Hierarchies (trees) in SQL Server 2005
There is much debate about how to implement hierarchies (trees) relationally in SQL Server. I decided to test the main techniques out and see which performed best for my application.
My problem is efficiently representing hierarchies in an experimental application code analysis database. The main hierarchy I am interested in is the class hierarchy. I want users to be able to determine quickly all the subclasses of a class. Class hierarchies tend to be broad and shallow. Since the .Net framework has about 18 500 classes (counting compiler generated classes) creation and query performance is an issue. In addition, since developers will be creating custom reports over the database, ease of query construction (queriability) is an issue.
There are three standard techniques for representing hierarchies in relation stores: the adjacency technique, the path technique, and the nested sets technique. A fourth approach based on floating point intervals (nested intervals) is sometimes mentioned but it is equivalent to the nested set approach with gaps and too hard for my users to understand.
Adjacency technique
In this representation, rows contain the IDs of their corresponding parent row. For example, the organization chart:
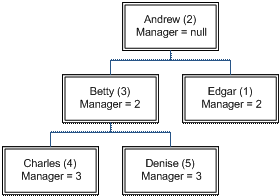
would be represented as:
Id |
Name |
Manager |
1 |
Edgar |
2 |
2 |
Andrew |
null |
3 |
Betty |
2 |
4 |
Charles |
3 |
5 |
Denise |
3 |
This is the first representation many people think of and is often considered a poor practice. However, many operations are straightforward to implement and users can easily understand it.
Path technique
In this representation, rows contain the path to their parents. For example, the organization chart:

would be represented as:
Id |
Name |
Path |
1 |
Edgar |
2 |
2 |
Andrew |
|
3 |
Betty |
2 |
4 |
Charles |
2,3 |
5 |
Denise |
2,3 |
This makes queries like finding all the descendents of a node straightforward since you only need to look for all nodes with the appropriate path prefix. Because of index limitations, the trees cannot be too deep since to be efficient you need to index the Path column, which in SQL Server 2005 must be at most 900 bytes.
Nested sets
This is the approach championed by the indomitable Joe Celko (see 1, 2, 3 and 4). Essentially the idea is to label nodes with their left and right traversal ranks as a node is entered and exited respectively. For example, the organization chart:

would be represented as:
Id |
Name |
Left |
Right |
1 |
Edgar |
8 |
9 |
2 |
Andrew |
1 |
10 |
3 |
Betty |
2 |
7 |
4 |
Charles |
3 |
4 |
5 |
Denise |
5 |
6 |
The representation makes operations like determining the descendents of a node and if two trees overlap easy because the left and right values bracket the left and right nodes of every descendent node.
The fundamental issue with the nested sets approach is that adding a node is very expensive (O(n)) since all subsequent nodes need to be renumbered.
Performance
Table 1 shows a simple benchmark for my problem involving 20 000 nodes. First the tree is created as 20 000 inserts and then the list of dependent nodes is generated for each of the 20 000 nodes in the tree. As expected, the adjacency technique works best for creating the tree. However, the surprising winner for finding all descendents of every node is also the adjacency technique.
Table 1 Time to create a 20 000 node tree and find all the descendents of each of the 20 000 nodes.
Technique |
Create (secs) |
All Descendents (secs) |
Adjacency |
4 |
4 |
Nested set |
6072 |
43 |
Path |
6 |
337 |
At first, I suspected a bug but my testing showed that all the techniques produce identical results. SQL Server 2005 does a good job of generating query plans for recursive CTE expressions but I think that because the whole table lives in cache and the tree is shallow (a maximum of 8 nodes deep) SQL Server can be very fast. It is also a great example of the power of the relational model since the result set is created in a highly parallelizable breadth-first way. As is often the case, a naïve implementation is faster because the runtime can optimize it better.
Because of the adjacency technique’s superior performance (for my shallow and broad trees) and queriability it is the most attractive choice. With more work I could probably improve the performance of the other techniques but the adjacency method has the performance and queriability I need. However, I am interested in any feedback you may have on issues I have missed.
Implementation experience
I found all three approaches easy to implement. The only time I had to think about what I was doing was figuring out what the best way to test for a varbinary prefix (I represented paths as strings of 4 byte node IDs). I am no T-SQL guru so I imagine any competent T-SQL developer could easily implement any of the approaches.
XML columns
The obvious SQL Server 20005 alternative is to encode the hierarchy in an XML column. Because classes are likely to relate to many other objects in the system, query patterns over classes are unpredictable and relational implementation performance is acceptable, I decided a pure relational implementation would give users the most power.
Comments
- Anonymous
February 15, 2006
There seems to be another mechanism for this in SQL Server 2005 (I found the link to it http://www.sqlservercentral.com/columnists/sSampath/recursivequeriesinsqlserver2005.asp)
Unfortunately I have not had a chance to try this out. Have you experimented with this technique? - Anonymous
February 15, 2006
This is the adjacency approach mentioned in the post. They use recursive CTE queries also.
