Cómo sincronizar dos tablas usando SQL Server Integration Services (SSIS)-Parte I de II
Hay diferentes situaciones en las que un administrador de base de datos necesita mantener dos tablas sincronizadas. Una de estas situaciones se da cuando es preciso mantener una copia de una talba en un repositorio de Datawarehouse que es usado como solución de archivo o generación de informes.
SQL Server proporciona un método robusto para mantener datos sincronizados en diferentes bases de datos usando Replicación, pero hay situacones en las que nuestra necesidad es sólo la de mantener sincronizadas un par de tablas y no deseamos tener que configurar una topología de replicación en la instancia.
El siguiente artículo está divido en dos partes: la Parte I explica cómo actualizar una tabla destino con la información que es añadida en una tabla origen, mientaras que la Parte II explica cómo replicar o propagar cualquier cambio que suecede en la información ya existente de la tabla origen en la tabla destino.
Este procedimiento se basa en el siguiente escenario: Una "tabla A" en la "base de datos A" replica periódicamente la nueva información añadida en una "tabla B" en la "base de datos B". La "tabla A" es actualizada periódicamente con nuevos registros y necesitamos copiar esa informaicón en la "tabla B". La implementación final tendrá el siguiente aspecto en SQL Server Business Intelligence Development Studio (BIDS):

Veamos cómo funciona esto:
1. "Source Table" es la "tabla A" en la "base de datos A" mientras que "Dest Table" es la tabla destino "B" en la "base de datos B". Empezamos creando dos conectores OLEDB diferentes en el componente de Data Flow en SSIS utilizando tanto la tabla origen como la tabla destino como orígenes de datos.
2. Necesitamos realizar una operación de JOIN en los dos orígenes de datos anteriores para copiar la información que queremos copiar de una tabla en la otra. Para que este JOIN funcione correctamente los datos deben de estar ordenados; esto se encuentra descrito en el siguiente enlace de MSDN:
En Integration Services, las transformaciones Mezclar y Combinación de mezcla requieren datos ordenados en sus entradas. Los datos de entrada deben estar ordenados físicamente, y se deben establecer opciones de ordenación en las salidas y en las columnas de salida del origen o en la transformación de nivel superior. Si las opciones de ordenación indican que los datos están ordenados, pero en realidad no lo están, los resultados de la operación de mezcla o combinación de mezcla son impredecibles.
En el operador de "Merge Join" es donde separamos los datos que han sido añadidos en la tabla origen (los datos que necesitamos) de los que no han sido añadidos (los que no necesitamos) desde la última ejecución del paquete de SSIS. En nuestro caso en la talba origen (a la izquierda) se han includio todas las columnas que queremos mantener sincronizadas mientras que la tabla destino (a la derecha) contiene solo el registro que correponde a la Clave Primaria, la columna "No_" en este caso. Este sería la descripción de la tarea:

Esta es la parte importante del proceso: el operador Left Outer Join recupera todos los registros en la tabla origen pero aquellos que no exiten en la tabla destino son recuperados como NULL en la columna "No_" usada en el Join (columna Join Key). Esto se encuentra también descrito en la documentación del producto:
Para incluir todos los productos, independientemente de si se ha escrito una revisión para alguno de ellos, utilice una combinación externa izquierda ISO. Ésta es la consulta:

LEFT OUTER JOIN incluye en el resultado todas las filas de la tabla Product, tanto si hay una coincidencia en la columna ProductID de la tabla ProductReview como si no la hay. Observe que en los resultados donde no hay un Id. de revisión de producto coincidente para un producto, la fila contiene un valor nulo en la columna ProductReviewID.
3. A continuación necesitamos separar los datos que necesitamos de los que no han cambiado. Para ello usamos una tarea de "Conditional Split" que se encarga de salvar la información para aquellos registros donde el campo clave "No_" devuelve NULL; dicho de otra forma, se encarga de salvar la información sólo de los registros nuevos. Aquí se muestra una descripción de esta tarea en BIDS:
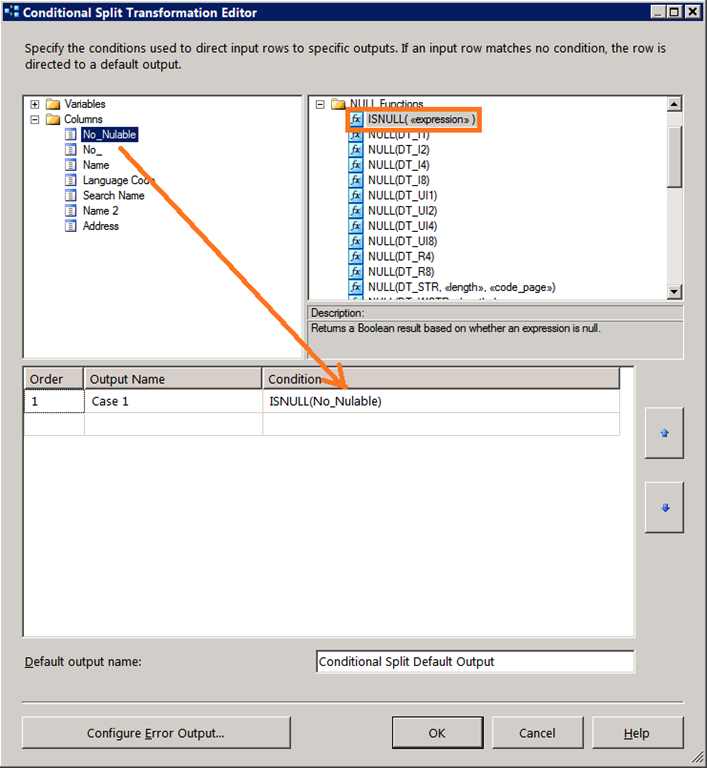
4. Finalmente realizamos un INSERT en los datos resultantes del operador "Conditional Split" en la tabla destino, que es la misma que usamos también como origen al principio del todo.
En este ejemplo la tarea de JOIN está configurada de tal modo que puede ser reutilizada tantas veces como sea necesario, los registros en la tabla destino no se duplicarán con la información de la tabla origen, sólo los nuevos registros serán incorporados en el destino.
Jorge Pérez Campo - Microsoft Customer Support Services
Comments
- Anonymous
May 21, 2014
Buenas Tardes. Mi nombre es Diego, Excelente ayuda, me sirvio de Mucho!!