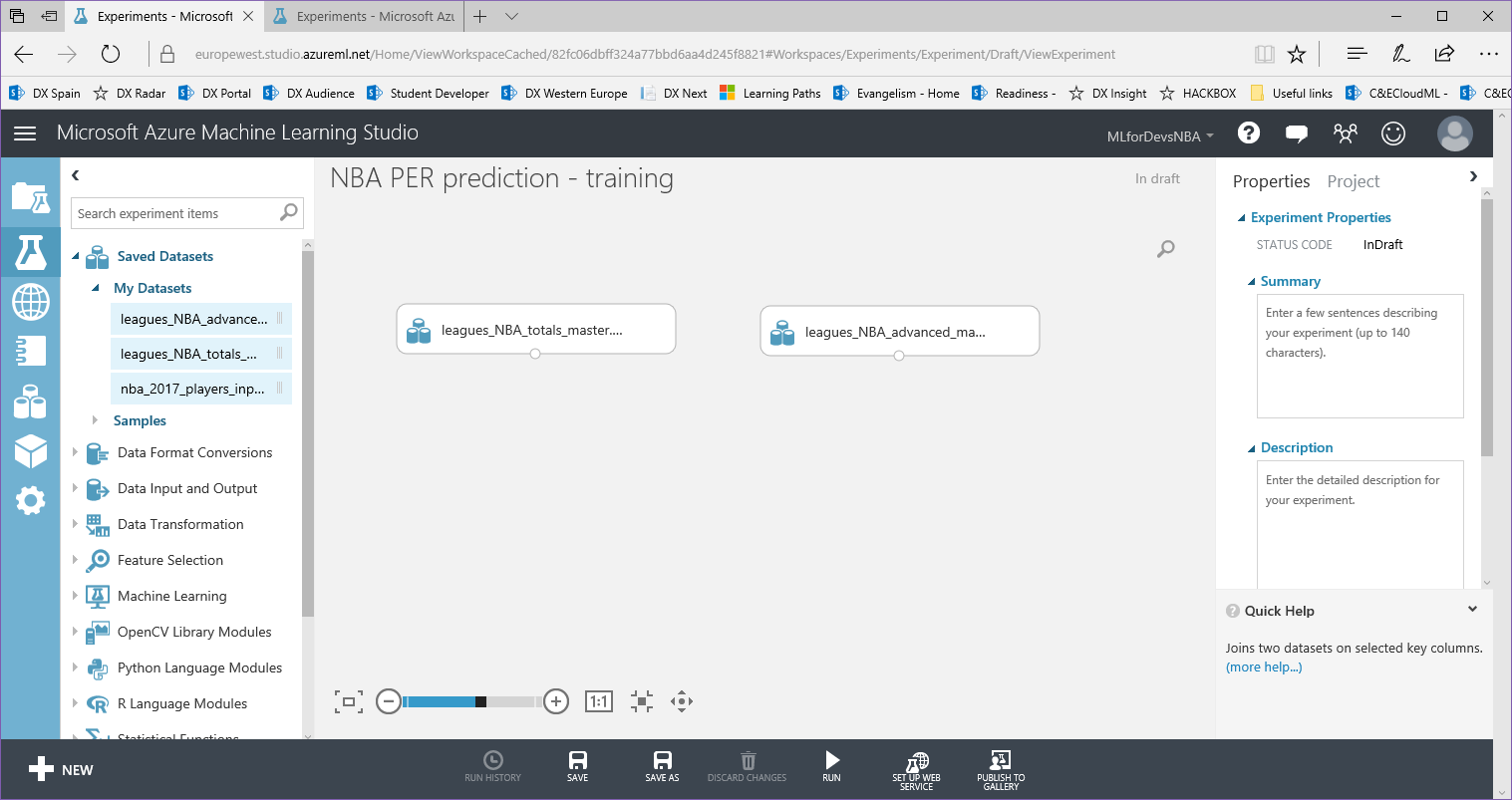
1. En la columna izquierda, tenemos la lista de los diferentes módulos que podemos utilizar en nuestros experimentos. Agrega los datasets de "totals" y "advanced" navegando por "Saved datasets > My datasets", arrastrando y soltando ambos archivos:
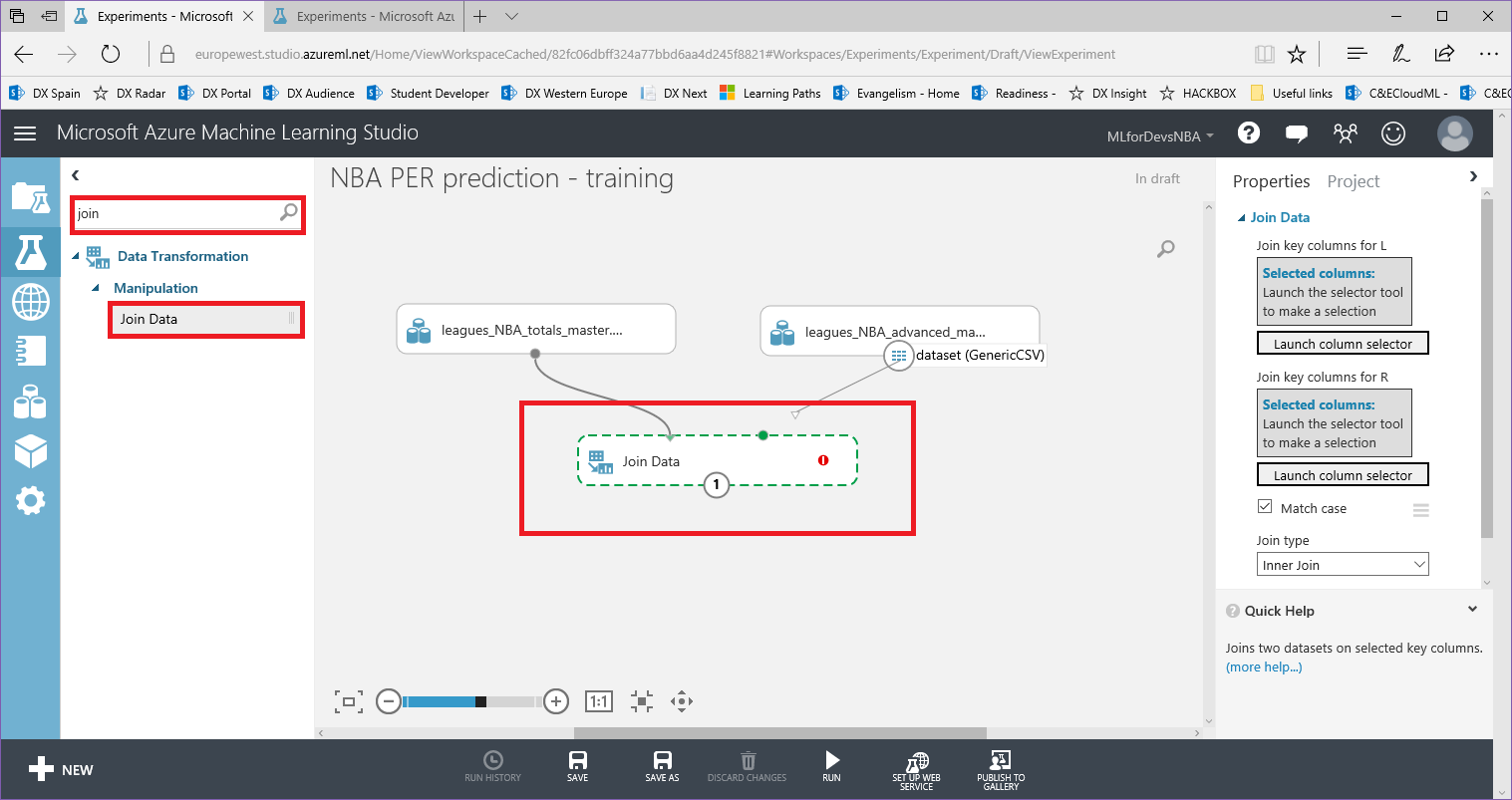
2. En la misma columna de la izquierda, busca el módulo "Join Data" y arrástralo al canvas. Una vez que lo