In early betas of SQL Server 2005, recursive CTE queries generated poor query plans so I did this calculation with a stored procedure. However, now recursive CTE queries generate good query plans so I use CTE queries. - Anonymous
February 15, 2006
Images referring to your file system my friend
file://Tkzaw-pro-14/Mydocs3/ABloesch/My%20Documents/Projects/Blog/Tree% - Anonymous
February 15, 2006
Thanks for the update.
Do you have a sample of the CTE query that you might use in the example you give above?
(To understand how the performance figures were obtained, is it possible to link to/display the SQL used?) - Anonymous
March 05, 2006
The comment has been removed - Anonymous
June 22, 2006
wonderful article!!
A question:
Where I can found the Class (namespace) Hierarchy Chart for .net 2.0? Just like the MFC Hierarchy Chart in MSDN2001? Is it
available from microsoft or MSDN? Can you give me a link?
Thank you very much!! - Anonymous
October 04, 2006
Do you have any data on the relative speed of the recursive CTE vs (your old) stored procedure versions of the adjacency model?Have you tried a materialised ancestor version of the adjacency model (using either triggers or indexed views)?Can you publish the code used in the tests? - Anonymous
January 28, 2007
The comment has been removed - Anonymous
March 30, 2007
I know it is too late to ask, but where is the data to test your experiment? - Anonymous
November 25, 2008
The comment has been removed - Anonymous
February 04, 2009
I am missing the classical datawarehouse approach. I know it is mostly focused on querying, but in my personal experiance, the insert performance is not too bad, depending on the model of inserts.I have successfully used a combination of adjencency with a cache table for holding all relationships. I would have the following cache tableemp_cachedescendant,ancestor,distance2,2,01,1,01,2,13,3,03,2,14,4,04,3,14,2,25,5,05,3,15,2,1Additionally I would add a depth column to the base table, which allows a quicker computation of the distance value inside the trigger maintaining the cache and have the cache table indexed (depending on your query patterns). Inserting, updateing & deleting is done exactly as with adjacency, which makes sure there are no loops at all. Querying will use the cache table (& depth column). Querying the cache is quite natural to sql.I used this to handle a cost center structure which was 17 levels deep and handled approx. 15.000 nodes. - Anonymous
April 02, 2009
The comment has been removed - Anonymous
May 07, 2009
Hi there,I have a problem which i wonder if you could point me in direction how to solve.I have a tree structure where each node have a "rating" column (int). For "composite" nodes, nodes with children the rating column should take the value of the max value of all its children. What kind of structure do i represent such a tree best in? - Anonymous
September 10, 2009
The comment has been removed - Anonymous
November 15, 2009
I don't know this Celko. Wikipedia says:He is often corrected by product experts including a number of the SQL Server MVP's which lead to protracted discussions which more often than not he comes out losing.All I know is he is a brag who's not helping average programmers... I have 20+ experience and paid $1000s of a day. Ashol. Same with you Chandrashekar. I bet you dont even know what you are saying. - Anonymous
June 10, 2011
In support of Marc Buzina's approach, here is my experience with a project that currently holds around 37,000 tree nodes and is always expected to grow, although not very fast.We started as usual with the adjacency list model. As the tree kept growing we moved to nested sets trying to improve response time. The tree kept growing and timeouts and concurrency problems made it clear that we needed another aproach. (Our nested sets implementation did not use gaps and inserts/updates/deletes involved a lot of recalculations of intervals. Also most probably it was not the most optimized implementation.) We came across something called "Transitive closure" which maps to the structure proposed by mbuzina.Now our Tree table has three columns: NodeId, ParentId, SiblingNumber. The TreeHierarchy table has AncestorId, DescendantId, Distance and holds about 240,000 records. It is maintained through triggers on the Tree table. Insert/update/delete of a node now affect only a small number of records in TreeHierarchy, so deadlocks and timeouts do not worry us any more. Retrieving the whole tree takes less than 0.6 sec. We never need to do this anyway, because the end user would have to wait a long long time for the browser to show all 37,000 nodes, so we load on demand only branches that the user decides to delve deeper into. The maximum depth currently is 11, and the most "fertile" parents have between 300 and 680 children. - Anonymous
October 22, 2011
It seems to me that the Nested Sets approach is storing more information than the others, namely, the ORDER in which sibling nodes appear. In the example above, if we wanted Denise to appear to the left of Charles, we would need another field (and a mechanism to manage the value of that field) to store the order in both the Adjacency and the Path techniques.I know the original post is a bit old at this point, but it would be interesting to see how one could build a mechanism to store the order of sibling nodes into the Adjacency and Path technique and then compare all three for speed. - Anonymous
July 25, 2012
I know this is an old thread but ran across it while doing a bit of research. I've got to ask, where is the code that built the 20,000 row sample and where is the code that you actually tested?