hayas hecho, conecta los dos conjuntos de datos con el módulo "Join Data", arrastrando desde el punto inferior del conjunto de datos a la parte superior del módulo "Join Data":
3. Con el módulo "Join Data" seleccionado, vamos a elegir las columnas comunes para unir los dos conjuntos de datos. Haz click en el selector de columnas para el primer conjunto de datos, selecciona las columnas comunes (Player, Post, Age, Tm, Season), haz click en la flecha derecha que hay entre ambas listas, y haz click en el botón ok en la parte inferior-derecha para confirmar, repitiendo el proceso para el segundo conjunto de datos:
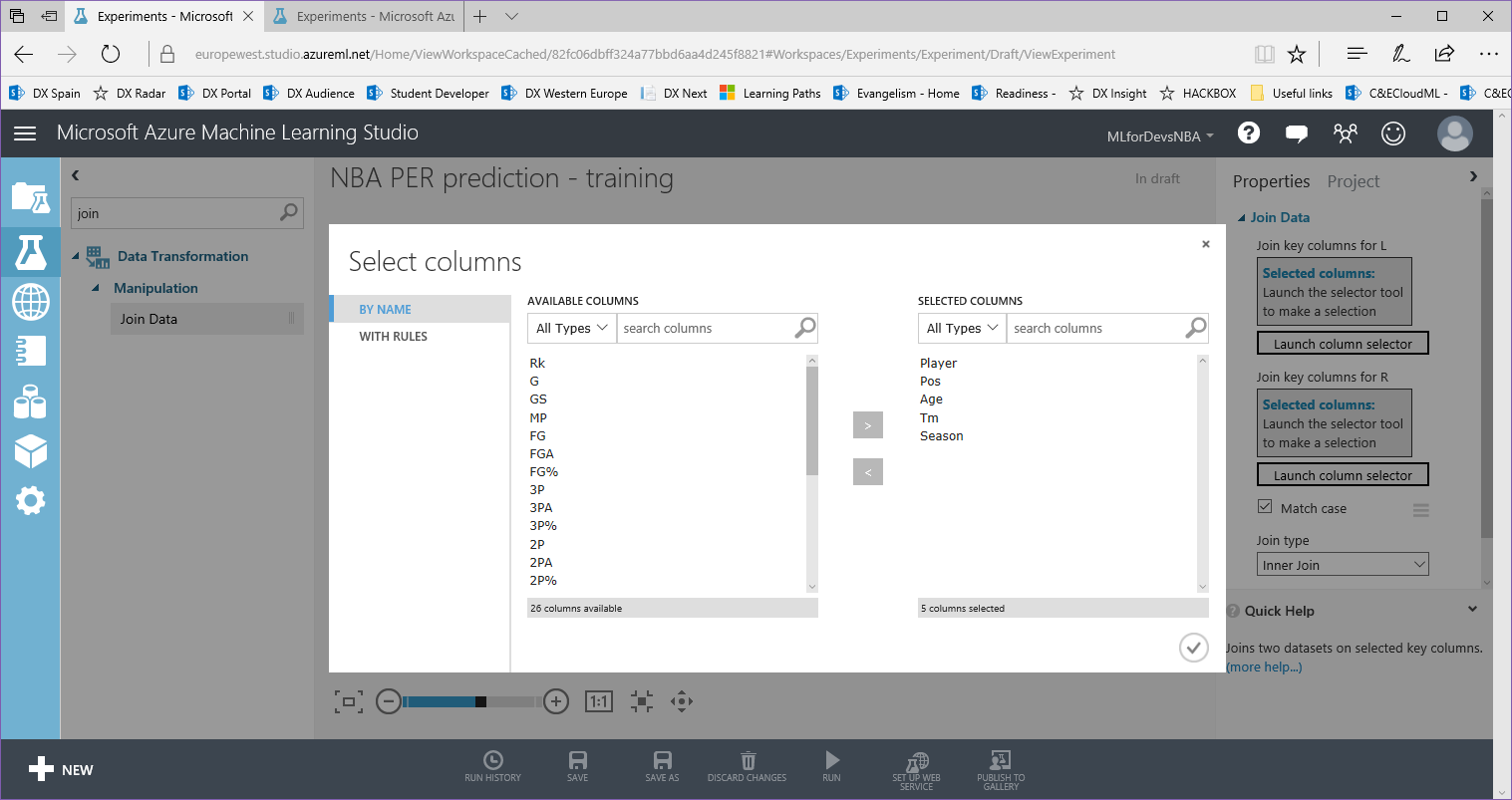
4. Para completar este paso, selecciona el tipo "Inner Join" en la lista desplegable y desmarca "Keep right key columns in combined table" para evitar columnas duplicadas en nuestro dataset unido:
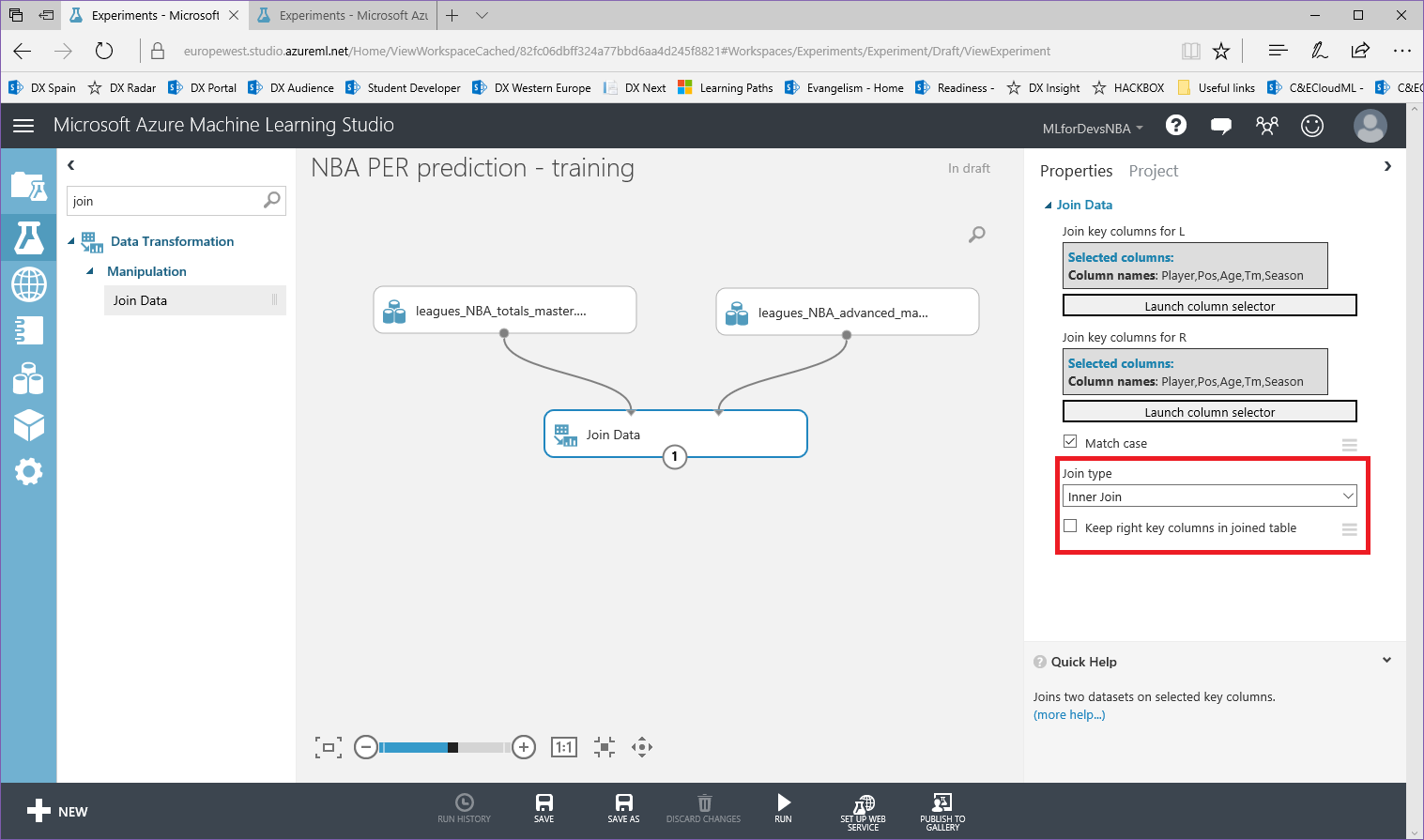
5. Puedes ejecutar el experimento (cuando se complete, aparecerá un signo de verificación verde en el módulo "Join Data") y echar un vistazo al conjunto de datos resultante haciendo click con el botón derecho en el punto inferior de "Join Data", y después "Visualize":
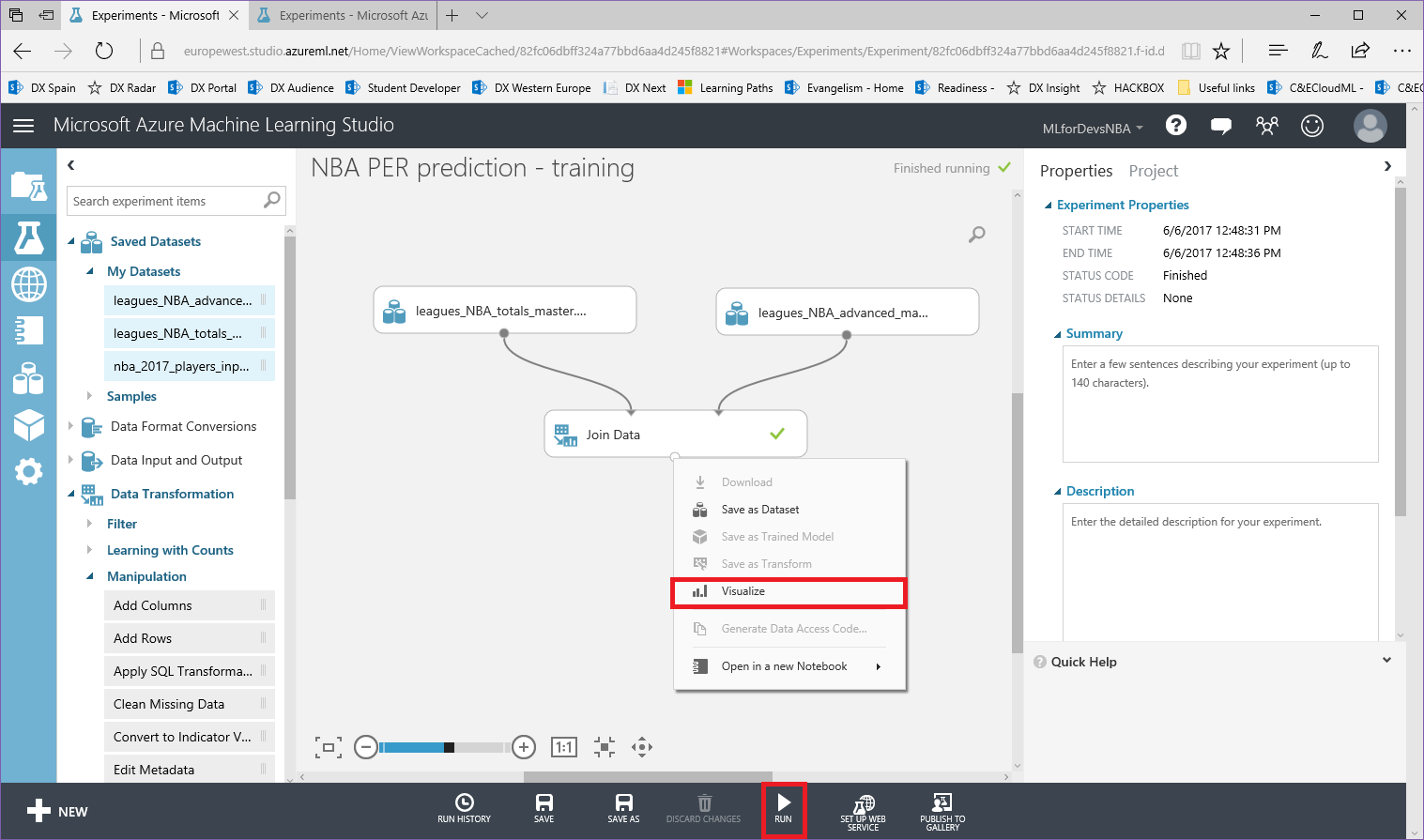

Finalmente, vamos a agregar nuestro experimento al proyecto que creamos antes, para tener todos nuestros elementos juntos:
1. Guarda el experimento (botón inferior de la barra), cambia a la vista "Projects", haz click en el proyecto creado anteriormente, y haz click en el botón "Edit" de la barra inferior:
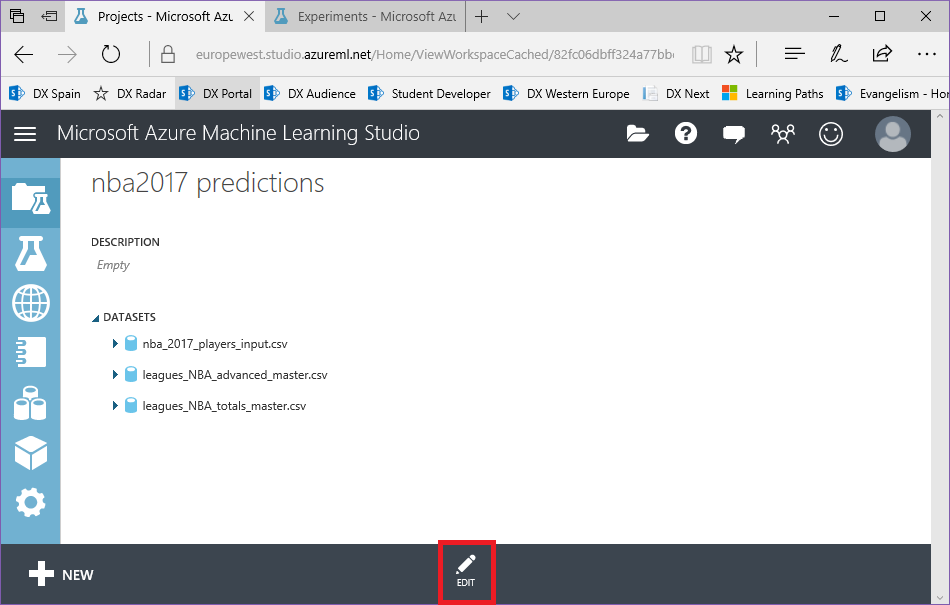
2. En la vista de edición, abre el menú desplegable "Experiments", marca el experimento que acabamos de crear para añadirlo al proyecto, y haz click en la flecha derecha entre ambas listas:
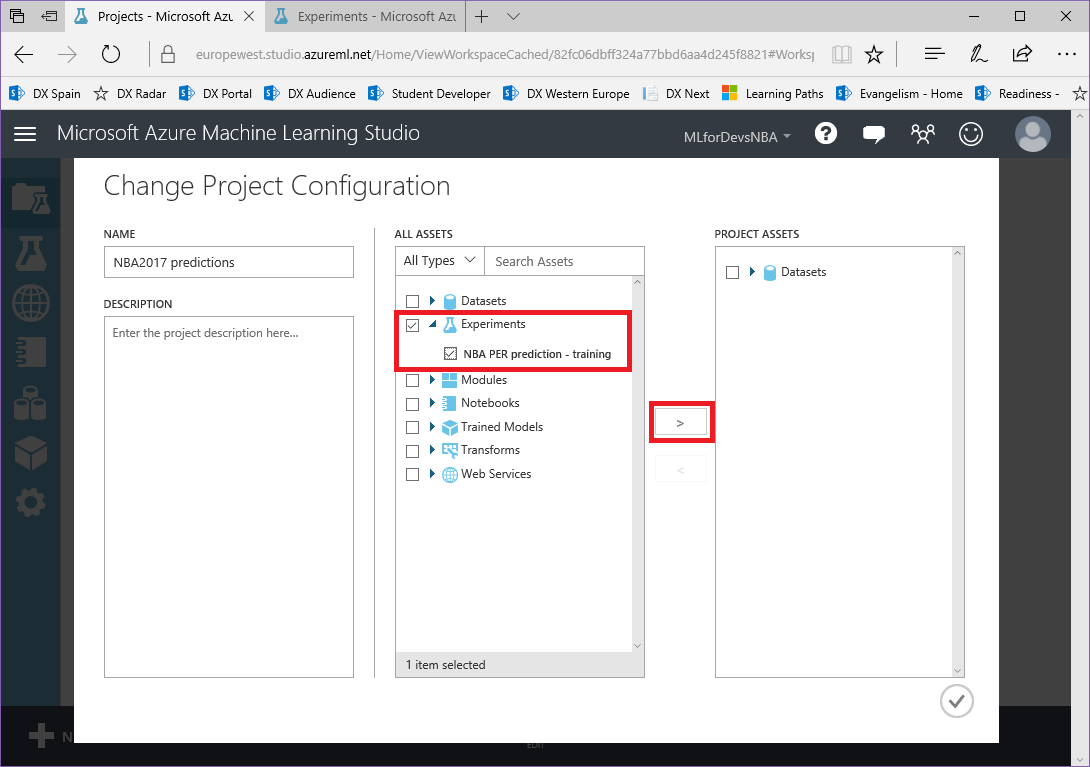
¡Todo preparado! Ya tenemos los conjuntos de datos, el experimento de entrenamiento con el primer paso en el flujo de datos y el proyecto que contiene todos los elementos creado, que debería tener este aspecto:

En el siguiente capítulo, comenzaremos a limpiar y preparar nuestros datos, parte fundamental de todo experimento de Machine Learning.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist